為了防止資料丟失以及服務重啟時能夠恢復資料,Redis支持資料的持久化,主要分為兩種方式,分別是RDB和AOF.
RDB
RDB持久化是把當前行程資料生成快照保存到磁盤上的程序,由于是某一時刻的快照,那么快照中的值要早于或者等于記憶體中的值,
生成的rdb檔案的名稱以及存盤位置由redis.conf中的dbfilename和dir兩個引數控制,默認生成的rdb檔案是dump.rdb,
觸發方式
觸發rdb持久化的方式有2種,分別是手動觸發和自動觸發,
手動觸發
redis客戶端執行save命令和bgsave命令都可以觸發rdb持久化,但是兩者還是有區別的,
1.使用save命令時是使用redis的主行程進行持久化,此時會阻塞redis服務,造成服務不可用直到持久化完成,線上環境不建議使用;
2.bgsave命令是fork一個子行程,使用子行程去進行持久化,主行程只有在fork子行程時會短暫阻塞,fork操作完成后就不再阻塞,主行程可以正常進行其他操作,
3.bgsave是針對save阻塞主行程所做的優化,后續所有的自動觸發都是使用bgsave進行操作,
自動觸發
在以下4種情況時會自動觸發
-
redis.conf中配置save m n,即在m秒內有n次修改時,自動觸發bgsave生成rdb檔案;
-
主從復制時,從節點要從主節點進行全量復制時也會觸發bgsave操作,生成當時的快照發送到從節點;
-
執行debug reload命令重新加載redis時也會觸發bgsave操作;
-
默認情況下執行shutdown命令時,如果沒有開啟aof持久化,那么也會觸發bgsave操作;
關閉rdb持久化
如果要關閉rdb持久化可以用兩種方法:
- 執行以下命令(redis-cli):
config set save ""
- 修改組態檔
// 打開該行注釋
save ""
// 注釋掉以下內容
# save 900 1
# save 300 10
# save 60 10000
流程
rdb持久化的流程圖如下所示:
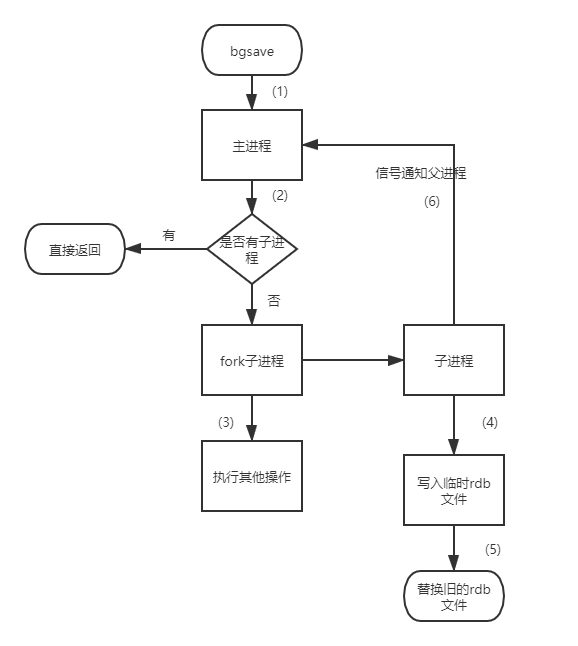
具體流程如下:
- redis客戶端執行bgsave命令或者自動觸發bgsave命令;
- 主行程判斷當前是否已經存在正在執行的子行程,如果存在,那么主行程直接回傳;
- 如果不存在正在執行的子行程,那么就fork一個新的子行程進行持久化資料,fork程序是阻塞的,fork操作完成后主行程即可執行其他操作;
- 子行程先將資料寫入到臨時的rdb檔案中,待快照資料寫入完成后再原子替換舊的rdb檔案;
- 同時發送信號給主行程,通知主行程rdb持久化完成,主行程更新相關的統計資訊(info Persitence下的rdb_*相關選項),
優缺點
優點
- RDB檔案是某個時間節點的快照,默認使用LZF演算法進行壓縮,壓縮后的檔案體積遠遠小于記憶體大小,適用于備份、全量復制等場景;
- Redis加載RDB檔案恢復資料要遠遠快于AOF方式;
缺點
- RDB方式實時性不夠,無法做到秒級的持久化;
- 每次呼叫bgsave都需要fork子行程,fork子行程屬于重量級操作,頻繁執行成本較高;
- RDB檔案是二進制的,沒有可讀性,AOF檔案在了解其結構的情況下可以手動修改或者補全;
- 版本兼容RDB檔案問題;
AOF
aof方式持久化是使用文本協議將每次的寫命令記錄到aof檔案中,經過檔案重寫后記錄最終的資料生成命令,在redis啟動時,通過執行aof檔案中的命令恢復資料,
aof方式主要解決了資料實時性持久化的問題,aof方式對于兼顧資料安全性和性能非常有幫助,
開啟aof
開啟aof模式持久化需要修改redis.conf檔案中的如下配置:
# 開啟aof
appendonly true
# aof檔案名稱
appendfilename "appendonly.aof"
# aof檔案存盤位置
dir ./
也可以在redis客戶端使用命令列的方式開啟或者關閉aof
# 開啟aof
config set appendonly yes
# 關閉aof
config set appendonly no
aof持久化流程
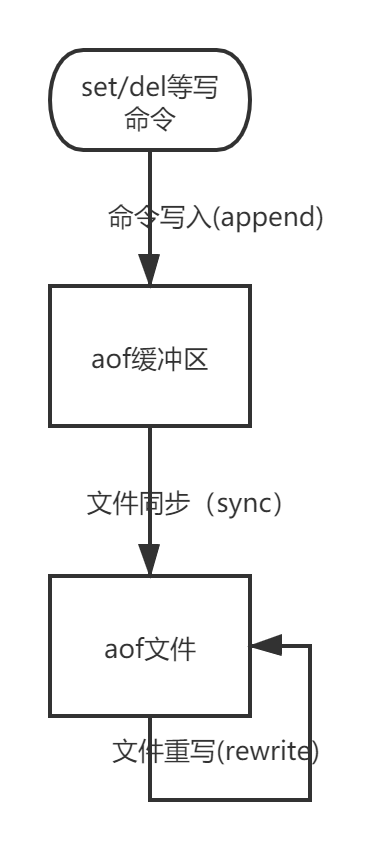
-
append
aof檔案只記錄寫命令,不記錄讀命令,當服務端接收到寫命令后,redis會將命令寫入到aof緩沖區中,之所以寫入緩沖區而不直接寫入aof檔案中是因為如果每次都將命令直接寫入到檔案中,那么redis的性能將完全取決于硬碟的讀寫能力,這與redis性能至上的理念不符,另外,寫入緩沖區中也便于使用不同的同步策略, -
sync
檔案同步,即將aof緩沖區中的命令同步到aof檔案中,redis提供三種策略以供選擇,由引數appendfsync控制,三種策略分別是:
always: 表示命令append到緩沖區以后呼叫系統fsync操作同步到aof檔案中,fsync操作完成后主執行緒回傳;
no: 表示命令寫入aof緩沖區后呼叫作業系統write操作,不對aof檔案做fsync同步,同步到硬碟操作由作業系統負責,通常同步周期最長30秒;
everysec: 表示命令寫入aof緩沖區后呼叫作業系統write操作,write操作完成后主執行緒回傳,由專門的執行緒每秒去進行fsync同步檔案操作
默認使用everysec,兼顧性能和安全性,很顯然,使用always時每次都要等同步完成后才能回傳,這個性能是很低的;同理使用no時,雖然不用每次都同步aof檔案,但是同步操作周期不可控,資料安全性得不到保障,因此還是使用默認的everysec兼顧安全性和性能,每一秒同步一次,也就是在突發狀況下最多丟失1秒的資料,
- 重寫(rewrite)
隨著寫命令越來越多,aof檔案的體積也越來越大,此時就需要重寫機制來按照特定的機制清除或者合并命令從而達到減小檔案體積,便于redis重啟加載的目的,
重寫機制
重寫規則
- 行程內已經過期的資料不再寫入檔案;
- 只保存最終資料的寫入命令,如set a 1, set a 2, set a 3,此時只保留最終的set a 3;
- 多條寫命令合并為一條命令,如lpush list 1, lpush list 2, lpush list 3合并為lpush list 1,2,3,同時為了防止單條命令過大,對于list、set、zset、hash等以64個元素為界限拆分為多條命令;
觸發
- 手動觸發
手動執行bgrewriteaof命令即可觸發aof重寫 - 自動觸發
自動觸發與redis.conf中的auto-aof-rewrite-min-size和auto-aof-rewrite-percentage配置有關,默認配置如下:
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 64mb
auto-aof-rewrite-min-size: 表示觸發aof重寫時aof檔案的最小體積,默認64m
auto-aof-rewrite-percentage: 表示當前aof檔案空間和上一次重寫后aof檔案空間的比值,默認是aof檔案體積翻倍時觸發重寫
auto-aof-rewrite-percentage的計算方法:
auto-aof-rewrite-percentage =(當前aof檔案體積 - 上次重寫后aof檔案體積)/ 上次重寫后aof檔案體積 * 100%
自動觸發的條件:
(當前aof檔案體積 > auto-aof-rewrite-min-size) && (auto-aof-rewrite-percentage的計算值 > 組態檔中配置的auto-aof-rewrite-percentage值)
重寫流程
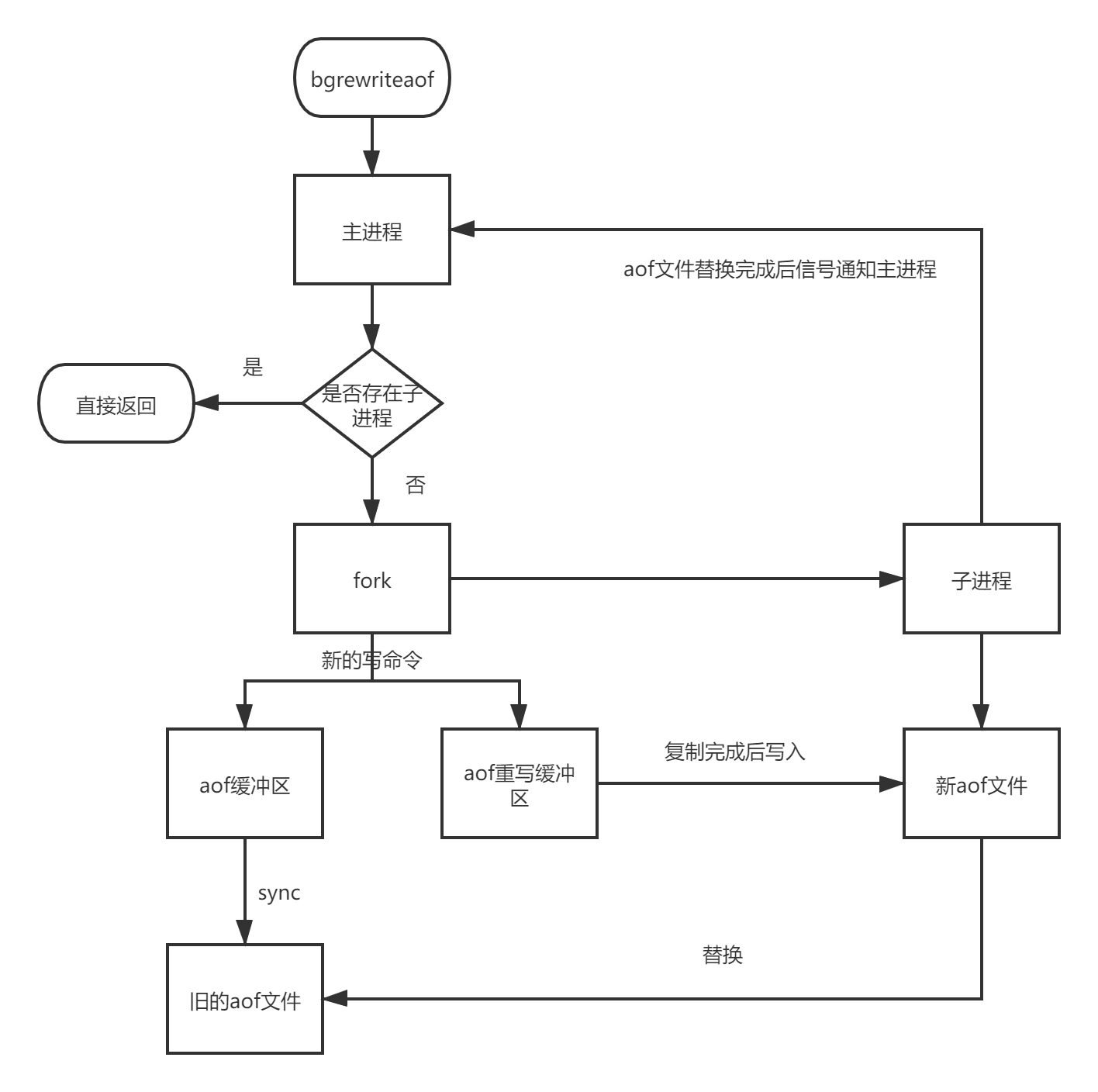
- 手動或者自動觸發檔案重寫后主行程需要先判斷當前是否有子行程存在,如果存在則直接返回,不存在則fork子行程;
- fork操作完成后,主行程即可回應其他命令,在子行程生成新的aof檔案程序中,主行程仍然維持原來的流程以保證原有aof機制的正確性;
- 在子行程生成新的aof檔案程序中主行程執行的新命令同時會被寫入到aof重寫緩沖區中,當新aof檔案生成后再將這一部分命令寫入到新aof檔案中,防止資料丟失;
- 子行程根據記憶體快照,根據重寫規則生成新的aof檔案,每次批量寫入硬碟資料量由配置
aof-rewrite-incremental-fsync控制,默認為32MB,防止單次刷盤資料過多造成硬碟阻塞; - 父行程把aof重寫緩沖區的資料寫入到新的aof檔案中;
- 使用新aof檔案替換舊的aof檔案并發送信號給主行程表示重寫完成,
優缺點
優點
- 資料安全性較高,每隔1秒同步一次資料到aof檔案,最多丟失1秒資料;
- aof檔案相比rdb檔案可讀性較高,便于災難恢復;
缺點
- 雖然經過檔案重寫,但是aof檔案的體積仍然比rdb檔案體積大了很多,不便于傳輸且資料恢復速度也較慢
- aof的恢復速度要比rdb的恢復速度慢
fork以及copy_on_write
fork
不論RDB方式去創建一個新的rdb檔案還是AOF方式重寫aof檔案,都需要fork一個子行程去處理以便在不阻塞主行程的情況下完成rdb檔案的生成以及aof檔案的重寫,下面我們簡單了解一下什么是fork以及使用到的copy_on_write寫時復制技術,
何為fork?簡而言之就是創建一個主行程的副本,創建的子行程除了行程id,其余任何內容都和主行程完全一致,這就是fork,
fork創建的子行程獨立于主行程而存在,雖然兩個行程記憶體空間的內容完全一致,但是對于記憶體的寫入、修改以及檔案的映射都是獨立的,兩個行程不會相互影響,
通過fork技術完美的解決了快照的問題,只需要某個時間點的記憶體中的資料,而父行程可以繼續對自己的記憶體進行修改、寫入而不會影響子行程的記憶體,這既不會阻塞主行程也不影響生成快照,
通過fork子行程的方式雖然能夠完美解決不阻塞的情況下創建快照的問題,但是又會引入以下的問題:
子行程和主行程擁有相同的記憶體空間,就相當于瞬間將記憶體的使用量提高了一倍,假設服務器是16GB記憶體,主行程占用10GB,那么此時再創建子行程還需奧10GB,很明顯超過了總記憶體,這很顯然是存在很大問題的,即使不超過總記憶體,fork時將記憶體使用量提高一倍也是不可取的,
COW
寫時拷貝(COW)就是為了解決這個問題而出現,那么什么是COW呢?
COW的主要作用就是將拷貝推遲到寫操作真正發生時,這也就避免了大量無意義的拷貝,
什么意思呢?
意思是說在fork子行程時,父子行程會被內核分配到不同的虛擬記憶體空間中,對于父子行程來說它們訪問的是不同的記憶體空間,但是兩個虛擬記憶體空間映射的仍然是相同的物理記憶體,也就是說在fork完成后未發生任何修改時,父子行程對應的物理記憶體是同一份,
如果此時主行程執行了修改或者寫入操作?因為有了修改或寫入操作,此時父子行程記憶體就會出現不一致的情況,由于是主行程進行的修改,因此內核會為主行程要修改的記憶體塊創建一個副本供主行程進行修改而不改變子行程的記憶體,也就是誰發生了修改就要為誰創建相應的副本,
linux中記憶體的復制是以記憶體頁為單位的(4KB),也就是會為發生改變的記憶體頁創建副本,
COW技術彌補了fork行程時記憶體翻倍的情況,fork操作為子行程訪問父行程提供了支持,COW減少了額外的開銷,這兩者是Redis能夠使用子行程進行快照持久化的核心,
COW原理:
fork()之后,kernel把父行程中所有的記憶體頁的權限都設為read-only,然后子行程的地址空間指向父行程,當父子行程都只讀記憶體時,相安無事,當其中某個行程寫記憶體時,CPU硬體檢測到記憶體頁是read-only的,于是觸發頁例外中斷(page-fault),陷入kernel的一個中斷例程,中斷例程中,kernel就會 把觸發的例外的頁復制一份,于是父子行程各自持有獨立的一份,
COW優點:
- 減少不必要的資源分配,只有在發生改變時才創建修改的記憶體頁的副本,而不是創建整個記憶體的副本;
- 減少fork子行程的時間,因為cow的存在,fork子行程時只需要復制主行程的空間記憶體頁表即可,而不需要復制物理記憶體,因此大大提高了fork子行程的速度,
COW缺點:
- 如果fork之后,父子行程都需要進行大量修改,那么就會出現大量的分頁錯誤(頁例外中斷page-fault),這就有點得不償失了,
但是對于redis來說,子行程只是用來生成快照的,并不會進行修改或者寫入操作,也就不存在上述所說的問題了,
重啟加載
Redis支持單獨啟動RDB或者單獨啟用AOF,也支持同時啟用RDB和AOF,redis重啟時加載流程如下所示:
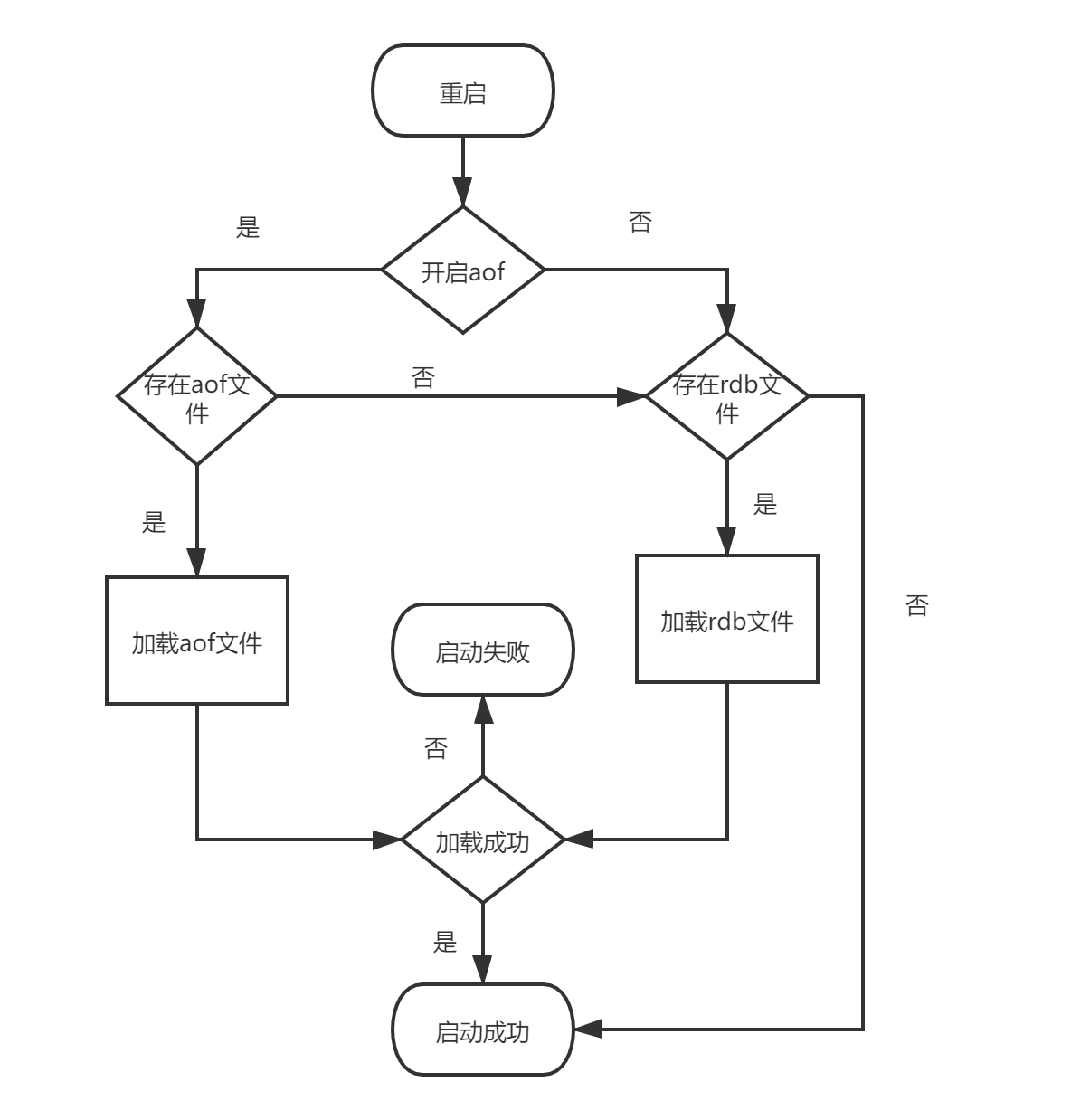
- redis重啟時判斷是否開啟aof,如果開啟了aof,那么就優先加載aof檔案;
- 如果aof存在,那么就去加載aof檔案,加載成功的話redis重啟成功,如果aof檔案加載失敗,那么會列印日志表示啟動失敗,此時可以去修復aof檔案后重新啟動;
- 若aof檔案不存在,那么redis就會轉而去加載rdb檔案,如果rdb檔案不存在,redis直接啟動成功;
- 如果rdb檔案存在就會去加載rdb檔案恢復資料,如加載失敗則列印日志提示啟動失敗,如加載成功,那么redis重啟成功,且使用rdb檔案恢復資料;
持久化程序中需要注意的問題
aof追加阻塞
aof追加阻塞是指在開啟aof持久化時,默認使用的是everysec同步策略,此時有一個額外的執行緒同步aof緩沖區中的內容到磁盤上的aof檔案,如果在同步程序中由于磁盤io過高導致的redis主行程阻塞;
出現aof阻塞的根本原因是磁盤負載過高,redis主行程會監控同步執行緒每次同步aof緩沖區內容到aof檔案所耗費的時間,如果距離上次同步成功的時間在2s內,那么主執行緒就直接回傳,如果距離上次同步成功的時間超過2s,redis主行程就會阻塞,直到同步完成,
具體的流程圖如下所示:
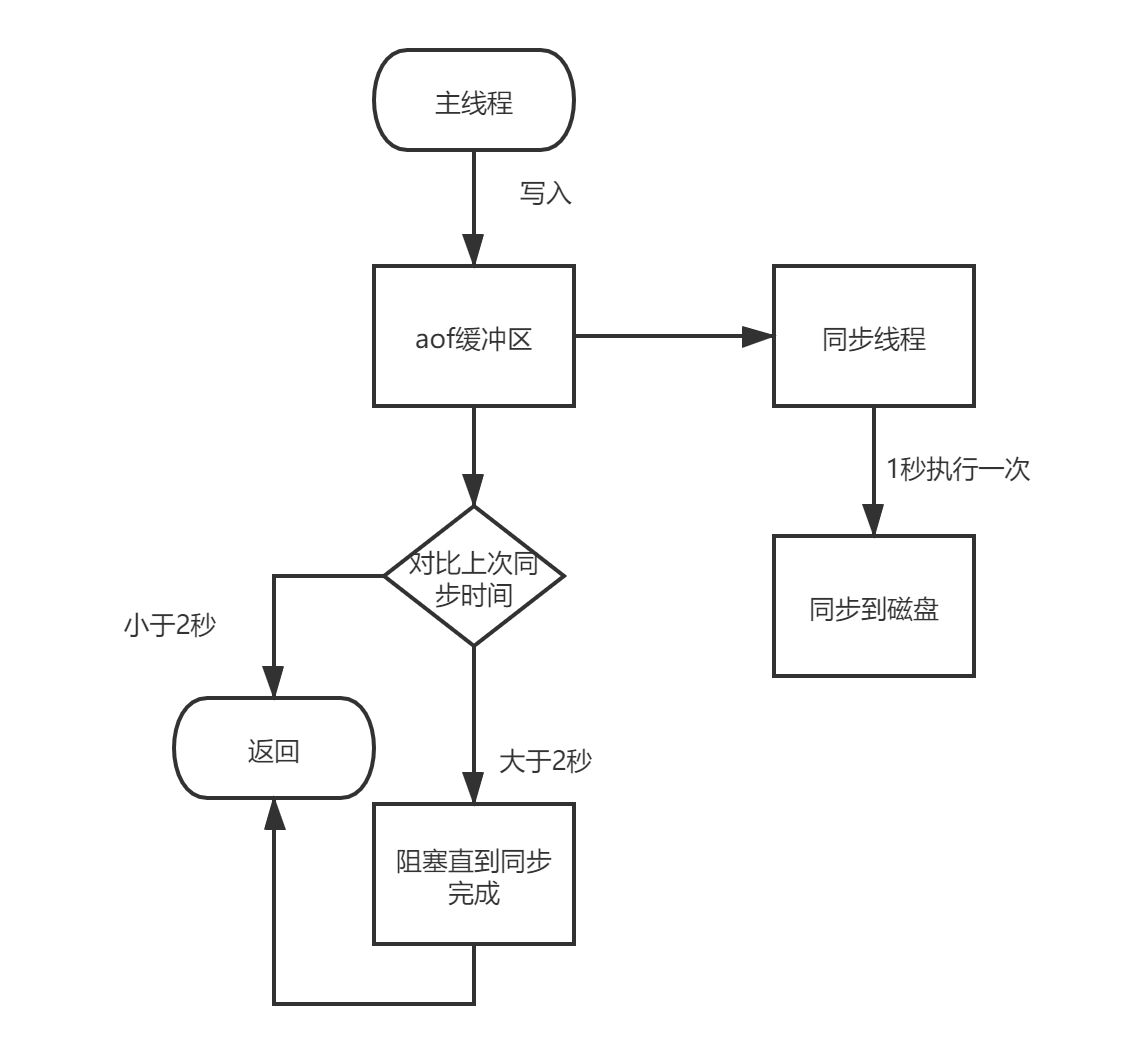
發生aof追加阻塞時會嚴重影響redis的性能,造成該現象的主要原因是磁盤高負載,那么相應的解決方案也要從磁盤負載上來解決,
解決方案:
- redis盡量不要與其他高磁盤消耗的服務部署在一起,如rabbitmq等訊息佇列,mysql等資料庫服務;
- 配置開啟no-appendfsync-on-rewrite=yes,表示在重寫期間不做fsync操作;
- 單機配置多個redis實體的情況下,不同實體分盤存盤aof檔案以減輕單個磁盤的壓力;
fork阻塞耗時問題
無論生成rdb檔案還是重寫aof檔案,都會使用fork創建一個子行程來處理,這樣就不會阻塞主行程了,雖然fork出來的子行程不會阻塞主行程,但是fork的程序中還是會阻塞主行程,也就是說子行程創建程序中還是會阻塞主行程影響redis對外提供服務,
前面提過fork程序中使用寫時復制技術,并不會真正的復制物理記憶體,但是會復制主行程的空間記憶體頁表,例如主行程為10G記憶體,大概要復制20M的空間頁表,也就是說主行程記憶體越大,需要復制的空間記憶體頁表越大,fork所需的時間越長,redis阻塞的時間越長,因此fork操作的優化點在于主行程的記憶體大小,另外有的虛擬化技術也會加大fork的時間,如Xen虛擬機,
因此從主行程記憶體和虛擬機化技術兩個方面來優化fork阻塞耗時問題:
- 盡量使用物理機或者高效支持fork的虛擬化技術;
- 控制Redis實體最大可用記憶體,fork耗時和redis主行程記憶體量成正比;
- 降低fork操作的頻率,如調高auto-aof-rewrite-min-size的值以減少aof重寫的次數,或者主從復制時減少全量復制等;
- 合理配置linux記憶體分配策略,防止由于物理記憶體不足導致的fork失敗;
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/236919.html
標籤:Java
上一篇:MyBatisPlus-快速入門
下一篇:重寫Laravel例外處理類