手寫演算法-python代碼實作Kmeans++以及優化
- 聚類結果不穩定的優化方法
- 一次優化:kmeans++
- 二次優化:添加引數n_init
- 其他問題的優化方法
聚類結果不穩定的優化方法
上篇文章,我們列舉了Kmeans的不足之處,也用python代碼實作了Kmeans聚類,但是跑出來的聚類結果不穩定,詳情請看:
鏈接: 手寫演算法-python代碼實作Kmeans
今天,我們來解決這個問題,
一次優化:kmeans++
問題點:隨機選取k個資料,導致結果無法收斂,
因為隨機選取,可能會使選取的幾個資料點都非常靠近,不僅導致演算法收斂很慢,還會導致結果只收斂到區域最小值,
解決思路:
使用Kmeans++的方法初始質心,流程如下:
1、從輸入的資料點集合中隨機選擇一個點作為第一個聚類中心;
2、對于資料集中的每一個點xi,計算它與已選擇的聚類中心中最近聚類中心的距離D(x);
3、 選擇一個新的資料點作為新的聚類中心,選擇的原則是:D(x)較大的點,被選取作為聚類中心的概率較大;
4、重復b和c直到選擇出k個聚類質心;
5、利用這k個質心來作為初始化質心去運行標準的K-Means演算法;
按照上面的流程,我們來修改Kmeans代碼,實作Kmeans++,
import numpy as np
from sklearn.datasets import make_blobs
from matplotlib import pyplot as plt
#無監督演算法,學習程序就是訓練質心的位置,進行聚類
class Kmeans:
#添加init引數,默認init = 'random'就是標準Kmeans,init = 'Kmeans++'則為Kmeans++
def __init__(self,k,init='random'):
self.k = k
self.init = init
def calc_distance(self,x1,x2):
diff = x1 - x2
distances = np.sqrt(np.square(diff).sum(axis=1))
return distances
def fit(self,x):
self.x = x
m,n = self.x.shape
if self.init == 'random':
#隨機選定k個資料作為初始質心,不重復選取
self.original_ = np.random.choice(m,self.k,replace=False)
#默認類別是從0到k-1
self.original_center = x[self.original_]
elif self.init == 'Kmeans++':
first = np.random.choice(m)
#儲存在一個串列中
index_select = [first]
#繼續選取k-1個點
for i in range(1,self.k):
all_distances = np.empty((m,0))
for j in index_select:
#計算每個資料點到已選擇的質心的距離
distances = self.calc_distance(self.x,x[j]).reshape(-1,1)
#把每個資料點到已選擇的質心的距離儲存在陣列中,每個質心一列
all_distances = np.c_[all_distances,distances]
#找到每個點到已選擇質心的最小距離
min_distances = all_distances.min(axis=1).reshape(-1,1)
#在min_distances里面選取距離較大的點作為下一個質心,我們就選最大的點
index = np.argmax(min_distances)
index_select.append(index)
#生成Kmeans++方法的初始質心,默認類別是從0到k-1
self.original_center = x[index_select]
while True:
#初始化一個字典,以類別作為key,賦值一個空陣列
dict_y = {}
for j in range(self.k):
dict_y[j] = np.empty((0,n))
for i in range(m):
distances =self.calc_distance(x[i],self.original_center)
#把第i個資料分配到距離最近的質心,存放在字典中
label = np.argsort(distances)[0]
dict_y[label] = np.r_[dict_y[label],x[i].reshape(1,-1)]
centers = np.empty((0,n))
#對每個類別的樣本重新求質心
for i in range(self.k):
center = np.mean(dict_y[i],axis=0).reshape(1,-1)
centers = np.r_[centers,center]
#與上一次迭代的質心比較,如果沒有發生變化,則停止迭代(也可考慮收斂時停止)
result = np.all(centers == self.original_center)
if result == True:
break
else:
#繼續更新質心
self.original_center = centers
def predict(self,x):
y_preds = []
m,n = x.shape
for i in range(m):
distances =self.calc_distance(x[i],self.original_center)
y_pred = np.argsort(distances)[0]
y_preds.append(y_pred)
return y_preds
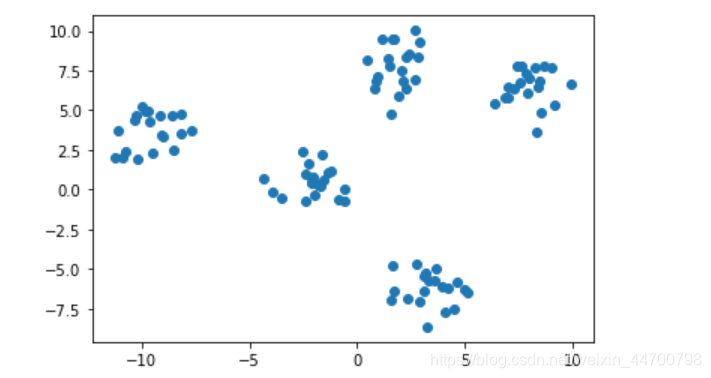
代碼修改完畢,現在我們再次請出上篇文章用到的資料集,驗證修改后,聚類結果穩不穩定:
#再次用到此資料集
x,y = make_blobs(centers=5,random_state=20,cluster_std=1)
plt.scatter(x[:,0],x[:,1])
plt.show()
model = Kmeans(k=5,init = 'Kmeans++')
model.fit(x)
y_preds = model.predict(x)
plt.scatter(x[:,0],x[:,1],c=y_preds)
plt.show()
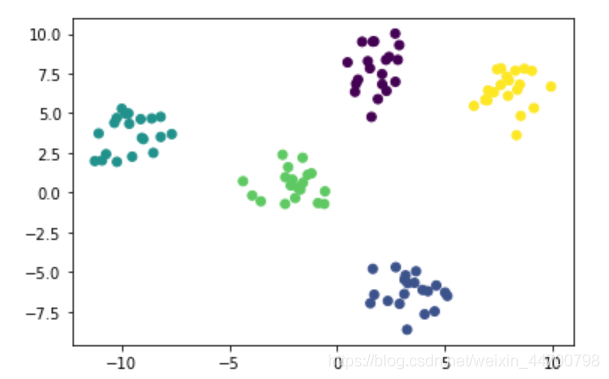
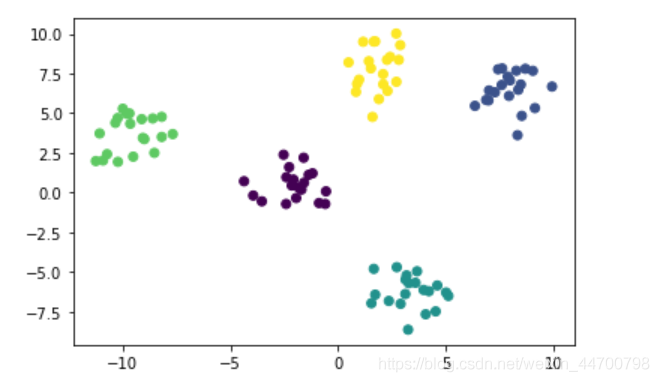
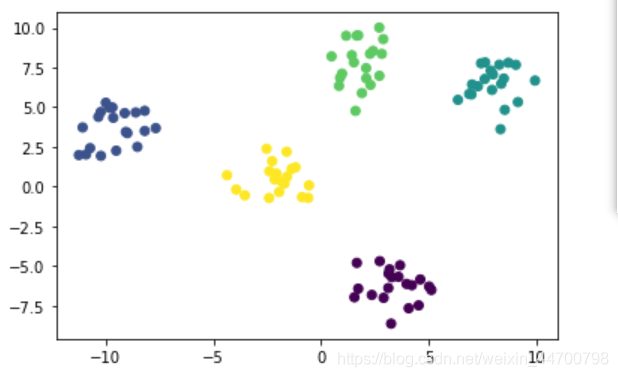
可以看到,不管執行多少遍,聚類結果都是穩定的,證明我們修改的Kmeans++成功!
二次優化:添加引數n_init
這是什么意思呢,意思很簡單:
就是我執行n_init次,最終結果取最優的一次,最優怎么理解呢?
簡單地說,就是所有樣本點到所屬的聚類質心的距離之和最小,即為最優,
J
=
m
i
n
∑
i
=
1
m
∣
∣
x
i
?
μ
c
i
∣
∣
2
J= min\sum_{i=1}^{m} ||x_i-\mu_c{^i}||^2
J=mini=1∑m?∣∣xi??μc?i∣∣2
在Kmeans++方法選取質心的基礎上,再添加引數n_init,雙重保險,萬無一失!哈哈,,,
找到n_init次運行中,J最小時,對應的聚類質心,即為最優解,
繼續修改代碼如下:
#無監督演算法,學習程序就是訓練質心的位置,進行聚類
class Kmeans:
#添加init引數,默認init = 'random'就是標準Kmeans,init = 'Kmeans++'則為Kmeans++
def __init__(self,k,n_init,init='random'):
self.k = k
self.n_init = n_init
self.init = init
def calc_distance(self,x1,x2):
diff = x1 - x2
distances = np.sqrt(np.square(diff).sum(axis=1))
return distances
def fit(self,x):
m,n = x.shape
if self.init == 'random':
#隨機選定k個資料作為初始質心,不重復選取
self.original_ = np.random.choice(m,self.k,replace=False)
#默認類別是從0到k-1
self.original_center = x[self.original_]
elif self.init == 'Kmeans++':
first = np.random.choice(m)
#儲存在一個串列中
index_select = [first]
#繼續選取k-1個點
for i in range(1,self.k):
all_distances = np.empty((m,0))
for j in index_select:
#計算每個資料點到已選擇的質心的距離
distances = self.calc_distance(x,x[j]).reshape(-1,1)
#把每個資料點到已選擇的質心的距離儲存在陣列中,每個質心一列
all_distances = np.c_[all_distances,distances]
#找到每個點到已選擇質心的最小距離
min_distances = all_distances.min(axis=1).reshape(-1,1)
#在min_distances里面選取距離較大的點作為下一個質心,我們就選最大的點
index = np.argmax(min_distances)
index_select.append(index)
#生成Kmeans++方法的初始質心,默認類別是從0到k-1
self.original_center = x[index_select]
while True:
#初始化一個字典,以類別作為key,賦值一個空陣列
dict_y = {}
for j in range(self.k):
dict_y[j] = np.empty((0,n))
for i in range(m):
distances =self.calc_distance(x[i],self.original_center)
#把第i個資料分配到距離最近的質心,存放在字典中
label = np.argsort(distances)[0]
dict_y[label] = np.r_[dict_y[label],x[i].reshape(1,-1)]
centers = np.empty((0,n))
#對每個類別的樣本重新求質心
for i in range(self.k):
center = np.mean(dict_y[i],axis=0).reshape(1,-1)
centers = np.r_[centers,center]
#與上一次迭代的質心比較,如果沒有發生變化,則停止迭代(也可考慮收斂時停止)
result = np.all(centers == self.original_center)
if result == True:
return dict_y,centers
break
else:
#繼續更新質心
self.original_center = centers
def select_optimal(self,x):
#儲存每次的J值
result = []
#儲存每次的聚類質心
center = []
for i in range(self.n_init):
dict_y_i,center_i =self.fit(x)
#計算J值
for j in range(self.k):
result_i = 0
#計算第j個類別的樣本到類別質心的距離之和
distance_j = np.sum(self.calc_distance(dict_y_i[j],center_i[j]))
result_i += distance_j
result.append(result_i)
center.append(center_i)
#找到最小J值,對應的聚類質心
index = np.argmin(result)
self.original_center = center[index]
def predict(self,x):
y_preds = []
m,n = x.shape
for i in range(m):
distances =self.calc_distance(x[i],self.original_center)
y_pred = np.argsort(distances)[0]
y_preds.append(y_pred)
return y_preds
二次修改過后,我們再次測驗,結果應該是更加穩定了,看有沒有bug
model = Kmeans(k=5,n_init=10,init = 'Kmeans++')
model.select_optimal(x)
y_preds = model.predict(x)
plt.scatter(x[:,0],x[:,1],c=y_preds)
plt.show()
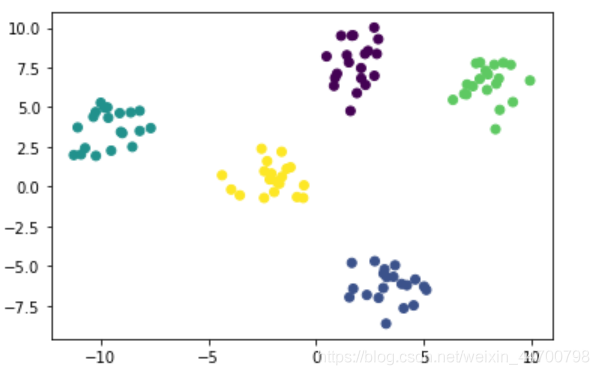
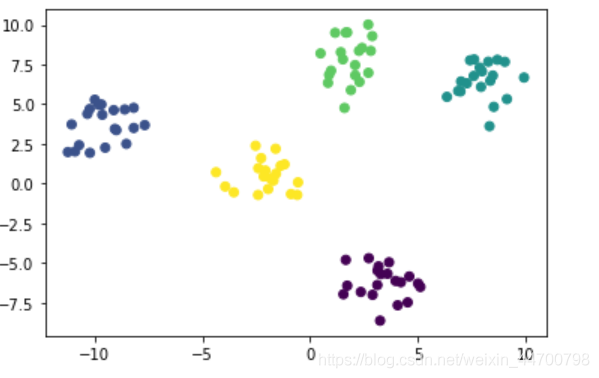
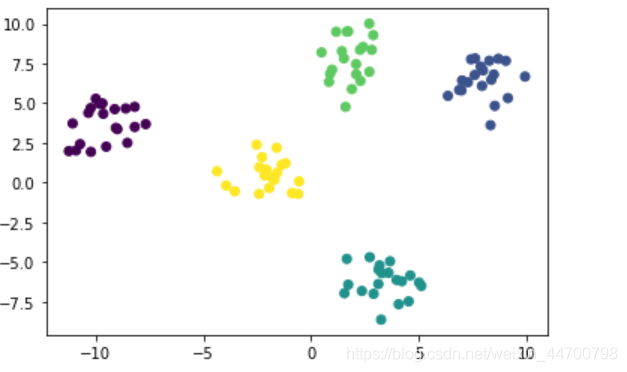
沒有bug,結果也很穩定,
sklearn的效果上篇文章展示過,很穩定,
為什么sklearn的聚類結果這么穩定?
其實熟悉Kmeans的同學就應該清楚,我們這是復現了一部分sklearn里面KMeans的功能,
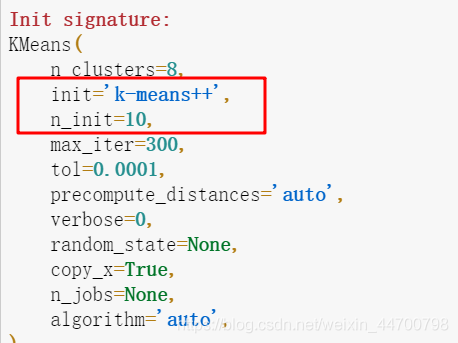
原因已經清楚了,sklearn里面的Kmeans,優化方法早就封裝好了!
其他問題的優化方法
一、k值的選取問題,
方法1、肘部圖法,一個樣本集,k值越大,聚類的類別越多,
損失就越小,這里的損失就是我們上面說的J值,但是,當k值到達某個點
時,繼續增大k值,損失的減小將變得緩慢,這個拐點對應的k值一般而
言,就是最佳k值,
方法2、從簇內的稠密程度和簇間的離散程度來評估聚類的效果,常見的
方法有輪廓系數Silhouette Coefficient和Calinski-Harabasz Index,
sklearn中已封裝好,sklearn.metrics.calinski_harabasz_score
得分越高,聚類效果越好,得分最高時,就是最佳的k值,
1、肘部圖法示例:
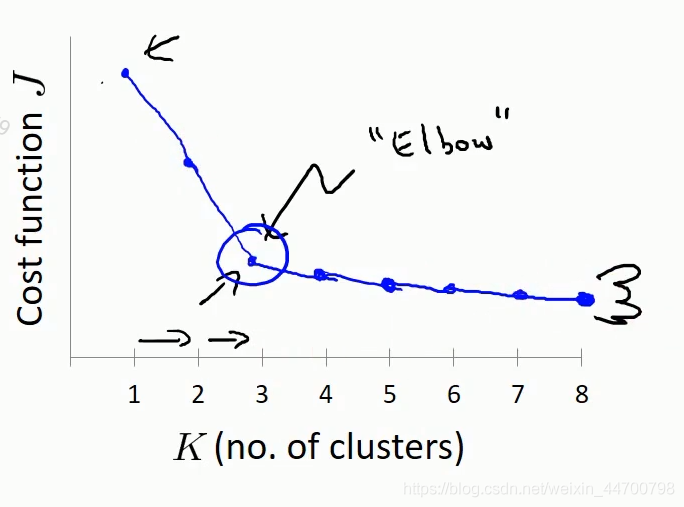
這個就迭代一下k值,然后畫一下影像,比較簡單,由于篇幅的原因,大家自行去實作一下,看看效果,這里就不寫代碼了;
2、metrics.calinski_harabasz_score對應的公式如下:
s
(
k
)
=
t
r
(
B
k
)
t
r
(
W
k
)
m
?
k
k
?
1
s(k) = \frac{tr(B_k)}{tr(W_k)} \frac{m-k}{k-1}
s(k)=tr(Wk?)tr(Bk?)?k?1m?k?
其中m為訓練集樣本數,k為類別數,Bk為類別之間的協方差矩陣,Wk為類別內部資料的協方差矩陣,tr為矩陣的跡,
score越大,代表類別內部資料的協方差越小,類別之間的協方差越大,也就是聚類效果越好,
用上面的資料集測驗一下:
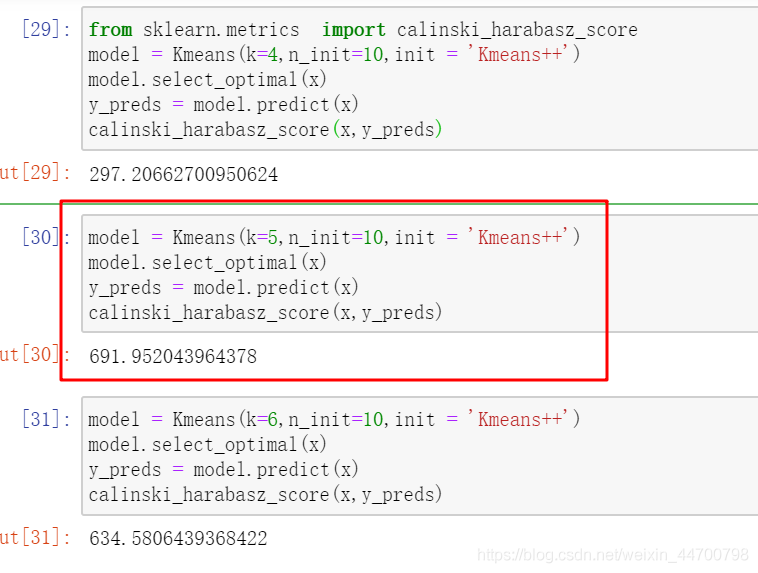
可以看到,K=5的時候,值最大,5就是我們要找的k值,
二、資料量很大時,時間復雜度很高,計算得很慢的問題
1、對距離計算的優化,elkan K-Means,利用了兩邊之和大于等于第三
邊,以及兩邊之差小于第三邊的三角形性質,來減少距離的計算,但是如
果樣本的特征是稀疏的,有缺失值的話,這個方法就不使用了,此時某些
距離無法計算,則不能使用該演算法,
Kmeans里面引數algorithm:有“auto”, “full” or “elkan”,“full”就是普通的歐氏距離,默認"auto",
2、Mini Batch K-Means,Mini Batch,也就是用樣本集中的一部分的樣本
來做K-Means,不再使用全部樣本,這樣可以避免樣本量太大時的計算難
題,演算法收斂速度大大加快,當然此時的代價就是我們的聚類的精確度也
會有一些降低,一般來說這個降低的幅度在可以接受的范圍之內,
sklearn里面直接封裝有MiniBatchKMeans,
這樣,Kmeans演算法的問題,基本上都寫了一下,至于Kmeans只適合處理凸樣本集,不適合處理非凸樣本集,這個問題,怎么解決,我們下一篇文章再寫,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/237239.html
標籤:python