目錄
- 1. CrawlSpider
- 2. Item Loader
- 3. 基本使用
前面幾個小節已經講解的爬蟲都是抓取一個或幾個頁面,然后分析頁面中的內容,這種爬蟲可以稱為專用爬蟲,通常是用來抓取特定頁面中感興趣的內容,例如,某個城市的天氣預報資訊,或特定商品的資訊等,除了專用爬蟲外,還有一類爬蟲應用非常廣泛,這就是通用爬蟲,這種爬蟲需要抓取的頁面資料量通常非常大,例如,像 Google、百度這樣的搜索引擎就是使用這種通用爬蟲抓取了整個互聯網的資料,然后經過復雜的處理,最終將處理過的資料保存到分布式資料庫中,通過搜索引擎查到的最終結果其實是經過整理后的資料,而資料的最初來源是利用通用爬蟲抓取的整個互聯網的資料,但對于大多數人來說,是沒必要抓取整個互聯網的資料的,即使抓取了,這么大量的資料也沒有那么多硬碟來存放,不過為了研究通用爬蟲,可以選擇抓取某個網站的滿足一定規則的資料,本文就會利用通用爬蟲抓取網站中的新聞資料,但在講解如何實作抓取新聞的通用爬蟲前,先要介紹兩個重要的工具:CrawlSpider 和 Item Loader,
1. CrawlSpider
CrawlSpider 是 Scrapy 提供的一個通用爬蟲,CrawlSpider 是一個類,撰寫的爬蟲類可以直接從 CrawlSpider 派生,CrawlSpider 類可以通過指定一些規則讓爬蟲抓取頁面中特定的內容,這些規則需要通過專門的 Rule 指定,爬蟲會根據 Rule 來確定當前頁面中哪些 URL 需要提取,以及是否抓取這些 URL 對應的 Web 頁面,
CrawlSpider 類從 Spider 類繼承,除了擁有 Spider 類的所有方法和屬性外,還提供了一個非常重要的屬性和方法:
(1) rules 屬性:用于指定抓取規則,該屬性是一個串列,可以包含了一個或多個 Rule 物件,每一個 Rule 對抓取頁面的動作都做了定義,CrawlSpider 會讀取 rules 中的每一個 Rule 并進行決議,
(2) parse_start_url 方法:這是一個可重寫的方法,當 start_urls 里對應的 Request 得到 Response 時,該方法被呼叫,通常在 parse_start_url 方法中會分析 Response,該方法必須回傳 Item 物件 或 Request 物件,
在講解 rules 屬性時涉及一個 Rule,這是一個類,該類的構造方法的定義如下:
class Rule:
def __init__(self, link_extractor=None, callback=None, cb_kwargs=None, follow=None,
process_links=None, process_request=None, errback=None):
self.link_extractor = link_extractor or _default_link_extractor
self.callback = callback
self.errback = errback
self.cb_kwargs = cb_kwargs or {}
self.process_links = process_links or _identity
self.process_request = process_request or _identity_process_request
self.process_request_argcount = None
self.follow = follow if follow is not None else not callback
.......
(1) link_extractor:是 LinkExtractor 物件,通過該物件,爬蟲可以知道需要抓取頁面中的哪些 URL,以及在哪個區域提取這些 URL,提取的 URL 會自動生成 Requests 物件,它同時也是一個資料結構,通常用 LxmlLinkExtractor 物件作為引數,LxmlLinkExtractor 類構造方法的定義如下:
class LxmlLinkExtractor(FilteringLinkExtractor):
def __init__(
self, allow=(), deny=(),
allow_domains=(), deny_domains=(),restrict_xpaths=(),
tags=('a', 'area'), attrs=('href',), canonicalize=False, unique=True,
process_value=None, deny_extensions=None,
restrict_css=(), strip=True, restrict_text=None,
):
.....
LxmlLinkExtractor 類通過構造方法傳入一些引數,常用引數的詳細說明如下:
- allow:一個正則運算式或正則運算式串列,該引數定義了當前頁面有哪些 URL 符合提取條件,只有符合這些條件的 URL 才會被提取,
- deny:與 allow 引數相反,滿足 deny 指定的條件的 URL 不會被提取,
- allow_domains:定義了符合要求的域名,只有包含這些域名的 URL 才會被提取,可以用該屬性限定只提取本網站的 URL,
- deny_domains:與 allow_domains 屬性相反,相當于域名黑名單,
- restrict_xpaths:定義了提取 URL 的區域,爬蟲只會提取該屬性指定區域內符合條件的 URL,
- restrict_css:與 restrict_xpaths 屬性的功能類似,只是需要通過 CSS 選擇器指定提取 URL 的區域,
除了這些引數外,還有一些其他引數,但這些引數的使用頻率不高,對這些引數感興趣的讀者可以參考官方檔案的說明,
https://doc.scrapy.org/en/latest/topics/link-extractors.html
(2) callback:回呼函式,每次按照 link_extractor 屬性指定的規則獲取 URL,向服務端發送 Request,獲取 Response 后,就會呼叫 callback 屬性指定的回呼函式,該函式接收一個 Response 物件,表示 Request 回傳的回應結果,callback 函式必須回傳一個包含 Item 物件或 Request 物件的串列,注意,不要使用 parse 作為回呼函式,由于 CrawlSpider 使用 parse 方法來實作其邏輯,如果 parse 方法被覆寫了,那么 CrawlSpider 將會運行失敗,
(3) cb_kwargs:字典型別的引數,包含傳遞給回呼函式的引數值,
(4) follow:布爾型別的引數,其中只能是 True 或 False,該引數指定根據規則從 Response 提取出來的 URL 是否需要跟進,如果 callback 引數值為 None,follow 的默認值是 True,否則默認值是 False,
(5) process_links:指定處理函式,根據規則提取 URL 時該函式會被呼叫,通常在該函式中過濾提取的 URL,
(6) process_request:同樣是處理函式,在根據規則提取 URL 后會自動創建 Request,然后會呼叫該處理函式,通常用于對 Request 進行處理,該函式必須回傳 Request 或 None,
2. Item Loader
Item Loader 提供了一種便捷的機制來幫助用戶方便地創建 Item,它提供了一系列 API 可以分析原始資料,并對 Item 的相應屬性進行賦值,Item 物件時用于保存抓取資料的容器,而 ItemLoader 提供的是填充容器的機制,有了 ItemLoader,提取資料會變得更容易,下面是 ItemLoader 類構造方法的定義,
def __init__(self, item=None, selector=None,
response=None, parent=None, **context):
.....
ItemLoader 類的構造方法包含了若干個引數,下面是對常用引數的說明,
- item:待填充的 Item 物件,通常是 Item 的子類的實體,在 Item 物件中會包含與抓取資料對應的屬性,
- selector:Selector 物件,用來提取填充資料的選擇器,
- response:當前正常處理的 Response 物件,
下面是一個比較典型的使用 ItemLoader 填充 Item 物件的案例:
def parse_item(self, response):
loader = NewsLoader(item=BlogsspiderItem(), response=response)
loader.add_xpath("name", "//div[@id='name']/text()")
loader.add_css('price', 'p#price')
loader.add_value('country', 'China')
return loader.load_item()
在這個案例中,首先創建了 BlogsspiderItem 類的實體,該類的父類是 Item,BlogsspiderItem 類中包含了name、price、country 屬性,分別通過 add_xpath、add_css 和 add_value 方法使用Xpath、CSS 選擇器和值的方式為這 3 個屬性賦值,最后通過 load_item 方法回傳填充后的 Item 物件,
另外,ItemLoader 的每個欄位中都包含了一個輸入處理器(Input Processor)和一個輸出處理器(Output Processor),輸入處理器收到資料時會立刻提取資料,處理結果會被收集起來,并保存在 ItemLoader 中,但不分配給 Item,收集到所有的資料后,load_item 方法被呼叫來用這些資料填充 Item 物件,在呼叫時會先呼叫輸出處理器來處理之 前收集到的資料,然后再保存到 Item 中,這時的 Item 就是最終生成的 Item 物件,下面介紹一些內置的處理器(Processor),
-
Identity 是最簡單的 Processor,不進行任何處理,直接回傳原來的資料,

-
TakeFirst:回傳串列的第一個非空值,也就是回傳第一個不為 None 或空串的串列元素值,通常會作為 Output Processor,實作代碼如下:

-
Join:用于將串列中每個元素首尾相接合成一個字串,每個串列元素之間默認的分隔符是空格,其實 Join 處理器內部呼叫了 Python 內建函式 join 來連接串列中的每一個元素,Join 類的源代碼如下:
class Join: """ Returns the values joined with the separator given in the ``__init__`` method, which defaults to ``' '``. It doesn't accept Loader contexts. When using the default separator, this processor is equivalent to the function: ``' '.join`` Examples: >>> from itemloaders.processors import Join >>> proc = Join() >>> proc(['one', 'two', 'three']) 'one two three' >>> proc = Join('<br>') >>> proc(['one', 'two', 'three']) 'one<br>two<br>three' """ def __init__(self, separator=' '): self.separator = separator def __call__(self, values): return self.separator.join(values) -
Compose:允許將多個處理器或函陣列合在一起使用,Compose 類構造方法的引數允許傳入多個處理器或函式,當前一個處理器或函式處理完,會將結果傳遞給下一個處理器或函式,以此類推,直到執行完最后一個處理器或函式為止,功能有點像 Linux 的管道命令,通過豎線(|)分隔多個命令,前一個命令會將執行結果傳遞給下一個要執行的命令,
>>> from itemloaders.processors import Compose >>> proc = Compose(lambda v: v[0], str.upper) >>> proc(['hello', 'world']) 'HELLO' -
MapCompose:與 Compose 類似,MapCompose 可以迭代處理一個串列輸入值,代碼如下:
>>> def filter_world(x): ... return None if x == 'world' else x ... >>> from itemloaders.processors import MapCompose >>> proc = MapCompose(filter_world, str.upper) >>> proc(['hello', 'world', 'this', 'is', 'something']) ['HELLO', 'THIS', 'IS', 'SOMETHING'] -
SelectJmes:可以通過 key 獲得 JSON 物件的 value,不過需要先安裝 jmespath 庫才可以使用 SelectJmes,pip install jmespath,示例代碼如下:
>>> from itemloaders.processors import SelectJmes, Compose, MapCompose >>> proc = SelectJmes("foo") #for direct use on lists and dictionaries >>> proc({'foo': 'bar'}) 'bar' >>> proc({'foo': {'bar': 'baz'}}) {'bar': 'baz'} Working with Json: >>> import json >>> proc_single_json_str = Compose(json.loads, SelectJmes("foo")) >>> proc_single_json_str('{"foo": "bar"}') 'bar' >>> proc_json_list = Compose(json.loads, MapCompose(SelectJmes('foo'))) >>> proc_json_list('[{"foo":"bar"}, {"baz":"tar"}]') ['bar']
3. 基本使用
1、創建一個工程
scrapy startproject CollegeBeautySpider
2、cd 工程
cd CollegeBeautySpider
3、創建一個基于 CrawlSpider 的爬蟲檔案
scrapy genspider -t crawl SpiderName www.xxx.com
scrapy genspider -t crawl BeautySpider www.xxx.com
校花網 的網頁結構比較簡單,這里就不進行具體的分析,我們只需要抓取校花的名字以及校花照片的鏈接地址,
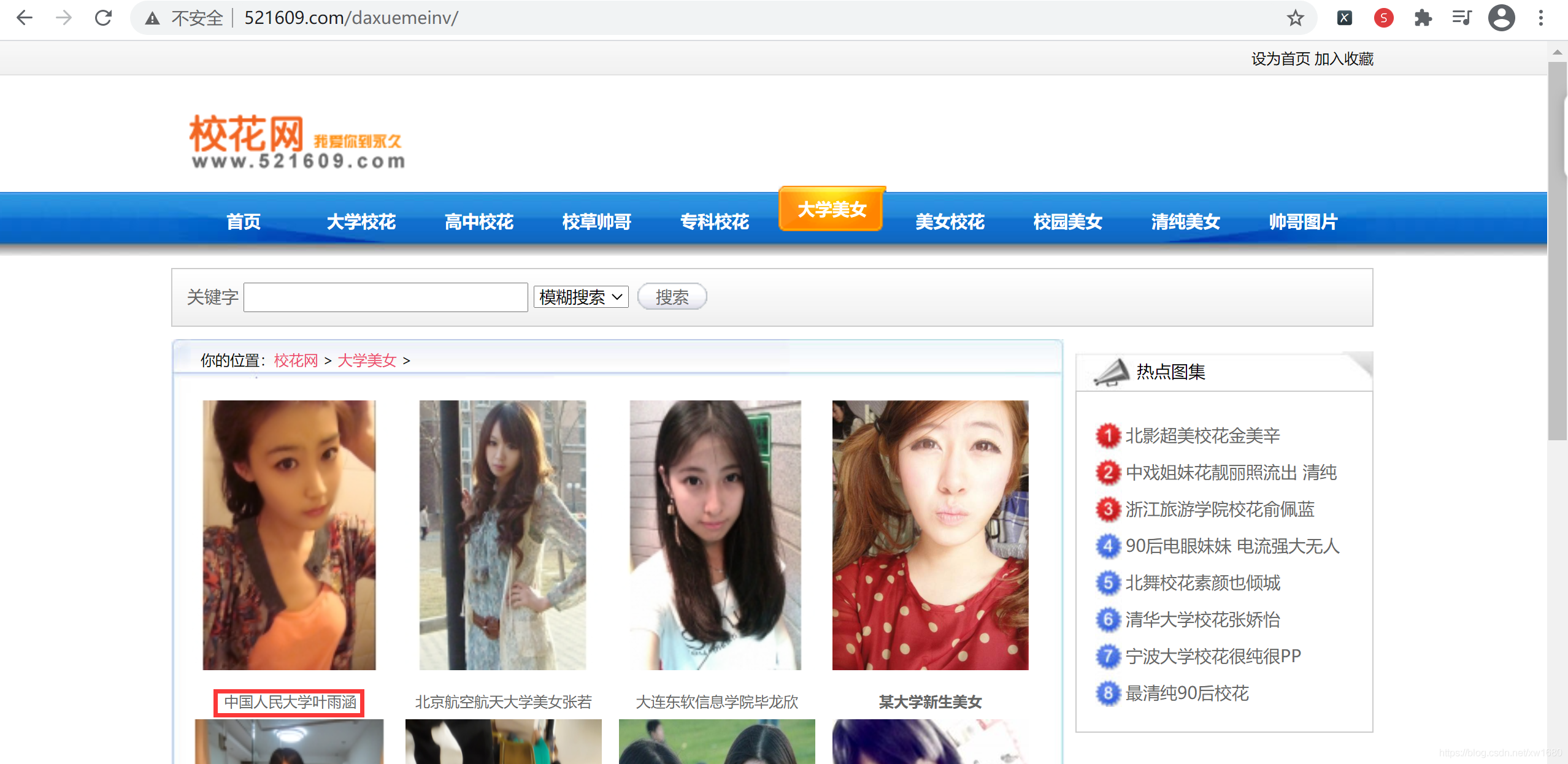
4、在工程根目錄創建一個 main.py 檔案,用于啟動爬蟲檔案,示例代碼如下:
import os
import sys
from scrapy.cmdline import execute
sys.path.append(os.path.dirname(os.path.abspath(__file__)))
execute('scrapy crawl BeautySpider -o beauty.csv'.split())
5、在 items.py 中撰寫 CollegebeautyspiderItem 類,爬蟲需要將抓取的新聞資料放到 Item 物件中,所以要先撰寫一個 CollegebeautyspiderItem 類,該類從 Item 繼承,代碼如下:
import scrapy
class CollegebeautyspiderItem(scrapy.Item):
beauty_name = scrapy.Field() # 美女的名字
beauty_src = scrapy.Field() # 美女圖片的src
6、緊接著在 spiders 檔案夾中的爬蟲檔案 BeautySpider.py 中撰寫抓取邏輯,如下:
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy.loader import ItemLoader
from CollegeBeautySpider.items import CollegebeautyspiderItem
class BeautyspiderSpider(CrawlSpider):
name = 'BeautySpider'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://www.521609.com/daxuemeinv/']
rules = (
Rule(LinkExtractor(allow=r'list\d+\.html'), callback='parse_item', follow=True),
)
# 提取每一個美女的相關資料:名字及圖片的src
def parse_item(self, response):
item_loader = ItemLoader(item=CollegebeautyspiderItem(), response=response)
item_loader.add_xpath("beauty_name", '//div[@class="index_img list_center"]/ul/li/a/img/@alt')
item_loader.add_xpath("beauty_src", '//div[@class="index_img list_center"]/ul/li/a/img/@src')
return item_loader.load_item()
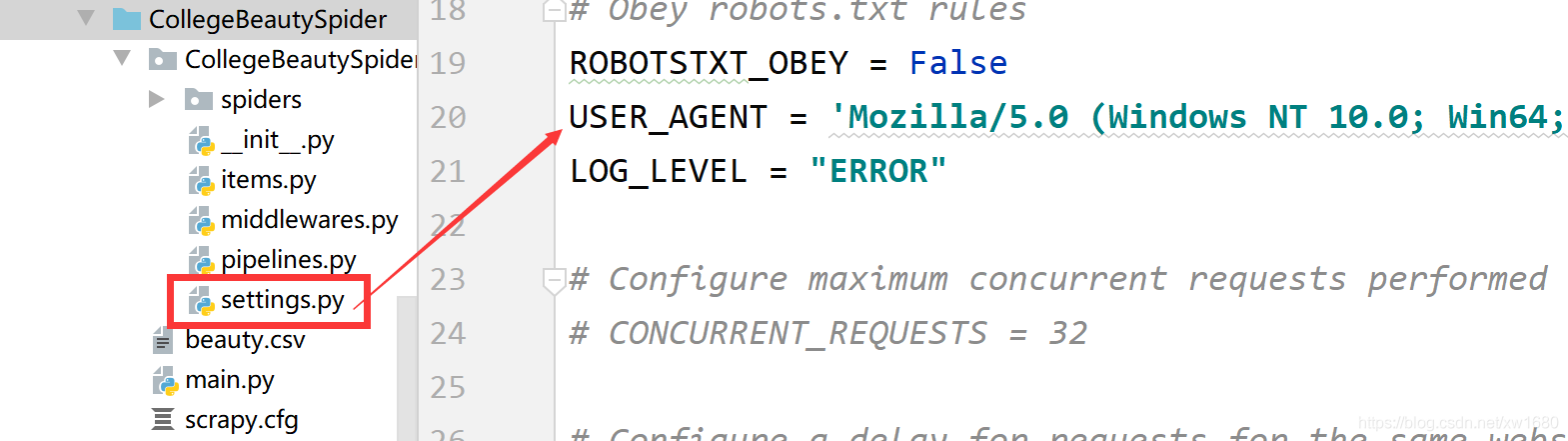
7、在 settings.py 檔案中更改配置資訊
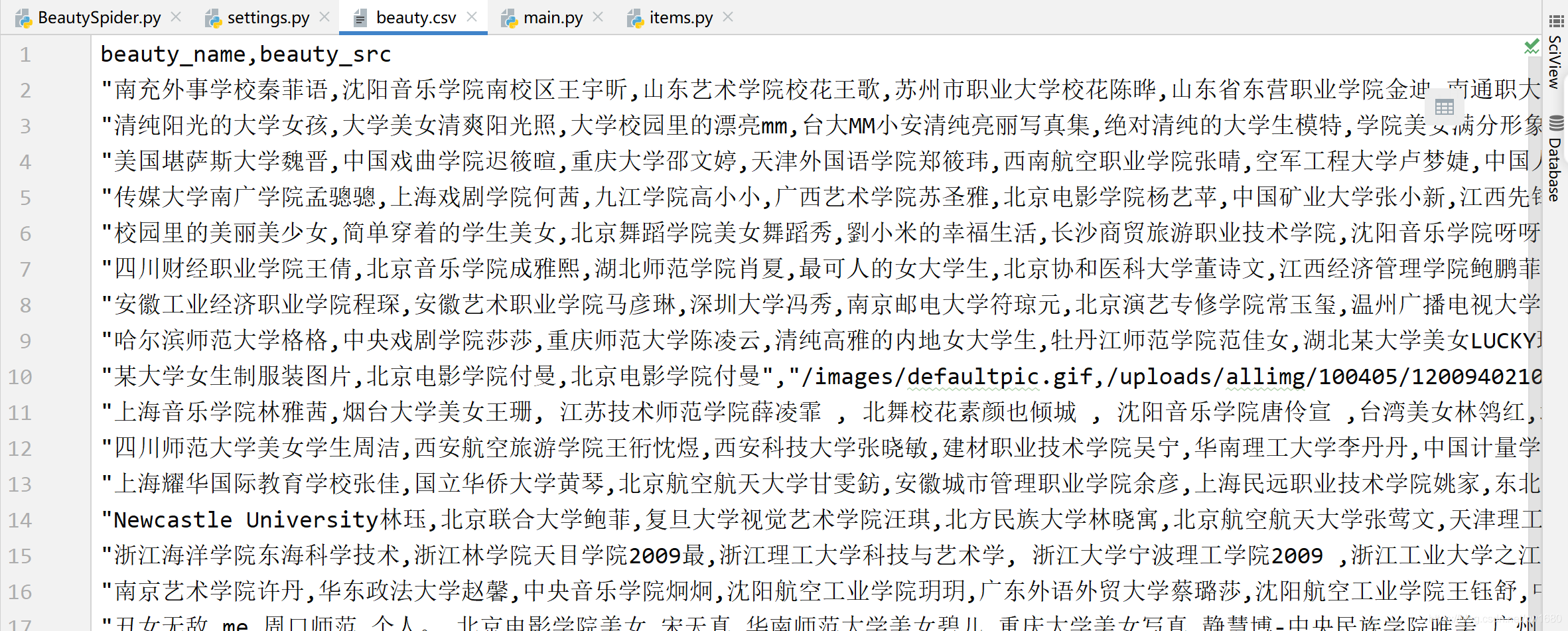
8、執行 main.py 檔案,程式運行結果如下:
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/240063.html
標籤:python
上一篇:深度學習入門篇01(Tensorflow-gpu的安裝)
下一篇:亂數函式