爬取安居客房源資訊
- Xpath插件的安裝
- 爬取重慶花溪附近的房源資訊(進入正題啦~)
- 梳理下邏輯
- 爬取資料的通用流程
- 代碼
- 代碼的問題 & 運行時可能出現的問題
- 結果
- 資料處理部分(寫給我自己噠~)
Xpath插件的安裝
鏈接:https://pan.baidu.com/s/1T3V11Ev8dPODa2fCRbeuCg
提取碼:qvzf
將這個安裝包解壓縮
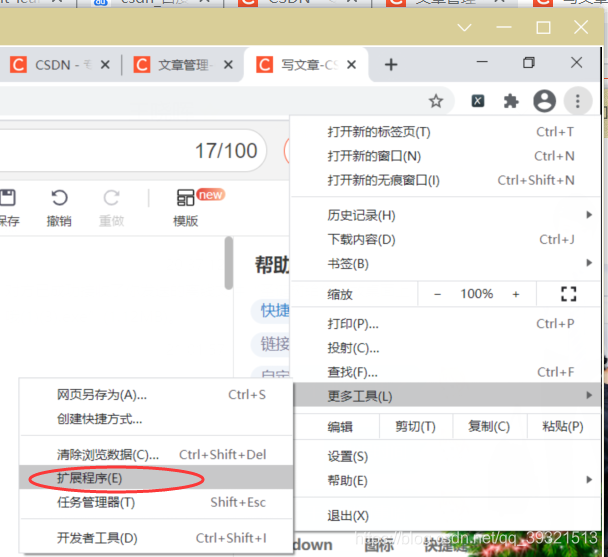
打開谷歌瀏覽器的擴展程式 ----> 打開開發者模式 ----> 點擊加載已解壓的擴展程式 ----> 選擇解壓的檔案夾
看下圖操作
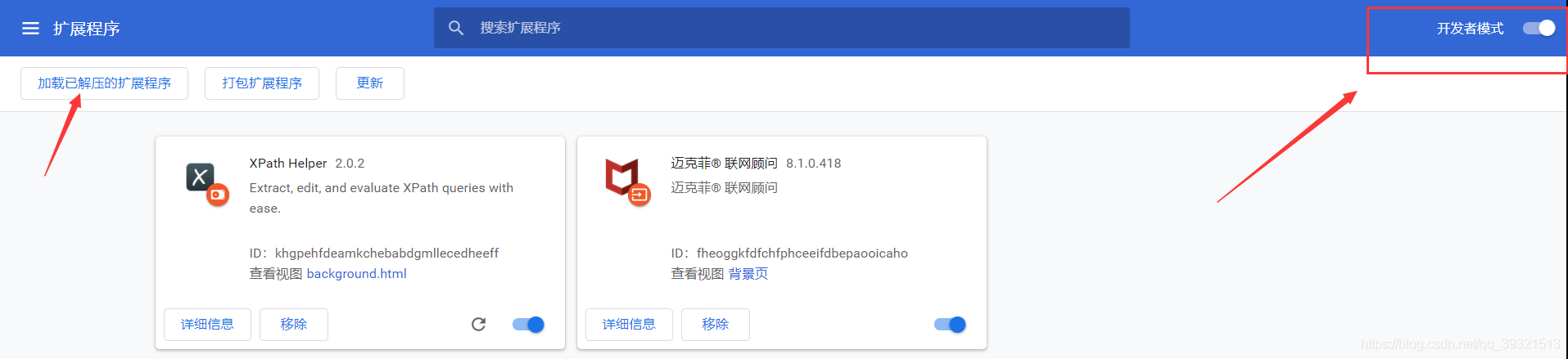
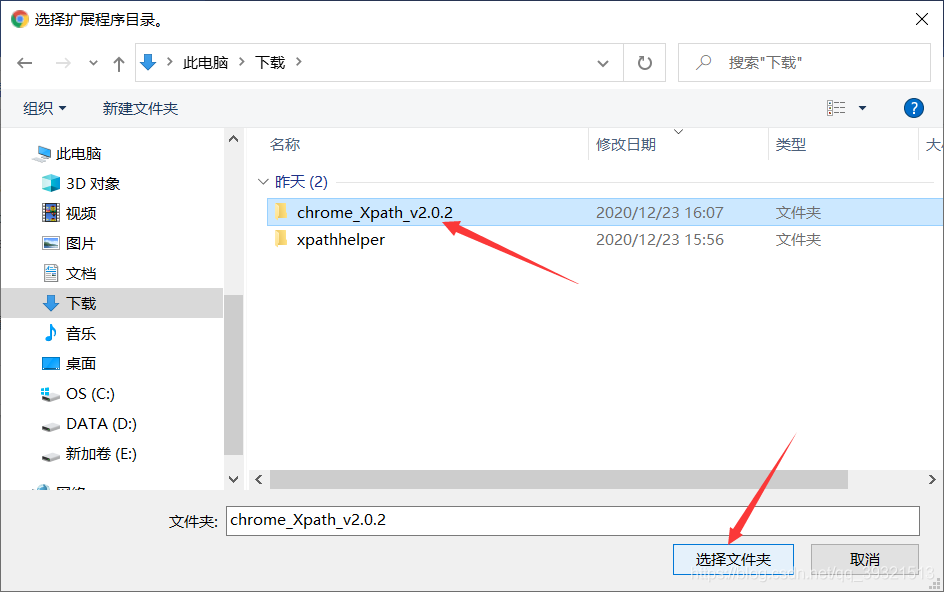
就會出現這個
瀏覽器導航欄上也會出現X圖示
點擊圖示就會彈出 再點擊就會關閉(或者使用快捷鍵ctrl+shift+X) 會出現這樣的黑框 左邊寫Xpath語法 右面是匹配到的結果 還可以看到匹配到的數量

需要自己去學習一下Xpath定位的語法 很簡單的 這里就不贅述了
爬取重慶花溪附近的房源資訊(進入正題啦~)
先看一下頁面的樣子,梳理下邏輯
串列頁頁面
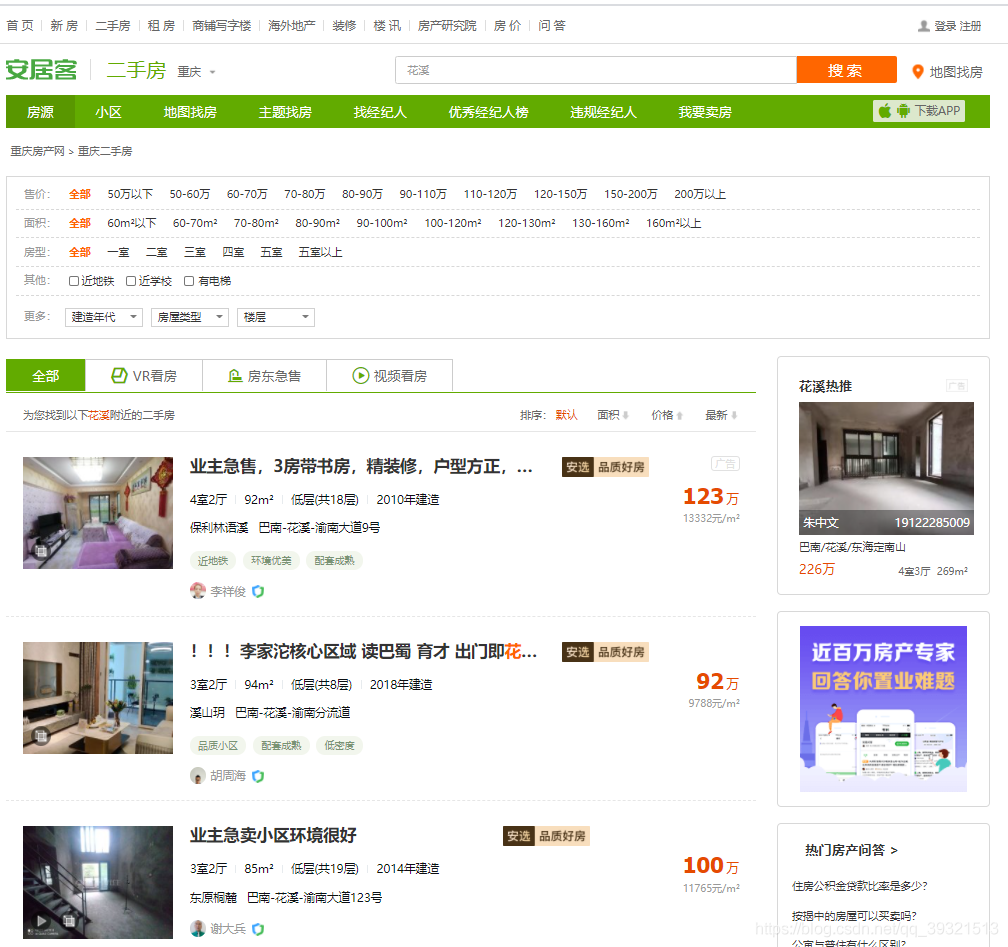
串列頁的分頁按鈕
詳情頁頁面(點擊串列頁標題進入)
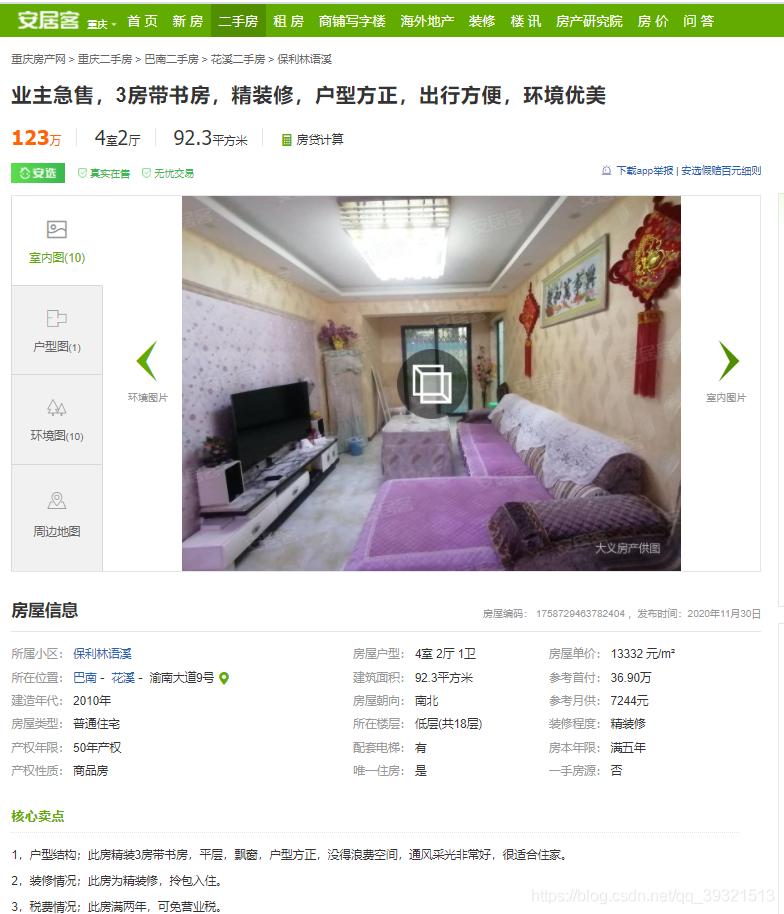
梳理下邏輯
我們先根據分頁獲得某一頁的串列頁,然后爬取串列頁的房價,然后進入詳情頁,爬取詳情頁的下列資訊


爬取資料的通用流程
- 根據url請求頁面,獲取頁面回應物件(也就是下面代碼中的html_obj = requests.get(url=url, headers=headers))
- 將頁面回應物件轉化為etree/parsel物件 (tree = etree.HTML(html_obj))
- 定位要爬取的資料 (tree.xpath(’…’))
- 獲取資料
- 持久化存盤
代碼
終于到了心心念念,激動人心的時刻啦~~ 上代碼!!!哈哈哈
寫了注釋了,不過多解釋
from collections import defaultdict
import requests
import pandas as pd
from lxml import etree
import re
# 獲取到分頁url的一個統一格式
url_all = 'https://chongqing.anjuke.com/sale/p{}-rd1/?kw=%E8%8A%B1%E6%BA%AA#filtersort'
# 請求頭
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
def get_url_list(url):
'''獲取url串列 用于分頁獲取內容'''
url_list = [url.format(i) for i in range(1, 21)] # 獲取20頁
return url_list
def get_page_etree(url, headers):
'''得到頁面的etree物件'''
html_obj = requests.get(url=url, headers=headers)# 根據url請求頁面,獲取頁面回應物件html_obj
html_obj = html_obj.content.decode() # 解決亂碼問題
tree = etree.HTML(html_obj) # 轉化為頁面的etree物件
return tree
def get_data(tree):
"""獲取一頁的房子資料"""
# 建立字典
info_dicts = defaultdict(list)
# 定位到一頁串列頁的所有li標簽
li_list = tree.xpath('//ul[@id="houselist-mod-new"]/li')
for li in li_list: # 遍歷每一條(li標簽) 一個li就對應著一個房子 一個房子的資料全部爬取完再爬取下一個房子,一頁爬取完再爬下一頁
# 串列頁 獲取價格
jiage = li.xpath('./div[@class="pro-price"]//strong/text()')[0]
info_dicts['價格(萬)'].append(jiage)
# 接下來進入詳情頁 獲取其他資料
# 先獲取a鏈接href屬性值 再跳轉到該鏈接進行爬取
a = li.xpath('.//div[@class="house-title"]/a/@href')[0]
# 獲取詳情頁etree物件
tree_i = get_page_etree(url=a, headers=headers)
# 決議資料
hx = tree_i.xpath('//ul[@class="houseInfo-detail-list clearfix"]/li[2]/div[2]/text()')[0].strip().split()
info_dicts['戶型-房間'].append(hx[0])
info_dicts['戶型-廳'].append(hx[1])
info_dicts['戶型-衛生'].append(hx[2])
# 建筑面積
mj = tree_i.xpath('//ul[@class="houseInfo-detail-list clearfix"]/li[5]/div[2]/text()')[0]
info_dicts['建筑面積'].append(mj)
# 朝向
cx = tree_i.xpath('//ul[@class="houseInfo-detail-list clearfix"]/li[8]/div[2]/text()')[0]
info_dicts['朝向'].append(cx)
# 小區
xq = tree_i.xpath('//ul[@class="houseInfo-detail-list clearfix"]/li[1]/div[2]/a/text()')[0].strip()
info_dicts['小區'].append(xq)
# 地址
dz = tree_i.xpath('//ul[@class="houseInfo-detail-list clearfix"]/li[4]/div[2]/p/text()')[1].strip().split()[1]
info_dicts['地址'].append(dz)
# 建筑時間
jzsj = tree_i.xpath('//ul[@class="houseInfo-detail-list clearfix"]/li[7]/div[2]/text()')[0].strip()
info_dicts['建筑時間'].append(jzsj)
# 總樓層 所處層數
str = tree_i.xpath('//ul[@class="houseInfo-detail-list clearfix"]/li[11]/div[2]/text()')[0]
zlc = re.search(r'\d+', str, re.A).group() # 這里用到了正則運算式提取資訊
info_dicts['總樓層'].append(zlc)
cs = re.search(r"['高','中','低']", str, re.U)
if cs is None:
cs = ''
else:
cs = cs.group()
info_dicts['所處層數'].append(cs)
# 裝修
zx = tree_i.xpath('//ul[@class="houseInfo-detail-list clearfix"]/li[12]/div[2]/text()')[0]
info_dicts['裝修'].append(zx)
# 電梯
dt = tree_i.xpath('//ul[@class="houseInfo-detail-list clearfix"]/li[14]/div[2]/text()')[0]
info_dicts['電梯'].append(dt)
data = pd.DataFrame(info_dicts)
return data
# 主程式部分
data = pd.DataFrame()
# 獲取url串列 用于分頁爬取
url_list = get_url_list(url_all)
for i, url in enumerate(url_list):
# 獲取每一頁的串列頁etree物件
tree = get_page_etree(url=url,headers=headers)
# 得到所有資料追加到data中
data = data.append(get_data(tree),ignore_index=True)
print('第',i+1,'頁爬取成功!')
# 持久化存盤
data.to_excel('重慶花溪房源資料.xls')
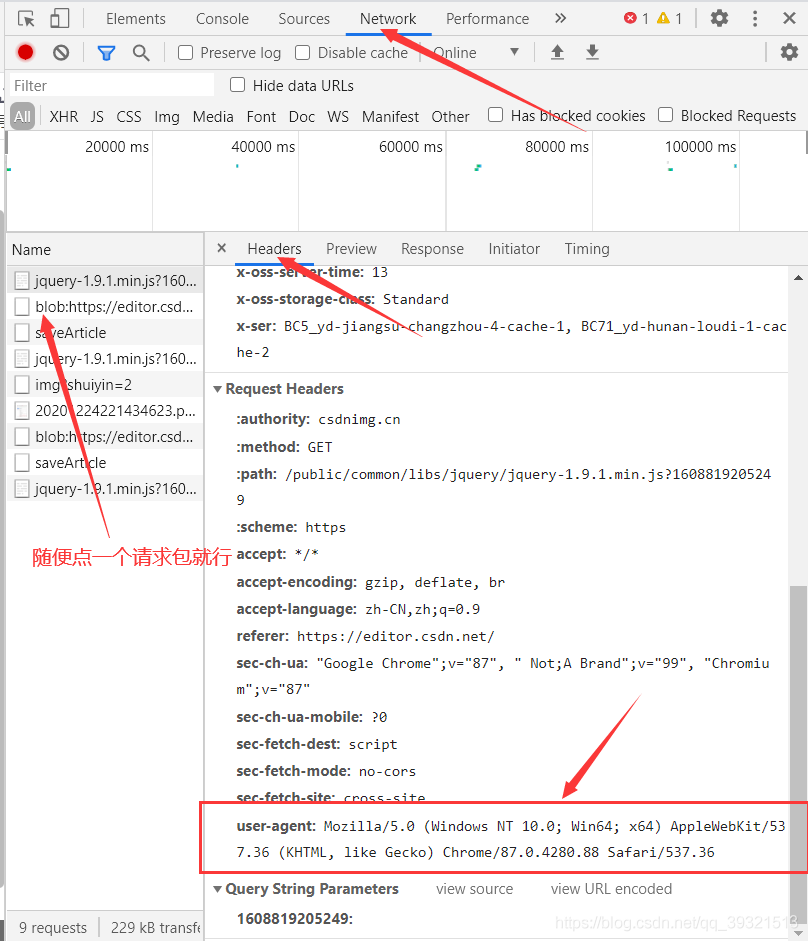
請求頭
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36'
}
這里從這里找,復制 粘貼它
代碼的問題 & 運行時可能出現的問題
存資料是爬到所有資料一次從DataFrame存到excel里,如果資料太大可能記憶體會吃不消,可以自己嘗試下一頁一追加到excel里,我這個20頁(頁數可以改的哈)1200條資料也還可以,資料量不大
如果報錯就從網頁手動訪問頁面,看是不是被人家的系統檢測到你爬取了,就像下面這樣 就換個網 重繪下頁面能訪問到串列頁 再運行程式爬取
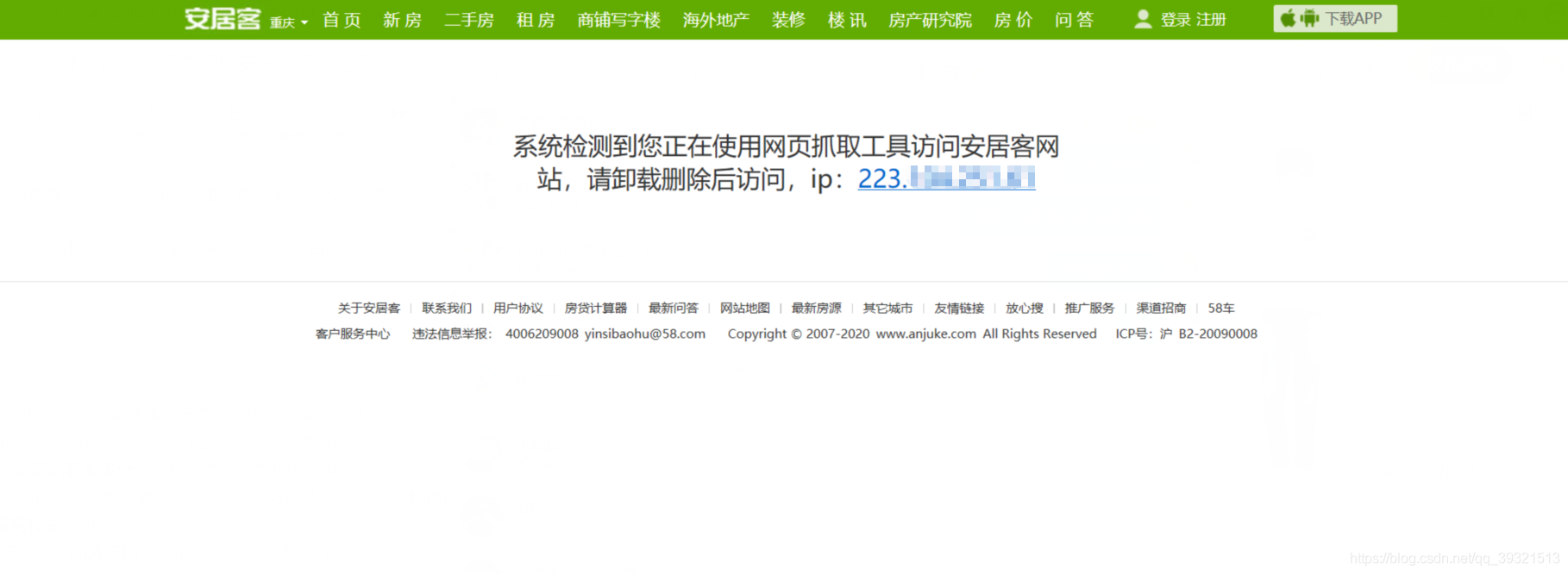
或者可能會出現驗證碼,手動通過驗證碼 ,重繪頁面,再爬取就ok
建議多重繪下頁面試試,能手動的訪問到串列頁一般就能正常爬下資料來
結果
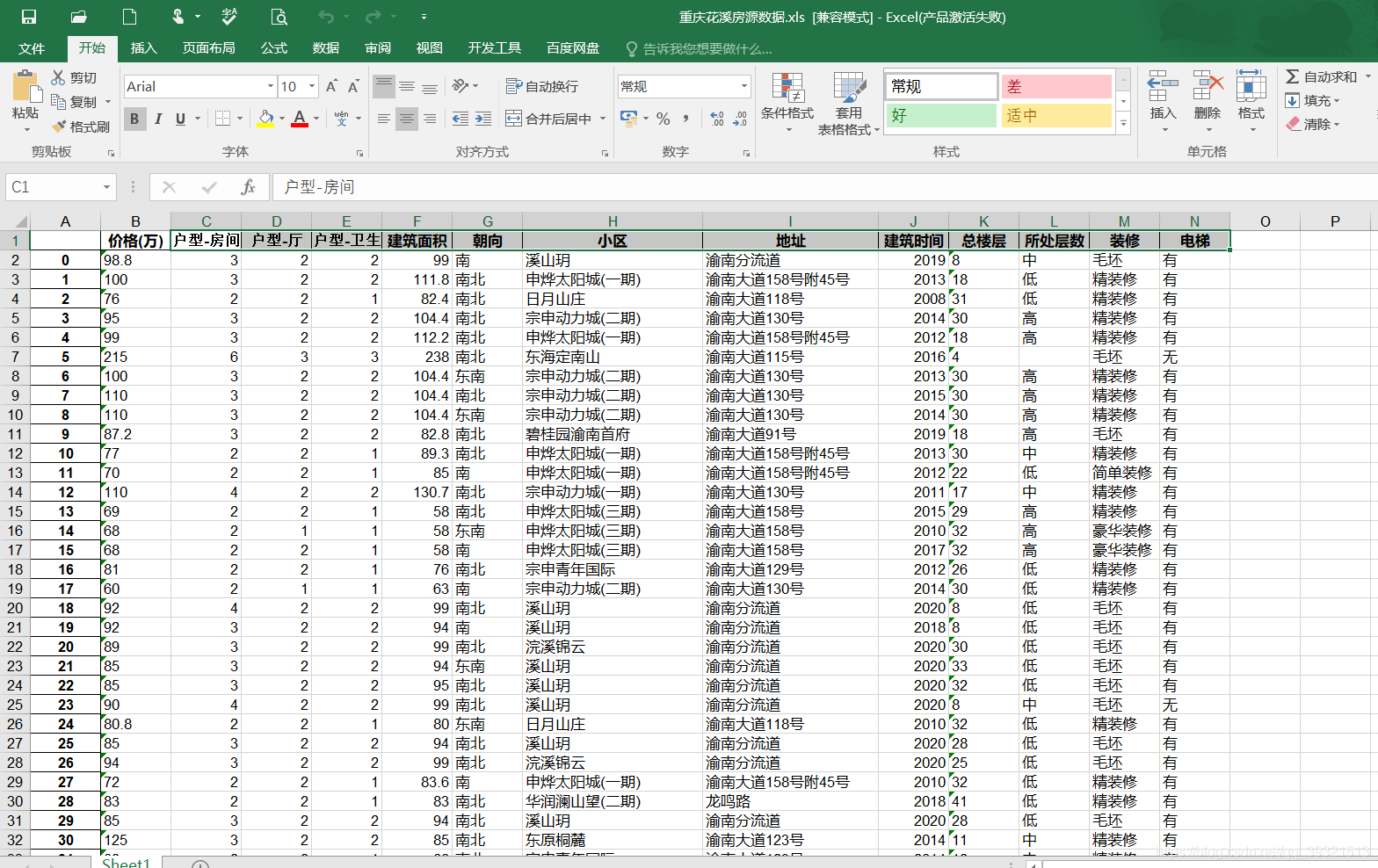
(電梯那一欄 有“滿三年”值 是因為 不是所有房子的詳情頁的是否有電梯那個資料都在同一位置上,他那個格式不是很統一,就會爬錯)
爬蟲學習視頻推薦,我從B站這個視頻學了學,覺得不錯附上鏈接
https://www.bilibili.com/video/BV1Yh411o7Sz?t=825&p=25
xpath語法講挺好的視頻:https://www.bilibili.com/video/BV14K411L7T5 (就是打廣告有點多~~)
加油,你是最胖的,歐耶~~
轉載請附上我的鏈接哦~
歡迎點贊+轉發+評論+討論~~
感謝支持~
資料處理部分(寫給我自己噠~)
import pandas as pd
data = pd.read_excel(r'C:/Users/user/Desktop/housePrice.xls')
# 處理缺失值
data = data.dropna(axis=0,subset=['所處層數'])
# 處理 電梯 例外值
data = data[data['電梯']!='滿三年']
# 字符型改成數值型資料
# 小區
xq = data['小區'].unique()
xq_dict = {value:key for key, value in enumerate(xq)}
print(xq_dict)
data['小區'] = [xq_dict[i] for i in data['小區']]
# 朝向
cx = data['朝向'].unique()
cx_dict = {value:key for key, value in enumerate(cx)}
print(cx_dict)
data['朝向'] = [cx_dict[i] for i in data['朝向']]
# 地址
dz = data['地址'].unique()
dz_dict = {value:key for key, value in enumerate(dz)}
print(dz_dict)
data['地址'] = [dz_dict[i] for i in data['地址']]
# 所處層數
cs = data['所處層數'].unique()
cs_dict = {value:key for key, value in enumerate(cs)}
print(cs_dict)
data['所處層數'] = [cs_dict[i] for i in data['所處層數']]
# 裝修
zx = data['裝修'].unique()
zx_dict = {value:key for key, value in enumerate(zx)}
print(zx_dict)
data['裝修'] = [zx_dict[i] for i in data['裝修']]
# 電梯
dt = data['電梯'].unique()
dt_dict = {value:key for key, value in enumerate(dt)}
print(dt_dict)
data['電梯'] = [dt_dict[i] for i in data['電梯']]
data.to_excel('housePrice.xlsx')
# print(data)
{‘溪山玥’: 0, ‘申燁太陽城’: 1, ‘日月山莊’: 2, ‘宗申動力城’: 3, ‘碧桂園渝南首府’: 4, ‘宗申青年國際’: 5, ‘浣溪錦云’: 6, ‘華潤瀾山望’: 7, ‘東原桐麓’: 8, ‘蕓峰蘭亭’: 9, ‘東海定南山’: 10, ‘曦圓麗景’: 11, ‘保利林語溪’: 12, ‘蔚藍時光’: 13}
{‘南’: 0, ‘南北’: 1, ‘東南’: 2, ‘北’: 3, ‘東’: 4, ‘西南’: 5, ‘東北’: 6, ‘西北’: 7, ‘西’: 8}
{‘渝南分流道’: 0, ‘渝南大道158號附45號’: 1, ‘渝南大道118號’: 2, ‘渝南大道130號’: 3, ‘渝南大道91號’: 4, ‘渝南大道158號’: 5, ‘渝南大道129號’: 6, ‘龍鳴路’: 7, ‘渝南大道123號’: 8, ‘龍洲大道1958號’: 9, ‘渝南大道115號’: 10, ‘青龍灣路’: 11, ‘渝南大道9號’: 12, ‘渝南大道8號’: 13}
{‘中’: 0, ‘低’: 1, ‘高’: 2}
{‘毛坯’: 0, ‘精裝修’: 1, ‘簡單裝修’: 2, ‘豪華裝修’: 3}
{‘有’: 0, ‘無’: 1}
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/240534.html
標籤:python