層次分析法AHP-Analytic Hierarchy Process操作流程及代碼實作
- 前言
- 層次分析法AHP(Analytic Hierarchy Process)的選擇
- 操作流程梳理及控制
- 計算邏輯梳理
- 代碼實作
- 結果展示
“養魚這種事情,請各位渣男渣女自重…”—猴可夫斯基

前言
堅持做一個”技術“搬運工,總結互相學習成長,專案中遇到一個給出評估分的需求,一開始會想到分數用類似評分卡模型(logit),或者分類模型用于給評定級別,但是這兩種都屬于監督學習范疇,我們遇到的情況是壓根也沒有監督值,甚至需要我們去創造出一個監督值,于是在美麗的PMO小姐姐的建議下,我們決定使用AHP層次分析法來創造一個分數,并在最終結果中加以修改調整成預期結果,
層次分析法AHP(Analytic Hierarchy Process)的選擇
AHP層次分析法是一種定性、定量相結合的系統化、層次化的分析方法,與傳統的統計學模型不同,它其實是基于專家經驗主觀的一種權重決策的方法,
舉個例子,加入我們想要決定一個人的違約概率,我們可以選用評分卡模型,跑Logit,或者分類模型去預測和描述一種關系或規則,然而,這種監督學習的機器學習方法,需要我們有足夠大量的歷史真實資料進行訓練,我們在現實作業中,連一個Y值都沒有,甚至是需要創造一個Y值,而當業務實質具有強經驗導向時,我們不妨采用AHP層次分析法,對專家給予個模塊指標的評分作為我們計算權重的依據,并進行相關測驗和校驗,
AHP的優點:
- 不依賴歷史客觀資料,
- 強化專家經驗,以最簡便的代價得到相對比較符合規則的指標權重或評分,
AHP的缺點:
- 依賴專家主觀經驗,是一種模糊的籠統的計算方法,當詢問的專家經驗不足時,會造成偏差,卻又無法驗證,
- 當指標過多時,會在實際操作中引起專家的方案導致收集到的評價有偏,
- 過于關注矩陣一致性檢驗,而不是合理性的探究,
操作流程梳理及控制
- 構建層次體系,分為:總目標,目標層,方案層(指標),
- 收集清洗相關指標,并制作相關調查問卷或訪談計劃,
- 選擇調查訪談的target人群,一般為專家或經驗豐富的相關經驗接觸者,
- 針對指標讓target人群進行評價,
- 制作矩陣,并計算驗證,求取矩陣特征值,
- 得到最終結論,并加以修正,
計算邏輯梳理
step1: 構建層次結構模型
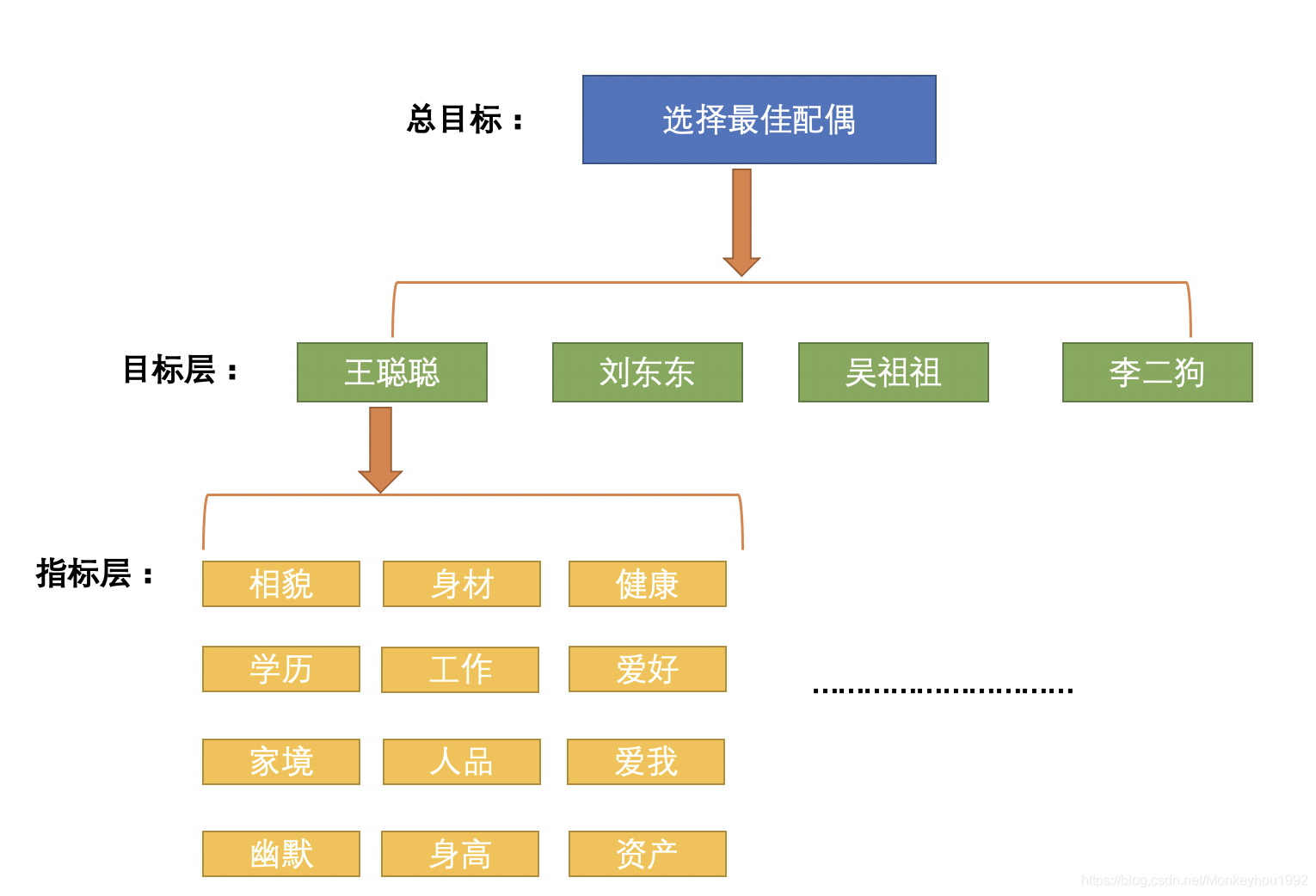
作為一名資深的魚塘養殖戶,張翠花小姐精心從她所養的魚塘中挑選了以上四位候選者,王聰聰、劉冬冬、吳祖祖和李二狗,但是她很糾結,這三位備胎到底選擇哪一位轉正,于是翠花女士與其閨蜜進行了一次頭腦風暴茶話會,羅列出了以下幾個備選指標,作為她考量選哪位備胎轉正的量化依據,但是,由于翠華女士養魚多年,在各大指標中已經迷失了自我,無法得到令自己信服的選擇,
于是乎,翠花女士像30位資深魚塘養殖戶發送了針對以上指標調查問卷,希望他們給出大家心中最好的評判標準,
step2: 構造互反矩陣
翠花女士按照層次結構模型,從上到下逐層構造判斷矩陣,每一層元素都以相鄰上一層次各元素為準則,按1-9標度方法兩兩比較構造判斷矩陣,換而言之,讓養魚專家們對這一坨指標進行兩兩打分,
打分標準如下:
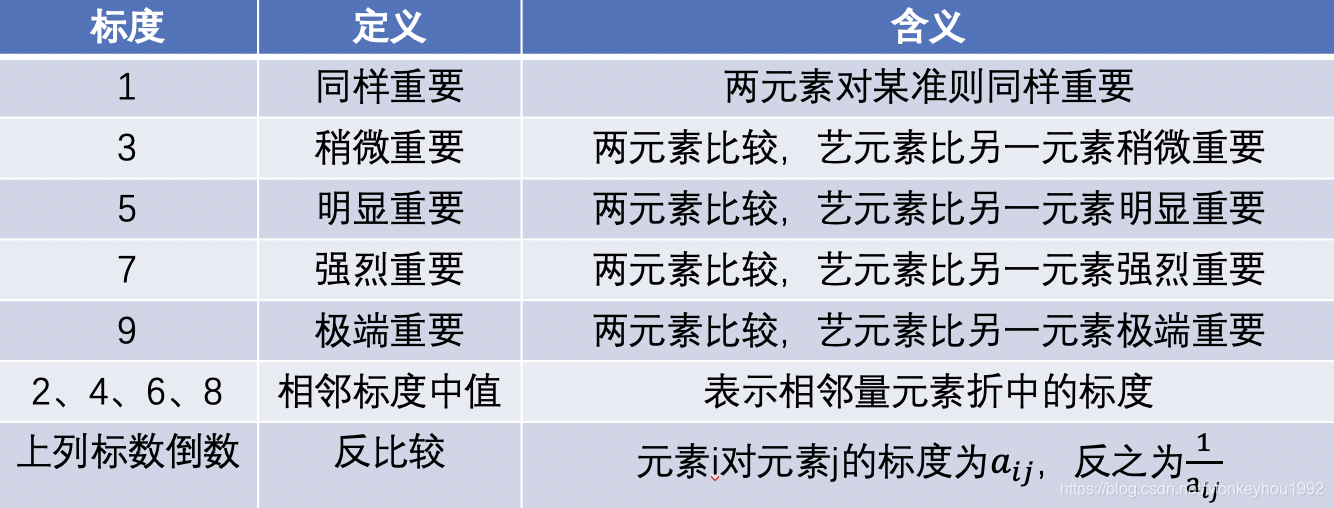
根據養魚專家們的經驗,參考上述評分標準,我們得到了以下矩陣:
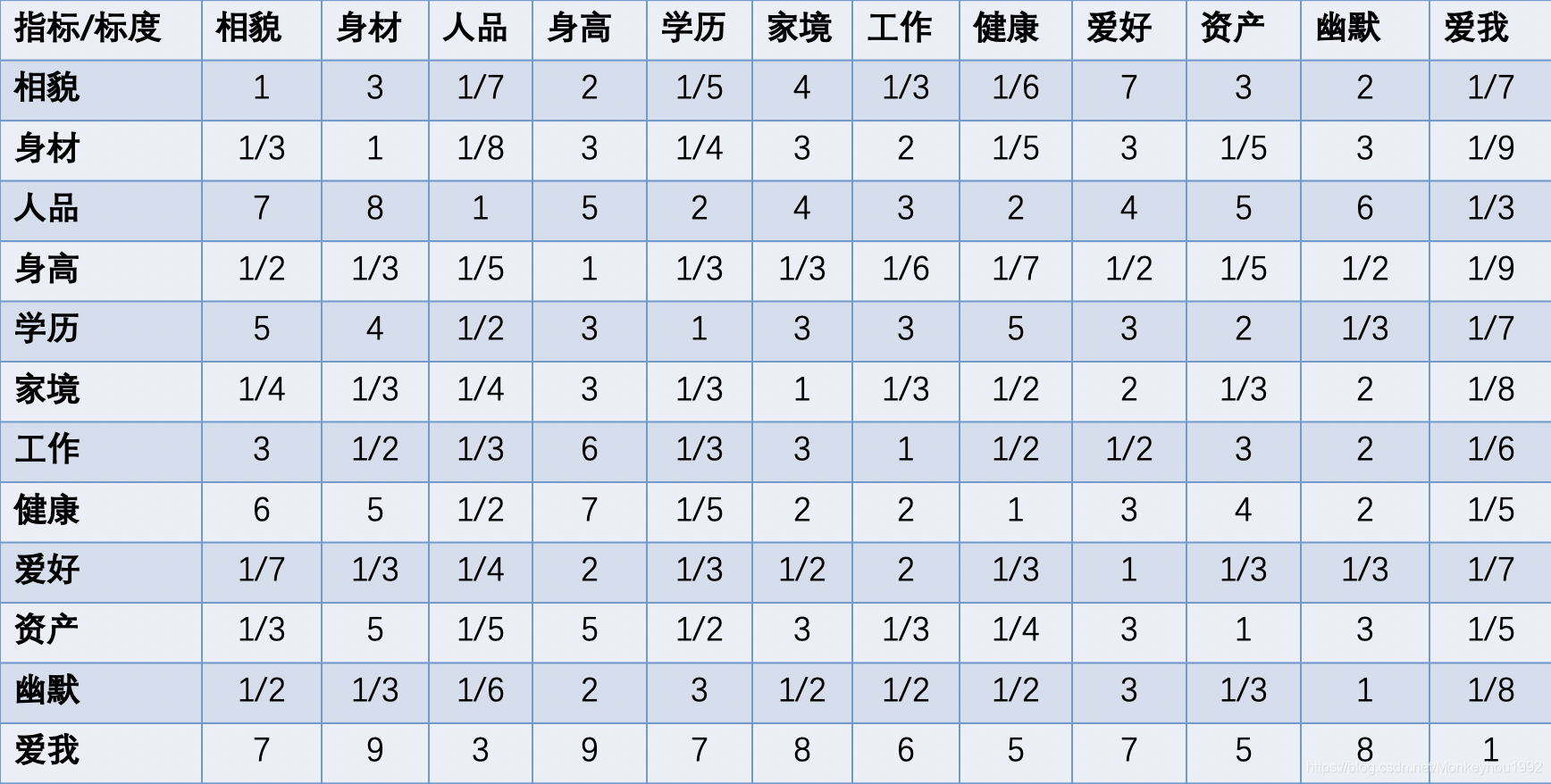
step3: 一致性檢驗
所謂一致性檢驗,簡單講就是,兩兩指標的協調性,我們認為a比不重要,b比c重要,那么一致性便是a比c也要重要,定義與公式如下:

當然,我們可以通過求出最大特征根及其對應的特征向量,并將特征向量進行歸一化,
將判斷矩陣(正反陣)A的所有列向量歸一化,后將每個行向量求和,并進行歸一化處理得列向量W(權向量/特征向量),
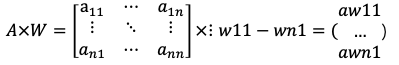
最大特征根為:
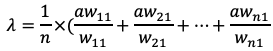
進行一致性檢驗:
CI(一致性指標)=(最大特征根-維度)/(維度-1)
其值與一致性程度成反比,
RI(隨機一致性指標,由維度判斷)
初始化RI值,用于一致性檢驗:
RI_list = [0, 0, 0.58, 0.90, 1.12, 1.24, 1.32, 1.41, 1.45]
計算后的CI值,如果<0.1,則視為通過一致性檢驗,否則需要調整矩陣引數,
代碼實作
python計算邏輯,首先指標比較少的情況,不需要呼叫tensorflow,此外,如果有多層指標情況出現,需要多層次迭代計算權重與最大特征值,
import numpy as np
import pandas as pd
class AHP:
# 傳入的np.ndarray是的判斷矩陣
def __init__(self, dataframe, result=None):
# 哪種方法
self.re = result
# 傳入矩陣
self.df = dataframe
if self.re == 'v1':
# 排序形成的字典 # 結果展示
self.m = self.createdict()
self.array = self.matrix1()
# 記錄矩陣大小
self.n = self.matrix1().shape[0]
elif self.re =='v2':
self.array = self.matrix2()
# 記錄矩陣大小
self.n = len(self.df.index)
# 初始化RI值,用于一致性檢驗
RI_list = [0, 0, 0.58, 0.90, 1.12, 1.24, 1.32, 1.41, 1.45]
self.RI = RI_list[self.n - 1]
# 轉換矩陣用于計算
def matrix1(self):
name = []
for key in self.m:
name.append(key)
values = []
for item in name:
values.append(self.m[item])
mylist = []
for i in range(len(values)):
alist = []
for j in range(len(values)):
temp = values[i]/values[j]
alist.append(temp)
mylist.append(alist)
array = np.array(mylist)
return array
# 生成輸入條件
def createdict(self):
my_dict = {}
print('標度1:同樣重要;標度3:稍微重要;標度5:明顯重要;標度7:強烈重要;標度9:極端重要;標度2、4、6、8:臨界重要性中值')
for item in data.columns.to_list()[1:]:
print('===============================')
print('請輸入'+str(item)+'的排序重要性!')
my_dict[item] = float(input())
print('===============================')
print('請輸入想要的計算結果:評估分or評估等級')
result = str(input())
return my_dict
# 轉換矩陣用于計算
def matrix2(self):
n = len(self.df.index)
alist = []
for i in range(n):
temp = list(data.T[i])[1:]
alist.append(temp)
return alist
# 獲取最大特征值和對應的特征向量
def get_eig(self):
# numpy.linalg.eig() 計算矩陣特征值與特征向量
eig_val, eig_vector = np.linalg.eig(self.array)
# 獲取最大特征值
max_val = np.max(eig_val)
max_val = round(max_val.real, 6)
# 通過位置來確定最大特征值對應的特征向量
index = np.argmax(eig_val)
max_vector = eig_vector[:, index]
max_vector = max_vector.real.round(6)
# 添加最大特征值屬性
global m
maxval = max_val
# 計算權重向量W
weight_vector = max_vector / sum(max_vector)
weight_vector = weight_vector.round(6)
# 列印結果
print("最大的特征值: " + str(max_val))
print("對應的特征向量為: " + str(max_vector))
print("歸一化后得到權重向量: " + str(weight_vector))
return weight_vector, maxval
# 測驗一致性
def changjiajun(self):
# 計算CI值
if self.re == 'v1' or self.re =='v2':
maxval = self.get_eig()[1]
CI = (maxval - self.n) / (self.n - 1)
CI = round(CI, 6)
# 列印結果
print("判斷矩陣的CI值為" + str(CI))
print("判斷矩陣的RI值為" + str(self.RI))
# 分類討論
if self.n == 2:
print("僅包含兩個子因素,不存在一致性問題")
else:
# 計算CR值
CR = CI / self.RI
CR = round(CR, 6)
# CR < 0.10才能通過檢驗
if CR < 0.10:
print("判斷矩陣的CR值為" + str(CR) + ",通過一致性檢驗")
vector = self.get_eig()[0]
return True
else:
print("判斷矩陣的CR值為" + str(CR) + ",未通過一致性檢驗")
return False
else:
print('請輸入正確的版本v1、v2!')
"""
input
"""
if __name__=='__main__':
data = pd.read_excel('養魚專業戶.xlsx')
# V1的方法為對所有中間指標排序 V2是直接匯入無反矩陣(兩兩比較的值)@常老師,她清楚
AHP(data,result='v1').changjiajun()
注意!
這份代碼是之前專案使用過的正路版本,v1引數是當專家亂寫經驗指標評分或者是種無法通過一致性檢驗時使用,v2引數便是兩兩標度的原始版本,
結果展示
翠花的結果:
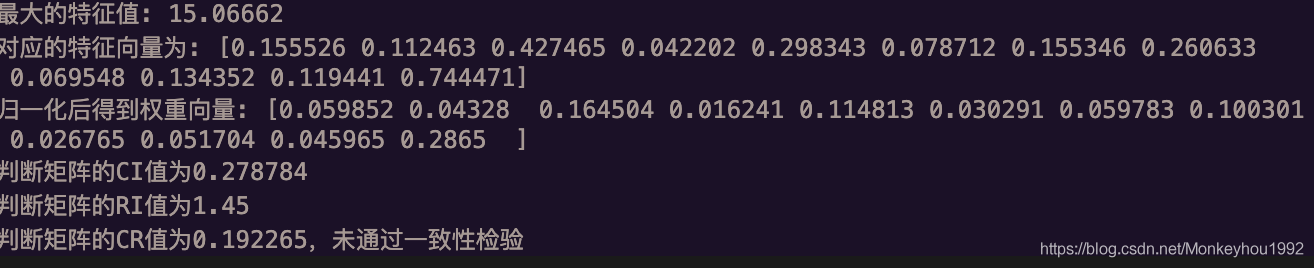
不難看出,在閨蜜的眼中,愛我、人品、健康的權重很高,而家境和資產是嘴不重要的指標,
因此,根據四個備胎的具體指標進行權重加總,翠花應當選擇李二狗同學,
…
…
然而,最終翠花選擇了王聰聰,
課后思考,這印證了AHP歸于強調矩陣一致性,而忽略了合理性探究,基于專家經驗的結果,并不能指導最終目標的選擇,

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/241018.html
標籤:python