Python爬蟲入門學習實踐——爬取小說
前言
本學期開始接觸python,python是一種面向物件的、解釋型的、通用的、開源的腳本編程語言,我覺得python最大的優點就是簡單易用,學習起來比較上手,對代碼格式的要求沒有那么嚴格,這種風格使得我在撰寫代碼時比較舒適,爬蟲作為python的最為吸引我興趣的一個方面,在學習之后可以幫助我們方便地獲取更多的資料源,從而進行更深層次更有效的資料分析,獲得更多的價值,
爬取小說思路
首先我們肯定是對小說網站進行觀察,辨別小說網站是靜態還是動態的,此次爬取的目標是筆趣閣網站https://www.xsbiquge.com(這里發現網址與上次爬取時的網址有所變化),任一點開一本小說的任一章節通過F12的Elements選項可以檢查到文章內容存在于 div id=‘content’ 標簽中,所以說爬取的目標是靜態的,當然,有人會問,使用動態的Selenium可以爬取嗎?答案是肯定的,當然網站是靜態的我們就沒有必要舍近求遠的使用動態方法求得結果,
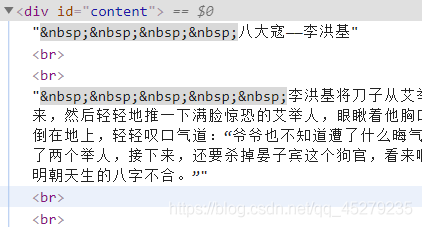
然后選取目標小說之后,點擊小說目錄頁面,通過F12的Elements選項可以觀察到小說所有章節的url都是有規則的,
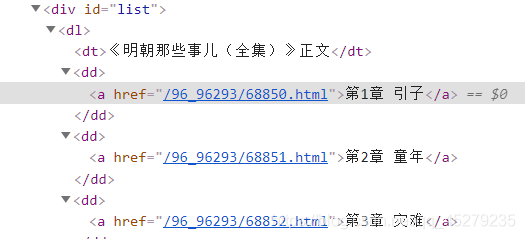
爬取到所有章節的url之后保存,對獲取的章節url進行完善之后在進入每一章節對標題和正文內容進行爬取,最后保存到txt檔案當中,
功能模塊實作
理清我們的思路之后,按照步驟一步一步完成功能,
1.使用request請求庫和資料清洗匹配的re庫
import requests
import re
2.對目標網站發送url請求
s = requests.Session()
url = 'https://www.xsbiquge.com/96_96293/'
html = s.get(url)
html.encoding = 'utf-8'
3.對網站目錄頁查找所有章節的url
# 獲取章節
caption_title_1 = re.findall(r'<a href="(/96_96293/.*?\.html)">.*?</a>',html.text)
4.對獲取所有章節的url進行完善方便再次訪問
for i in caption_title_1:
caption_title_1 = 'https://www.xsbiquge.com'+i
5.對獲取的每一張url進行訪問尋找標題和正文內容
s1 = requests.Session()
r1 = s1.get(caption_title_1)
r1.encoding = 'utf-8'
# 獲取章節名#meta是head頭檔案中的內容,用這個獲取章節名
name = re.findall(r'<meta name="keywords" content="(.*?)" />',r1.text)[0]
print(name)
#這里print出章節名,方便程式運行后檢查文本保存有無遺漏
chapters = re.findall(r'<div id="content">(.*?)</div>',r1.text,re.S)[0]

6.對獲取的正文內容進行清洗
chapters = chapters.replace(' ', '')
chapters = chapters.replace('readx();', '')
chapters = chapters.replace('& lt;!--go - - & gt;', '')
chapters = chapters.replace('<!--go-->', '')
chapters = chapters.replace('()', '')
# 轉換字串
s = str(chapters)
#將內容中的<br>替換
s_replace = s.replace('<br/>',"\n")
while True:
index_begin = s_replace.find("<")
index_end = s_replace.find(">",index_begin+1)
if index_begin == -1:
break
s_replace = s_replace.replace(s_replace[index_begin:index_end+1],"")
pattern = re.compile(r' ',re.I)#使匹配對大小寫不敏感
fiction = pattern.sub(' ',s_replace)
7.將資料保存到預先設定的txt中
path = r'F:\title.txt' # 這是我存放的位置,你可以進行更改
#a是追加
file_name = open(path,'a',encoding='utf-8')
file_name.write(name)
file_name.write('\n')
file_name.write(fiction)
file_name.write('\n')
#保存完之后關閉
file_name.close()
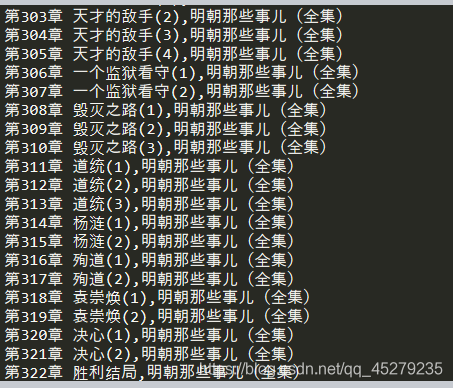
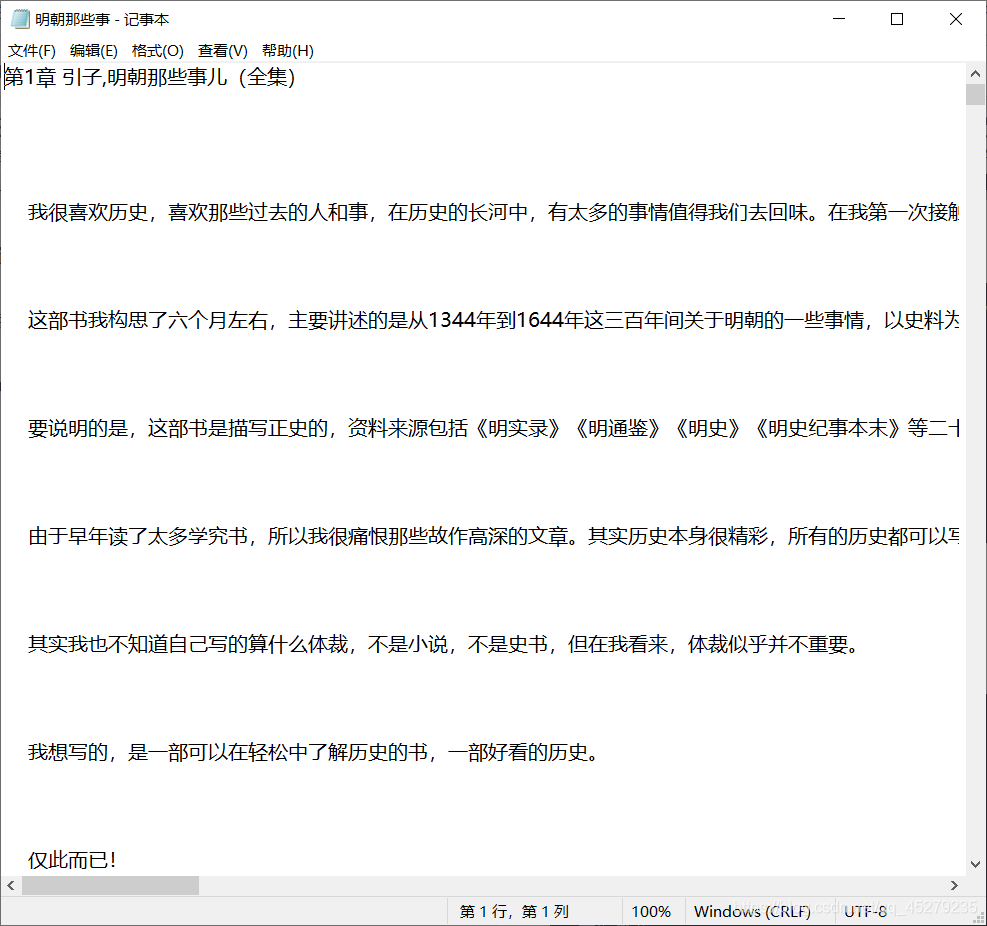
運行結果
程式原始碼
import requests
import re
s = requests.Session()
url = 'https://www.xsbiquge.com/96_96293/'
html = s.get(url)
html.encoding = 'utf-8'
# 獲取章節
caption_title_1 = re.findall(r'<a href="(/96_96293/.*?\.html)">.*?</a>',html.text)
# 寫檔案+
path = r'F:\title.txt' # 這是我存放的位置,你可以進行更改
#a是追加
file_name = open(path,'a',encoding='utf-8')
# 回圈下載每一張
for i in caption_title_1:
caption_title_1 = 'https://www.xsbiquge.com'+i
# 網頁源代碼
s1 = requests.Session()
r1 = s1.get(caption_title_1)
r1.encoding = 'utf-8'
# 獲取章節名
#meta是head頭檔案中的內容,用這個獲取章節名
name = re.findall(r'<meta name="keywords" content="(.*?)" />',r1.text)[0]
print(name)
file_name.write(name)
file_name.write('\n')
# 獲取章節內容
#re.S在字串a中,包含換行符\n,在這種情況下:
#如果不使用re.S引數,則只在每一行內進行匹配,如果一行沒有,就換下一行重新開始,而使用re.S引數以后,正則運算式會將這個字串作為一個整體,在整體中進行匹配,
chapters = re.findall(r'<div id="content">(.*?)</div>',r1.text,re.S)[0]
#換行
chapters = chapters.replace(' ', '')
chapters = chapters.replace('readx();', '')
chapters = chapters.replace('& lt;!--go - - & gt;', '')
chapters = chapters.replace('<!--go-->', '')
chapters = chapters.replace('()', '')
# 轉換字串
s = str(chapters)
#將內容中的<br>替換
s_replace = s.replace('<br/>',"\n")
while True:
index_begin = s_replace.find("<")
index_end = s_replace.find(">",index_begin+1)
if index_begin == -1:
break
s_replace = s_replace.replace(s_replace[index_begin:index_end+1],"")
pattern = re.compile(r' ',re.I)#使匹配對大小寫不敏感
fiction = pattern.sub(' ',s_replace)
file_name.write(fiction)
file_name.write('\n')
file_name.close()
- 關于 re 使用,參考 這兒,
總結
程式代碼實作了爬取小說的功能,對資料進行了清洗,但這只是對一本小說進行爬取,如果想對全站小說進行爬取,可以在功能模塊上再添加一個大的回圈獲取網站所有小說的url就可以實作了,這是我的想法以及實作,如果你有其他的思路,可以評論交流一下,大家互相學習進步,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/241023.html
標籤:python