以此為例
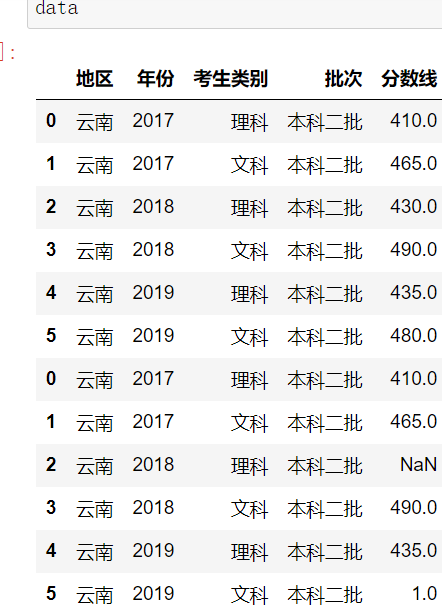
一.重復資料處理
1.drop_duplicates
| 引數名 | 接收 | 意義 | 默認 |
|---|---|---|---|
| subset | String / sequence | 去重的序列 | None(全部列) |
| keep | String | 重復時保留第幾個資料 first :保留第一個 last :保留最后一個 false :不保留 |
first(保留第一個) |
| inplace | Boolean | 是否在原表上操作 | False |
DataFrame.drop_duplicates()
示例
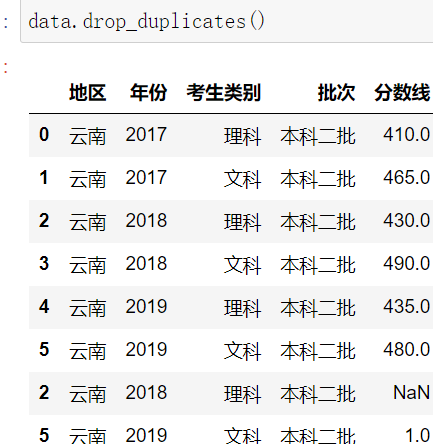
二.缺失值處理
1.dropna洗掉法(減少樣本)
| 引數名 | 接收 | 意義 | 默認 |
|---|---|---|---|
| axis | 0/1 | 0為洗掉記錄特征為行 1為洗掉記錄特征為列 |
0 |
| how | String | any只要存在缺失就洗掉 all全部缺失才洗掉 |
any |
| subest | array | 進行去重的行/列 | None |
| inplace | Boolean | 是否在原表上操作 | Flash |
DataFrame.dropna()
示例
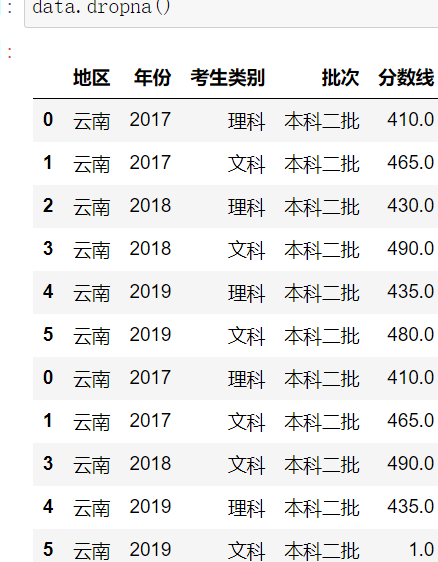
2.fillna替換法(影響標準差)
| 引數名 | 接收 | 意義 | 默認 |
|---|---|---|---|
| value | Scalar dict series Dataframe |
表示用于替換的值 | 無 |
| method | Stirng | Backfill/bfill 使用下一個缺失值來填補 Pad/ffil使用上一個缺失值填補 |
None |
| axis | 0/1 | 軸向 | 1 |
| inplace | Boolean | 是否原表操作 | False |
| limit | Int | 填補缺失值的個數上限 | None |
DataFrame.fillna()
示例
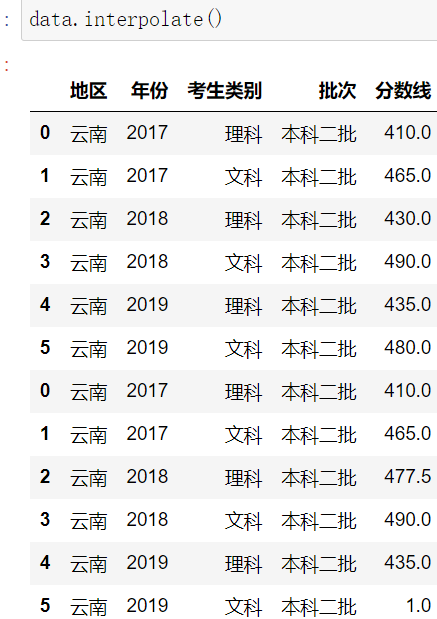
3.interpolater()插值法
| 引數method選擇添加 | 引數 |
|---|---|
| 默認 | 'Linear' |
| 資料增長速率越來越快 | 'quadratic' |
| 資料集呈現出累計分布 | 'pchip' |
| 平滑繪圖為目標 | 'akima' |
DataFrame.interpolater()
示例
三.例外值處理
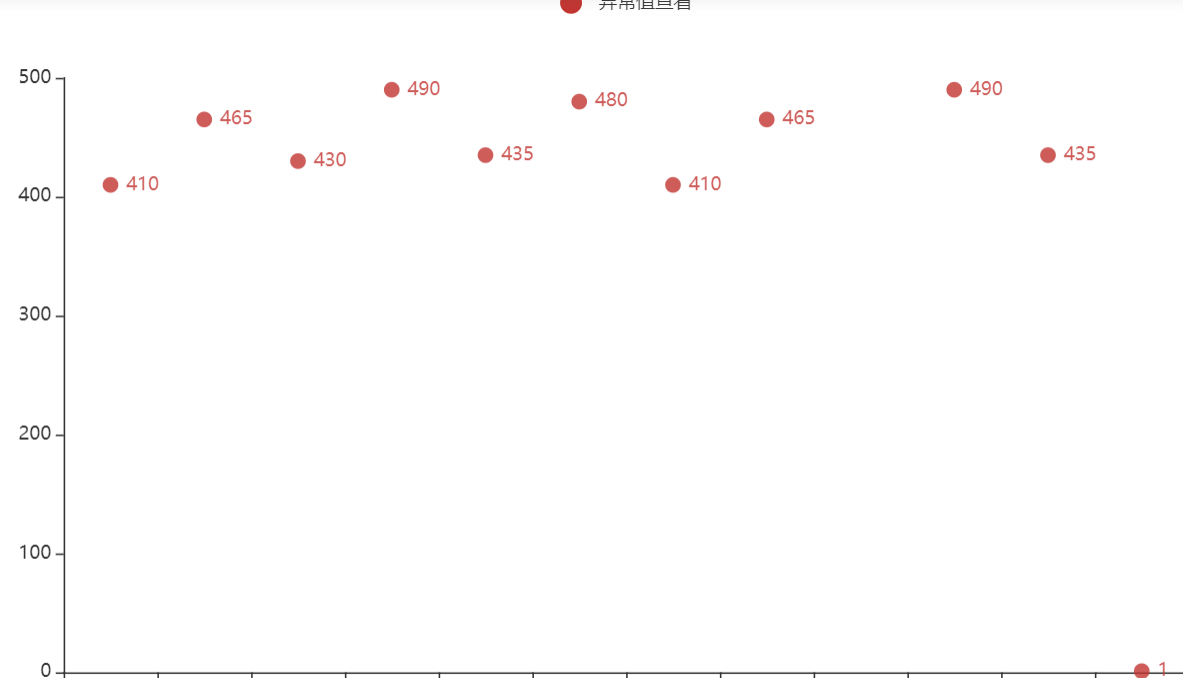
1.散點圖查看例外值
可知例外為1
示例
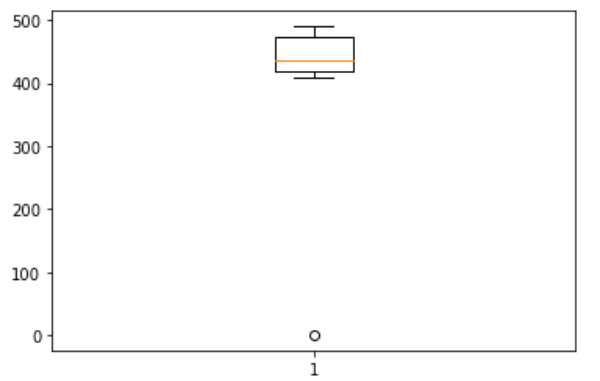
2.箱線圖查看例外值
可知例外為1
示例
3.處理方法借鑒缺失值處理
四.標準化
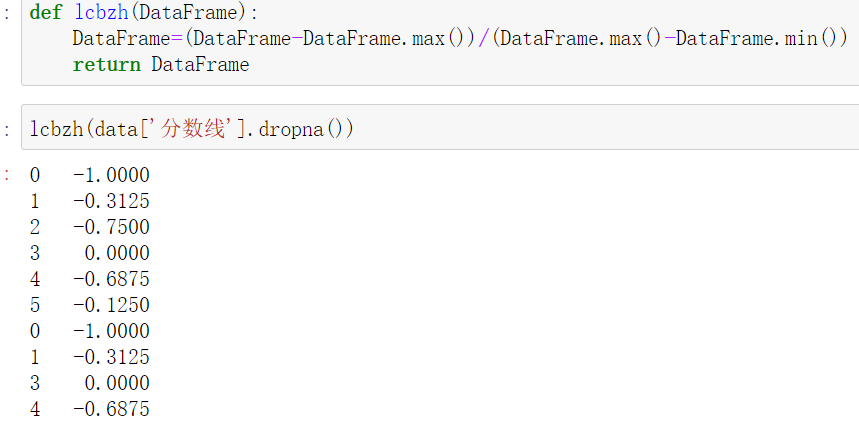
1.離差標準化
將資料映射到[0.1]的區間,處理線性變換資料
公式 :
def lcbzh(DataFrame):
DataFrame=(DataFrame-DataFrame.max())/(DataFrame.max()-DataFrame.min())
return DataFrame
示例
2.標準差標準
處理資料均值為0,標準差為1的資料
公式:
3.小數定點標準化資料
用于移動小數點的位置至[-1,1]
公式:
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/241212.html
標籤:Python