本文的文字及圖片過濾網路,可以學習,交流使用,不具有任何商業用途,如有問題請及時聯系我們以作處理,
以下文章來源于法納斯特 ,作者法納斯特

Python爬蟲、資料分析、網站開發等案例教程視頻免費在線觀看
https://space.bilibili.com/523606542
1.概述
美團網的爬蟲整體其實比較簡單,通過開發者模式找到真實資料請求地址后,用requests請求的資料格式是標準的json字串,非常好處理,

在本文我們將介紹兩種常見的獲取資料的方式,其一是通過搜索獲取結果,其二是通過篩選獲取結果,兩種方式在獲取真實資料請求地址的方法上稍有差異,具體我們見下面章節,
2.搜索結果資料采集
如果想在PC網頁端搜索結果,需要先進行賬號登錄,然后方可進行搜索操作,
2.1. 獲取真實資料請求地址
如下圖,我們先在搜索框 輸入 搜索關鍵字如“火鍋”,然后進行以下步驟:(以谷歌瀏覽器為例)
- 按 F12 進入到開發者模式
- 在右側開發者模式頁面最上方點擊Network—>XHR
- 在左側搜索結果頁拖到最下方,點擊下一頁(如 2)
- 然后在右側的開發者模式頁面左側靠上的Name,點擊第二個uuid開頭的即可出現我們需要的資訊
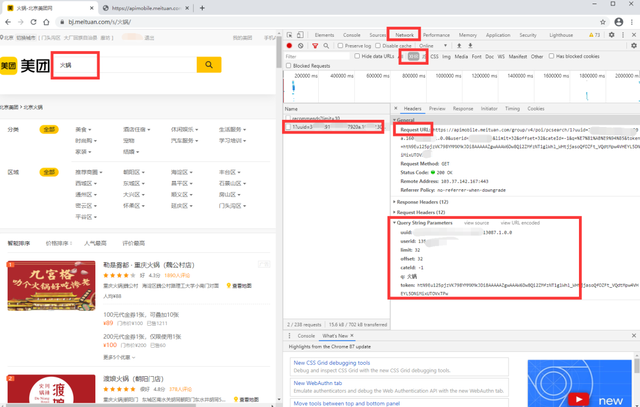
獲取真實資料請求地址
我們可以發現Request URL即為真實資料請求地址,其基礎部分長這樣(北京)https://apimobile.meituan.com/group/v4/poi/pcsearch/1?...
最終鏈接地址還需要有以下引數:在 Query String Parameters 中可以看到哈
uuid: # 你的uuid,登錄后在開發者模式獲取
userid: # 你的userid,登錄后在開發者模式獲取
limit: 32 # 每頁的 店鋪資訊數
offset: 32 # 當前 偏移量,第1頁為0,第2頁為 (2-1)*limit
cateId: -1 # 型別
q: 火鍋 # 搜索的關鍵字
token: htN9Eu125pjzVK798YMMXMkJDi8AAAAAZgwAAAW6Dw8Qi2ZMfzNT1glWhl_WHtjjasoQfOZFt_VQdtMpw4VHEYL5DNiMixUTOVxTPw # token,經過測驗發現可以不需要
如果你在其他篩選項進行選擇時,會發現對應引數可能增加或減少,這個時候根據自己需求進行引數設定即可,
2.2. 請求資料(requests)
這里只需要用到兩個庫,requests請求資料,json決議json資料字串,
import requests
import json
# 以北京為例,其基礎鏈接如下:
base_url = 'https://apimobile.meituan.com/group/v4/poi/pcsearch/1?'
# 上海為如下,差異就在最后面問號前面的數字,上海為10,北京為1
# https://apimobile.meituan.com/group/v4/poi/pcsearch/10?
uuid = xxxx # 你的uuid,登錄后在開發者模式獲取
userid = xxx # 你的userid,登錄后在開發者模式獲取
key = '火鍋'
# 這里演示請求第一頁的資料
page = 1
# 設定請求引數
parameters = {
'uuid': uuid, # 你的uuid,登錄后在開發者模式獲取
'userid': userid, # 你的userid,登錄后在開發者模式獲取
'limit':32, # 每頁的 店鋪資訊數
'offset':32*(page - 1), # 當前 偏移量,第1頁為0,第2頁為 (2-1)*limit
'cateId':-1, #
'q': key, # 搜索的關鍵字
}
# 設定請求頭
header = {
"Accept-Encoding": "Gzip", # 使用gzip壓縮傳輸資料讓訪問更快
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:83.0) Gecko/20100101 Firefox/83.0",
}
# get方法請求網頁資料
re = requests.get(base_url, headers = header, params=parameters)
# re.text是我們需要的資料
text = re.text
# 由于是json格式的字串,用json.load()方法格式化
js = json.loads(text)
# 需要用到的資料在 js['data']中
data = js['data']
searchResult = data['searchResult'] # 結果串列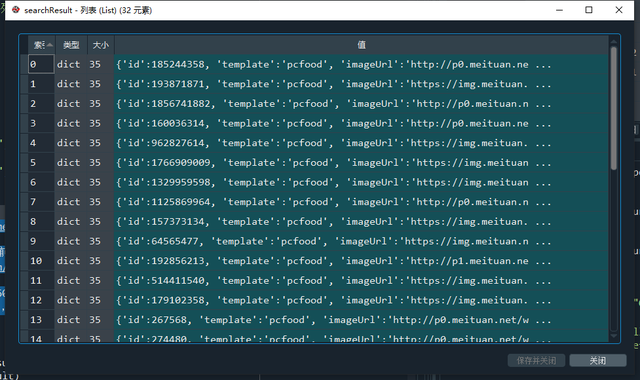
結果其實是很結構化的
2.3. 決議獲取需要的資料
由于單頁存在32組資料,且每組資料欄位較多,我們用串列來存盤單頁資料,用字典存盤單個店鋪的資訊,
考慮到我想記錄每個店鋪的優惠券銷售量資訊,又因為優惠券存盤的是串列形式,這里我單獨處理了優惠券的記錄資訊,組合其他基礎資訊后形成一條資料,因此在最終的資料中同一個店鋪會存在多條,不過其優惠券資訊是存在差異的,
# 接2.2.中結果
shops = []
for dic in searchResult:
shop = {}
shop['id'] = dic['id']
shop['店鋪名稱'] = dic['title']
shop['地址'] = dic['address']
shop['地區'] = dic['areaname']
shop['平均消費'] = dic['avgprice']
shop['評分'] = dic['avgscore']
shop['評價數'] = dic['comments']
shop['型別'] = dic['backCateName']
# shop['優惠'] = dic['deals']
shop['經度'] = dic['longitude']
shop['緯度'] = dic['latitude']
shop['最低消費'] = dic['lowestprice']
if dic['deals'] == None:
shops.append(shop)
else:
for deal in dic['deals']:
# deal = dic['deals'][1]
shop_info = shop.copy()
shop_info['優化id'] = deal['id']
shop_info['優惠券名稱'] = deal['title']
shop_info['優惠券原價值'] = deal['value']
shop_info['優惠券價格'] = deal['price']
shop_info['優惠券銷量'] = deal['sales']
shops.append(shop_info) 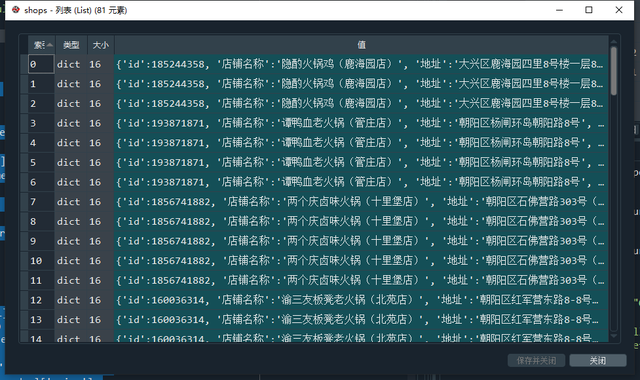
店鋪資料串列
2.4. 存盤結果到本地(csv檔案)
我們每獲取一頁資料之后,立刻寫入本地,因為每頁的資料最后是由字典組成的串列,我們可以直接使用pandas的Dataframe.to_csv()方法來進行追加寫入,
# 接 2.3. 中的結果
import pandas as pd
df = pd.DataFrame(shops)
# 需要存盤表頭,所以對于第一頁的資料我們連表頭一起存盤
if page == 1:
df.to_csv('火鍋店鋪資料.csv',index=False, mode='a+', )
# 非第一頁的資料,我們之存資料不存表頭,mode='a+'是追加模式
else:
df.to_csv('火鍋店鋪資料.csv',header=False,index=False, mode='a+', )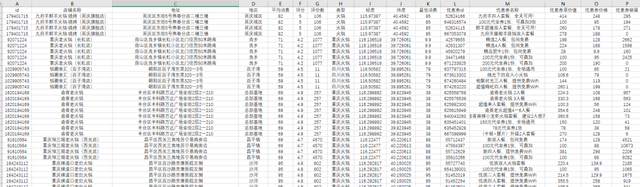
匯出的資料表
3.分類篩選結果資料采集
在進行分類篩選的時候,我們不需要進行賬號登錄即可獲取資料,不過通過分析發現這種情況下真實資料請求地址有別的搜索結果下的真實資料請求地址,且稍微麻煩一點,具體我們見后面的分析,
3.1. 獲取真實資料請求地址
和2.搜索結果資料采集中的程序一樣,進行以下步驟:(以谷歌瀏覽器為例)
- 按 F12 進入到開發者模式
- 在右側開發者模式頁面最上方點擊Network—>XHR
- 重繪頁面或者點擊下一頁(如2)
- 然后在右側的開發者模式頁面左側靠上的Name,點擊getPolist?即可獲得我們需要的資訊
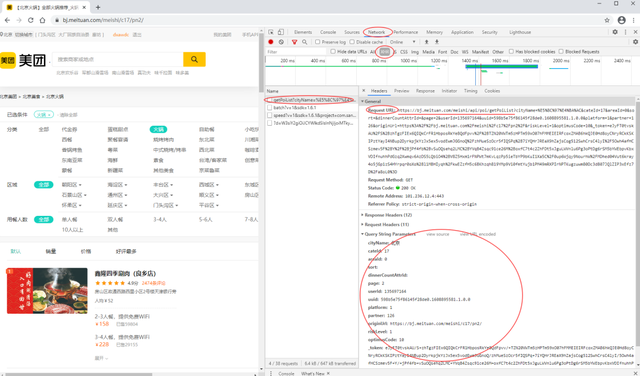
獲取真實資料請求地址
我們可以發現Request URL即為真實資料請求地址,其基礎部分長這樣(北京)https://bj.meituan.com/meishi/api/poi/getPoiList?
最終鏈接地址還需要有以下引數:在 **Query String Parameters **中可以看到哈
cityName: 北京 # 城市
cateId: 17 # 分類
areaId: 0 # 區域
sort: # 排序型別
dinnerCountAttrId: # 就餐人數
page: 2
userId:
uuid:
platform: 1 # 平臺
partner: 126
originUrl: https://bj.meituan.com/meishi/c17/pn2/
riskLevel: 1
optimusCode: 10
_token:
我們發現在上面引數中,隨著翻頁,page、originUrl會規律性變化,同時_token也會有所改變,而該值需要特殊處理獲取,其他引數在你確定頁面篩選項后都是固定的,
3.2. _token決議與生成
我重繪三次,獲取三個token如下,我們試著介紹一下里面分別含有啥引數資訊,
token = [
'eJx1T01vqkAU/S+zhTjDlzDusOLriLYqKkrTBTMgwyCKQBFt+t/fNGkXb/GSm5yPe3Jy7yeoSQJGGkIYIRV0aQ1GQBugwRCooG3kZogcjGyMho4lA+xfDxvSo/VuAkZvtm6p2MLv38Za6jcN60jVkIPe1V9uSq6bcr5TRIYAb9uqGUFIxaBM8/YjPg/YpYSSNzyHTLOhPOQ/ISBbyo1skVj8YPyD7a9eyIdkRZNnZ8nS2S0RTGtd4a34vuOm/wK3874mXbFih8uWbZtxJNDcw1SPRf8nyBSruhXXy9i+EC16tfFyo+DCyzo37dbR5vDKs7Xw+LHHT24HHWVvMHqf5Y9iYiPhw8VuscwpuVcnaswOxAj55slTomXY3aM01ruA6zBy58W09llw8pNhf95F3uGknSfXKrC9YxJTO5iEs+OY+c8hbaamYrrV3NKupAuzHRSY3hTRPjhqxXOkZ0bZOziaohey0OsyaZlFiL3flg9IDJTr4OsvJZyVbQ==',
'eJyFT8luo0AQ/Ze+GrkXzNKWcrABB/DYBLPYTJSDWYJpDGZYTMJo/j0dKTnkNFJJb6mnp6q/oLVSsMQIUYQEcM9asAR4juYyEEDf8Y2MVIoUKhKJYgEkPz1ZpgKI21AHy2eFSAKV6MunceD6GVOCBIxU9CJ88wXnZMHnM2XxELj0fdMtIYzZvMqKfjjX8+RWQc67SwETrMCmJpAf8/8g4KWVz0s5ll94/sL+W+/4f7ytK/Kas8we08nvnbVuuOu9psSO7tZvj5nq2TjXf2tu5Sajfh/IERNom+lhsBxp864Z4iobVskxiEkemqdx84rZSsPHabrkm9bw7hNUiiddUV/rCXqB1kQ+vpr3Yj2LZK+wTk3P4q2bGDd0HNKtiYI6W+yalLTUl8IgKhWm2PsgweJWLsPWuZVFdC1aNfe13R9GyhG9T1ulrn/tI+twTdteS+loElna3VimPs3EdGxyNpO6JH6MK5WkohedAqObzrPMwezGWHrwTLhYqSS0af7wAP59AGUUnIY=',
'eJyNT8tugkAU/ZfZQpwBxGFMuqhPQOUhYgpNFwgUUWAsDGBp+u+dJu2iuyY3OY97cnLvB6iNBEwlhAhCIujSGkyBNEKjCRABa/hmgjSCMFEnElFFEP/1ZCyJ4FQfF2D6jGVVJCp5+Tb2XD9LREaihDT0Iv7yMefymM93yuAhcGbs1kwhPF1GZZqzNqpGMS0h5805h7GE4a1SID/mP0EZAl5cHngxx+sPRj/IfvWO/8gbmzyrOEvNPhkOkv04LN1ZOsc38+I5fZUm4Symq72RG+OFbXfhfa0TCpdBfujcuC/sXq8yvTj7+L1NFcZUt9OCytiudj2m6/BkYE0T6GtHBGdQITXcGAWTIsRqFhbruV8XpU5xEczszXvmb4c1RHbUDtunxFNKIQ+8fauRfONfbSa3fq6qxeDGpnSEru4H7kUuK3J3/OHVijaLq7WyunqJ8dli/aYJnFRzBIXc89hO3oY+KZuEmUrIlFO2rKl3LLC1C99o4HtRF+tkXpjC48MD+PwC/5KgHA=='
]對于這三個token,加密演算法比較簡單,其采用的是二進制壓縮與base64編碼,
3.2.1. 決議
我們在決議token時的操作步驟是先進行base64解碼再進行二進制解壓,這里需要用到base64庫和zlib庫,
import base64
import zlib
for s in token:
temp = base64.b64decode(s)
result = zlib.decompress(temp)
print(result)b'{"rId":100900,"ver":"1.0.6","ts":1608907906850,"cts":1608907906930,"brVD":[725,959],"brR":[[1920,1080],[1920,1040],24,24],"bI":["https://bj.meituan.com/meishi/c17/","https://bj.meituan.com/"],"mT":[],"kT":[],"aT":[],"tT":[],"aM":"","sign":"eJwdjc1tAjEQhXvh4KN/ULxrIvkQcYoUcUsBZj0LE9b2ajxGSg+5pwkqoB7oI1ZO79PT+9kEgvAevRZTYOhgRjEhfx9CAv/8+X3cbyJizkD70jK/MVMPibIyplb3JYI3WhTCE+ZPWvyZea2vSh2/ZALkFrKcSlKd6xnVZEYl1nDqpS7Efdab7SDWJfBcKHWbsF4+4ApL51qIvWgV/j9bw+jtzh0tjHZ2g3mx89ZF0NIM2rmdtc5II7XUmz/I30i2"}'
b'{"rId":100900,"ver":"1.0.6","ts":1608907932591,"cts":1608907932669,"brVD":[725,959],"brR":[[1920,1080],[1920,1040],24,24],"bI":["https://bj.meituan.com/meishi/c17/pn2/","https://bj.meituan.com/meishi/c17/"],"mT":[],"kT":[],"aT":[],"tT":[],"aM":"","sign":"eJwdzTtOBDEQBNC7bODQnxGe8SJ1gDZCQmQcwDvu2W12/JHdRuIO5FyCE3AeuAcWUb2gVHXwFf1jAC1WzzhgFrESvz/7iPD78fnz/SUCpYT1lHviB+Y6SiIXptjbKQcEo0WudKH0Une4Mpd2r9T5VUYk7j7JNUc13K6kVrOokiYlir8gTCMqj2kw0yzK7nnLNYIRldrtCd9wH265Moje8P+3dwpgj+5scbGbm82d3SYXUEsza+eO1jojjdRSH/4A82VJ9g=="}'
b'{"rId":100900,"ver":"1.0.6","ts":1608907956195,"cts":1608907956271,"brVD":[725,959],"brR":[[1920,1080],[1920,1040],24,24],"bI":["https://bj.meituan.com/meishi/c17/pn3/","https://bj.meituan.com/meishi/c17/pn2/"],"mT":[],"kT":[],"aT":[],"tT":[],"aM":"","sign":"eJwdzT1OAzEQBeC7pJjSPwnedZBcoFRIiI4DOOvZxGH9o/EYiTvQcwlOwHngHlhU7yue3tt5Qv8YnILFMw7oGZbI788+ofv9+Pz5/oIQc0Y6lZ75gZlGCUrlmHo7lYBOKygULzG/0OauzLXdS3m+iYSRu89iKUkOt2uUi55lzQcJ1V/QHUYQj2mn9xPUzfNaKDkNFNvrE77hNtwKsYPe8P+39xicOdqzwdmsdtJ3Zt3bgEroSVl7NMZqoYUSavcH9ClJ+A=="}'根據三個token決議結果,我們發現其帶有的引數較多,但是變化的只有部分,其中ts、cts是時間戳,以第一個為例:
ts = 1608907906850

ts
cts = 1608907906930

cts
由于2個都是毫秒級的時間戳,其實都是同一個時間點,相差90毫秒左右,因此我們可以在進行請求的時候獲取當前時間然后即可獲取ts和cts引數值,
另外有變化的就是BI,其是當前網頁和前序網頁的原始地址,亦可有規律生成,
最后,我們發現sign也是變化的,而且和token很像,我們用同樣的決議方式可以發現其規律:
s = 'eJwdjc1tAjEQhXvh4KN/ULxrIvkQcYoUcUsBZj0LE9b2ajxGSg+5pwkqoB7oI1ZO79PT+9kEgvAevRZTYOhgRjEhfx9CAv/8+X3cbyJizkD70jK/MVMPibIyplb3JYI3WhTCE+ZPWvyZea2vSh2/ZALkFrKcSlKd6xnVZEYl1nDqpS7Efdab7SDWJfBcKHWbsF4+4ApL51qIvWgV/j9bw+jtzh0tjHZ2g3mx89ZF0NIM2rmdtc5II7XUmz/I30i2'
temp = base64.b64decode(s)
result = zlib.decompress(temp)
print(result)b'"areaId=0&cateId=17&cityName=\xe5\x8c\x97\xe4\xba\xac&dinnerCountAttrId=&optimusCode=10&originUrl=https://bj.meituan.com/meishi/c17/&page=1&partner=126&platform=1&riskLevel=1&sort=&userId=&uuid=598b5e75f86145f28de0.1608895581.1.0.0"'很巧,我們發現其實他就是一些引陣列合,其中有變化的就是originUrl和page引數,和當前訪問頁關聯,
3.2.2. 生成
我們知道token決議程序之后,逆向程序即可生成token,我們選取一個決議后的token格式化,然后構建生成方式,
# 決議后的token格式化
{'rId': 100900,
'ver': '1.0.6',
'ts': 1608907906850,
'cts': 1608907906930,
'brVD': [725, 959],
'brR': [[1920, 1080], [1920, 1040], 24, 24],
'bI': ['https://bj.meituan.com/meishi/c17/', 'https://bj.meituan.com/'],
'mT': [],
'kT': [],
'aT': [],
'tT': [],
'aM': '',
'sign': 'eJwdjc1tAjEQhXvh4KN/ULxrIvkQcYoUcUsBZj0LE9b2ajxGSg+5pwkqoB7oI1ZO79PT+9kEgvAevRZTYOhgRjEhfx9CAv/8+X3cbyJizkD70jK/MVMPibIyplb3JYI3WhTCE+ZPWvyZea2vSh2/ZALkFrKcSlKd6xnVZEYl1nDqpS7Efdab7SDWJfBcKHWbsF4+4ApL51qIvWgV/j9bw+jtzh0tjHZ2g3mx89ZF0NIM2rmdtc5II7XUmz/I30i2'}對于sign,我們也看下其決議后的結果:
b'"areaId=0&cateId=17&cityName=\xe5\x8c\x97\xe4\xba\xac&dinnerCountAttrId=&optimusCode=10&originUrl=https://bj.meituan.com/meishi/c17/&page=1&partner=126&platform=1&riskLevel=1&sort=&userId=&uuid=598b5e75f86145f28de0.1608895581.1.0.0"'因此,我們在構造token之前先構造sign:
s_sign = f'"areaId=0&cateId=17&cityName=北京&dinnerCountAttrId=&optimusCode=10&originUrl={Url}&page={page}&partner=126&platform=1&riskLevel=1&sort=&userId=&uuid=598b5e75f86145f28de0.1608895581.1.0.0"'在選定城市后,sign可變引數為originUrl和page,
再生成sign:
# 構造sign
Url = 'https://bj.meituan.com/meishi/c17/'
page = 1
s_sign = f'"areaId=0&cateId=17&cityName=北京&dinnerCountAttrId=&optimusCode=10&originUrl={Url}&page={page}&partner=126&platform=1&riskLevel=1&sort=&userId=&uuid=598b5e75f86145f28de0.1608895581.1.0.0"'
# 二進制編碼
encode = s_sign.encode()
# 二進制壓縮
compress = zlib.compress(encode)
# base64編碼
b_encode = base64.b64encode(compress)
# 轉為字串
sign = str(b_encode, encoding='utf-8')
得到可以用于構造token的sign如下:
'eJwdjc1tAjEQhXvh4KN/ULxrIvkQcYoUcUsBZj0LE9b2ajxGSg+5pwkqoB7oI1ZO79PT+9kEgvAevRZTYOhgRjEhfx9CAv/8+X3cbyJizkD70jK/MVMPibIyplb3JYI3WhTCE+ZPWvyZea2vSh2/ZALkFrKcSlKd6xnVZEYl1nDqpS7Efdab7SDWJfBcKHWbsF4+4ApL51qIvWgV/j9bw+jtzh0tjHZ2g3mx89ZF0NIM2rmdtc5II7XUmz/I30i2'再構造token:
# 接上面sign
from datetime import datetime
ts = int(datetime.now().timestamp() * 1000)
beforeUrl = 'https://bj.meituan.com/'
bI = [Url, beforeUrl]
dic_token = {
'rId': 100900,
'ver': '1.0.6',
'ts': ts,
'cts': ts+90,
'brVD': [725, 959],
'brR': [[1920, 1080], [1920, 1040], 24, 24],
'bI': bI,
'mT': [],
'kT': [],
'aT': [],
'tT': [],
'aM': '',
'sign':sign
}
# 二進制編碼
encode = str(dic_token).encode()
# 二進制壓縮
compress = zlib.compress(encode)
# base64編碼
b_encode = base64.b64encode(compress)
# 轉為字串
token = str(b_encode, encoding='utf-8')得到token如下:
'eJx1j01zqjAARf+KOxZ0TMKHMd1hxTairRUVpdMFBASCKAKNaKf//ZEufDNv5i0yc+7JnTvJt1LRSHnsIQgJhA89RcRVFxXUh/2B0uWmlrcDOCRdAcOBiTrJ/rHYkDasNuNOf2DNfOgRk3z+uqVUH4ho3TqCQ9jZezJk0gx5fstUdpW0acr6EYCQ94s4a76CY5+dCtBxnWaAIQzkw/7TUuRQsZJDkvI7BXdq/rq5/Ktcq7PkKDmeXiLOUGNx+z3ditRwXsF61lZU5O9sd1qzdT3yOZzZJNQC3j67iWqWl/x8GuETRf4bJouVSnI7EVYslv5q95YmS26n+5Y8WQIM1a3Owus0u+VjDLkD5pv5IgvptTyE+nRHdS9dPdmqv/DE1Y8DTbipBnxrlk8qh7kHJxq0x41v7w7oOD6XLrb3URBid+xN9yPmvHhhPTFUwypnJjpT4SUbwEl4UXlzS2HDX3wt0Yt2SPwJfKVzrSqihpmU4u26uAGqw0xTfv4AOoWaFA=='3.3. 請求資料(requests)
和搜索結果資料采集一樣,用requests請求資料,json決議json資料字串,
import requests
import json
import base64
import zlib
# 以北京為例,其基礎鏈接如下:
base_url = 'https://bj.meituan.com/meishi/api/poi/getPoiList?'
uuid = '598b5e75f86145f28de0.1608895581.1.0.0' # 你的userid,登錄后在開發者模式獲取
# 這里演示請求第一頁的資料
page = 1
# 構造sign
Url = 'https://bj.meituan.com/meishi/c17/'
s_sign = f'"areaId=0&cateId=17&cityName=北京&dinnerCountAttrId=&optimusCode=10&originUrl={Url}&page={page}&partner=126&platform=1&riskLevel=1&sort=&userId=&uuid=598b5e75f86145f28de0.1608895581.1.0.0"'
# 二進制編碼
encode = s_sign.encode()
# 二進制壓縮
compress = zlib.compress(encode)
# base64編碼
b_encode = base64.b64encode(compress)
# 轉為字串
sign = str(b_encode, encoding='utf-8')
# 接上面sign
from datetime import datetime
ts = int(datetime.now().timestamp() * 1000)
beforeUrl = 'https://bj.meituan.com/'
bI = [Url, beforeUrl]
dic_token = {
'rId': 100900,
'ver': '1.0.6',
'ts': ts,
'cts': ts+90,
'brVD': [725, 959],
'brR': [[1920, 1080], [1920, 1040], 24, 24],
'bI': bI,
'mT': [],
'kT': [],
'aT': [],
'tT': [],
'aM': '',
'sign':sign
}
# 二進制編碼
encode = str(dic_token).encode()
# 二進制壓縮
compress = zlib.compress(encode)
# base64編碼
b_encode = base64.b64encode(compress)
# 轉為字串
token = str(b_encode, encoding='utf-8')
# 設定請求引數
parameters = {
'cityName': '北京' ,# 城市
'cateId': 17 ,# 分類
'areaId': 0 , # 區域
'sort': '',# 排序型別
'dinnerCountAttrId': '' ,# 就餐人數
'page': page,
'userId': '',
'uuid': uuid,
'platform': 1 ,# 平臺
'partner': 126,
'originUrl': Url,
'riskLevel': 1,
'optimusCode': 10,
'_token': token,
}
# 設定請求頭
header = {
"Accept-Encoding": "Gzip", # 使用gzip壓縮傳輸資料讓訪問更快
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:83.0) Gecko/20100101 Firefox/83.0",
}
# get方法請求網頁資料
re = requests.get(base_url, headers = header, params=parameters)
# re.text是我們需要的資料
text = re.text
# 由于是json格式的字串,用json.load()方法格式化
js = json.loads(text)
# 需要用到的資料在 js['data']中
data = js['data']
poiInfos = data['poiInfos'] # 結果串列
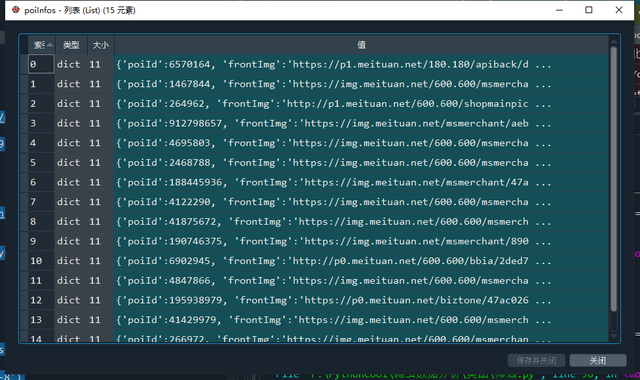
結果串列
3.4. 決議獲取需要的結果
到這一步及之后的資料存盤程序和 2.搜索結果資料采集的步驟大同小異,大家可以自行處理了,不過我們發現通過這種方式獲取的店鋪資訊好像更少些,哈哈哈!
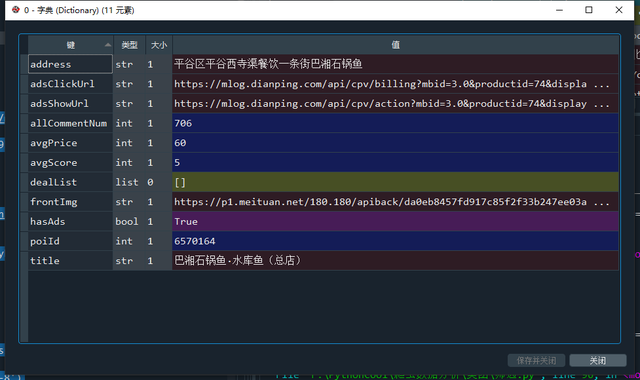
單店鋪資訊
3.5. 存盤結果到本地
同2.4.存盤結果到本地(csv檔案)
4.總結
對于美團的這兩種資料采集方式,我們在進行處理的時候難易度不一樣,其中搜索結果資料采集相對簡單,在獲取到真實資料請求地址后,撰寫回圈腳本就能完成批量爬取;但是對于第二種分類篩選結果資料采集來說,由于其token是時刻在變化的,我們需要進行一定的生成處理后才能爬取到資料,其程序稍微復雜了些,
'cts': ts+90, 'brVD': [725, 959], 'brR': [[1920, 1080], [1920, 1040], 24, 24], 'bI': bI, 'mT': [], 'kT': [], 'aT': [], 'tT': [], 'aM': '', 'sign':sign } # 二進制編碼 encode = str(dic_token).encode() # 二進制壓縮 compress = zlib.compress(encode) # base64編碼 b_encode = base64.b64encode(compress) # 轉為字串 token = str(b_encode, encoding='utf-8')得到token如下:
'eJx1j01zqjAARf+KOxZ0TMKHMd1hxTairRUVpdMFBASCKAKNaKf//ZEufDNv5i0yc+7JnTvJt1LRSHnsIQgJhA89RcRVFxXUh/2B0uWmlrcDOCRdAcOBiTrJ/rHYkDasNuNOf2DNfOgRk3z+uqVUH4ho3TqCQ9jZezJk0gx5fstUdpW0acr6EYCQ94s4a76CY5+dCtBxnWaAIQzkw/7TUuRQsZJDkvI7BXdq/rq5/Ktcq7PkKDmeXiLOUGNx+z3ditRwXsF61lZU5O9sd1qzdT3yOZzZJNQC3j67iWqWl/x8GuETRf4bJouVSnI7EVYslv5q95YmS26n+5Y8WQIM1a3Owus0u+VjDLkD5pv5IgvptTyE+nRHdS9dPdmqv/DE1Y8DTbipBnxrlk8qh7kHJxq0x41v7w7oOD6XLrb3URBid+xN9yPmvHhhPTFUwypnJjpT4SUbwEl4UXlzS2HDX3wt0Yt2SPwJfKVzrSqihpmU4u26uAGqw0xTfv4AOoWaFA=='3.3. 請求資料(requests)
和搜索結果資料采集一樣,用requests請求資料,json決議json資料字串,
import requests
import json
import base64
import zlib
# 以北京為例,其基礎鏈接如下:
base_url = 'https://bj.meituan.com/meishi/api/poi/getPoiList?'
uuid = '598b5e75f86145f28de0.1608895581.1.0.0' # 你的userid,登錄后在開發者模式獲取
# 這里演示請求第一頁的資料
page = 1
# 構造sign
Url = 'https://bj.meituan.com/meishi/c17/'
s_sign = f'"areaId=0&cateId=17&cityName=北京&dinnerCountAttrId=&optimusCode=10&originUrl={Url}&page={page}&partner=126&platform=1&riskLevel=1&sort=&userId=&uuid=598b5e75f86145f28de0.1608895581.1.0.0"'
# 二進制編碼
encode = s_sign.encode()
# 二進制壓縮
compress = zlib.compress(encode)
# base64編碼
b_encode = base64.b64encode(compress)
# 轉為字串
sign = str(b_encode, encoding='utf-8')
# 接上面sign
from datetime import datetime
ts = int(datetime.now().timestamp() * 1000)
beforeUrl = 'https://bj.meituan.com/'
bI = [Url, beforeUrl]
dic_token = {
'rId': 100900,
'ver': '1.0.6',
'ts': ts,
'cts': ts+90,
'brVD': [725, 959],
'brR': [[1920, 1080], [1920, 1040], 24, 24],
'bI': bI,
'mT': [],
'kT': [],
'aT': [],
'tT': [],
'aM': '',
'sign':sign
}
# 二進制編碼
encode = str(dic_token).encode()
# 二進制壓縮
compress = zlib.compress(encode)
# base64編碼
b_encode = base64.b64encode(compress)
# 轉為字串
token = str(b_encode, encoding='utf-8')
# 設定請求引數
parameters = {
'cityName': '北京' ,# 城市
'cateId': 17 ,# 分類
'areaId': 0 , # 區域
'sort': '',# 排序型別
'dinnerCountAttrId': '' ,# 就餐人數
'page': page,
'userId': '',
'uuid': uuid,
'platform': 1 ,# 平臺
'partner': 126,
'originUrl': Url,
'riskLevel': 1,
'optimusCode': 10,
'_token': token,
}
# 設定請求頭
header = {
"Accept-Encoding": "Gzip", # 使用gzip壓縮傳輸資料讓訪問更快
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:83.0) Gecko/20100101 Firefox/83.0",
}
# get方法請求網頁資料
re = requests.get(base_url, headers = header, params=parameters)
# re.text是我們需要的資料
text = re.text
# 由于是json格式的字串,用json.load()方法格式化
js = json.loads(text)
# 需要用到的資料在 js['data']中
data = js['data']
poiInfos = data['poiInfos'] # 結果串列
結果串列
3.4. 決議獲取需要的結果
到這一步及之后的資料存盤程序和 2.搜索結果資料采集的步驟大同小異,大家可以自行處理了,不過我們發現通過這種方式獲取的店鋪資訊好像更少些,哈哈哈!
單店鋪資訊
3.5. 存盤結果到本地
同2.4.存盤結果到本地(csv檔案)
4.總結
對于美團的這兩種資料采集方式,我們在進行處理的時候難易度不一樣,其中搜索結果資料采集相對簡單,在獲取到真實資料請求地址后,撰寫回圈腳本就能完成批量爬取;但是對于第二種分類篩選結果資料采集來說,由于其token是時刻在變化的,我們需要進行一定的生成處理后才能爬取到資料,其程序稍微復雜了些,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/241215.html
標籤:Python