(資料分析)網課評論分析
- 1.資料抓取
- 2.資料清洗
- 2.1資料格式統一
- 2.2空值處理
- 2.3資料去重
- 2.4評論清洗
- 3.資料分析及可視化
- 3.1課程評分分析
- 3.2用戶昵稱格式
- 3.3各平臺評論的平均長度
- 3.4各平臺評論高頻詞
- 3.5評論數與課程評分之間的關系
本文通過爬取的資料,對中國大學MOOC(icourse)、慕課網(imooc)、騰訊課堂(keqq)、網易云課堂(study163)四個網課平臺的課程資訊及評論進行簡要分析,同時,對資料分析的整體流程做一個總結,內容如有紕漏,敬請指出,
1.資料抓取
資料集的獲取是我們進行資料分析的第一步,現在獲取資料的主要途徑一般為:現成資料;自己寫爬蟲去爬取資料;使用現有的爬蟲工具爬取所需內容,保存到資料庫,或以檔案的形式保存到本地,
博主用的是現有的資料進行資料分析,
如果是想通過自己寫爬蟲來爬取資料,那么整體思路大致分為:確定爬取的內容、對主頁面決議、子頁面的獲取、子頁面的決議、資料的保存,現在的網站或多或少都有一些基本的反爬措施,那么,我們在寫爬蟲時就應針對該網站制定相應的反反爬策略,如請求頭、IP代理、cookie限制、驗證碼限制等,這些常見的反爬機制要能夠應用在你寫的爬蟲當中,
如果爬蟲大致能夠爬取我們所需的內容,下一步,我認為就是提高爬取速度,增加穩定性了,我們知道當request模塊對頁面發起請求時,整個程式是處于阻塞狀態,在請求的這段時間后面的代碼是無法運行的,所以說當我們需要對很多個頁面發起請求時,我們可以通過使用異步協程的方式,使我們能夠利用阻塞的這段時間去執行其他任務,由于requests模塊是不支持異步協程的,我們需要使用aiohttp模塊來對頁面發起請求,再搭配asyncio來實作異步爬蟲,
提高穩定性,就需要一些穩定的ip代理,防止爬蟲運行期間ip被封,推薦自己爬取一些免費的ip代理的網站,通過代碼測驗一下,將能用的保存到資料庫中,使用時直接通過類來使用即可,如果你對爬蟲中的ip代理的使用還是很了解,不妨看下這篇文章(異步爬蟲)requests和aiohttp中代理IP的使用,
因為我沒用過爬蟲工具,所以就不介紹了,
2.資料清洗
資料得到手,我們就需要對我們爬取的資料進行清洗作業,為之后的資料分析做鋪墊,如果清洗的不到位勢必會對之后的資料分析造成影響,
下文將從資料格式統一、空值處理、資料去重、評論清洗等方面來介紹,
2.1資料格式統一
對于四個平臺的資料,由于各個平臺爬取的內容有所不同,資料型別也有差別,我們根據后期分析的需要,提取我們需要的內容,資料型別與格式統一后再將課程及評論資訊合并,
如課程評分中,imooc的評分格式為‘9分’,而資料分析時,只需要9來作為分數即可,各個平臺的評分要求不同,這里統一5分制,
# 正則提取數字
df['評論分數'] = df['評論分數'].str.extract(r'(\d+)', expand=True)
# 型別轉換,并改為五分制
df['評論分數'] = df['評論分數'].values.astype(float)/2
重新對列名進行命名
df.rename(columns=({'課程名':'course_name', '學習人數':'total_stu'}), inplace=True)
2.2空值處理
對于資料中的空值(Nan),如果該行中的資料對后面資料分析影響不大,那么,直接洗掉改行即可,
# 直接洗掉course_id列中值為空的行(不包含空字串)
df = df.dropna(subset=['comment'])
如果要對空字串進行洗掉,直接使用上述方法并不能實作,可以先將字串轉為np.nan型別,再使用dropna來洗掉,
# 將空字串轉為'np.nan',用于下一步洗掉
df['course_id'].replace(to_replace=r'^\s*$', value=np.nan, regex=True, inplace=True)
# 洗掉course_id中的空值,并重置索引
df = df.dropna(subset=['course_id'])
df.reset_index(drop=True, inplace=True)
2.3資料去重
用于爬取時的誤差,部分資料有部分重復,這是就需要洗掉這些重復的資料,只保留一條即可,
# 根據course_id列的唯一性,可以把它作為作為參照,如存在多行course_id相同,那么只保留最開始出現的,
df.drop_duplicates(subset=['course_id'], keep='first', inplace=True)
# 重置索引
df.reset_index(drop=True, inplace=True)
2.4評論清洗
對單一用戶的重復評論去重,對于同一用戶在不同時間對同一課程進行的評論如果內容相同,可以認為該用戶在評論時并未認真思考,因此應只保留第一次,以保證后期分析資料的有效性,
df.drop_duplicates(subset=['user_id', 'comment'], keep='first', inplace=True)
df.reset_index(drop=True, inplace=True)
去除評論中的換行符(\n)和回車(\r),
df['comment'] = df['comment'].str.replace('\r|\n', '')
去除評論開頭和結尾的空格
df['comment'] = df['comment'].str.strip()
對于純數字評論(如‘111’,‘123456’,‘666’),無實際意義,并不能說明對某一事物的評價,應洗掉,先通過正則將其替換成空字串,后面統一洗掉,
df['comment'] = df['comment'].str.replace('^[0-9]*$', '')
對于單一重復字符評論(如‘aaaa’,‘!!!’),無實際意義,
df['comment'] = df['comment'].str.replace(r'^(.)\1*$', '')
部分評論包含時間(如‘2020/11/20 20:00:00打卡’),通過正則匹配將時間日期轉為空字串,防止影響之后對評論的分詞,
df['comment'] = df['comment'].str.replace(r'\d+/\d+/\d+ \d+:\d+:\d+', '')
機械壓縮去詞
(1)機械壓縮去詞思想
由于評論資訊中評論質量參差不齊,沒有實際意義的評論有很多,只通過簡單的文本去重,很難將那些沒有意義的評論大量洗掉,因此經過簡單的文本去重后,還要使用機械壓縮進行再次去重,如‘非常好非常好’,‘好呀好呀’等,
這類連續重復的評論,在之前的清洗中很難洗掉,但放任不管,當之后情感分析時,經過分詞,積極詞匯量與實際詞匯量相差較多,對后期統計會產生較大影響,
(2)機械壓縮去詞的結構
從一般的評論來講,人們一般只會在開頭和結尾添加無意義的重復語料,如‘為什么為什么課程這么貴’,‘真的非常好好好’,而中間出現連續詞時,大多是成語及名詞修飾等,如‘老師講課真的滔滔不絕,如同江河!’等,如果對這樣的詞進行壓縮,可能會改變陳述句原意,因此,只對開頭和結尾出現重復詞時進行壓縮去詞,
(3)機械壓縮處理程序及規則制定
連續累贅重復的判斷可以通過建立兩個存放字符的串列來完成,一個一個的讀取字符,并按照不同的情況,將字符放入第一個或第二個串列或觸發壓縮判斷,若觸發判斷得出的結果是重復(即串列1和串列2有意義的字符部分完全相同)則進行去除,這里根據python資料分析與挖掘實戰書中的規則參考,指定七條規則,
規則1:如果讀入的字符與串列1的第一個字符相同,而串列2中沒有放入任何字符,則將這個字符放入串列2中,

規則2:如果讀入的字符與串列1中的第一個字符相同時,而串列2也有字符,那么觸發壓縮判斷,若結果是重復,則進行去除,并清空串列2,

規則3:如果讀入的字符與串列1的第一個字符相同,而串列2也有字符,觸發壓縮判斷,若不重復,則清空兩個串列,并把讀入的這個字符放入串列1的第一個位置,

規則4:如果讀入的字符與串列1的第一個字符不相同,觸發壓縮判斷,若重復,且兩個串列中字符數目大于2,則去除,并清空兩個串列,將該字符存入串列1,
規則5:如果讀入的字符與串列1的第一個字符不相同,觸發壓縮判斷,若不重復,且串列2中沒有字符,則繼續在串列1中放入字符,
規則6:如果讀入的字符與串列1的第一個字符不相同,觸發壓縮判斷,若不重復,且串列2中有字符,則繼續在串列2中放入字符,
規則7:讀完所有字符后,觸發壓縮判斷,對串列1與串列2進行比較,若重復則洗掉,
(4)機械壓縮效果展示

3.資料分析及可視化
3.1課程評分分析
首先對各個平臺課程的評分進行分析,并可視化,
由于平臺資料中只有兩個平臺包含課程評分,所以只對這兩個平臺的課程評分進行分析,
從合并好的課程資訊csv中選擇兩平臺的500門課程評分進行分析,統計各個評磁區間的課程數量,
df = pd.read_csv(r'merge_course.csv', usecols=['platform', 'rating'])
df = df.loc[df['platform'] == 'imooc'].head(500)
print(len(df[df['rating'] >= 4.75]))
print(len(df[(df['rating'] < 4.75) & (df['rating'] >=4.5)]))
print(len(df[(df['rating'] < 4.5)]))
再資料通過matplotlib庫進行可視化,得到下圖,
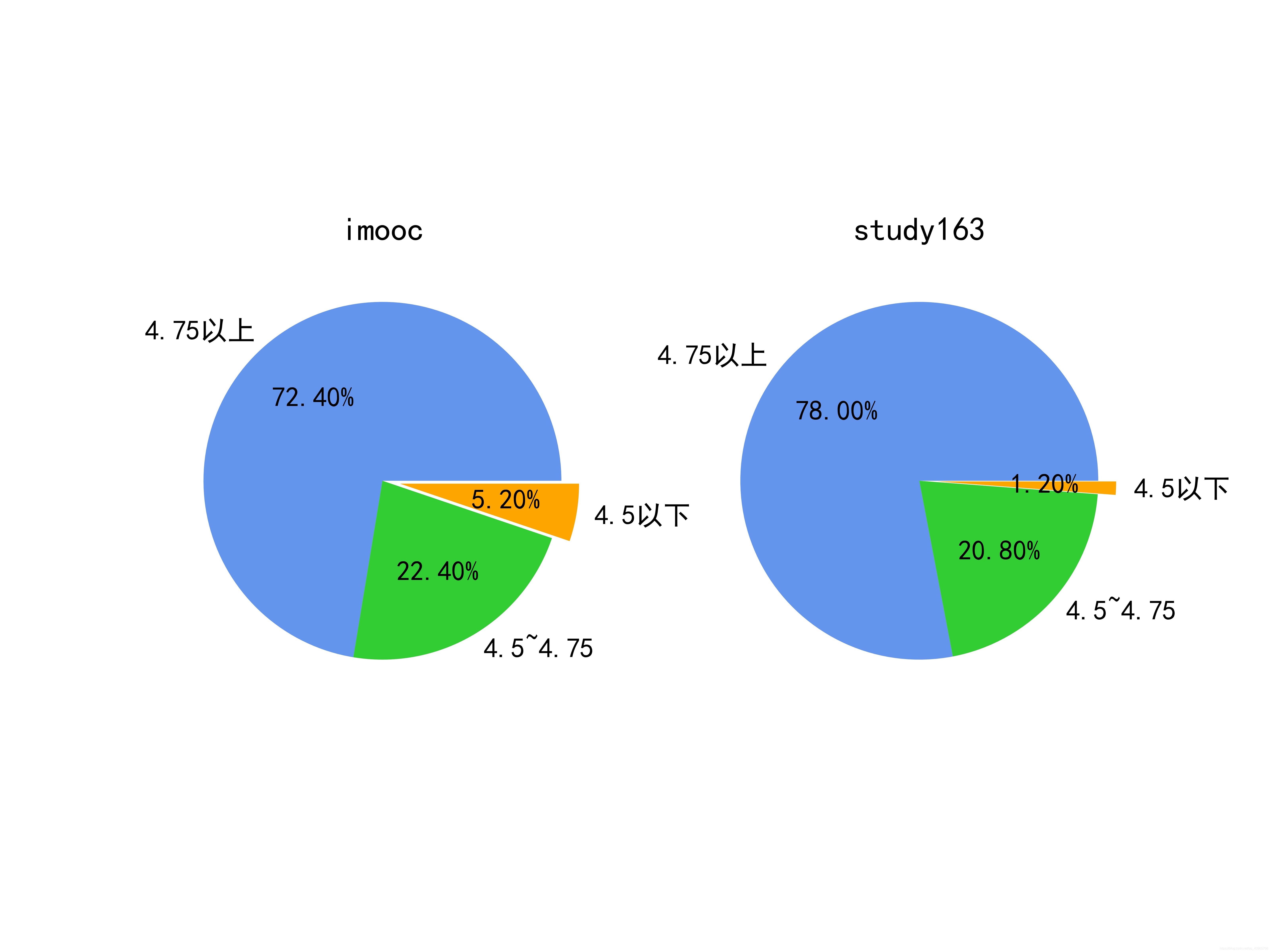
通過圖可以很清晰的看出,兩個平臺的評磁區間分布,總的來說study163平臺的課程整體評分要比imooc平臺高一些,4.5分以下的課程只占到1%左右,
3.2用戶昵稱格式
用戶名從評論資訊中獲取,通過去重,來保證用戶名的唯一性,由于keqq平臺用戶名是隱藏的,所以不進行統計,
df = pd.read_csv(r'C:/Users/pc/Desktop/new_merge_comment.csv',
low_memory=False, usecols=['platform', 'user_name'])
df = df.loc[df['platform']=='mooc163', :]
df.dropna(inplace=True)
df.drop_duplicates(keep='first', inplace=True)
df.reset_index(drop=True, inplace=True)
df = df.head(30000)
chinese_name = []
for name in df['user_name'].values:
if re.findall(r'[\u4e00-\u9fff]', name):
chinese_name.append(name)
pure_chinese_name = []
for name in chinese_name:
if name == ''.join(re.findall(r'[\u4e00-\u9fff]', name)):
pure_chinese_name.append(name)
print(30000-len(chinese_name)) # 字符
print(len(pure_chinese_name)) # 中文
得到各個平臺的用戶名格式,就可以進行可視化了,結果如下圖,
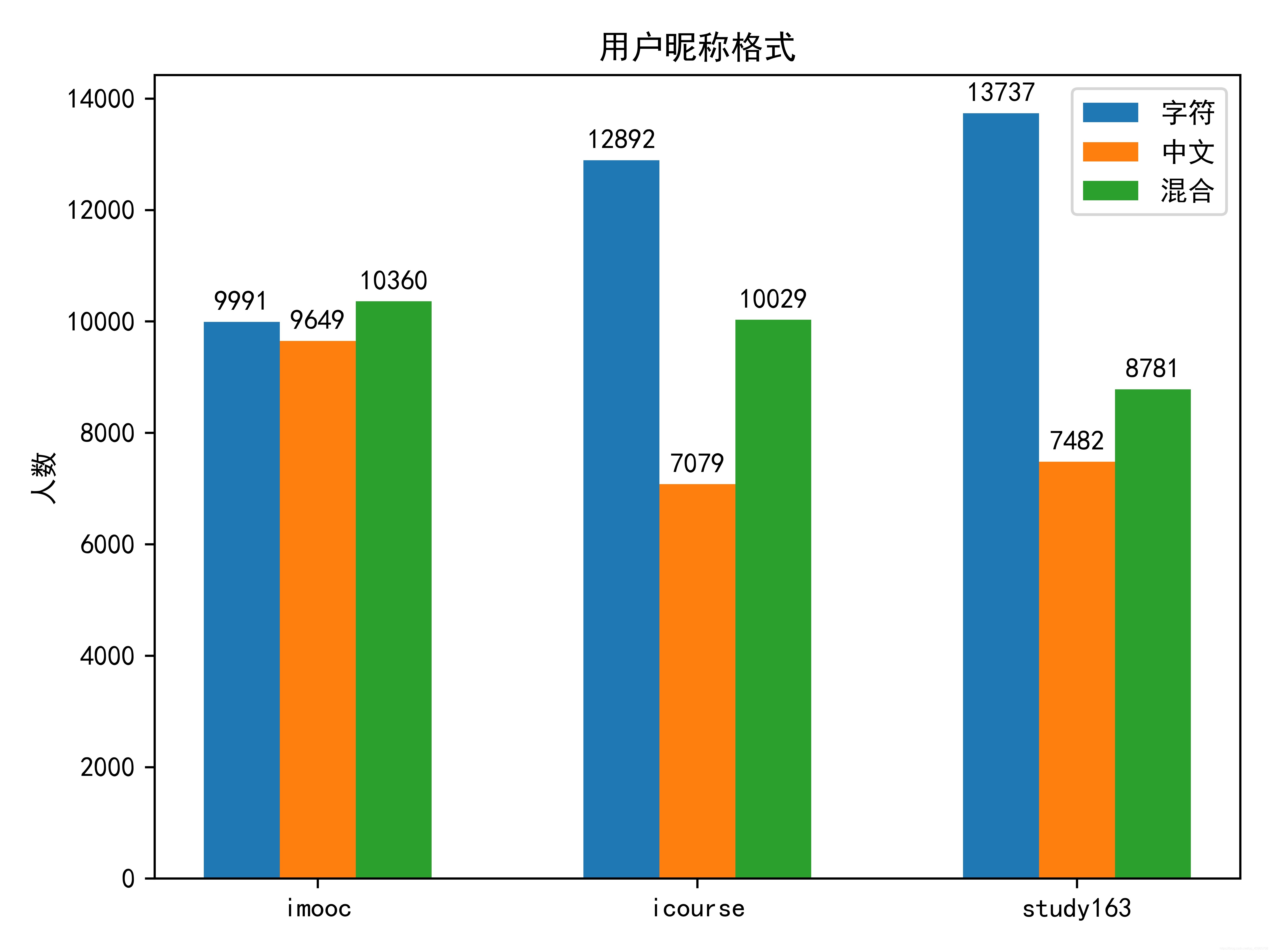
根據圖中資訊可知,在imooc平臺,三種格式的用戶名使用人數大致持平,而在icourse和study163平臺上使用純字符來做為昵稱的人數要明顯多于純中文的昵稱,
3.3各平臺評論的平均長度
之前已經統計了各個平臺課程評論的平均長度,現在只需要取它們的平均值即可,
df = pd.read_csv(r'Chinese_comment.csv', low_memory=False,
usecols=['platform', 'average_length'])
print(df.groupby('platform').describe().reset_index(drop=None))

可視化結果如下,
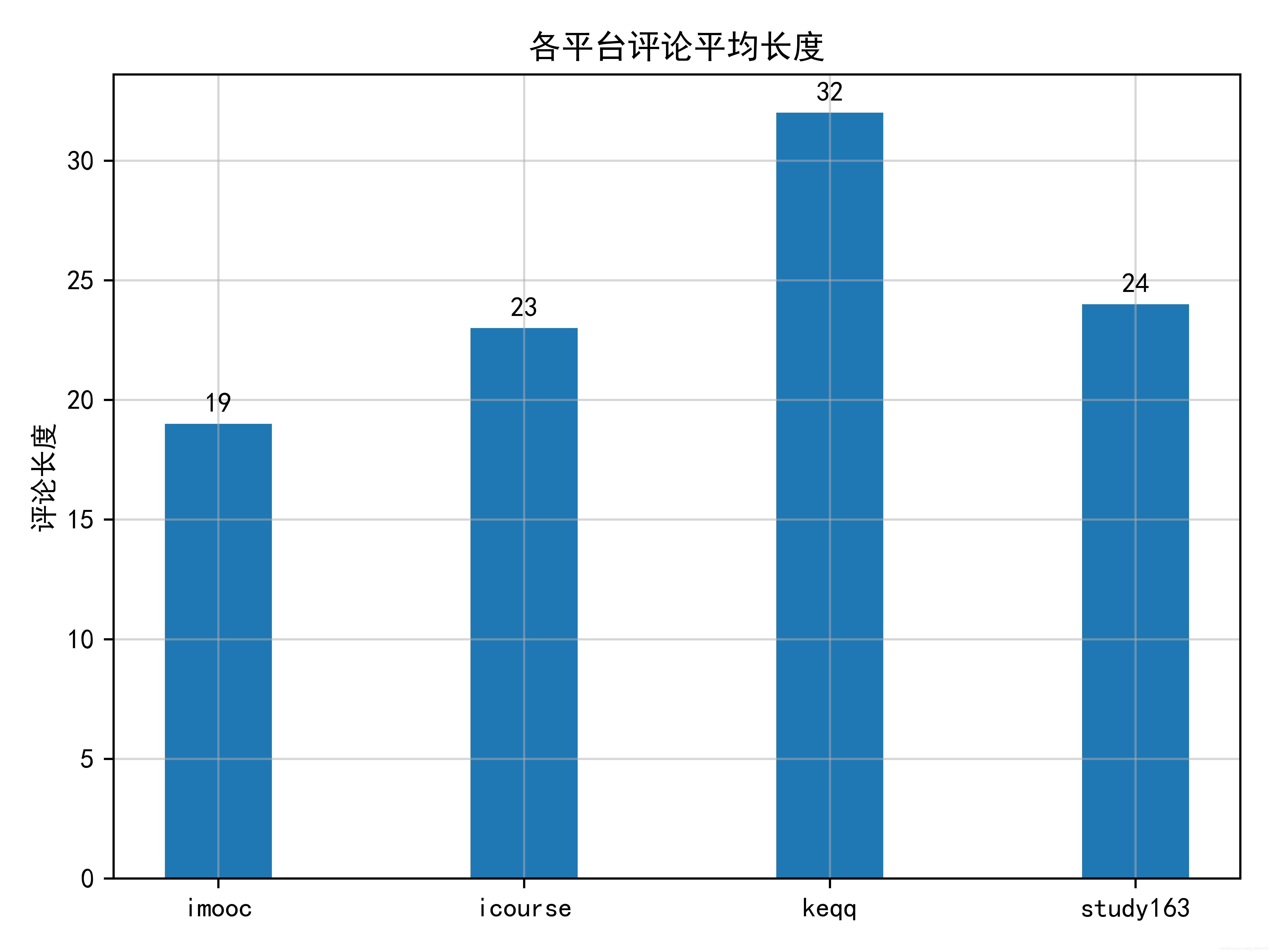
四個平臺的評論平均長度以騰訊課堂(keqq)最高,中國大學MOOC(icourse)與網易云課堂(study163)相近,慕課網(imooc)最低,通過評論平均長度側面反映出各個平臺用戶的活躍度,
3.4各平臺評論高頻詞
提取各個平臺的積極消極高頻詞,
使用dataframe保存讀取csv檔案中的內容,再從dataframe中讀取每一條評論,使用groupby()函式按課程名進行分組,同時將該課程評論合并到同一列,
course_comment = df.groupby(['course_id'])['comment'].apply(sum)
將dataframe中的資料保存到字典中,創建一個新的dataframe物件new_df來保存課程名和提取的正面/負面高頻詞,回圈字典中的鍵‘comemnt’的每一個評論,使用jieba分詞精準模式對其進行分詞,對比匯入的中文停用詞表將詞匯串列中無用的字符漢字進行剔除,之后匯入positive.txt,negative.txt分別作為正面情感詞典,負面情感詞典,回圈每個分詞后得到的課程正面/負面詞匯串列,使用Courter函式獲取正面/負面詞匯串列出現次數最多的五組詞,
up_list = Counter(positive_list).most_common(5)
down_list = Counter(negative_list).most_common(5)
之后將得到的高頻詞和課程名保存到new_df中,回圈直至所有的課程評論都已保存,
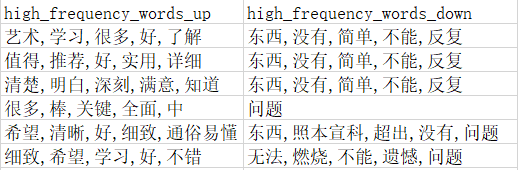
到這里已經獲取了各平臺每一課程中所有評論的高頻詞,接下來只需要整合每個平臺課程的高頻詞,將其以詞匯圖的形式來展現即可,這里以慕課網(imooc)平臺的積極消極高頻詞作為展示,
可視化結果如下圖
課程評論積極高頻詞

課程評論消極高頻詞

從這兩個詞云圖中的高頻詞,不難看出,用戶對課程的難易度、教師的講課水平、課程的整體結構、課后習題的安排有較高的要求,如積極詞匯中出現較多的“易懂”、“詳細”、“基礎”、“清晰”等,消極詞匯中出現較多的“復雜”、“辛苦”、“廢話”等,
3.5評論數與課程評分之間的關系
這里我們隨機選取慕課網(imooc)和網易云課堂(study163)200門課程,分別統計它們的課程評分和評論數,
df = pd.read_csv('merge_course.csv', low_memory=False,
usecols=['platform', 'course_name', 'course_id', 'rating'])
df = df.loc[df['platform'] == 'imooc'].reset_index(drop=None).head(200)
df_comment = pd.read_csv('merge_comment.csv', low_memory=False,
usecols=['platform', 'course_id', 'comment'])
df_comment = df_comment.loc[df_comment['platform'] == 'mooc163']
series = df_comment.groupby('course_id')['comment'].count()
df_comment = pd.DataFrame()
df_comment['course_id'] = series.index
df_comment['count'] = series.values
df_comment['course_id'] = df_comment['course_id'].str.extract('^(\d+)', expand=True)
new_df = pd.merge(df, df_comment, on='course_id')
rating_list = new_df['rating'].values.tolist() # 課程評分
count_list = new_df['count'].values.tolist() # 課程評論
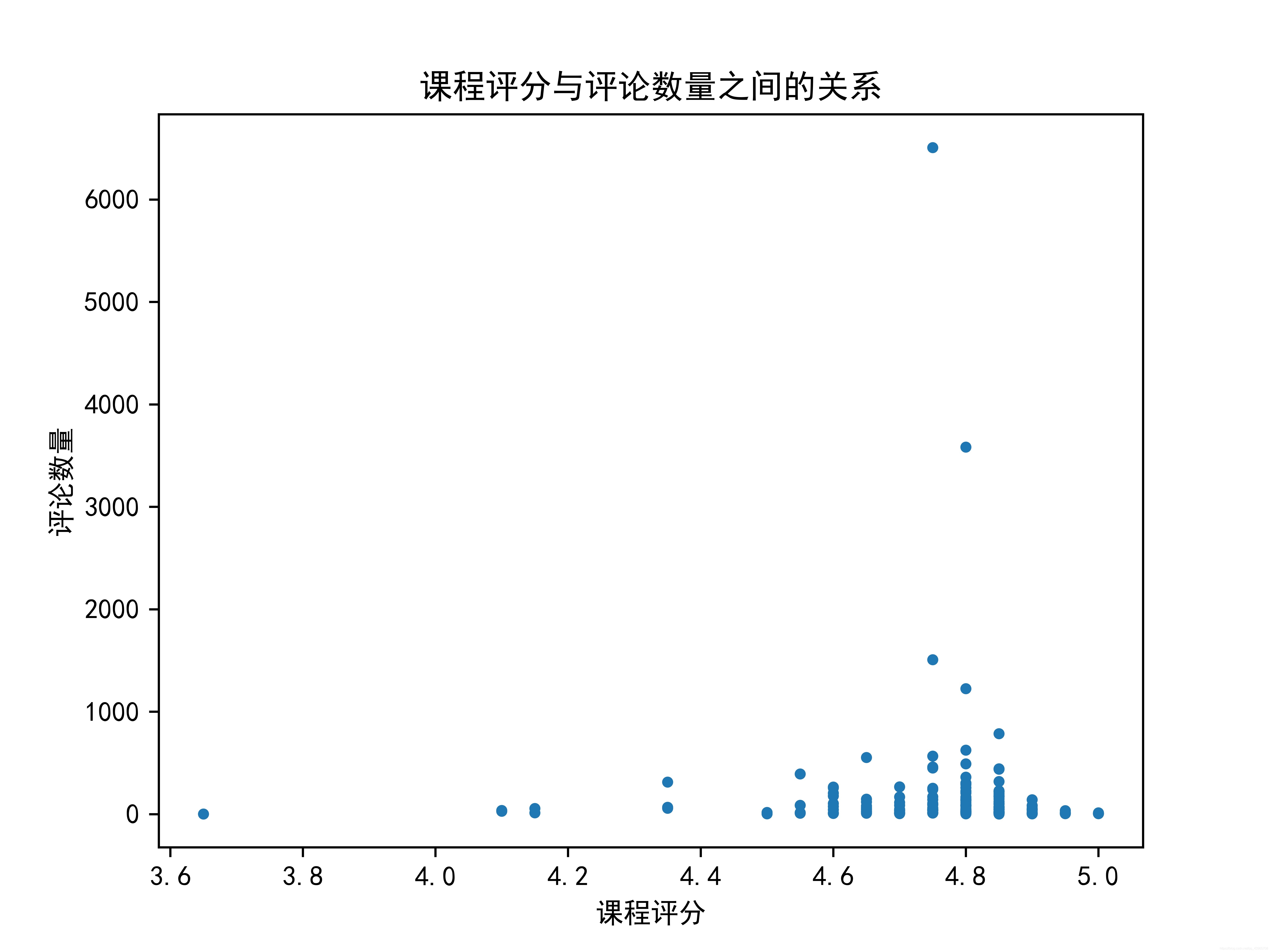
得到rating_list、count_list后通過散點圖可視化,結果如下圖,
慕課網(imooc)
網易云課堂(study163)
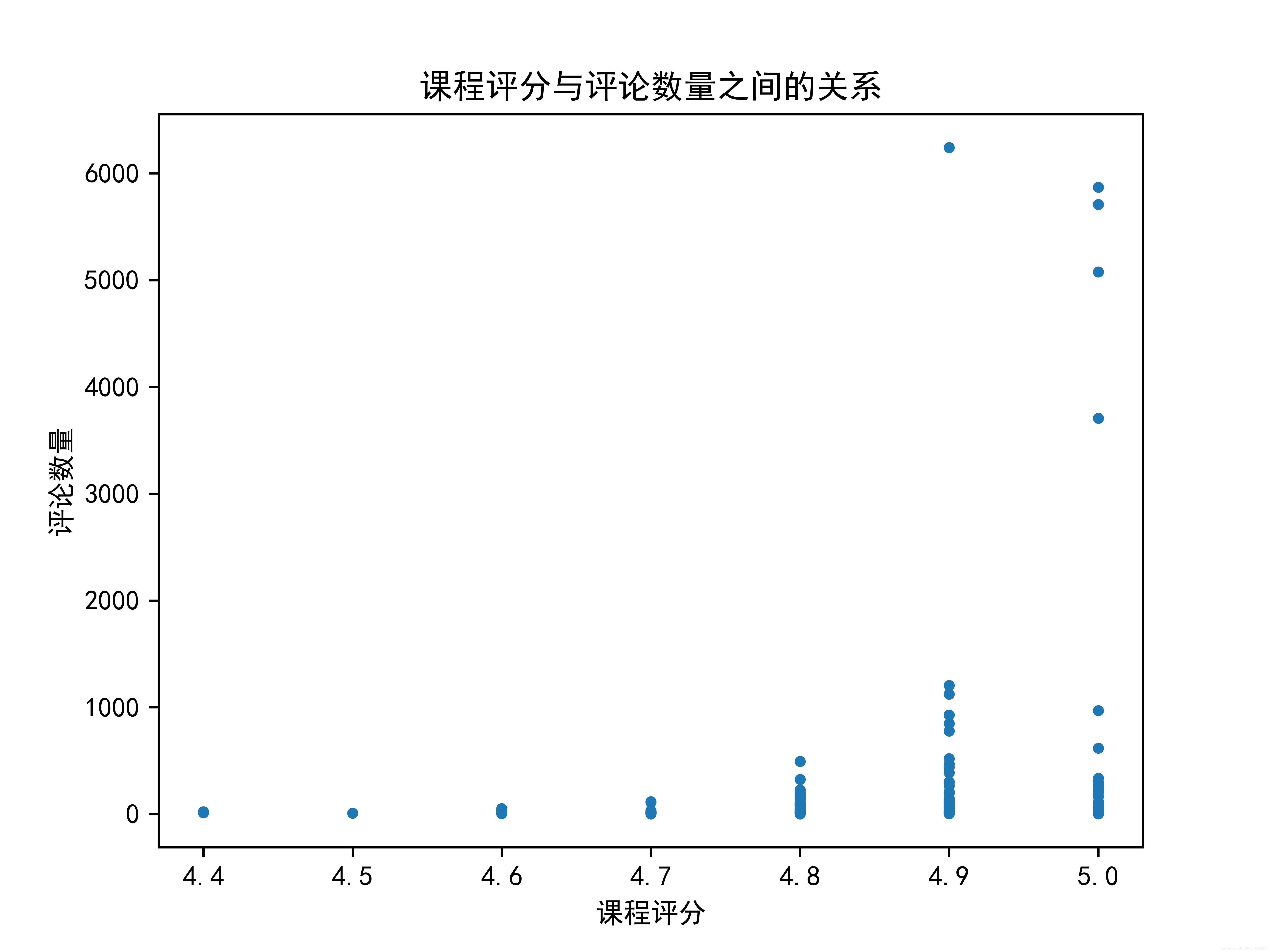
通過兩個平臺的對比不難看出,當評論數量較多時,慕課網的課程評分基本穩定在4.8–5.0之間,課程評分基本穩定在4.9–5.0之間,兩平臺評論數量最多的課程評分分別為4.8,4.9分,可見評級人數越多,越不容易達到滿分,同時兩個平臺中評分較低的課程普遍評論量不高,可見當評級人數較少時,個別用戶的低分就會對課程評分產生較大影響,
以上便是本文全部內容,部分代碼并不完整,只提供思路,matplotlib可視化可以參考官方檔案,所以在文中就沒放可視化相關代碼,
參考資料:
python資料分析與挖掘實戰
pandas官方檔案
matplotlib官方檔案
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/241345.html
標籤:python
下一篇:Python3 - Seaborn: clustermap(), heatmap(), pivot_table(), corr() 有料~~~