Tensorflow 目標檢測中資料增強究竟起了什么作用?— 探索資料增強的真正作用
1. 無資料增強模型和有資料增強模型–>測驗同一資料集
-
利用voc資料集(train:07+12trainandvalidation test:07test)進行訓練和測驗;
-
訓練
不包含任何資料增強方法的mobilenet-ssd,最終mAP為:22.64% -
訓練
只包含random_vertical_flip(#隨機垂直翻轉)的mobilenet-ssd,最終mAP為:21.91% -
兩個map的差別分析原因:
(1)兩個mAP不同,并且擁有垂直翻轉資料增強的模型mAP還小于本身模型,說明隨機垂直翻轉沒有提升了模型對于影像的識別能力,因為測驗集中不存在翻轉的目標,
同時說明了隨機垂直翻轉資料增強沒能夠對原始正常影像起到一個資料量增大或者是魯棒性提升的效果,因此對于正常的測驗集結果沒有提升,
(2)記錄此處兩個mAP的差值(記錄為C1):-0.73%
2. 無資料增強模型和有資料增強模型–>測驗同一翻轉資料集(1步驟中的資料集翻轉得到)
- 將測驗集全部影像翻轉,組成一個新的測驗集;
(1)處理影像代碼:
from PIL import Image
import os
os.chdir('/*/personaddcar/test/VOCdevkit/VOC2007/JPEGImages')
for filename in os.listdir('/*/personaddcar/test/VOCdevkit/VOC2007/JPEGImages'):
print(filename)
im=Image.open(filename)
im=im.rotate(180)
im.save(filename, quality = 95, subsampling = 0)
(2)處理xml檔案代碼:
import xml.etree.cElementTree as ET
import os
path_root = "/*/test/VOCdevkit/VOC2007/Annotations/"
xml_list = os.listdir(path_root)
for axml in xml_list:
path_xml = os.path.join(path_root, axml)
tree = ET.parse(path_xml)
root = tree.getroot()
width = root.find('size').find('width').text
height = root.find('size').find('height').text
for child in root.findall('object'):
bndbox = child.find('bndbox')
xmin = bndbox.find('xmin').text
ymin = bndbox.find('ymin').text
xmax = bndbox.find('xmax').text
ymax = bndbox.find('ymax').text
new_xmin = str(int(width) - int(xmax))
new_ymin = str(int(height) - int(ymax))
new_xmax = str(int(width) - int(xmin))
new_ymax = str(int(height) - int(ymin))
bndbox.find('xmin').text = new_xmin
bndbox.find('ymin').text = new_ymin
bndbox.find('xmax').text = new_xmax
bndbox.find('ymax').text = new_ymax
tree.write(os.path.join("/*/VOCdevkit/VOC2007/Annotations/", axml))
print("***********finish one object**************")
-
利用該測驗集測驗
不包含任何資料增強方法的mobilenet-ssd,最終mAP為:4.04%,其中對于每一個類別的詳細mAP中,對于飛機類和貓類的識別情況較好,因為這兩類某些垂直翻轉情況對于原影像的影響不是很大,不屬于普遍的關于水平對稱的目標,但是和正常測驗集的飛機類和貓類的mAP結果相比還是差距較大, -
利用該測驗集測驗
只包含random_vertical_flip(#隨機垂直翻轉)的mobilenet-ssd,最終mAP為:22.14% -
兩個map的差別分析原因:
(1)如果兩個mAP不同,說明隨機垂直翻轉提升了模型對于影像的識別能力,而該能力的提升代表模型對于垂直翻轉目標的識別能力變強了,不是因為訓練資料集變大了
(2)觀察此處兩個mAP的差值(記錄為C2):18.1%
3. 結論:
(1)如果C1>=C2,代表隨機垂直翻轉提升了模型對于影像的識別能力,而該能力的提升大概率是依賴于資料增強導致的資料集變大,不代表模型對于垂直翻轉目標的識別能力變強了;
(2)如果C1<C2&&C1>0,說明隨機垂直翻轉提升了模型對于影像的識別能力,而該能力的提升不僅僅代表模型對于垂直翻轉目標的識別能力變強了,同時也代表資料增強使得訓練資料集變大起了效果,
(3)如果C1<C2&&C1<0,說明隨機垂直翻轉提升了模型對于影像的識別能力,而該能力的提升僅僅代表模型對于垂直翻轉目標的識別能力變強了,不代表資料增強使得訓練資料集變大起了效果,
這說明想識別什么還是得訓練集中有什么!!訓練集中沒有的特征別指望模型可以泛化了!!!
4. 附注:
-
在實驗中發現,當利用合適的資料增強方法時,對于模型在正常公開資料集的測驗集(例如,VOC 07test)上的
mAP提升明顯; -
比如,正常訓練
mobilenet-ssd目標檢測模型時采用的資料增強方式為下圖的2個資料增強方式,訓練后的模型在測驗集上的mAP能達到68%,遠遠大于目前不利用資料增強方式訓練得到的模型,
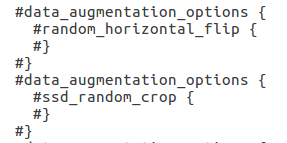
-
上述現象體現了合適的資料增強的方法對于目標檢測模型的重要性,提升了原始模型的魯棒性,
-
也體現了神經網路目標檢測模型不具備旋轉不變性,僅能依靠資料增強方式來提升部分旋轉不變性,
5. 同樣更新于知乎賬號中
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/241848.html
標籤:python
上一篇:縱橫杯2020
下一篇:Python知識點總結