以天堂圖片網為例,
1.分析網站
進入網站后的頁面如下:
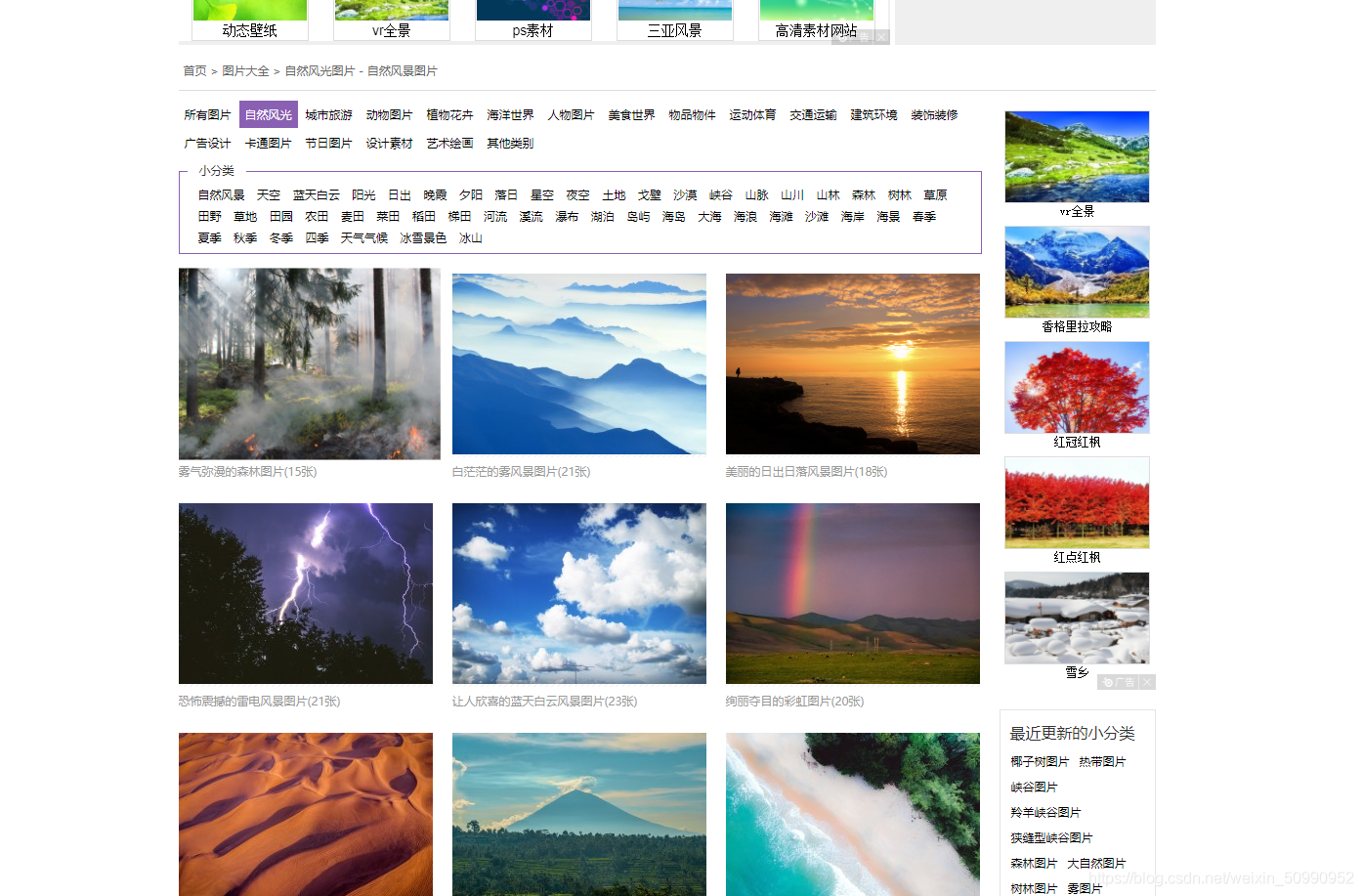
可以看到,我們想爬取的圖片明顯不在這個界面,那我們順便點進去一個:
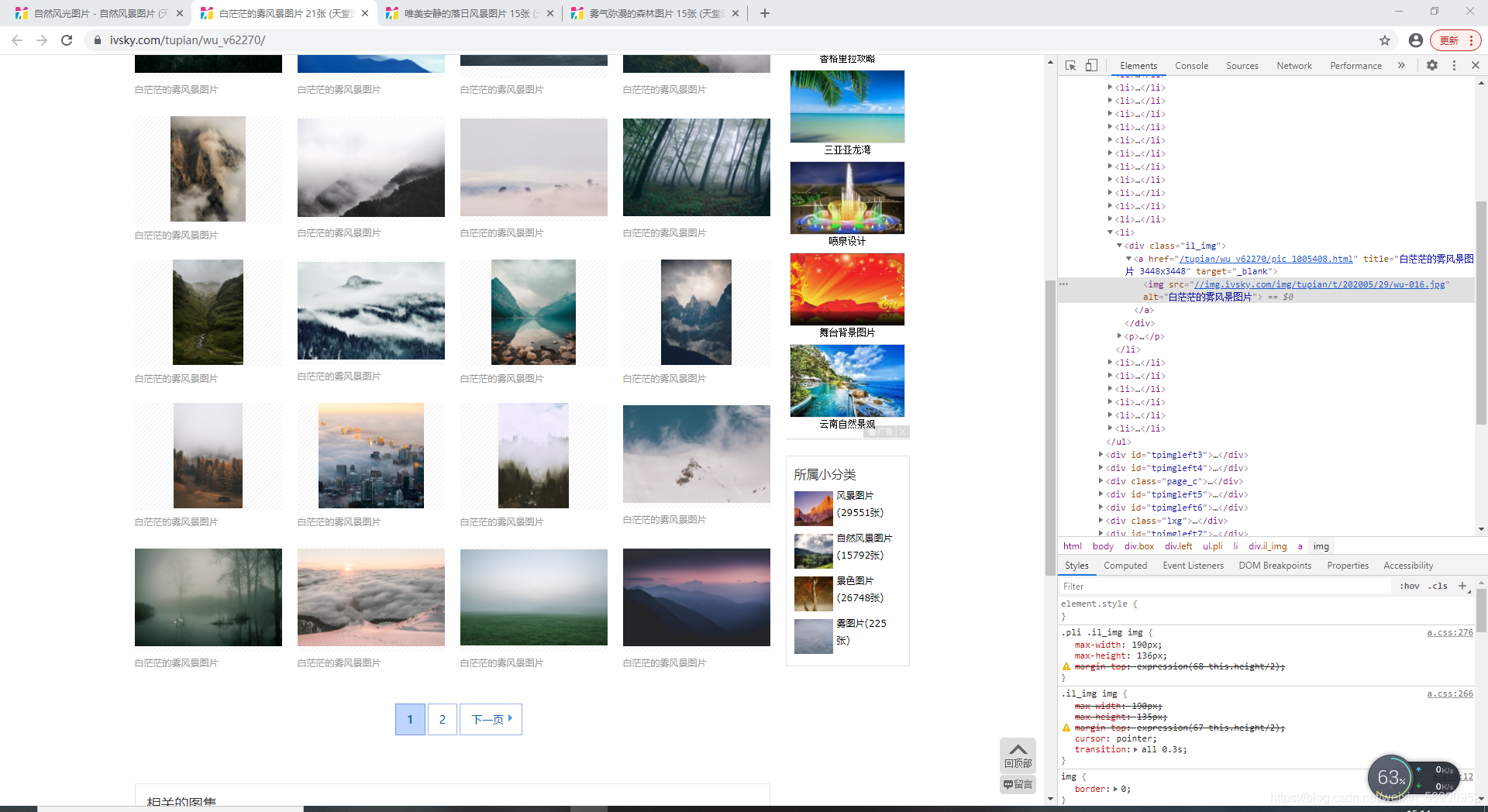
進去后是這樣的,右鍵檢查圖片也可以發現我們需要的圖片鏈接都是在這個界面的,那么到這里基本上就分析完成了,可以進行下一步了,
2.敲代碼
養成好習慣,先把網站的headers獲取一下(有些網站的訪問并不需要headers):
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'}
通過以上分析,也就是說我們要先訪問初始網頁,然后在初始界面里定位到目標網頁的url,然后訪問目標網頁,并在目標網頁里定位到具體的圖片鏈接,然后將圖片下載下來久好了,
接下來,是具體代碼實作:
1.訪問初始網頁:
url_base='https://www.ivsky.com/tupian/ziranfengguang/'
response=requests.get(url,headers=headers)#訪問網頁
html=response.text
2.定位目標網頁(這里我主要用的方法是正則運算式,當然也有很多其他的方法,看個人):
urls=re.findall('<p><a href="(.*?)" title=".*?" target="_blank">.*?</a></p>',html)#獲取鏈接
for url in urls:#遍歷鏈接
print(url)
3.訪問目標網頁
注意:以上步驟獲得的url輸出后是這樣的
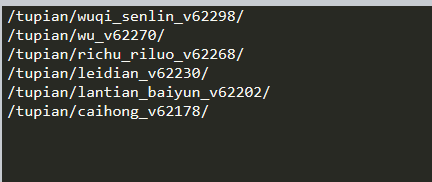
這樣的url是不能直接用requests.get方法去訪問的,也就是說,需要我們進行一些加工(可以直接手動點進去看一下網頁的具體url):
url="https://www.ivsky.com/"+url#規范格式
response=requests.get(url,headers=headers)
html1=response.text
4.定位圖片鏈接,并下載保存
我想將一個網頁下的圖片保存到一個檔案夾,所有先創建一個檔案夾,直接用它網頁的標題做檔案名(因為我個人比較懶,不想自己想名字):
dir_name=re.findall('<h1>(.*?)</h1>',html1)#以標題為檔案夾名
if not os.path.exists(str(dir_name)):#判斷檔案夾有無,沒有則生成
os.mkdir(str(dir_name))
然后定位圖片,下載:
注意:這里的圖片鏈接有跟上面一樣的問題
pics=re.findall('<div class="il_img"><a href=".*?" title=".*?" target="_blank"><img src="(.*?)" alt=".*?"></a>',html1)#獲取圖片
for pic in pics:#遍歷圖片
file_name=pic.split('/')[-1]#以/為分隔符,取最后一段作為檔案名
pic="http:"+pic#規范格式
response=requests.get(pic,headers=headers)
with open(str(dir_name) + '/' + file_name,'wb') as f:#/為分級 wb代表二進制模式檔案,允許寫入檔案,
f.write(response.content)
完整代碼:
url_base='https://www.ivsky.com/tupian/ziranfengguang/'
response=requests.get(url,headers=headers)#訪問網頁
html=response.text
urls=re.findall('<p><a href="(.*?)" title=".*?" target="_blank">.*?</a></p>',html)#獲取鏈接
for url in urls:#遍歷鏈接
url="https://www.ivsky.com/"+url#規范格式
response=requests.get(url,headers=headers)
html1=response.text
dir_name=re.findall('<h1>(.*?)</h1>',html1)#以標題為檔案夾名
if not os.path.exists(str(dir_name)):#判斷檔案夾有無,沒有則生成
os.mkdir(str(dir_name))
pics=re.findall('<div class="il_img"><a href=".*?" title=".*?" target="_blank"><img src="(.*?)" alt=".*?"></a>',html1)#獲取圖片
for pic in pics:#遍歷圖片
file_name=pic.split('/')[-1]#以/為分隔符,取最后一段作為檔案名
pic="http:"+pic#規范格式
response=requests.get(pic,headers=headers)
with open(str(dir_name) + '/' + file_name,'wb') as f:#/為分級 wb代表二進制模式檔案,允許寫入檔案,
f.write(response.content)
到這里,爬取圖片的功能已經基本實作,但是(畫重點了嗷!!!)
3.代碼完善和糾錯
很明顯的啦!每個圖片網站的圖片怎么可能只有一頁
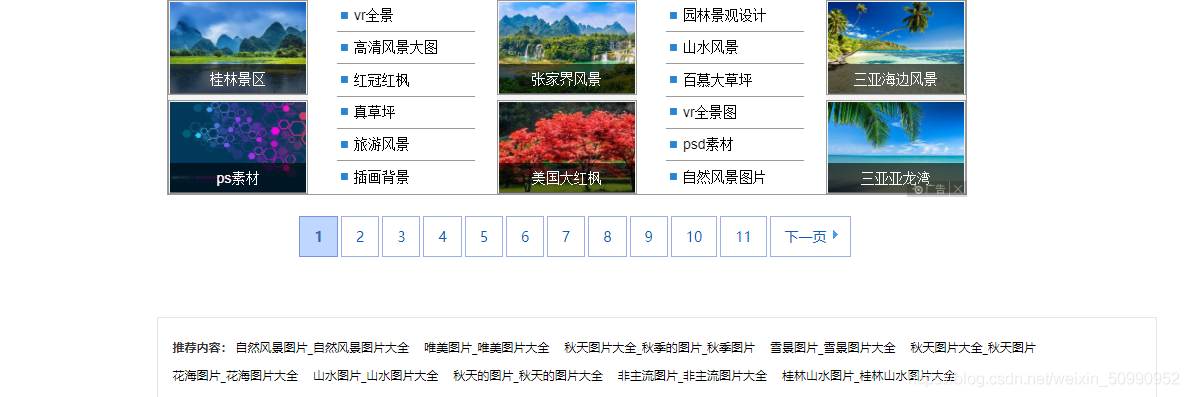
也就是說我們還需要加一個翻頁的操作,因為天堂圖片網是個靜態網頁,通過觀察他的不同頁的網址變化,其實不難找出規律:
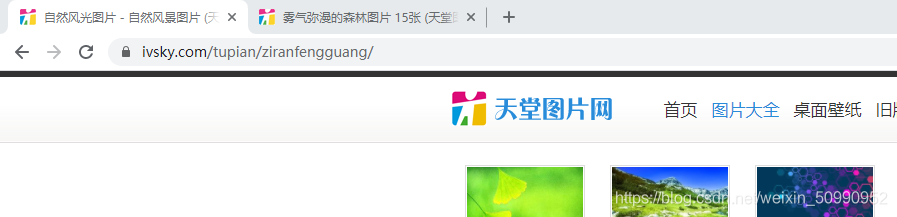
這是第一頁
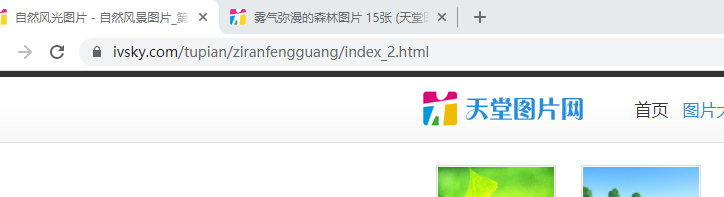
這是第二頁,一目了然嘛,
那具體代碼實作:
url_base='https://www.ivsky.com/tupian/ziranfengguang/'
for x in range(1):#定義爬取到的圖片頁
if x==1:
pass
else:
url=url_base+"index_"+str(x)+".html"
到這里,相信已經有細心的小伙伴發現了,那如果圖片頁里面也有好幾頁該這么辦呢,不可能也像上面的一樣,搞格式匹配吧,畢竟不是每個圖片頁都有好幾頁的,
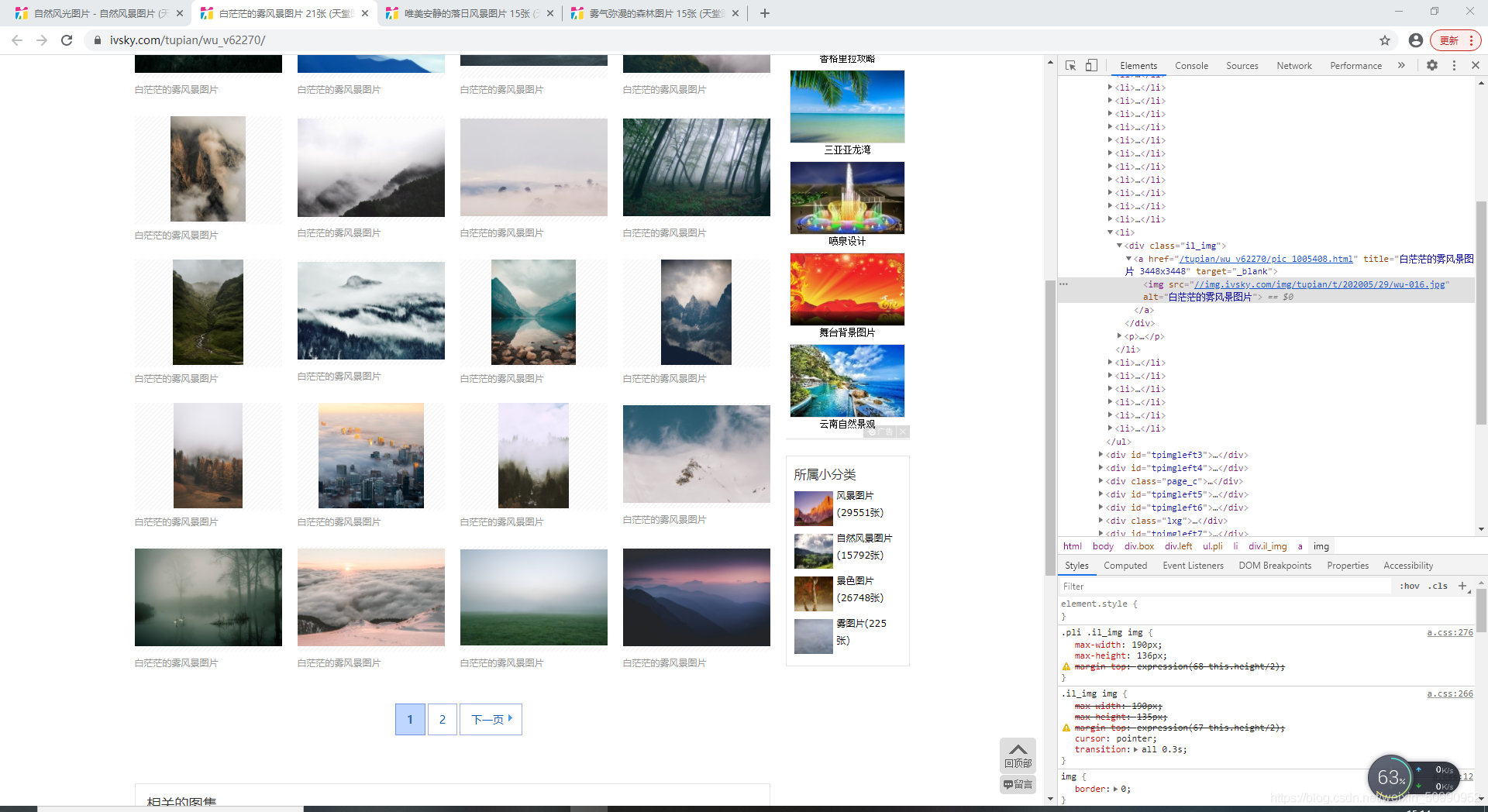
也就是說,我們在訪問每一個圖片頁后,需先對是否有下一頁進行一個判斷,然后來決定接下來的執行程序,這里就又要用到正則運算式定位了,
具體代碼實作:
next_page=re.findall("<a class='page-next' href='(.*?)'>下一頁</a>",html1)
if next_page:#如果有下一頁
for url in next_page:#因為直接得到的next_page是list型的,通過這個方式轉換為str型
url="https://www.ivsky.com/"+url
response=requests.get(url,headers=headers)
html=response.text
``````
那么到這里,我們對天堂圖片網的圖片的爬蟲才真正的已經基本上完成了,下面附上:
真—完整代碼
import requests
import re
import os
import time
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/85.0.4183.102 Safari/537.36'}
def get_pics(url):#獲取圖片函式
response=requests.get(url,headers=headers)#訪問網頁
html=response.text
urls=re.findall('<p><a href="(.*?)" title=".*?" target="_blank">.*?</a></p>',html)#獲取鏈接
for url in urls:#遍歷鏈接
time.sleep(1)
url="https://www.ivsky.com/"+url#規范格式
response=requests.get(url,headers=headers)
html1=response.text
dir_name=re.findall('<h1>(.*?)</h1>',html1)#以標題為檔案夾名
if not os.path.exists(str(dir_name)):#判斷檔案夾有無,沒有則生成
os.mkdir(str(dir_name))
down_pics(html1,dir_name)
def down_pics(html1,dir_name):
pics=re.findall('<div class="il_img"><a href=".*?" title=".*?" target="_blank"><img src="(.*?)" alt=".*?"></a>',html1)#獲取圖片
for pic in pics:#遍歷圖片
file_name=pic.split('/')[-1]#以/為分隔符,取最后一段作為檔案名
pic="http:"+pic#規范格式
response=requests.get(pic,headers=headers)
with open(str(dir_name) + '/' + file_name,'wb') as f:#/為分級 wb代表二進制模式檔案,允許寫入檔案,
f.write(response.content)
next_page=re.findall("<a class='page-next' href='(.*?)'>下一頁</a>",html1)
if next_page:#如果有下一頁
for url in next_page:
url="https://www.ivsky.com/"+url
response=requests.get(url,headers=headers)
html=response.text
down_pics(html,dir_name)
if __name__ == "__main__":
url_base='https://www.ivsky.com/tupian/ziranfengguang/'
for x in range(1):#定義爬取到的圖片頁
if x==1:
pass
else:
url=url_base+"index_"+str(x)+".html"
get_pics(url)
以上方法應該可以用于大部分靜態網頁,如果你不能爬取圖片,先考慮你的定位運算式有沒有問題,如果是可以下載但無法打開,就要考慮你的headers是否寫錯,或者是網頁設定了防盜鏈,
另外,特別提出,寫正則運算式一定要根據網頁源代碼寫,不要根據F12里面的寫
寫正則運算式一定要根據網頁源代碼寫
寫正則運算式一定要根據網頁源代碼寫
寫正則運算式一定要根據網頁源代碼寫
重要的事情說三遍!!!
(如果你一定要問我為什么,可以自己去看看上面關于next_page的F12和網頁源代碼的區別)
寫的不怎么樣,大家見諒哈!!
下面應該還會寫一個關于動態爬取圖片的方法,大家想看的可以插個眼,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/241853.html
標籤:python