Java 入門
Java簡介
Java簡介
https://www.runoob.com/java/java-intro.html
JDK、JRE、JVM
》首先是JDK
JDK(Java Development Kit) 是 Java 語言的軟體開發工具包(SDK), 在JDK的安裝目錄下有一個jre目錄,里面有兩個檔案夾bin和lib,在這里可以認為bin里的就是jvm,lib中則是jvm作業所需要的類別庫,而jvm和 lib合起來就稱為jre,
然后我們來看JRE
JRE(Java Runtime Environment,Java運行環境),包含JVM標準實作及Java核心類別庫,JRE是Java運行環境,并不是一個開發環境,所以沒有包含任何開發工具(如編譯器和除錯器)
最后JVM也一目了然了
JVM是Java Virtual Machine(Java虛擬機)的縮寫,JVM是一種用于計算設備的規范,它是一個虛構出來的計算機,是通過在實際的計算機上仿真模擬各種計算機功能來實作的,


開發環境配置
https://www.runoob.com/java/java-environment-setup.html
第一個Java程式
打開文本編輯器,輸入以下代碼:
public class HelloWorld {
/* 第一個Java程式
* 它將輸出字串 Hello World
*/
public static void main(String[] args) {
System.out.println("Hello World"); // 輸出 Hello World
}
}
在一個Java程式中,你總能找到一個類似:
public class Hello { ... }的定義,這個定義被稱為class(類),這里的類名是
Hello,大小寫敏感,class用來定義一個類,public表示這個類是公開的,public、class都是Java的關鍵字,必須小寫,Hello是類的名字,按照習慣,首字母H要大寫,而花括號{}中間則是類的定義,注意到類的定義中,我們定義了一個名為
main的方法:public static void main(String[] args) { ... }方法是可執行的代碼塊,一個方法除了方法名
main,還有用()括起來的方法引數,這里的main方法有一個引數,引數型別是String[],引數名是args,public、static用來修飾方法,這里表示它是一個公開的靜態方法,void是方法的回傳型別,而花括號{}中間的就是方法的代碼,方法的代碼每一行用
;結束,這里只有一行代碼,就是:System.out.println("Hello, world!");它用來列印一個字串到螢屏上,
Java規定,某個類定義的
public static void main(String[] args)是Java程式的固定入口方法,因此,Java程式總是從main方法開始執行,注意到Java原始碼的縮進不是必須的,但是用縮進后,格式好看,很容易看出代碼塊的開始和結束,縮進一般是4個空格或者一個tab,
最后,當我們把代碼保存為檔案時,檔案名必須是
Hello.java,而且檔案名也要注意大小寫,因為要和我們定義的類名Hello完全保持一致,
注意:類名與檔案名要一致
如何運行Java程式
Java原始碼本質上是一個文本檔案,我們需要先用javac把Hello.java編譯成位元組碼檔案Hello.class,然后,用java命令執行這個位元組碼檔案:
┌──────────────────┐
│ Hello.java │<─── source code
└──────────────────┘
│ compile
▼
┌──────────────────┐
│ Hello.class │<─── byte code
└──────────────────┘
│ execute
▼
┌──────────────────┐
│ Run on JVM │
└──────────────────┘
因此,可執行檔案javac是編譯器,而可執行檔案java就是虛擬機,
第一步,在保存Hello.java的目錄下執行命令javac Hello.java:
$ javac Hello.java
如果源代碼無誤,上述命令不會有任何輸出,而當前目錄下會產生一個Hello.class檔案:
$ ls
Hello.class Hello.java
第二步,執行Hello.class,使用命令java Hello(這里加.class和不加時一樣的):
$ java Hello
Hello, world!
注意:給虛擬機傳遞的引數Hello是我們定義的類名,虛擬機自動查找對應的class檔案并執行,
如果遇到編碼問題,我們可以使用 -encoding 選項設定 utf-8 來編譯:
javac -encoding UTF-8 HelloWorld.java
java HelloWorld
有一些童鞋可能知道,直接運行java Hello.java也是可以的:
$ java Hello.java
Hello, world!
這是Java 11新增的一個功能,它可以直接運行一個單檔案原始碼!
需要注意的是,在實際專案中,單個不依賴第三方庫的Java原始碼是非常罕見的,所以,絕大多數情況下,我們無法直接運行一個Java原始碼檔案,原因是它需要依賴其他的庫,
使用IDEA運行
https://blog.csdn.net/weixin_43838785/article/details/99105624
IDEA快捷鍵
+ psvm+Enter 快速生成main函式
+ sout+Enter 快速生成`System.out.println();`
小結
一個Java原始碼只能定義一個public型別的class,并且class名稱和檔案名要完全一致;
使用javac可以將.java原始碼編譯成.class位元組碼;
使用java可以運行一個已編譯的Java程式,引數是類名,
Java基礎
注釋
撰寫注釋的原因
撰寫程式時總需要為程式添加一些注釋,用以說明某段代碼的作用,或者說明某個類的用途、某個方法的功能,以及該方法的引數和回傳值的資料型別及意義等,
撰寫注釋的原因及意義如下
為了更好的閱讀自己撰寫的代碼,建議添加這注釋,自己寫的代碼,可能過一段時間回顧的時候,就變得不熟悉,這個時候,注釋就起到了很好的幫助作用,
可讀性第一,效率第二,一個軟體一般都是一個團隊協同作戰開發出來的,因此,一個人寫的代碼,需要被整個團隊的其他人所理解,
代碼即檔案,程式源代碼是程式檔案的重要組成部分,
注釋的語法規則
撰寫Java中的注釋不會出現在可執行程式中,因此,可以在源程式中根據需要添加任意多的注釋,而不必擔心可執行代碼會膨脹,在 Java 中,有三種書寫注釋的方式,
-
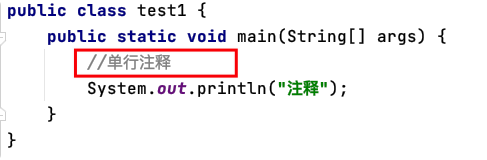
單行注釋——注釋一行
以雙斜杠“//”標識,只能注釋一行內容,用在注釋資訊內容少的地方,
-
多行注釋——注釋一段
包含在“/* ”和“ */”之間,能注釋很多行的內容,為了可讀性比較好,一般首行和尾行不寫注釋資訊(這樣也比較美觀好看),
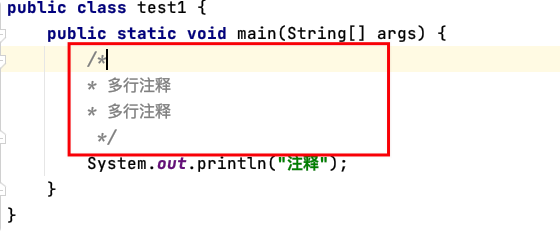
注意:多行注釋可以嵌套單行注釋,但是不能嵌套多行注釋和檔案注釋, -
檔案注釋
包含在“/** ”和“ */”之間,也能注釋多行內容,一般用在類、方法和變數上面,用來描述其作用,注釋后,滑鼠放在類和變數上面會自動顯示出我們注釋的內容,
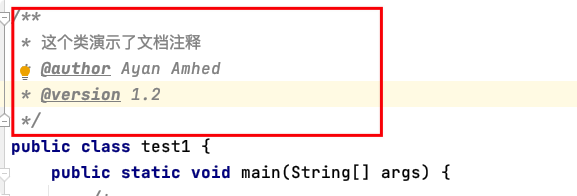
注意:檔案注釋能嵌套單行注釋,不能嵌套多行注釋和檔案注釋,一般首行和尾行也不寫注釋資訊,
識別符號和關鍵字
Java識別符號定義
-
包名、類名、方法名、引數名、變數名等,這些符號被稱為識別符號,
-
識別符號可以由字母、數字、下劃線()和美元符號($)組成
-
識別符號不能以數字開頭,不能是java中的關鍵字,例如:
-
正確的識別符號
Username、username123、user_name、_userName、$username -
不正確的識別符號:
123username、class、87.2、Hello World、num*123
-
-
首字符之后可以是字母(A-Z 或者 a-z),美元符($)、下劃線()或數字的任何字符,
-
識別符號是大小寫敏感,
Java識別符號規則
- 包名所有字母必須小寫,例如:cn.itcast.test
- 類名和介面名每個單詞的首字母都要大寫,例如:ArrayList
- 常量名所有的字母都大寫,單詞之間用下劃線連接,例如:DAY_OF_MONTH
- 變數名和方法名的第一個單詞首字母小寫,從第二個單詞開始,每個單詞首字母大寫,例如:lineName、getLingNumber
- 在程式中,應該盡量使用有意義的英文單詞來定義識別符號,使得程式便于閱讀,例如:使用userName表示用戶名,password表示密碼,
Java 關鍵字
- 下面列出了 Java 關鍵字,這些保留字不能用于常量、變數、和任何識別符號的名稱,
- 所有的關鍵字都是小寫
- 程式中的識別符號不能以關鍵字命名
- const和goto是保留字關鍵字,雖然在java中還沒有任何意義,但在程式中不能用來作為自定義的識別符號,
- true、false和null不屬于關鍵字,它們是一個單獨標識型別,不能直接使用
| 類別 | 關鍵字 | 說明 |
|---|---|---|
| 訪問控制 | private | 私有的 |
| 訪問控制 | protected | 受保護的 |
| 訪問控制 | public | 公共的 |
| 類、方法和變數修飾符 | abstract | 宣告抽象 |
| 類、方法和變數修飾符 | class | 類 |
| 類、方法和變數修飾符 | extends | 擴充,繼承 |
| 類、方法和變數修飾符 | final | 最終值,不可改變的 |
| 類、方法和變數修飾符 | implements | 實作(介面) |
| 類、方法和變數修飾符 | interface | 介面 |
| 類、方法和變數修飾符 | native | 本地,原生方法(非 Java 實作) |
| 類、方法和變數修飾符 | new | 新,創建 |
| 類、方法和變數修飾符 | static | 靜態 |
| 類、方法和變數修飾符 | strictfp | 嚴格,精準 |
| 類、方法和變數修飾符 | synchronized | 執行緒,同步 |
| 類、方法和變數修飾符 | transient | 短暫 |
| 類、方法和變數修飾符 | volatile | 易失 |
| 程式控制陳述句 | break | 跳出回圈 |
| 程式控制陳述句 | case | 定義一個值以供 switch 選擇 |
| 程式控制陳述句 | continue | 繼續 |
| 程式控制陳述句 | default | 默認 |
| 程式控制陳述句 | do | 運行 |
| 程式控制陳述句 | else | 否則 |
| 程式控制陳述句 | for | 回圈 |
| 程式控制陳述句 | if | 如果 |
| 程式控制陳述句 | instanceof | 實體 |
| 程式控制陳述句 | return | 回傳 |
| 程式控制陳述句 | switch | 根據值選擇執行 |
| 程式控制陳述句 | while | 回圈 |
| 錯誤處理 | assert | 斷言運算式是否為真 |
| 錯誤處理 | catch | 捕捉例外 |
| 錯誤處理 | finally | 有沒有例外都執行 |
| 錯誤處理 | throw | 拋出一個例外物件 |
| 錯誤處理 | throws | 宣告一個例外可能被拋出 |
| 錯誤處理 | try | 捕獲例外 |
| 包相關 | import | 引入 |
| 包相關 | package | 包 |
| 基本型別 | boolean | 布爾型 |
| 基本型別 | byte | 位元組型 |
| 基本型別 | char | 字符型 |
| 基本型別 | double | 雙精度浮點 |
| 基本型別 | float | 單精度浮點 |
| 基本型別 | int | 整型 |
| 基本型別 | long | 長整型 |
| 基本型別 | short | 短整型 |
| 變數參考 | super | 父類,超類 |
| 變數參考 | this | 本類 |
| 變數參考 | void | 無回傳值 |
| 保留關鍵字 | goto | 是關鍵字,但不能使用 |
| 保留關鍵字 | const | 是關鍵字,但不能使用 |
| 保留關鍵字 | null | 空 |
資料型別
強型別語言
強型別語言也稱為強型別定義語言,是一種總是強制型別定義的語言,要求變數的使用要嚴格符合定義,所有變量都必須先定義后使用,
Java、.Net和C++等一些語言都是強制型別定義的,也就是說,一旦一個變數被指定了某個資料型別,如果不經過強制轉換,那么它就永遠是這個資料型別了,
例如你有一個整數,如果不顯式地進行轉換,你不能將其視為一個字串,
弱型別語言
弱型別語言也稱為弱型別定義語言,與強型別定義相反,像VB,PHP等一些語言就屬于弱型別語言,
簡單理解就是一種變數型別可以被忽略的語言,
比如VBScript是弱型別定義的,在VBScript中就可以將字串'12'和整數3進行連接得到字串'123',然后可以把它看成整數123,而不用顯示轉換,但其實他們的型別沒有改變,VB只是在判斷出一個運算式含有不同型別的變數之后,自動在這些變數前加了一個clong()或(int)()這樣的轉換函式而已,能做到這一點其實是歸功于VB的編譯器的智能化而已,這并非是VB語言本身的長處或短處,
強型別語言和弱型別語言比較
強型別語言在速度上可能略遜色于弱型別語言,但是強型別語言帶來的嚴謹性可以有效地幫助避免許多錯誤,
Java 基本資料型別
變數就是申請記憶體來存盤值,也就是說,當創建變數的時候,需要在記憶體中申請空間,
記憶體管理系統根據變數的型別為變數分配存盤空間,分配的空間只能用來儲存該型別資料,
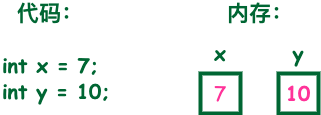
因此,通過定義不同型別的變數,可以在記憶體中儲存整數、小數或者字符,
Java 的兩大資料型別:
-
內置資料型別
-
參考資料型別

內置資料型別
Java語言提供了八種基本型別,六種數字型別(四個整數型,兩個浮點型),一種字符型別,還有一種布爾型,
byte:
- byte 資料型別是8位、有符號的,以二進制補碼表示的整數;
- 最小值是 -128(-2^7);
- 最大值是 127(2^7-1);
- 默認值是 0;
- byte 型別用在大型陣列中節約空間,主要代替整數,因為 byte 變數占用的空間只有 int 型別的四分之一;
- 例子:byte a = 100,byte b = -50,
short:
- short 資料型別是 16 位、有符號的以二進制補碼表示的整數
- 最小值是 -32768(-2^15);
- 最大值是 32767(2^15 - 1);
- Short 資料型別也可以像 byte 那樣節省空間,一個short變數是int型變數所占空間的二分之一;
- 默認值是 0;
- 例子:short s = 1000,short r = -20000,
int:
- int 資料型別是32位、有符號的以二進制補碼表示的整數;
- 最小值是 -2,147,483,648(-2^31);
- 最大值是 2,147,483,647(2^31 - 1);
- 一般地整型變數默認為 int 型別;
- 默認值是 0 ;
- 例子:int a = 100000, int b = -200000,
long:
- long 資料型別是 64 位、有符號的以二進制補碼表示的整數;
- 最小值是 -9,223,372,036,854,775,808(-2^63);
- 最大值是 9,223,372,036,854,775,807(2^63 -1);
- 這種型別主要使用在需要比較大整數的系統上;
- 默認值是 0L;
- 例子: long a = 100000L,Long b = -200000L,
"L"理論上不分大小寫,但是若寫成"l"容易與數字"1"混淆,不容易分辯,所以最好大寫,
float:
- float 資料型別是單精度、32位、符合IEEE 754標準的浮點數;
- float 在儲存大型浮點陣列的時候可節省記憶體空間;
- 默認值是 0.0f;
- 浮點數不能用來表示精確的值,如貨幣;
- 例子:float f1 = 234.5f,
double:
- double 資料型別是雙精度、64 位、符合IEEE 754標準的浮點數;
浮點數的默認型別為double型別;- double型別同樣不能表示精確的值,如貨幣;
- 默認值是 0.0d;
- 例子:double d1 = 123.4,
boolean:
- boolean資料型別表示一位的資訊;
- 只有兩個取值:true 和 false;
- 這種型別只作為一種標志來記錄 true/false 情況;
- 默認值是 false;
- 例子:boolean one = true,
char:
- char型別是一個單一的 16 位 Unicode 字符;
- 最小值是 \u0000(即為 0);
- 最大值是 \uffff(即為65、535);
- char 資料型別可以儲存任何字符;
- 例子:char letter = 'A';
型別默認值
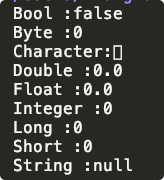
下表列出了 Java 各個型別的默認值:
| 資料型別 | 默認值 |
|---|---|
| byte | 0 |
| short | 0 |
| int | 0 |
| long | 0L |
| float | 0.0f |
| double | 0.0d |
| char | 'u0000' |
| String (or any object) | null |
| boolean | false |
public class Test {
static boolean bool;
static byte by;
static char ch;
static double d;
static float f;
static int i;
static long l;
static short sh;
static String str;
public static void main(String[] args) {
System.out.println("Bool :" + bool);
System.out.println("Byte :" + by);
System.out.println("Character:" + ch);
System.out.println("Double :" + d);
System.out.println("Float :" + f);
System.out.println("Integer :" + i);
System.out.println("Long :" + l);
System.out.println("Short :" + sh);
System.out.println("String :" + str);
}
}
對于數值型別的基本型別的取值范圍,我們無需強制去記憶,因為它們的值都已經以常量的形式定義在對應的包裝類中了,請看下面的例子:
public class PrimitiveTypeTest {
public static void main(String[] args) {
// byte
System.out.println("基本型別:byte 二進制位數:" + Byte.SIZE);
System.out.println("包裝類:java.lang.Byte");
System.out.println("最小值:Byte.MIN_VALUE="https://www.cnblogs.com/yishiyuntuan/p/+ Byte.MIN_VALUE);
System.out.println("最大值:Byte.MAX_VALUE="https://www.cnblogs.com/yishiyuntuan/p/+ Byte.MAX_VALUE);
System.out.println();
// short
System.out.println("基本型別:short 二進制位數:" + Short.SIZE);
System.out.println("包裝類:java.lang.Short");
System.out.println("最小值:Short.MIN_VALUE="https://www.cnblogs.com/yishiyuntuan/p/+ Short.MIN_VALUE);
System.out.println("最大值:Short.MAX_VALUE="https://www.cnblogs.com/yishiyuntuan/p/+ Short.MAX_VALUE);
System.out.println();
// int
System.out.println("基本型別:int 二進制位數:" + Integer.SIZE);
System.out.println("包裝類:java.lang.Integer");
System.out.println("最小值:Integer.MIN_VALUE="https://www.cnblogs.com/yishiyuntuan/p/+ Integer.MIN_VALUE);
System.out.println("最大值:Integer.MAX_VALUE="https://www.cnblogs.com/yishiyuntuan/p/+ Integer.MAX_VALUE);
System.out.println();
// long
System.out.println("基本型別:long 二進制位數:" + Long.SIZE);
System.out.println("包裝類:java.lang.Long");
System.out.println("最小值:Long.MIN_VALUE="https://www.cnblogs.com/yishiyuntuan/p/+ Long.MIN_VALUE);
System.out.println("最大值:Long.MAX_VALUE="https://www.cnblogs.com/yishiyuntuan/p/+ Long.MAX_VALUE);
System.out.println();
// float
System.out.println("基本型別:float 二進制位數:" + Float.SIZE);
System.out.println("包裝類:java.lang.Float");
System.out.println("最小值:Float.MIN_VALUE="https://www.cnblogs.com/yishiyuntuan/p/+ Float.MIN_VALUE);
System.out.println("最大值:Float.MAX_VALUE="https://www.cnblogs.com/yishiyuntuan/p/+ Float.MAX_VALUE);
System.out.println();
// double
System.out.println("基本型別:double 二進制位數:" + Double.SIZE);
System.out.println("包裝類:java.lang.Double");
System.out.println("最小值:Double.MIN_VALUE="https://www.cnblogs.com/yishiyuntuan/p/+ Double.MIN_VALUE);
System.out.println("最大值:Double.MAX_VALUE="https://www.cnblogs.com/yishiyuntuan/p/+ Double.MAX_VALUE);
System.out.println();
// char
System.out.println("基本型別:char 二進制位數:" + Character.SIZE);
System.out.println("包裝類:java.lang.Character");
// 以數值形式而不是字符形式將Character.MIN_VALUE輸出到控制臺
System.out.println("最小值:Character.MIN_VALUE="https://www.cnblogs.com/yishiyuntuan/p/+ (int) Character.MIN_VALUE);
// 以數值形式而不是字符形式將Character.MAX_VALUE輸出到控制臺
System.out.println("最大值:Character.MAX_VALUE="https://www.cnblogs.com/yishiyuntuan/p/+ (int) Character.MAX_VALUE);
}
}
編譯以上代碼輸出結果如下所示:
基本型別:byte 二進制位數:8 包裝類:java.lang.Byte 最小值:Byte.MIN_VALUE=https://www.cnblogs.com/yishiyuntuan/p/-128 最大值:Byte.MAX_VALUE=127 基本型別:short 二進制位數:16 包裝類:java.lang.Short 最小值:Short.MIN_VALUE=-32768 最大值:Short.MAX_VALUE=32767 基本型別:int 二進制位數:32 包裝類:java.lang.Integer 最小值:Integer.MIN_VALUE=-2147483648 最大值:Integer.MAX_VALUE=2147483647 基本型別:long 二進制位數:64 包裝類:java.lang.Long 最小值:Long.MIN_VALUE=-9223372036854775808 最大值:Long.MAX_VALUE=9223372036854775807 基本型別:float 二進制位數:32 包裝類:java.lang.Float 最小值:Float.MIN_VALUE=1.4E-45 最大值:Float.MAX_VALUE=3.4028235E38 基本型別:double 二進制位數:64 包裝類:java.lang.Double 最小值:Double.MIN_VALUE=4.9E-324 最大值:Double.MAX_VALUE=1.7976931348623157E308 基本型別:char 二進制位數:16 包裝類:java.lang.Character 最小值:Character.MIN_VALUE=0 最大值:Character.MAX_VALUE=65535
資料型別擴展
整數擴展
在JAVA里的進制中
0b開頭二進制 0開頭是八進制 0x開頭是十六進制點數擴展
public static void main(String[] args) {
int i1 = 10;
int i2 = 0b10; //二進制10
int i3 = 010; //八進制10
int i4 = 0x10; //十六進制10 16進制: 0~9 A~F
// 全部輸出查看結果
System.out.println(i1); //10
System.out.println(i2); //2
System.out.println(i3); //8
System.out.println(i4); //16
System.out.println("二進制輸出" + Integer.toBinaryString(i1));
System.out.println("八進制輸出" + Integer.toOctalString(i1));
System.out.printf("八進制輸出" + "%010o\n", i1);
System.out.printf("十六進制輸出" + "%010x\n", i1);
System.out.println("十六進制輸出" + Integer.toHexString(i1));
}

浮點數擴展
-
浮點數是一個離散的數,表示的值不精確且存在誤差,不適合進行數值比較
-
浮點數在計算機中是以一種類似于科學計數法的方式(IEEE 754)來存盤和運算的(計算機組成原理),
-
浮點數的計算是不精確的,它存在舍入誤差和表示大小溢位的問題,浮點數強制轉型成整數時,會舍棄掉小數,顯示整數的最大值
-
浮點數的存盤也是不精確的,它是采用二進制的方式存盤在計算機中,超出精度后溢位的部分就不會被存盤,所以會出現誤差,
public static void main(String[] args) { float f1=0.1F; double f2=0.1; System.out.println(f1==f2);//false float f3=888888888888888f; float f4=f3+1; System.out.println(f3==f4);//ture }
那么問題也來了,既然我們在程式中使用的浮點數來表示小數的時候,會出現誤差,我們在表示銀行業務的時候,應該用什么來表示賬戶余額才能使其不出現問題呢?
我們可以采用Java中提供的數學工具類BigDecimal類來對其進行表示,
注意:在Java中,最好完全避免使用浮點數來進行比較,
字符擴展
在Java中,我們通常使用''將字符包裹起來用于字符的表示,但實際上,計算機對字符的存盤是一個二進制的整數,每個正整數都對應了一個字符,這一一的對應就是Unicode編碼,Unicode編碼就是一張表,一串列示為數字,一串列示為字符,正是通過這張表將其一一對應,
char ch1 = 'A';
char ch2 = 'a';
System.out.println(ch1);//A
System.out.println((int)ch1);//65
System.out.println(ch2);//a
System.out.println((int)ch2);//97
這里就不得不說到字符中的轉義字符,我們在表示字符的時候,也可以表示成下面的這種形式,其范圍在\u0000~\uFFFF:
char ch3 = '\u0061';
System.out.println(ch3);//a
這里的\u就表示Unicode編碼,轉義字符也有很多,常見的有:
\n 回車
\r 換行
\'單引號
\"雙引號
\t水平制表符
\b空格
\\ 反斜杠
布林值擴展
boolean flag = true;
if (flag == true) {}
if (flag) {}
兩個if判斷所表示的意識完全一致,但是后者比前者更為簡潔,者一般就是新手程式員喜歡寫的,而后者一般為老程式員的習慣,我們寫代碼的時候,不僅是要完成業務邏輯的需要,我們寫出的代碼也應該簡潔精煉,在這里就不得不提到Jquery的一句話,write less,do more,寫的更少,做的更多,
型別轉換
自動型別轉換
資料型別自動轉換:將取值范圍小的型別自動轉換為取值范圍大的型別,例如:
一個 int 型別變數和一個 byte 型別變數進行相加,運算的結果是:變數的型別將是 int 型別,
同樣道理,當一個 int 型別變數和一個 double 變數運算時, int 型別將會自動提升為 double 型別進行運算,
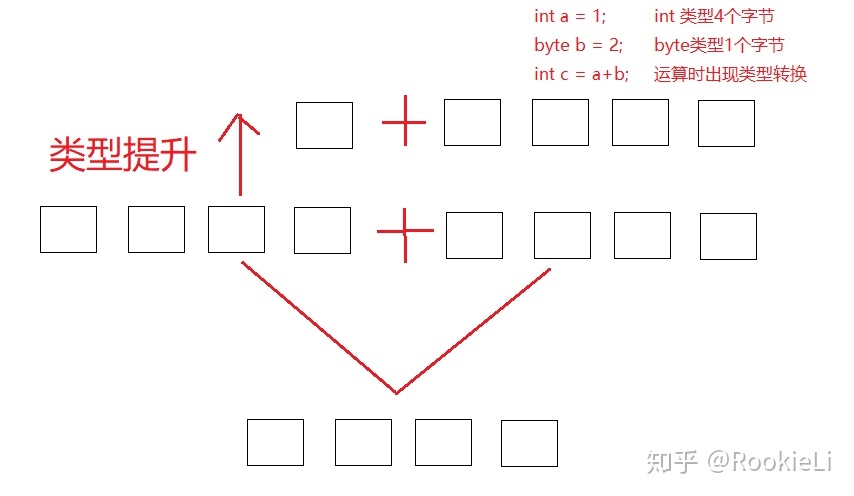
轉換規則:
范圍小的型別向范圍大的型別提升:byte、short、char 運算時候直接提升為 int,
byte、short、char‐‐>int‐‐>long‐‐>float‐‐>double,
強制型別轉換
強制型別轉換:將 取值范圍大的型別強制轉換成取值范圍小的型別 ,
比較而言,自動轉換是 Java 自動執行的,而強制轉換需要我們自己手動執行,
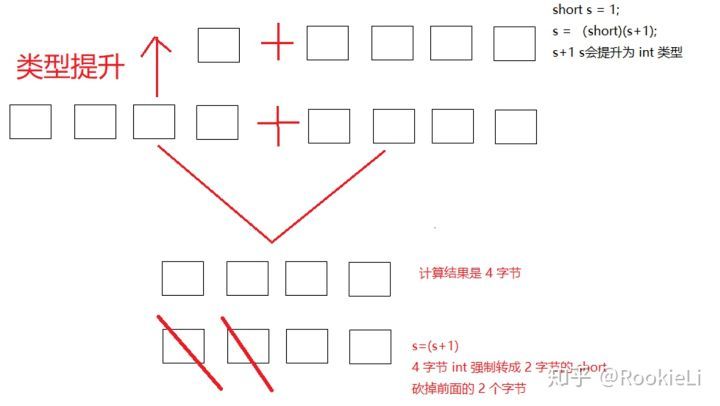
將 1.5 賦值到 int 型別變數:產生編譯失敗,無法賦值,
要修改為:
int i = (int)1.5; //但是這樣會導致 1.5 變成 1,
doubled=(int)2.5; // double型別資料強制轉成int型別,直接去掉小數點,
public static void main(String[] args) {
/**
* int a=1.5; 編譯失敗,無法賦值
*/
int i = (int)1.5;
double d=2.5;
//int型別和double型別運算,結果是double型別
//int型別會提升為double型別
double e = d + i;
System.out.println(e);
}
變數、常量、作用域
變數
變數,見名知義,就是可以變化的量,
因為Java是一種強型別的語言,每一個變數都必須宣告它們的型別,它是程式中最基本的存盤單元,其中包括變數名、變數型別和作用域,語法如下:
資料型別 變數名 [= 值] [{,變數名 [ = 值]}...];
//一行中宣告多個同型別的變數 都未賦初始值
int a, b, c;
//一行中宣告多個變數 都賦值
int d = 1, e = 2;
//一行中宣告多個變數 有賦值 有未賦值
int f, g = 3;
//一行中宣告一個變數
int age = 20;
//宣告一個參考型變數
String name = "Ara_Hu";
我們在宣告變數時,為了提高程式的可閱讀性,我們最好不要在一行中宣告多個變數,我們可以一行宣告一個變數,在某些關鍵的變數之前加上注釋,標明這個變數的用途,這樣可以大大提高我們程式的可閱讀性,
注意:
- 每個變數都需要有型別,型別可以是基本型別,也可以是參考型別
- 變數名必須是合法的識別符號
- 變數宣告是一條完整的陳述句,必須以分號結尾
- 變數在宣告后必須要賦值后才能進行使用
常量
常量,可以理解為一種特殊的變數,它的值初始化之后就不能再進行修改,它是不會變動的值,常量名一般采用大寫字符,
//宣告一個常量
final double PI = 3.14;
我們宣告常量的時候需要使用final關鍵字來對變數進行修飾,在修飾前它是一個變數,但是在通過final是修飾后,它就成為了一個常量,
**注意:常量的值,是不能進行修改的**
作用域
作用域(scope),程式設計概念,通常來說,一段程式代碼中所用到的名字并不總是有效/可用的,而限定這個名字的可用性的代碼范圍就是這個名字的作用域,
變數又分為類變數、實體變數和區域變數,三種不同型別的變數就對應著不同的作用范圍,就是它們存在著不同的作用域,
- 類變數:在類中但是獨立于方法之外的變數,用
static修飾, - 實體變數:在類中但是獨立于方法之外的變數,不過沒有
static修飾, - 區域變數:類的方法中的變數,
類變數在本類中任何地方都可直接使用,在其他類中用類名.變數名可使用;
實體變數不論在什么地方都需要先實體化本類,在通過實體化的本類的參考(new的該物件的變數名)來進行使用;
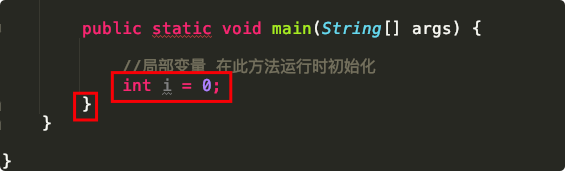
區域變數僅在宣告此變數的那段代碼中可用,一般都是在宣告此變數到最接近宣告此變數之后的}段中有效(比如下面這個圖,變數i僅在兩個紅框之間有效);
類變數:
- 在本類中可以直接使用,在其他類中可直接通過類名呼叫(ClassName.VariableName)
- 類變數通常是一個常量,為了方便呼叫,一般在類變數前面添加
public和final關鍵字,宣告為公開的常量 - 類變數在第一次被訪問時創建,在程式結束時銷毀
實體變數:
- 實體變數在物件創建的時候創建,在物件被銷毀的時候銷毀
- 實體變數可以通過變數名訪問(就是new出來的物件的變數名)
- 一般實體變數都會構建為
private私有的,然后類中提供對應的getter和setter方法來進行訪問和賦值
區域變數:
- 僅在宣告它的方法或者代碼塊中有效
- 當包含區域變數的方法或者代碼塊執行時,變數創建,結束時銷毀
- 區域變數沒有默認值,所以區域變數在被宣告后,必須初始化才能使用
public class Demo {
//類變數 在此類加載時就會初始化
static String name = "Ara_Hu";
//實體變數 在此類實體化時才會初始化
int age = 20;
public static void main(String[] args) {
//區域變數 在此方法運行時初始化
int i = 0;
}
}
基本運算子
計算機的最基本用途之一就是執行數學運算,作為一門計算機語言,Java也提供了一套豐富的運算子來操縱變數,我們可以把運算子分成以下幾組:
- 算術運算子
- 關系運算子
- 位運算子
- 邏輯運算子
- 賦值運算子
- 其他運算子
1. 算術運算子
算術運算子在數學運算式中的使用方式與在代數中使用的方式相同,下表列出了算術運算子的使用示例 -
假設整數型別變數A的值為:10,變數B的值為:20,則 -
| 運算子 | 描述 | 示例 |
|---|---|---|
+ |
加法運算子,第一個運算元加上第二個數運算元 | A + B結果為:30 |
- |
減法運算子,從第一個運算元減去第二個運算元 | A - B結果為:-10 |
* |
兩個運算元相乘 | A * B結果為:200 |
/ |
左運算元除以右運算元回傳模值 | B / A結果為:2 |
% |
左運算元除以右運算元回傳余數 | B % A結果為:0 |
++ |
將運算元的值增加1 |
A++,則A的值為:11 |
-- |
將運算元的值減1 |
A--,則A的值為:9 |
public class Test {
public static void main(String[] args) {
int a = 10;
int b = 20;
int c = 25;
int d = 25;
System.out.println("a + b = " + (a + b) );
System.out.println("a - b = " + (a - b) );
System.out.println("a * b = " + (a * b) );
System.out.println("b / a = " + (b / a) );
System.out.println("b % a = " + (b % a) );
System.out.println("c % a = " + (c % a) );
System.out.println("a++ = " + (a++) );
System.out.println("a-- = " + (a--) );
// 查看 d++ 與 ++d 的不同
System.out.println("d++ = " + (d++) );
System.out.println("++d = " + (++d) );
}
}
注意:Java中兩個整數相除,只會輸出結果的整數部分
int a=4;
int b=3;
float c = (float) a/b;
System.out.print(c);//輸出:1
//如果要的到精確的結果,要用下面的方法
int a=4;
int b=3;
float c = (float) a/(float) b;
System.out.print(c);//輸出:1.3333334
自增自減運算子
1、自增(++)自減(--)運算子是一種特殊的算術運算子,在算術運算子中需要兩個運算元來進行運算,而自增自減運算子是一個運算元,
public class selfAddMinus{
public static void main(String[] args){
int a = 3;//定義一個變數;
int b = ++a;//自增運算
int c = 3;
int d = --c;//自減運算
System.out.println("進行自增運算后的值等于"+b);
System.out.println("進行自減運算后的值等于"+d);
}
}
運行結果為:
進行自增運算后的值等于4
進行自減運算后的值等于2
決議:
- int b = ++a; 拆分運算程序為: a=a+1=4; b=a=4, 最后結果為b=4,a=4
- int d = --c; 拆分運算程序為: c=c-1=2; d=c=2, 最后結果為d=2,c=2
2、前綴自增自減法(++a,--a): 先進行自增或者自減運算,再進行運算式運算,
3、后綴自增自減法(a++,a--): 先進行運算式運算,再進行自增或者自減運算 實體:
public class selfAddMinus{
public static void main(String[] args){
int a = 5;//定義一個變數;
int b = 5;
int x = 2*++a;
int y = 2*b++;
System.out.println("自增運算子前綴運算后a="+a+",x="+x);
System.out.println("自增運算子后綴運算后b="+b+",y="+y);
}
}
運行結果為:
自增運算子前綴運算后a=6,x=12
自增運算子后綴運算后b=6,y=10
如何理解?b=++a就是先執行a=a+1,在執行b=a;
b=*--a是先執行b=a;在執行a=a+1;
對于以下,有int x = 5, y = 6, z; 題目1:z = ++x + y++; 題目2:z = ++x + x++; 題目3:x = ++x + x++; 對于上面的三道題目,我們下面一一解答,使用的技巧就是:把原始計算式轉化成多個、有先后計算順序的、小的計算式,然后帶入變數的值,進行求解,記住:同一優先級的運算子的計算順序是從右往左, Q1:z = ++x + y++; 可以轉化為: x = x +1; z = x + y; y = y + 1; 帶入x = 5, y = 6,可得x = 6; z = 12; y = 7; Q2:z = ++x + x++; 可以轉化為: x = x +1; z = x + x; x = x + 1; 帶入x = 5,可得x = 6; z = 6+6=12; x = 7; 故x=7,z=12; Q3:x = ++x + x++; 可以轉化為: x = x +1; x = x + x; x = x + 1; 帶入x = 5,可得x = 5+1=6; x = 6+6=12; x = 12+1=13; 故x=13,
溢位
整數溢位
要特別注意,整數由于存在范圍限制,如果計算結果超出了范圍,就會產生溢位,而溢位不會出錯,卻會得到一個奇怪的結果:
public class Main {
public static void main(String[] args) {
int x = 2147483640;
int y = 15;
int sum = x + y;
System.out.println(sum); // -2147483641
}
}
要解釋上述結果,我們把整數2147483640和15換成二進制做加法:
0111 1111 1111 1111 1111 1111 1111 1000 + 0000 0000 0000 0000 0000 0000 0000 1111 ----------------------------------------- 1000 0000 0000 0000 0000 0000 0000 0111
由于最高位計算結果為1,因此,加法結果變成了一個負數,
要解決上面的問題,可以把int換成long型別,由于long可表示的整型范圍更大,所以結果就不會溢位:
long x = 2147483640;
long y = 15;
long sum = x + y;
System.out.println(sum); // 2147483655
浮點數溢位
整數運算在除數為0時會報錯,而浮點數運算在除數為0時,不會報錯,但會回傳幾個特殊值:
NaN表示Not a NumberInfinity表示無窮大-Infinity表示負無窮大
例如:
double d1 = 0.0 / 0; // NaN
double d2 = 1.0 / 0; // Infinity
double d3 = -1.0 / 0; // -Infinity
這三種特殊值在實際運算中很少碰到,我們只需要了解即可,
2. 關系運算子
Java語言支持以下關系運算子,假設變數A的值是10,變數B的值是20,則 -
| 運算子 | 描述 | 示例 |
|---|---|---|
== |
等于運算子,檢查兩個運算元的值是否相等,如果相等,則條件變為真, | A==B結果為假, |
!= |
不等于運算子,檢查兩個運算元的值是否不相等,如果不相等,則條件變為真, | A!=B結果為真, |
> |
大于運算子,檢查左運算元的值是否大于右運算元的值,如果大于,則條件變為真, | A>B結果為假, |
< |
小于運算子,檢查左運算元的值是否小于右運算元的值,如果小于,則條件變為真, | A<B結果為真, |
>= |
大于或等于運算子,檢查左運算元的值是否大于等于右運算元的值,如果大于或等于,則條件變為真, | A>=B結果為假, |
<= |
小于或等于運算子,檢查左運算元的值是否小于或等于右運算元的值,如果小于或等于,則條件變為真, | A<=B結果為真, |
public class Test {
public static void main(String[] args) {
int a = 10;
int b = 20;
System.out.println("a == b = " + (a == b) );
System.out.println("a != b = " + (a != b) );
System.out.println("a > b = " + (a > b) );
System.out.println("a < b = " + (a < b) );
System.out.println("b >= a = " + (b >= a) );
System.out.println("b <= a = " + (b <= a) );
}
}
a == b = false
a != b = true
a > b = false
a < b = true
b >= a = true
b <= a = false
3. 按位運算子
移位運算
在計算機中,整數總是以二進制的形式表示,例如,int型別的整數7使用4位元組表示的二進制如下:
00000000 0000000 0000000 00000111
可以對整數進行移位運算,對整數7左移1位將得到整數14,左移兩位將得到整數28:
int n = 7; // 00000000 00000000 00000000 00000111 = 7
int a = n << 1; // 00000000 00000000 00000000 00001110 = 14
int b = n << 2; // 00000000 00000000 00000000 00011100 = 28
int c = n << 28; // 01110000 00000000 00000000 00000000 = 1879048192
int d = n << 29; // 11100000 00000000 00000000 00000000 = -536870912
左移29位時,由于最高位變成1,因此結果變成了負數,
類似的,對整數28進行右移,結果如下:
int n = 7; // 00000000 00000000 00000000 00000111 = 7
int a = n >> 1; // 00000000 00000000 00000000 00000011 = 3
int b = n >> 2; // 00000000 00000000 00000000 00000001 = 1
int c = n >> 3; // 00000000 00000000 00000000 00000000 = 0
如果對一個負數進行右移,最高位的1不動,結果仍然是一個負數:
int n = -536870912;
int a = n >> 1; // 11110000 00000000 00000000 00000000 = -268435456
int b = n >> 2; // 11111000 00000000 00000000 00000000 = -134217728
int c = n >> 28; // 11111111 11111111 11111111 11111110 = -2
int d = n >> 29; // 11111111 11111111 11111111 11111111 = -1
還有一種無符號的右移運算,使用>>>,它的特點是不管符號位,右移后高位總是補0,因此,對一個負數進行>>>右移,它會變成正數,原因是最高位的1變成了0:
int n = -536870912;
int a = n >>> 1; // 01110000 00000000 00000000 00000000 = 1879048192
int b = n >>> 2; // 00111000 00000000 00000000 00000000 = 939524096
int c = n >>> 29; // 00000000 00000000 00000000 00000111 = 7
int d = n >>> 31; // 00000000 00000000 00000000 00000001 = 1
對byte和short型別進行移位時,會首先轉換為int再進行位移,
仔細觀察可發現,左移實際上就是不斷地×2,右移實際上就是不斷地÷2,
位運算
位運算是按位進行與、或、非和異或的運算,
與運算的規則是,必須兩個數同時為1,結果才為1:
n = 0 & 0; // 0
n = 0 & 1; // 0
n = 1 & 0; // 0
n = 1 & 1; // 1
或運算的規則是,只要任意一個為1,結果就為1:
n = 0 | 0; // 0
n = 0 | 1; // 1
n = 1 | 0; // 1
n = 1 | 1; // 1
非運算的規則是,0和1互換:
n = ~0; // 1
n = ~1; // 0
異或運算的規則是,如果兩個數不同,結果為1,否則為0:
n = 0 ^ 0; // 0
n = 0 ^ 1; // 1
n = 1 ^ 0; // 1
n = 1 ^ 1; // 0
對兩個整數進行位運算,實際上就是按位對齊,然后依次對每一位進行運算,例如:
// 位運算
public class Main {
public static void main(String[] args) {
int i = 167776589; // 00001010 00000000 00010001 01001101
int n = 167776512; // 00001010 00000000 00010001 00000000
System.out.println(i & n); // 167776512
}
}
a = 0011 1100
b = 0000 1101
-----------------
a&b = 0000 1100
a|b = 0011 1101
a^b = 0011 0001
~a = 1100 0011
下面的表中列出了按位運算子,假設整數變數A=60,變數B=13,那么 -
| 運算子 | 描述 | 示例 |
|---|---|---|
& |
二進制AND運算子,如果存在于兩個運算元中,則它會將結果復制到結果中, | A & B的結果為:12,也就是:0000 1100 |
| |
二進制OR運算子,如果存在于任一運算元中,則復制一位, | A Ι B 的結果為:61,也就是:0011 1101 |
^ |
二進制異或運算子,如果在一個運算元中設定但不在兩個運算元中設定,則復制該位, | A ^ B的結果為:49,也就是:0011 0001 |
~ |
二元一元補充運算子是一元的,具有“翻轉”位的效果, | ~A的結果為:-61,也就是:1100 0011 |
<< |
二進制左移運算子,左運算元值向左移動右運算元指定的位數, | A << 2的結果為:240,也就是:1111 0000 |
>> |
二進制右移運算子,左運算元值向右移動右運算元指定的位數, | A >> 2的結果為:15,也就是:1111 |
>>> |
右移零填充運算子, 左運算元值向右移動右運算元指定的位數,移位值用零填充, | A >>>2的結果為:15,也就是:0000 1111 |
4. 邏輯運算子
下表列出了邏輯運算子 -
假設布爾變數A的值為:true,變數B 的值為:false,則 -
| 運算子 | 描述 | 示例 |
|---|---|---|
&& |
邏輯AND運算子, 如果兩個運算元都不為零,則條件成立, | (A && B)結果為:false |
|| |
邏輯OR運算子, 如果兩個運算元中的任何一個非零,則條件變為真, | (A || B)結果為:true |
! |
邏輯非運算子,用于反轉其運算元的邏輯狀態, 如果條件為真,則口邏輯NOT運算子將為false, |
!(A && B)結果為:true |
短路運算
布爾運算的一個重要特點是短路運算,如果一個布爾運算的運算式能提前確定結果,則后續的計算不再執行,直接回傳結果,
因為false && x的結果總是false,無論x是true還是false,因此,與運算在確定第一個值為false后,不再繼續計算,而是直接回傳false,
public class Main {
public static void main(String[] args) {
boolean b = 5 < 3;
boolean result = b && (5 / 0 > 0);
System.out.println(result);
}
}
如果沒有短路運算,&&后面的運算式會由于除數為0而報錯,但實際上該陳述句并未報錯,原因在于與運算是短路運算子,提前計算出了結果false,
如果變數b的值為true,則運算式變為true && (5 / 0 > 0),因為無法進行短路運算,該運算式必定會由于除數為0而報錯,可以自行測驗,
類似的,對于||運算,只要能確定第一個值為true,后續計算也不再進行,而是直接回傳true:
boolean result = true || (5 / 0 > 0); // true
5. 賦值運算子
以下是Java語言支持的賦值運算子 -
| 運算子 | 描述 | 示例 |
|---|---|---|
= |
簡單賦值運算子, 將右側運算元的值分配給左側運算元, | C = A + B將A + B的值分配給C, |
+= |
相加與賦值運算子, 它將右運算元相加到左運算元并將結果分配給左運算元, | C += A等于C = C + A, |
-= |
減去與賦值運算子, 它從左運算元中減去右運算元,并將結果賦給左運算元, | C -= A等于C = C - A, |
*= |
乘以與賦值運算子, 它將右運算元與左運算元相乘,并將結果賦給左運算元, | C *= A等于C = C * A, |
/= |
除以與賦值運算子, 它將左運算元除以右運算元,并將結果賦給左運算元, | C /= A等于C = C / A, |
%= |
模數與賦值運算子, 它使用兩個運算元來計算獲取模數,并將結果賦給左運算元, | C %= A等于C = C % A, |
<<= |
左移與賦值運算子, | C <<= 2與C = C << 2相同 |
>>= |
右移與賦值運算子, | C >>= 2與C = C >> 2相同 |
&= |
按位與賦值運算子, | C &= 2與C = C & 2相同 |
^= |
按位異或和賦值運算子, | C ^= 2與C = C ^ 2相同 |
|= |
按位包含或與賦值運算子, | C|= 2與C = C|2相同 |
6. 其它運算子
Java語言支持的其他運算子很少,
6.1. 條件運算子(???
條件運算子也稱為三元運算子, 此運算子由三個操作陣列成,用于計算布爾運算式, 運算子的目標是確定應將哪個值賦給變數, 運算子寫成 -
variable x = (expression) ? value if true : value if false
下面是一段示例代碼:
public class Test {
public static void main(String args[]) {
int a, b;
a = 10;
b = (a == 1) ? 20: 30;
System.out.println( "Value of b is : " + b );
b = (a == 10) ? 20: 30;
System.out.println( "Value of b is : " + b );
}
}
執行上面示例代碼,得到以下結果 -

6.2. instanceof運算子
此運算子僅用于物件參考變數, 運算子檢查物件是否屬于特定型別(型別別或介面型別), instanceof運算子寫成 -
( Object reference variable ) instanceof (class/interface type)
如果運算子左側的變數參考的物件是右側的類/介面型別,則結果為真, 以下是一個例子 -
public class Test {
public static void main(String args[]) {
String name = "haha";
// 當 name 的型別是 String 時,則回傳為:true
boolean result = name instanceof String;
System.out.println( result );
}
}
執行上面示例代碼,得到以下結果:
true
如果要比較的物件與右側型別兼容,則此運算子仍將回傳true, 以下是另一個例子 -
class Vehicle {}
public class Car extends Vehicle {
public static void main(String args[]) {
Vehicle a = new Car();
boolean result = a instanceof Car;
System.out.println( result );
}
}
執行上在示例代碼,得到以下結果:
true
Java運算子優先級
在Java的計算運算式中,運算優先級從高到低依次是:
()!~++--*/%+-<<>>>>>&|+=-=*=/=
記不住也沒關系,只需要加括號就可以保證運算的優先級正確,
下表中具有最高優先級的運算子在的表的最上面,最低優先級的在表的底部,
| 類別 | 運算子 | 關聯性 |
|---|---|---|
| 后綴 | () [] . (點運算子) | 左到右 |
| 一元 | expr++ expr-- | 從左到右 |
| 一元 | ++expr --expr + - ~ ! | 從右到左 |
| 乘性 | * /% | 左到右 |
| 加性 | + - | 左到右 |
| 移位 | >> >>> << | 左到右 |
| 關系 | > >= < <= | 左到右 |
| 相等 | == != | 左到右 |
| 按位與 | & | 左到右 |
| 按位異或 | ^ | 左到右 |
| 按位或 | | | 左到右 |
| 邏輯與 | && | 左到右 |
| 邏輯或 | | | | 左到右 |
| 條件 | ?: | 從右到左 |
| 賦值 | = + = - = * = / =%= >> = << =&= ^ = | = | 從右到左 |
| 逗號 | , | 左到右 |
流程控制
輸入和輸出
輸出
在前面的代碼中,我們總是使用System.out.println()來向螢屏輸出一些內容,
println是print line的縮寫,表示輸出并換行,因此,如果輸出后不想換行,可以用print():
public class Main {
public static void main(String[] args) {
System.out.print("A,");
System.out.print("B,");
System.out.print("C.");
System.out.println();
System.out.println("END");
}
}

格式化輸出
Java還提供了格式化輸出的功能,為什么要格式化輸出?因為計算機表示的資料不一定適合人來閱讀:
public class Main {
public static void main(String[] args) {
double d = 12900000;
System.out.println(d); // 1.29E7
}
}
如果要把資料顯示成我們期望的格式,就需要使用格式化輸出的功能,格式化輸出使用System.out.printf(),通過使用占位符%?,printf()可以把后面的引數格式化成指定格式:
public class Main {
public static void main(String[] args) {
double d = 3.1415926;
System.out.printf("%.2f\n", d); // 顯示兩位小數3.14
System.out.printf("%.4f\n", d); // 顯示4位小數3.1416
}
}
Java的格式化功能提供了多種占位符,可以把各種資料型別“格式化”成指定的字串:
| 占位符 | 說明 |
|---|---|
| %d | 格式化輸出整數 |
| %x | 格式化輸出十六進制整數 |
| %f | 格式化輸出浮點數 |
| %e | 格式化輸出科學計數法表示的浮點數 |
| %s | 格式化字串 |
注意,由于%表示占位符,因此,連續兩個%%表示一個%字符本身,
占位符本身還可以有更詳細的格式化引數,下面的例子把一個整數格式化成十六進制,并用0補足8位:
public class Main {
public static void main(String[] args) {
int n = 12345000;
System.out.printf("n=%d, hex=%08x", n, n); // 注意,兩個%占位符必須傳入兩個數
}
}
詳細的格式化引數請參考JDK檔案java.util.Formatter
輸入
和輸出相比,Java的輸入就要復雜得多,
java.util.Scanner 是 Java5 的新特征,我們可以通過 Scanner 類來獲取用戶的輸入,
下面是創建 Scanner 物件的基本語法(注意:通過(import陳述句匯入java.util.Scanner):
Scanner s = new Scanner(System.in);
有了Scanner物件后,通過 Scanner 類的 next() 與 nextLine() 方法獲取輸入的字串,在讀取前我們一般需要 使用 hasNext 與 hasNextLine 判斷是否還有輸入的資料:
使用 next 方法:
import java.util.Scanner;
public class ScannerDemo {
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
// 從鍵盤接收資料
// next方式接收字串
System.out.println("next方式接收:");
// 判斷是否還有輸入
if (scan.hasNext()) {
String str1 = scan.next();
System.out.println("輸入的資料為:" + str1);
}
scan.close();//關閉Scanner物件節省資源
}
}
執行以上程式輸出結果為:
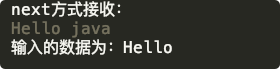
$ javac ScannerDemo.java
$ java ScannerDemo
next方式接收:
runoob com
輸入的資料為:runoob
可以看到 java 字串并未輸出,接下來我們看 nextLine,
使用 nextLine 方法:
import java.util.Scanner;
public class ScannerDemo {
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
// 從鍵盤接收資料
// nextLine方式接收字串
System.out.println("nextLine方式接收:");
// 判斷是否還有輸入
if (scan.hasNextLine()) {
String str2 = scan.nextLine();
System.out.println("輸入的資料為:" + str2);
}
scan.close();
}
}
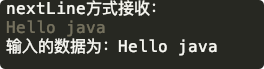
可以看到 java 字串輸出,
next() 與 nextLine() 區別
next():
- 1、一定要讀取到有效字符后才可以結束輸入,
- 2、對輸入有效字符之前遇到的空白,next() 方法會自動將其去掉,
- 3、只有輸入有效字符后才將其后面輸入的空白作為分隔符或者結束符,
- next() 不能得到帶有空格的字串,
nextLine():
- 1、以Enter為結束符,也就是說 nextLine()方法回傳的是輸入回車之前的所有字符,
- 2、可以獲得空白,
如果要輸入 int 或 float 型別的資料,在 Scanner 類中也有支持,但是在輸入之前最好先使用 hasNextXxx() 方法進行驗證,再使用 nextXxx() 來讀取:
nextBigDecimal()
nextByte()
nextShort()
nextInt()
nextLong()
nextFloat()
nextDouble()
nextBoolean()
這些方法用于讀取不同型別的資料,
import java.util.Scanner;
public class ScannerDemo {
public static void main(String[] args) {
Scanner scan = new Scanner(System.in);
// 從鍵盤接收資料
int i = 0;
float f = 0.0f;
System.out.print("輸入整數:");
if (scan.hasNextInt()) {
// 判斷輸入的是否是整數
i = scan.nextInt();
// 接收整數
System.out.println("整數資料:" + i);
} else {
// 輸入錯誤的資訊
System.out.println("輸入的不是整數!");
}
System.out.print("輸入小數:");
if (scan.hasNextFloat()) {
// 判斷輸入的是否是小數
f = scan.nextFloat();
// 接收小數
System.out.println("小數資料:" + f);
} else {
// 輸入錯誤的資訊
System.out.println("輸入的不是小數!");
}
scan.close();
}
}
輸入總結:
輸入分三步:
- 創建Scanner物件
- 獲取用戶輸入
- 關閉Scanner物件
Java回圈結構
順序結構的程式陳述句只能被執行一次,如果您想要同樣的操作執行多次,,就需要使用回圈結構,
順序結構的程式陳述句只能被執行一次,如果您想要同樣的操作執行多次,,就需要使用回圈結構,
Java中有三種主要的回圈結構:
- while 回圈
- do…while 回圈
- for 回圈
在Java5中引入了一種主要用于陣列的增強型for回圈,
while 回圈
while是最基本的回圈,它的結構為:
while( 布爾運算式 ) {
//回圈內容
}
只要布爾運算式為 true,回圈就會一直執行下去,
public class Main {
public static void main(String[] args) {
int sum = 0; // 累加的和,初始化為0
int n = 1;
while (n <= 100) { // 回圈條件是n <= 100
sum = sum + n; // 把n累加到sum中
n++; // n自身加1
}
System.out.println(sum); // 5050
}
}
注意到while回圈是先判斷回圈條件,再回圈,因此,有可能一次回圈都不做,
對于回圈條件判斷,以及自增變數的處理,要特別注意邊界條件,思考一下將下面的代碼為何沒有獲得正確結果(5051)
public class Main {
public static void main(String[] args) {
int sum = 0;
int n = 0;
while (n <= 100) {
n ++;
sum = sum + n;
}
System.out.println(sum);
}
}
5151
改為下面可得到正確結果
n ++; sum = sum + n;
如果回圈條件永遠滿足,那這個回圈就變成了死回圈,死回圈將導致100%的CPU占用,用戶會感覺電腦運行緩慢,所以要避免撰寫死回圈代碼,
如果回圈條件的邏輯寫得有問題,也會造成意料之外的結果:
public class Main {
public static void main(String[] args) {
int sum = 0;
int n = 1;
while (n > 0) {
sum = sum + n;
n ++;
}
System.out.println(n); // -2147483648
System.out.println(sum);
}
}
表面上看,上面的while回圈是一個死回圈,但是,Java的int型別有最大值,達到最大值后,再加1會變成負數,結果,意外退出了while回圈,
do…while 回圈
對于 while 陳述句而言,如果不滿足條件,則不能進入回圈,但有時候我們需要即使不滿足條件,也至少執行一次,
do…while 回圈和 while 回圈相似,不同的是,do…while 回圈至少會執行一次,
do {
//代碼陳述句
}while(布爾運算式);
注意:布爾運算式在回圈體的后面,所以陳述句塊在檢測布爾運算式之前已經執行了, 如果布爾運算式的值為 true,則陳述句塊一直執行,直到布爾運算式的值為 false,
public class Main {
public static void main(String[] args) {
int sum = 0;
int n = 1;
do {
sum = sum + n;
n ++;
} while (n <= 100);
System.out.println(sum);
}
}
使用do while回圈時,同樣要注意回圈條件的判斷,
for回圈
除了while和do while回圈,Java使用最廣泛的是for回圈,
for回圈的功能非常強大,它使用計數器實作回圈,for回圈會先初始化計數器,然后,在每次回圈前檢測回圈條件,在每次回圈后更新計數器,計數器變數通常命名為i,
for回圈執行的次數是在執行前就確定的,語法格式如下:
for(初始化; 布爾運算式; 更新) {
//代碼陳述句
}
關于 for 回圈有以下幾點說明:
- 最先執行初始化步驟,可以宣告一種型別,但可初始化一個或多個回圈控制變數,也可以是空陳述句,
- 然后,檢測布爾運算式的值,如果為 true,回圈體被執行,如果為false,回圈終止,開始執行回圈體后面的陳述句,
- 執行一次回圈后,更新回圈控制變數,
- 再次檢測布爾運算式,回圈執行上面的程序,
public class Main {
public static void main(String[] args) {
int sum = 0;
for (int i=1; i<=100; i++) {
sum = sum + i;
}
System.out.println(sum);
}
}
注意for回圈的初始化計數器總是會被執行,并且for回圈也可能回圈0次,
使用for回圈時,千萬不要在回圈體內修改計數器!在回圈體中修改計數器常常導致莫名其妙的邏輯錯誤,對于下面的代碼:
public class Main {
public static void main(String[] args) {
int[] ns = { 1, 4, 9, 16, 25 };
for (int i=0; i<ns.length; i++) {
System.out.println(ns[i]);
i = i + 1;
}
}
}
雖然不會報錯,但是,陣列元素只列印了一半,原因是回圈內部的i = i + 1導致了計數器變數每次回圈實際上加了2(因為for回圈還會自動執行i++),因此,在for回圈中,不要修改計數器的值,計數器的初始化、判斷條件、每次回圈后的更新條件統一放到for()陳述句中可以一目了然,
如果希望只訪問索引為奇數的陣列元素,應該把for回圈改寫為:
int[] ns = { 1, 4, 9, 16, 25 };
for (int i=0; i<ns.length; i=i+2) {
System.out.println(ns[i]);
}
通過更新計數器的陳述句i=i+2就達到了這個效果,從而避免了在回圈體內去修改變數i,
使用for回圈時,計數器變數i要盡量定義在for回圈中,如果變數i定義在for回圈外,那么,退出for回圈后,變數i仍然可以被訪問,這就破壞了變數應該把訪問范圍縮到最小的原則,
使用
for回圈時,計數器變數i要盡量定義在for回圈中:int[] ns = { 1, 4, 9, 16, 25 }; for (int i=0; i<ns.length; i++) { System.out.println(ns[i]); } // 無法訪問i int n = i; // compile error!如果變數
i定義在for回圈外:int[] ns = { 1, 4, 9, 16, 25 }; int i; for (i=0; i<ns.length; i++) { System.out.println(ns[i]); } // 仍然可以使用i int n = i;那么,退出
for回圈后,變數i仍然可以被訪問,這就破壞了變數應該把訪問范圍縮到最小的原則,靈活使用for回圈
for回圈還可以缺少初始化陳述句、回圈條件和每次回圈更新陳述句,例如:// 不設定結束條件: for (int i=0; ; i++) { ... } // 不設定結束條件和更新陳述句: for (int i=0; ;) { ... } // 什么都不設定: for (;;) { ... }通常不推薦這樣寫,但是,某些情況下,是可以省略
for回圈的某些陳述句的,
Java 增強 for 回圈(for each回圈)
Java5 引入了一種主要用于陣列的增強型 for 回圈,
Java 增強 for 回圈語法格式如下:
for(宣告陳述句 : 運算式) {
//代碼句子
}
宣告陳述句:宣告新的區域變數,該變數的型別必須和陣列元素的型別匹配,其作用域限定在回圈陳述句塊,其值與此時陣列元素的值相等,
運算式:運算式是要訪問的陣列名,或者是回傳值為陣列的方法,
除了陣列外,for each回圈能夠遍歷所有“可迭代”的資料型別,包括后面會介紹的List、Map等,
break和continue
無論是while回圈還是for回圈,有兩個特別的陳述句可以使用,就是break陳述句和continue陳述句,
break 關鍵字
break 主要用在回圈陳述句或者 switch 陳述句中,用來跳出整個陳述句塊,
在回圈程序中,可以使用break陳述句跳出當前回圈,
break 跳出最里層的回圈,并且繼續執行該回圈下面的陳述句,
public class Main {
public static void main(String[] args) {
for (int i=1; i<=10; i++) {
System.out.println("i = " + i);
for (int j=1; j<=10; j++) {
System.out.println("j = " + j);
if (j >= i) {
break;
}
}
// break跳到這里
System.out.println("breaked");
}
}
}
上面的代碼是兩個for回圈嵌套,因為break陳述句位于內層的for回圈,因此,它會跳出內層for回圈,但不會跳出外層for回圈,
continue 關鍵字
break會跳出當前回圈,也就是整個回圈都不會執行了,而continue則是提前結束本次回圈,直接繼續執行下次回圈,
continue 適用于任何回圈控制結構中,作用是讓程式立刻跳轉到下一次回圈的迭代,
在 for 回圈中,continue 陳述句使程式立即跳轉到更新陳述句,
在 while 或者 do…while 回圈中,程式立即跳轉到布爾運算式的判斷陳述句,
public class Main {
public static void main(String[] args) {
int sum = 0;
for (int i=1; i<=10; i++) {
System.out.println("begin i = " + i);
if (i % 2 == 0) {
continue; // continue陳述句會結束本次回圈
}
sum = sum + i;
System.out.println("end i = " + i);
}
System.out.println(sum); // 25
}
}
小結
break陳述句可以跳出當前回圈;
break陳述句通常配合if,在滿足條件時提前結束整個回圈;
break陳述句總是跳出最近的一層回圈;
continue陳述句可以提前結束本次回圈;
continue陳述句通常配合if,在滿足條件時提前結束本次回圈,
Java選擇結構
Java 條件陳述句 - if...else
if
在Java程式中,如果要根據條件來決定是否執行某一段代碼,就需要if陳述句,
if陳述句的基本語法是:
if (條件) {
// 條件滿足時執行
}
根據if的計算結果(true還是false),JVM決定是否執行if陳述句塊(即花括號{}包含的所有陳述句),
當if陳述句塊只有一行陳述句時,可以省略花括號{},但是,省略花括號并不總是一個好主意,假設某個時候,突然想給if陳述句塊增加一條陳述句時:
public class Main {
public static void main(String[] args) {
int n = 50;
if (n >= 60)
System.out.println("及格了");
System.out.println("恭喜你"); // 注意這條陳述句不是if陳述句塊的一部分
System.out.println("END");
}
}
由于使用縮進格式,很容易把兩行陳述句都看成if陳述句的執行塊,但實際上只有第一行陳述句是if的執行塊,在使用git這些版本控制系統自動合并時更容易出問題,所以不推薦忽略花括號的寫法,
else
if陳述句還可以撰寫一個else { ... },當條件判斷為false時,將執行else的陳述句塊:
public class Main {
public static void main(String[] args) {
int n = 70;
if (n >= 60) {
System.out.println("及格了");
} else {
System.out.println("掛科了");
}
System.out.println("END");
}
}
注意,else不是必須的,
還可以用多個if ... else if ...串聯,例如:
public class Main {
public static void main(String[] args) {
int n = 70;
if (n >= 90) {
System.out.println("優秀");
} else if (n >= 60) {
System.out.println("及格了");
} else {
System.out.println("掛科了");
}
System.out.println("END");
}
}
串聯的效果其實相當于:
if (n >= 90) {
// n >= 90為true:
System.out.println("優秀");
} else {
// n >= 90為false:
if (n >= 60) {
// n >= 60為true:
System.out.println("及格了");
} else {
// n >= 60為false:
System.out.println("掛科了");
}
}
在串聯使用多個if時,要特別注意判斷順序,觀察下面的代碼:
public class Main {
public static void main(String[] args) {
int n = 100;
if (n >= 60) {
System.out.println("及格了");
} else if (n >= 90) {
System.out.println("優秀");
} else {
System.out.println("掛科了");
}
}
}
執行發現,n = 100時,滿足條件n >= 90,但輸出的不是"優秀",而是"及格了",原因是if陳述句從上到下執行時,先判斷n >= 60成功后,后續else不再執行,因此,if (n >= 90)沒有機會執行了,
正確的方式是按照判斷范圍從大到小依次判斷:
// 從大到小依次判斷:
if (n >= 90) {
// ...
} else if (n >= 60) {
// ...
} else {
// ...
}
或者改寫成從小到大依次判斷:
// 從小到大依次判斷:
if (n < 60) {
// ...
} else if (n < 90) {
// ...
} else {
// ...
}
使用if時,還要特別注意邊界條件,例如:
public class Main {
public static void main(String[] args) {
int n = 90;
if (n > 90) {
System.out.println("優秀");
} else if (n >= 60) {
System.out.println("及格了");
} else {
System.out.println("掛科了");
}
}
}
假設我們期望90分或更高為“優秀”,上述代碼輸出的卻是“及格”,原因是>和>=效果是不同的,
前面講過了浮點數在計算機中常常無法精確表示,并且計算可能出現誤差,因此,判斷浮點數相等用==判斷不靠譜:
public class Main {
public static void main(String[] args) {
double x = 1 - 9.0 / 10;
if (x == 0.1) {
System.out.println("x is 0.1");
} else {
System.out.println("x is NOT 0.1");
}
}
}
正確的方法是利用差值小于某個臨界值來判斷:
public class Main {
public static void main(String[] args) {
double x = 1 - 9.0 / 10;
if (Math.abs(x - 0.1) < 0.00001) {
System.out.println("x is 0.1");
} else {
System.out.println("x is NOT 0.1");
}
}
}
判斷參考型別相等
在Java中,判斷值型別的變數是否相等,可以使用==運算子,但是,判斷參考型別的變數是否相等,==表示“參考是否相等”,或者說,是否指向同一個物件,例如,下面的兩個String型別,它們的內容是相同的,但是,分別指向不同的物件,用==判斷,結果為false:
public class Main {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "HELLO".toLowerCase();
System.out.println(s1);
System.out.println(s2);
if (s1 == s2) {
System.out.println("s1 == s2");
} else {
System.out.println("s1 != s2");
}
}
}
變數都是直接存盤的數值,所以用==比較的時候結果是true,
而對于非基本資料型別的變數,在一些書籍中稱作為 參考型別的變數,比如上面的s1就是參考型別的變數,參考型別的變數存盤的并不是 “值”本身,而是于其關聯的物件在記憶體中的地址,
? 用(==)進行比較的時候,比較的是他們在記憶體中的存放地址,所以,除非是同一個new出來的物件,他們的比較后的結果為true,否則比較后結果為false,
要判斷參考型別的變數內容是否相等,必須使用equals()方法:
public class Main {
public static void main(String[] args) {
String s1 = "hello";
String s2 = "HELLO".toLowerCase();
System.out.println(s1);
System.out.println(s2);
if (s1.equals(s2)) {
System.out.println("s1 equals s2");
} else {
System.out.println("s1 not equals s2");
}
}
}
注意:執行陳述句s1.equals(s2)時,如果變數s1為null,會報NullPointerException:
public class Main {
public static void main(String[] args) {
String s1 = null;
if (s1.equals("hello")) {
System.out.println("hello");
}
}
}
要避免NullPointerException錯誤,可以利用短路運算子&&:
public class Main {
public static void main(String[] args) {
String s1 = null;
if (s1 != null && s1.equals("hello")) {
System.out.println("hello");
}
}
}
還可以把一定不是null的物件"hello"放到前面:例如:if ("hello".equals(s)) { ... },
switch多重選擇
除了if陳述句外,還有一種條件判斷,是根據某個運算式的結果,分別去執行不同的分支,
例如,在游戲中,讓用戶選擇選項:
- 單人模式
- 多人模式
- 退出游戲
這時,switch陳述句就派上用場了,
switch陳述句根據switch (運算式)計算的結果,跳轉到匹配的case結果,然后繼續執行后續陳述句,直到遇到break結束執行,
switch case 陳述句語法格式如下
switch(expression){
case value :
//陳述句
break; //可選
case value :
//陳述句
break; //可選
//你可以有任意數量的case陳述句
······
default : //可選
//陳述句
}
switch case 陳述句有如下規則:
- switch 陳述句中的變數型別可以是: byte、short、int 或者 char,從 Java SE 7 開始,switch 支持字串 String 型別了,同時 case 標簽必須為字串常量或字面量,
- switch 陳述句可以擁有多個 case 陳述句,每個 case 后面跟一個要比較的值和冒號,
- case 陳述句中的值的資料型別必須與變數的資料型別相同,而且只能是常量或者字面常量,
- 當變數的值與 case 陳述句的值相等時,那么 case 陳述句之后的陳述句開始執行,直到 break 陳述句出現才會跳出 switch 陳述句,
- 當遇到 break 陳述句時,switch 陳述句終止,程式跳轉到 switch 陳述句后面的陳述句執行,case 陳述句不必須要包含 break 陳述句,如果沒有 break 陳述句出現,程式會繼續執行下一條 case 陳述句,直到出現 break 陳述句,
- switch 陳述句可以包含一個 default 分支,該分支一般是 switch 陳述句的最后一個分支(可以在任何位置,但建議在最后一個),default 在沒有 case 陳述句的值和變數值相等的時候執行,default 分支不需要 break 陳述句,
switch case 執行時,一定會先進行匹配,匹配成功回傳當前 case 的值,再根據是否有 break,判斷是否繼續輸出,或是跳出判斷,
public class Test {
public static void main(String args[]){
//char grade = args[0].charAt(0);
char grade = 'C';
switch(grade)
{
case 'A' :
System.out.println("優秀");
break;
case 'B' :
case 'C' :
System.out.println("良好");
break;
case 'D' :
System.out.println("及格");
break;
case 'F' :
System.out.println("你需要再努力努力");
break;
default :
System.out.println("未知等級");
}
System.out.println("你的等級是 " + grade);
}
}
以上代碼編譯運行結果如下:
良好
你的等級是 C
對于多個==判斷的情況,使用switch結構更加清晰,
同時注意,上述“翻譯”只有在switch陳述句中對每個case正確撰寫了break陳述句才能對應得上,
使用switch時,注意case陳述句并沒有花括號{},而且,case陳述句具有“穿透性”,漏寫break將導致意想不到的結果:如果 case 陳述句塊中沒有break 陳述句時,JVM 并不會順序輸出每一個case對應的回傳值,而是繼續匹配,匹配不成功則回傳默認 case,匹配成功后,從當前 case 開始,后續所有case的值都會輸出,
public class Test {
public static void main(String args[]){
int i = 5;
//int i = 1;
switch(i){
case 0:
System.out.println("0");
case 1:
System.out.println("1");
case 2:
System.out.println("2");
default:
System.out.println("default");
}
}
}
以上代碼編譯運行結果如下:
default
1
2
default
編譯檢查
使用IDE時,可以自動檢查是否漏寫了break陳述句和default陳述句,方法是打開IDE的編譯檢查,
在Idea中,選擇
Preferences-Editor-Inspections-Java-Control flow issues,將以下檢查標記為Warning:
- Fallthrough in 'switch' statement
- 'switch' statement without 'default' branch
當
switch陳述句存在問題時,即可在IDE中獲得警告提示,
switch運算式
使用switch時,如果遺漏了break,就會造成嚴重的邏輯錯誤,而且不易在源代碼中發現錯誤,從Java 12開始,switch陳述句升級為更簡潔的運算式語法,使用類似模式匹配(Pattern Matching)的方法,保證只有一種路徑會被執行,并且不需要break陳述句:
public class Main {
public static void main(String[] args) {
String fruit = "apple";
switch (fruit) {
case "apple" -> System.out.println("Selected apple");
case "pear" -> System.out.println("Selected pear");
case "mango" -> {
System.out.println("Selected mango");
System.out.println("Good choice!");
}
default -> System.out.println("No fruit selected");
}
}
}
Selected apple
這樣可以獲得更簡潔的代碼,
yield
大多數時候,在switch運算式內部,我們會回傳簡單的值,
但是,如果需要復雜的陳述句,我們也可以寫很多陳述句,放到{...}里,然后,用yield回傳一個值作為switch陳述句的回傳值:
public class Main {
public static void main(String[] args) {
String fruit = "orange";
int opt = switch (fruit) {
case "apple" -> 1;
case "pear", "mango" -> 2;
default -> {
int code = fruit.hashCode();
yield code; // switch陳述句回傳值
}
};
System.out.println("opt = " + opt);
}
}
Java陣列
陣列對于每一門編程語言來說都是重要的資料結構之一,當然不同語言對陣列的實作及處理也不盡相同,
Java 語言中提供的陣列是用來存盤固定大小的同型別元素,
宣告陣列變數
首先必須宣告陣列變數,才能在程式中使用陣列,下面是宣告陣列變數的語法:
dataType[] arrayRefVar; // 首選的方法
或
dataType arrayRefVar[]; // 效果相同,但不是首選方法
注意: 建議使用 dataType[] arrayRefVar 的宣告風格宣告陣列變數, dataType arrayRefVar[] 風格是來自 C/C++ 語言 ,在Java中采用是為了讓 C/C++ 程式員能夠快速理解java語言,
創建陣列
Java語言使用new運算子來創建陣列,語法如下:
arrayRefVar = new dataType[arraySize];
上面的語法陳述句做了兩件事:
- 一、使用
dataType[arraySize]創建了一個陣列, - 二、把新創建的陣列的參考賦值給變數
arrayRefVar,
陣列變數的宣告,和創建陣列可以用一條陳述句完成,如下所示:
dataType[] arrayRefVar = new dataType[arraySize];
另外,也可以在定義陣列時直接指定初始化的元素,這樣就不必寫出陣列大小,而是由編譯器自動推算陣列大小,
dataType[] arrayRefVar = new dataType[]{value0, value1, ..., valuek};
//或
dataType[] arrayRefVar = {value0, value1, ..., valuek};
Java的陣列有幾個特點:
- 陣列所有元素初始化為默認值,整型都是
0,浮點型是0.0,布爾型是false; - 陣列一旦創建后,大小就不可改變,
注意:
- 要訪問陣列中的某一個元素,需要使用索引,陣列索引從
0開始,例如,5個元素的陣列,索引范圍是0~4,- 可以修改陣列中的某一個元素,使用賦值陳述句,例如,
ns[1] = 79;,- 可以用
陣列變數.length獲取陣列大小;- 陣列是參考型別,在使用索引訪問陣列元素時,如果索引超出范圍,運行時將報錯;
注意陣列是參考型別,并且陣列大小不可變,我們觀察下面的代碼:
public class Main {
public static void main(String[] args) {
// 5位同學的成績:
int[] ns;
ns = new int[] { 68, 79, 91, 85, 62 };
System.out.println(ns.length); // 5
ns = new int[] { 1, 2, 3 };
System.out.println(ns.length); // 3
}
}
陣列大小變了嗎?看上去好像是變了,但其實根本沒變,
對于陣列ns來說,執行ns = new int[] { 68, 79, 91, 85, 62 };時,它指向一個5個元素的陣列:
ns
│
▼
┌───┬───┬───┬───┬───┬───┬───┐
│ │68 │79 │91 │85 │62 │ │
└───┴───┴───┴───┴───┴───┴───┘
執行ns = new int[] { 1, 2, 3 };時,它指向一個新的3個元素的陣列:
ns ──────────────────────┐
│
▼
┌───┬───┬───┬───┬───┬───┬───┬───┬───┬───┬───┐
│ │68 │79 │91 │85 │62 │ │ 1 │ 2 │ 3 │ │
└───┴───┴───┴───┴───┴───┴───┴───┴───┴───┴───┘
但是,原有的5個元素的陣列并沒有改變,只是無法通過變數ns參考到它們而已,
字串陣列
如果陣列元素不是基本型別,而是一個參考型別,那么,修改陣列元素會有哪些不同?
字串是參考型別,因此我們先定義一個字串陣列:
String[] names = {
"ABC", "XYZ", "zoo"
};
對于String[]型別的陣列變數names,它實際上包含3個元素,但每個元素都指向某個字串物件:
┌─────────────────────────┐
names │ ┌─────────────────────┼───────────┐
│ │ │ │ │
▼ │ │ ▼ ▼
┌───┬───┬─┴─┬─┴─┬───┬───────┬───┬───────┬───┬───────┬───┐
│ │???│???│???│ │ "ABC" │ │ "XYZ" │ │ "zoo" │ │
└───┴─┬─┴───┴───┴───┴───────┴───┴───────┴───┴───────┴───┘
│ ▲
└─────────────────┘
對names[1]進行賦值,例如names[1] = "cat";,效果如下:
┌─────────────────────────────────────────────────┐
names │ ┌─────────────────────────────────┐ │
│ │ │ │ │
▼ │ │ ▼ ▼
┌───┬───┬─┴─┬─┴─┬───┬───────┬───┬───────┬───┬───────┬───┬───────┬───┐
│ │???│???│???│ │ "ABC" │ │ "XYZ" │ │ "zoo" │ │ "cat" │ │
└───┴─┬─┴───┴───┴───┴───────┴───┴───────┴───┴───────┴───┴───────┴───┘
│ ▲
└─────────────────┘
這里注意到原來names[1]指向的字串"XYZ"并沒有改變,僅僅是將names[1]的參考從指向"XYZ"改成了指向"cat",其結果是字串"XYZ"再也無法通過names[1]訪問到了,
陣列操作
有了陣列,我們還需要來操作它,而陣列最常見的一個操作就是遍歷,
通過for回圈就可以遍歷陣列,因為陣列的每個元素都可以通過索引來訪問,因此,使用標準的for回圈可以完成一個陣列的遍歷:
public class Main {
public static void main(String[] args) {
int[] ns = { 1, 4, 9, 16, 25 };
for (int i=0; i<ns.length; i++) {
int n = ns[i];
System.out.println(n);
}
}
}
為了實作for回圈遍歷,初始條件為i=0,因為索引總是從0開始,繼續回圈的條件為i<ns.length,因為當i=ns.length時,i已經超出了索引范圍(索引范圍是0 ~ ns.length-1),每次回圈后,i++,
第二種方式是使用for each回圈,直接迭代陣列的每個元素:
public class Main {
public static void main(String[] args) {
int[] ns = { 1, 4, 9, 16, 25 };
for (int n : ns) {
System.out.println(n);
}
}
}
注意:在for (int n : ns)回圈中,變數n直接拿到ns陣列的元素,而不是索引,
顯然for each回圈更加簡潔,但是,for each回圈無法拿到陣列的索引,因此,到呼叫哪一種for回圈,取決于我們的需要,
列印陣列內容
直接列印陣列變數,得到的是陣列在JVM中的參考地址:
int[] ns = { 1, 1, 2, 3, 5, 8 };
System.out.println(ns); // 類似 [I@7852e922
這并沒有什么意義,因為我們希望列印的陣列的元素內容,因此,使用for each回圈來列印它:
int[] ns = { 1, 1, 2, 3, 5, 8 };
for (int n : ns) {
System.out.print(n + ", ");
}
使用for each回圈列印也很麻煩,幸好Java標準庫提供了Arrays.toString(),可以快速列印陣列內容:
陣列排序
Java的標準庫已經內置了排序功能,我們只需要呼叫JDK提供的Arrays.sort()就可以排序:
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[] ns = { 28, 12, 89, 73, 65, 18, 96, 50, 8, 36 };
Arrays.sort(ns);
System.out.println(Arrays.toString(ns));
}
}
必須注意,對陣列排序實際上修改了陣列本身,
Arrays 類
java.util.Arrays 類能方便地操作陣列,它提供的所有方法都是靜態的,
具有以下功能:
- 給陣列賦值:通過 fill 方法,
- 對陣列排序:通過 sort 方法,按升序,
- 比較陣列:通過 equals 方法比較陣列中元素值是否相等,
- 查找陣列元素:通過 binarySearch 方法能對排序好的陣列進行二分查找法操作,
陣列的其他用法
陣列作為函式的引數
陣列可以作為引數傳遞給方法,
例如,下面的例子就是一個列印 int 陣列中元素的方法:
public static void printArray(int[] array) {
for (int i = 0; i < array.length; i++) {
System.out.print(array[i] + " ");
}
}
下面例子呼叫 printArray 方法列印出 3,1,2,6,4 和 2:
printArray(new int[]{3, 1, 2, 6, 4, 2});
陣列作為函式的回傳值
public static int[] reverse(int[] list) {
int[] result = new int[list.length];
for (int i = 0, j = result.length - 1; i < list.length; i++, j--) {
result[j] = list[i];
}
return result;
}
多維陣列
多維陣列可以看成是陣列的陣列,比如二維陣列就是一個特殊的一維陣列,其每一個元素都是一個一維陣列,例如:
String str[][] = new String[3][4];
二維陣列就是陣列的陣列,
public class Main {
public static void main(String[] args) {
int[][] ns = {
{ 1, 2, 3, 4 },
{ 5, 6, 7, 8 },
{ 9, 10, 11, 12 }
};
System.out.println(ns.length); // 3
}
}
因為ns包含3個陣列,因此,ns.length為3,實際上ns在記憶體中的結構如下:
┌───┬───┬───┬───┐
┌───┐ ┌──>│ 1 │ 2 │ 3 │ 4 │
ns ─────>│???│──┘ └───┴───┴───┴───┘
├───┤ ┌───┬───┬───┬───┐
│???│─────>│ 5 │ 6 │ 7 │ 8 │
├───┤ └───┴───┴───┴───┘
│???│──┐ ┌───┬───┬───┬───┐
└───┘ └──>│ 9 │10 │11 │12 │
└───┴───┴───┴───┘
如果我們定義一個普通陣列arr0,然后把ns[0]賦值給它:
public class Main {
public static void main(String[] args) {
int[][] ns = {
{ 1, 2, 3, 4 },
{ 5, 6, 7, 8 },
{ 9, 10, 11, 12 }
};
int[] arr0 = ns[0];
System.out.println(arr0.length); // 4
}
}
實際上arr0就獲取了ns陣列的第0個元素,因為ns陣列的每個元素也是一個陣列,因此,arr0指向的陣列就是{ 1, 2, 3, 4 },在記憶體中,結構如下:
arr0 ─────┐
▼
┌───┬───┬───┬───┐
┌───┐ ┌──>│ 1 │ 2 │ 3 │ 4 │
ns ─────>│???│──┘ └───┴───┴───┴───┘
├───┤ ┌───┬───┬───┬───┐
│???│─────>│ 5 │ 6 │ 7 │ 8 │
├───┤ └───┴───┴───┴───┘
│???│──┐ ┌───┬───┬───┬───┐
└───┘ └──>│ 9 │10 │11 │12 │
└───┴───┴───┴───┘
訪問二維陣列的某個元素需要使用array[row][col],例如:
System.out.println(ns[1][2]); // 7
二維陣列的每個陣列元素的長度并不要求相同,例如,可以這么定義ns陣列:
int[][] ns = {
{ 1, 2, 3, 4 },
{ 5, 6 },
{ 7, 8, 9 }
};
這個二維陣列在記憶體中的結構如下:
┌───┬───┬───┬───┐
┌───┐ ┌──>│ 1 │ 2 │ 3 │ 4 │
ns ─────>│???│──┘ └───┴───┴───┴───┘
├───┤ ┌───┬───┐
│???│─────>│ 5 │ 6 │
├───┤ └───┴───┘
│???│──┐ ┌───┬───┬───┐
└───┘ └──>│ 7 │ 8 │ 9 │
└───┴───┴───┘
要列印一個二維陣列,可以使用兩層嵌套的for回圈:
for (int[] arr : ns) {
for (int n : arr) {
System.out.print(n);
System.out.print(', ');
}
System.out.println();
}
或者使用Java標準庫的Arrays.deepToString():
import java.util.Arrays;
public class Main {
public static void main(String[] args) {
int[][] ns = {
{ 1, 2, 3, 4 },
{ 5, 6, 7, 8 },
{ 9, 10, 11, 12 }
};
System.out.println(Arrays.deepToString(ns));
}
}
多維陣列的動態初始化(以二維陣列為例)
- 直接為每一維分配空間,格式如下:
type[][] typeName = new type[typeLength1][typeLength2];
type 可以為基本資料型別和復合資料型別,arraylength1 和 arraylength2 必須為正整數,arraylength1 為行數,arraylength2 為列數,
例如:int a[][] = new int[2][3];
- 從最高維開始,分別為每一維分配空間,例如:
String s[][] = new String[2][];
s[0] = new String[2];
s[1] = new String[3];
s[0][0] = new String("Good");
s[0][1] = new String("Luck");
s[1][0] = new String("to");
s[1][1] = new String("you");
s[1][2] = new String("!");

多維陣列的參考(以二維陣列為例)
對二維陣列中的每個元素,參考方式為 arrayName[index1][index2],例如:
num[1][0];
命令列引數
Java程式的入口是main方法,而main方法可以接受一個命令列引數,它是一個String[]陣列,
這個命令列引數由JVM接收用戶輸入并傳給main方法:
public class Main {
public static void main(String[] args) {
for (String arg : args) {
System.out.println(arg);
}
}
}
我們可以利用接收到的命令列引數,根據不同的引數執行不同的代碼,例如,實作一個-version引數,列印程式版本號:
public class Main {
public static void main(String[] args) {
for (String arg : args) {
if ("-version".equals(arg)) {
System.out.println("v 1.0");
break;
}
}
}
}
上面這個程式必須在命令列執行,我們先編譯它:
$ javac Main.java
然后,執行的時候,給它傳遞一個-version引數:
$ java Main -version
v 1.0
這樣,程式就可以根據傳入的命令列引數,作出不同的回應,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/243117.html
標籤:Java
上一篇:為什么 StackOverflow 上的代碼片段會摧毀你的專案?
下一篇:Spring-AOP核心