作者:Joker
https://meandni.com/2020/05/12/3619/
前言
大家都知道,程式中的所有資訊都是以二進制的形式存盤在計算機的底層,也就是說我們在代碼中定義的一個 char 字符或者一個 int 整數都會被轉換成二進制碼儲存起來,這個程序可以被稱為編碼,而將計算機底層的二進制碼轉換成螢屏上有意義的字符(如“hello world”),這個程序就稱為解碼,
在計算機中字符的編解碼就涉及到字符集(Character Set)這個概念,他就相當于能夠將一個字符與一個整數一一對應的一個映射表,常見的字符集有 ASCII、Unicode 等,
很多時候我們會將字符集的編碼與字符集混為一談,從這里就可以看出它們并非同一個概念,字符集僅僅是一個字符的集合,而編碼卻是一個更復雜的程序,至于為什么會經常將這兩個概念放在一起,他們之間的聯系是什么,我們經常使用的 UTF-8 又是什么,這就是這篇文章我要討論的話題,
ASCII 編碼
歷史中的很長一段時間里,計算機僅僅應用在歐洲的一些發達國家,因此在他們的程式中只存在他們所理解的拉丁字母(如a、b、c、d等)和阿拉伯數字,他們在編碼解碼時也只需要考慮這一種情況,就是如何將這些字符轉換成計算機所能理解的二進制數,
此時 ASCII 字符集應運而生,他們在編碼時只需要對照著 ASCII 字符集,每當在程式中遇到字符 a 時,就會相應的找到其中 a 對應的 ASCII 值 97 然后以二進制形式存起來即可,
下圖展示了 ASCII 字符集對照表,其中包括了控制字符(回車鍵、退格、換行鍵等)和可顯示字符(英文大小寫字符、阿拉伯數字和西文符號),
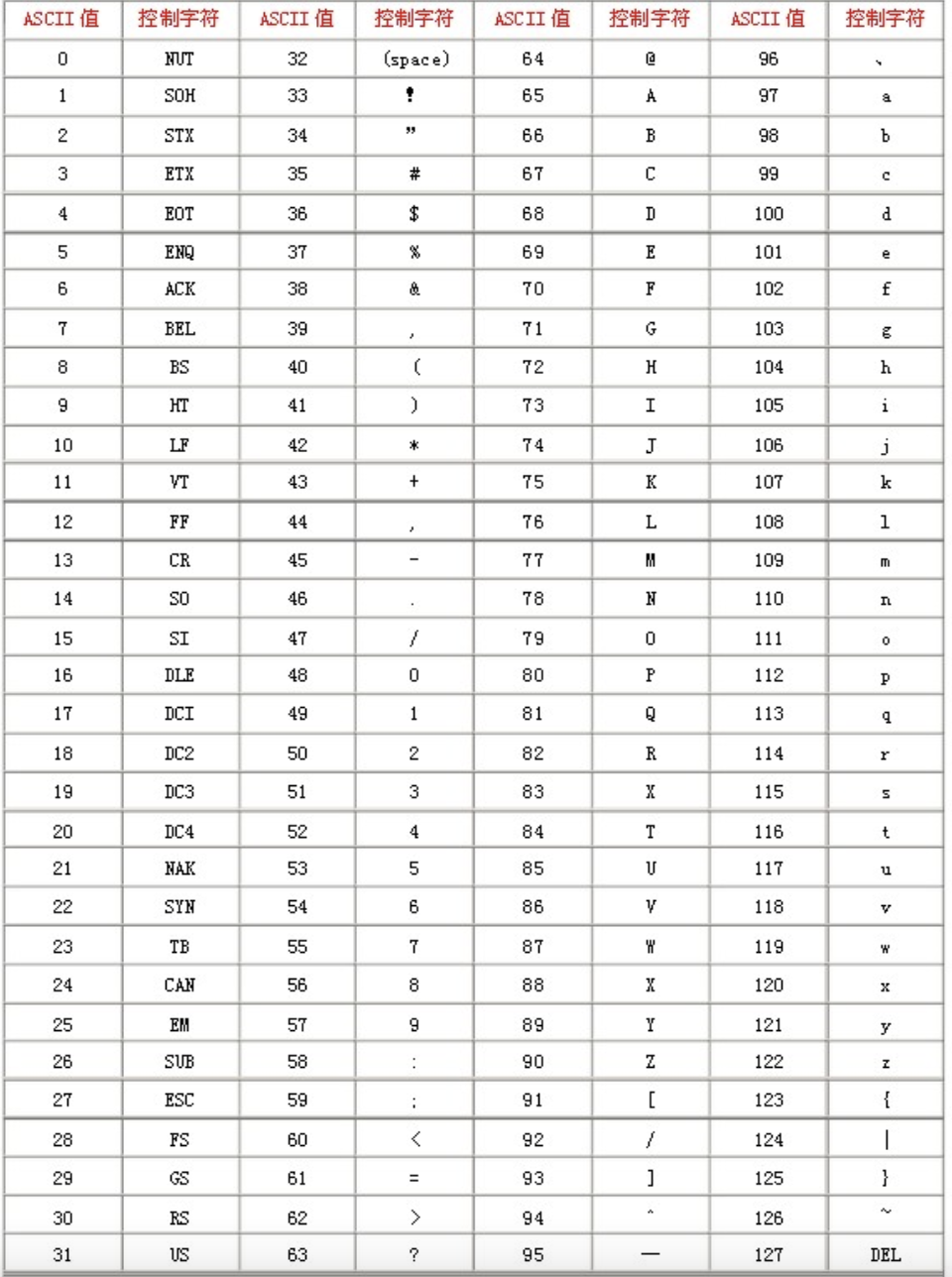
這種編碼方式就被稱為 ASCII 編碼,從字符集對照表中可以看出,ASCII 字符集支持 128 種字符,僅使用 7 個 bit 位,也就是一個位元組的后 7 位就可以將它們全部表示出來,而最前面的一位統一規定為 0 即可(如 0110 0001 表示 a),
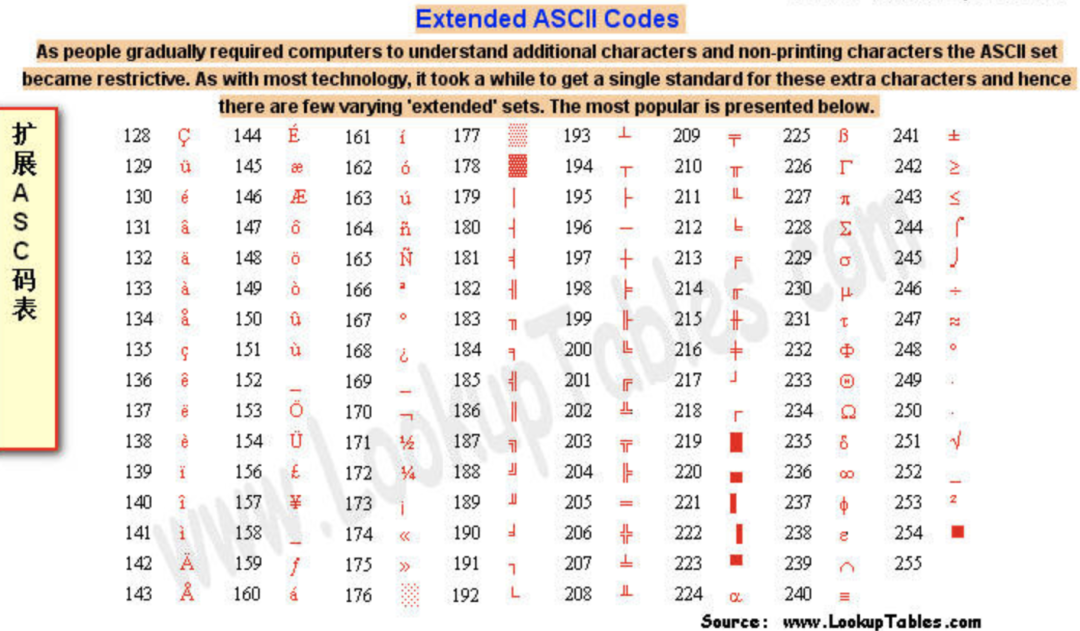
后來,為了能夠表示更多的歐洲國家的常用字符如法語中帶符號的字符é,又制定了 ASCII 額外擴展的版本 EASCII,這里就可以使用一個完整子節的 8 個 bit 位表示共 256 個字符,其中就又包括了一些衍生的拉丁字母,
非ASCII編碼
ASCII 字符集沿用至今,但它最大的缺點在于只能表示基本的拉丁字母、阿拉伯數字和英式標點符號,因此只能表示現代美國英語(而且在處理英語當中的外來詞如 na?ve、café、élite 等等單詞時,所有重音符號都不得不去掉),而 EASCII 雖然解決了部分西歐語言的顯示問題,但是當計算機傳入亞洲之后,各國的語言依然不能完整地表示出來,
在這個年代,每個國家就各自來對 ASCII 字符集做了拓展,最具代表性的就是國內的 GB 類的漢字編碼模式,這種模式規定:ASCII 值小于 127 的字符的意義與原來 ASCII 集中的字符相同,但當兩個 ASCII 值大于 127 的字符連在一起時,就表示一個簡體中文的漢字,前面的一個位元組(高位元組)從 0xA1 拓展到 0xF7,后面一個位元組(低位元組)從 0xA1 到 0xFE,這樣就可以組合出了大約 7000 多個簡體漢字了,
為了在解碼時操作的統一,GB 類編碼表中還也加入了數學符號、羅馬希臘的字母、日文的假名等,連在 ASCII 里本來就有的數字、標點、字母都統一重新表示為了兩個位元組長的編碼,這就是我們常說的 “全角” 字符,而原來在 127 號以下的那些就叫 “半角” 字符了,這種編碼規則就是后來的 GB2312,
> “一個漢字算兩個英文字符!一個漢字算兩個英文字符……”
下圖展示了 GB2312 字符集中的一小部分,具體可查看 GB2312 簡體中文編碼表(http://www.knowsky.com/resource/gb2312tbl.htm),

這樣,我們中國就有了屬于自己的字符集了,但中國的漢字實在是太多了,人們很快就發現 GB2312 字符集只能夠那點漢字明顯不夠(如中國前總理朱镕基的 “镕” 字并不在 GB2312 字符集中),于是專家們又繼續把 GB2312 沒有用到的碼位使用到其他沒有被收錄的漢字中,
后來還是不夠用,于是干脆不再要求低位元組一定是 127 號之后的內碼,只要第一個位元組是大于 127 就固定表示這是一個漢字的開始,不管后面跟的是不是擴展字符集里的內容,結果擴展之后的編碼方案被稱為 GBK 標準,GBK 包括了 GB2312 的所有內容,同時又增加了近 20000 個新的漢字(包括繁體字)和符號,
當時的各個國家都像中國這樣制定出了一套自己的編碼標準,之后當我們需要使用計算機與國際接軌時,問題出現了!國家與國家之間誰也不懂誰的編碼,130 在法語編碼中代表了é,在希伯來語編碼中卻代表了字母 Gimel (?),在俄語編碼中又會代表另一個符號,但是所有這些編碼方式中,0—127 表示的符號依然都是一樣的,因為他們都兼容 ASCII 碼,這一點,如今也是一樣,
Unicode
正如上一節中所說的,世界上各國都有不同的編碼方式,同一個二進制數字可以被解碼成不同的符號,因此,要想打開一個文本檔案,就必須知道它的編碼方式,否則用錯誤的編碼方式解讀,就會出現亂碼,
為了解決這個問題,最終的集大成者 Unicode 字符集出現了,它將世界上所有的符號都納入其中,成功實作了每個數字代表唯一的至少在某種語言中使用的符號,目前,Unicode 字符集中已經收錄超過 13 萬個字符(第十萬個字符在2005年獲采納),值得關注的是,Unicode 依然兼容 ASCII,即 0~127 意義依然不變,
碼點
Unicode 表示的是一個字符集,與我們通常所說的 UTF-8、UTF-6 等編碼方式并不相同,本節介紹的編號就相當于 ASCII 碼中的 ASCII 值,它就是 Unicode 字符集中唯一表示某個字符的標識,在 Unicode 也稱作碼點(Code Point),如碼點 U+0061,這里的 61 就是 97 的十六進制表示,它就表示 Unicode 字符集中的字符 ‘a‘,
碼點的表示的形式為 U+[XX]XXXX,X 代表一個十六制數字,一般可以有 4-6 位,不足 4 位前補 0 補足 4 位,超過則按是幾位就是幾位,具體范圍是 U+0000~U+10FFFF,大概是 111 萬,按 Unicode 官方的說法,碼點范圍就這樣了,以后也不擴充了,一百多萬足夠用了,目前也只定義了 11 萬多個字符左右,
整個編碼程序中碼點就作為了一個中間的過渡層,可用下面這張圖來表示:
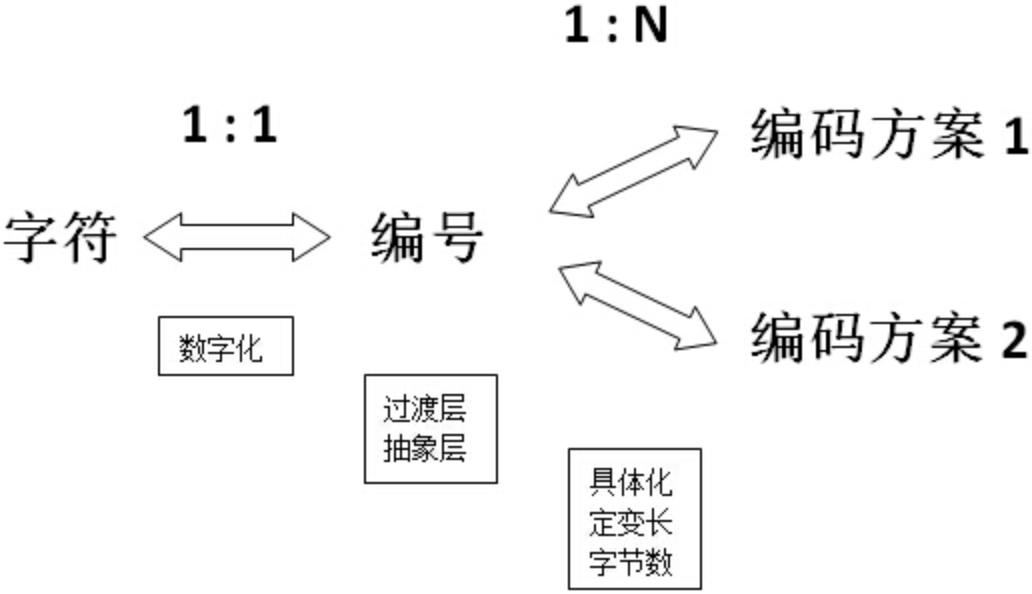
從這張圖可以看出,整個解碼可分為兩個程序,首先,將程式中的字符根據字符集中的編號數字化為某個特定的數值,然后根據編號以特定的方式存盤到計算機中,
顯然,這時候我們就可以發現編號并不是最終存盤在計算機中的結果,按照之前的理解,編碼即把一個字符編碼為一個二進制數字存盤起來,然而這種表述并不準確,真正的編碼不止這么簡單,這其中還涉及了每個數字用幾個位元組表示,是用定長還是變長表示等具體細節,
舉個例子,字符 a 的碼點為 U+0061(十進制為 97),那么這個 U+0061 該如何存盤,單純的表示 U+0061 可以直接使用 7 位的二進制數 110 0001 表示,但在 GB 類的編碼模式中就需要以兩個位元組存盤即 0000 0000 0110 0001(空位用 0 填充),
Unicode 編碼
Unicode 字符集衍生出來的編碼方案有三種,分別是 UTF-32、UTF-16 和 UTF-8,這使他與之前的編碼模式不同,因為 ASCII、GBK 等類編碼模式的字符集和編碼方式都是一一對應的,而 Unicode 的編碼實作卻有三種,這就是我們需要區分字符集與編碼的原因之一,因為此時 Unicode 并不特指 UTF-8 或者 UTF-32,
下面,我們來看下面這張示意圖,探究各種編碼模式下,碼點是如何具體轉換成各種編碼的:
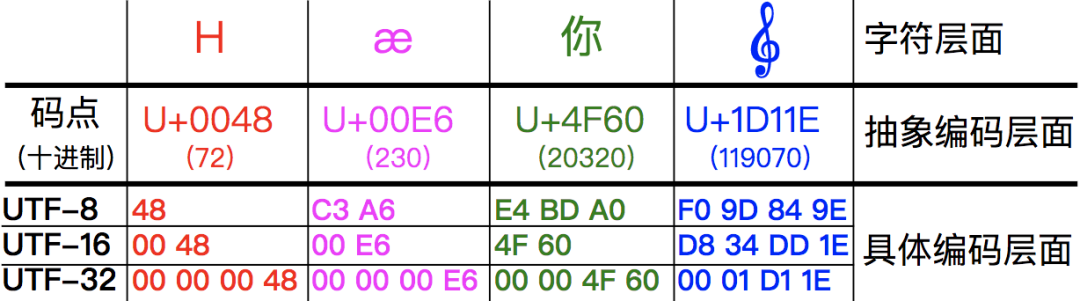
上面表中包含了四個字符的碼點,其中也展示了四個不同的碼點在 UTF-32、UTF-16 和 UTF-8 三種編碼模式下的編碼結果,
其中:碼點到 UTF-32 的轉換最簡單,就是在前面填充 0 滿 4 位元組即可;碼點到 UTF-8 的轉換,除了最小那個在數值上一樣外,其它三個完全看不出兩者的關系;
碼點到 UTF-16 的轉換則是最不規則的,可以看出前三個字符 UTF-16 與碼點是完全一致的,但那個大碼點(準確地說是超過了 U+FFFF 的碼點)則有了很大的變化,長度變成了四位元組,值也變得很不一樣了,
這其中又涉及到編碼程序中定長與變長兩種實作方式,這里的 UTF-32 就屬于定長編碼,即永遠用 4 位元組存盤碼點,而 UTF-8、UTF-16 就屬于變長存盤,UTF-8 根據不同的情況使用 1-4 位元組,而 UTF-16 使用 2 或 4 位元組來存盤碼點,
定長與變長
為什么要有定長與變長這兩種編碼形式?在中文的表達中都會有所謂的斷句問題,如果我們處理不好斷句很有可能會將意思傳遞錯誤,如下面這句來自算命先生紙條中的內容:
大富大貴沒有災難要小心
此時,如果算命俠客這樣斷句:
大富大貴,沒有災難要小心
表示我福大命大,沒有災難,可以肆意妄為了,但是沒過多久這位俠客就去世了,算命先生絕望地說,你會錯意了,原來,其實是這樣斷句的:
大富大貴沒有,災難要小心
表示你沒有大富大貴,出門要小心,斷句就可能會出現這樣嚴重的后果,
這也是計算機在解碼時需要使用定長與變長的原因,因為計算機底層的二進制碼也和算命先生紙條中的內容一樣,毫無章法,我們如果想要正確理解其中的意思就要有一個約定俗成的規則,
UTF-32
在 UTF-32 這種定長的編碼方式下就表示每 4 個子節一個斷句,那么字符 A 的碼點 U+0041(二進制為 1000001)被 UTF-32 編碼后就會變成如下形式存盤在計算機中:
> 00000000 00000000 00000000 01000001
它會將 4 個位元組中空出的高位全部填充為 0,這種表示的最大缺點是占用空間太大,因為不管都大的碼點都需要四個位元組來存盤,非常的占空間,那么如何突破這個瓶頸呢?變長方案應運而生,
UTF-8
UTF-8 屬于變長的編碼方式,它可以由 1,2,3,4 四種位元組組合,使用的是高位保留的方式來區別不同變長,具體方式如下:
-
對于只有一個位元組的符號,位元組的第一位設為0,后面 7 位為這個符號的 Unicode 碼,此時,對于英語字母UTF-8 編碼和 ASCII 碼是相同的,
-
對于 n 位元組的符號(n > 1),第一個位元組的前 n 位都設為 1,第 n + 1 位設為0,后面位元組的前兩位一律設為 10,剩下的沒有提及的二進制位,全部為這個符號的 Unicode 碼,如下表所示:

根據上表,編碼字符時就非常簡單了,以漢字 “丑” 為例,它的碼點為 0x4E11(0100 1110 0001 0001)在上表的第三行范圍(0000 0800 ~ 0000 FFFF)內,因此 “丑” 需要以三個位元組的形式編碼:
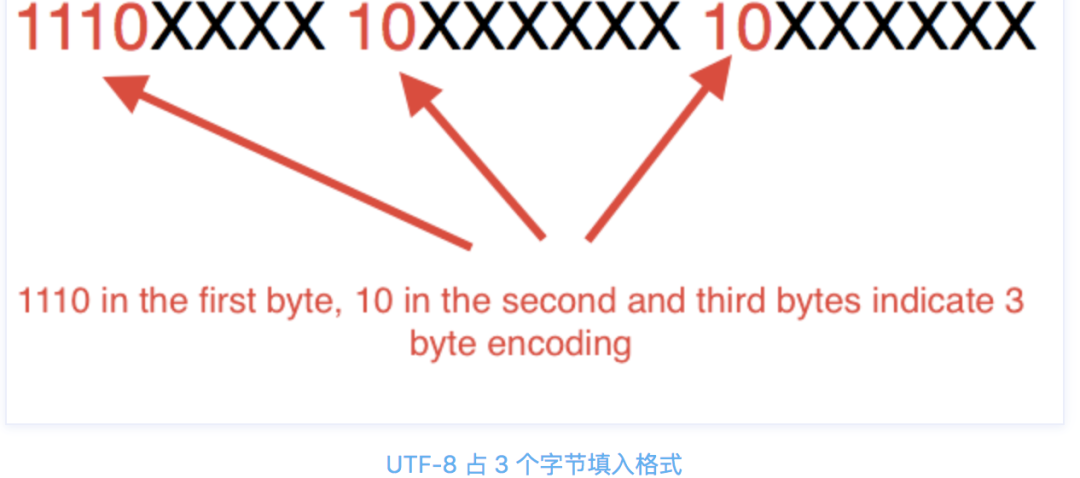
這里最高位的第一個位元組中的三個 1 表示該字符占 3 個位元組,空出的 16 位 x 就會從 “丑” 的最后一個二進制位開始,依次從后向前填入格式中,多出的位補 0,這樣就得到了 “丑” 的 UTF-8 編碼是 11100100 10111000 10010001,轉換成十六進制就是 E4B891,
解碼 UTF-8 編碼也很簡單了,如果一個位元組的第一位是 0,則這個位元組單獨就是一個字符;如果第一位是1,則連續有多少個 1,就表示當前字符占用多少個位元組,”丑” 有三個 1 表示占三個字符,然后取出有效位即可,
UTF-16
UTF-16 使用的是是一種變長為 2 或 4 位元組編碼模式,
最初,Unicode1.0 被設計為純 16 位編碼,擁有 65,536 個碼點(U+0000~U+FFFF),目的就是希望能夠表示所有現代字符,然而隨著時間推移,16 位對于計算機而言顯然是不夠的,因此產生了如今的 4 位元組的 UTF-16 編碼,此時,Unicode 就具有了 1,114,112 個代碼點(U+10000 ~ U+10FFFF),這就是我們之前介紹 Unicode,
此時,范圍在 U+0000~U+FFFF 的碼點被稱了為BMP(Basic Multilingual Plane,基本多語言平面),而后來拓展的范圍 U+10000 ~ U+10FFFF 稱為SP(Supplementary Planes,增補平面)****,UTF-16 就是利用 BMP 使用代理的方式來對字符進行編碼,
何為代理?
代理和 UTF-8 中的高位保留的目的一樣,就是為了能夠實作變長的編碼方式,
什么是代理區?
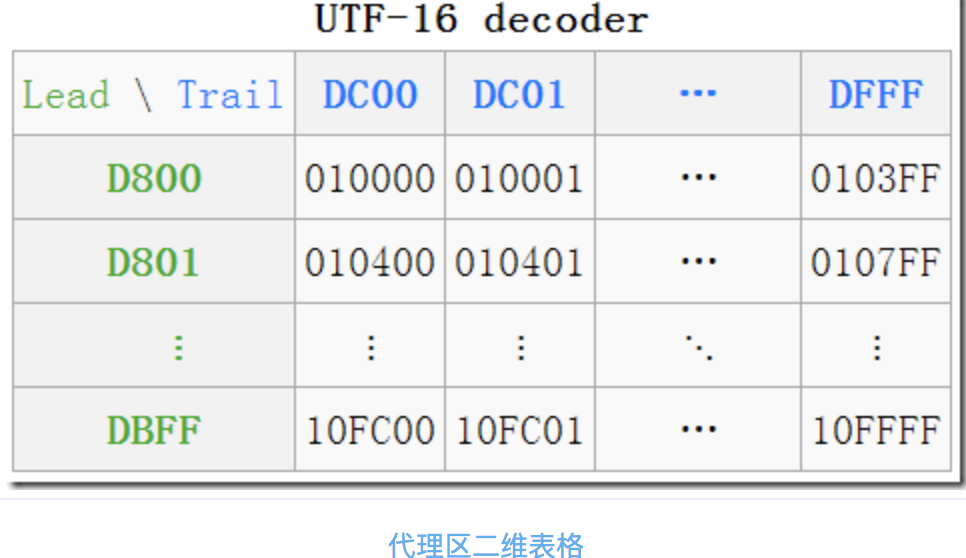
代理區由兩個特殊范圍(BMP 中的空閑部分)的 Unicode 碼點組成,總共有 2048 個位置,均分為高代理區(D800–DBFF)和低代理區(DC00–DFFF)兩部分,各 1024,這兩個區可以組成一個二維的表格,共有 1,024 x 1,024 = 1,048,576 = 16×65536 個單元格,所以它恰好可以表示代理(增補)的 16 位中的所有字符,
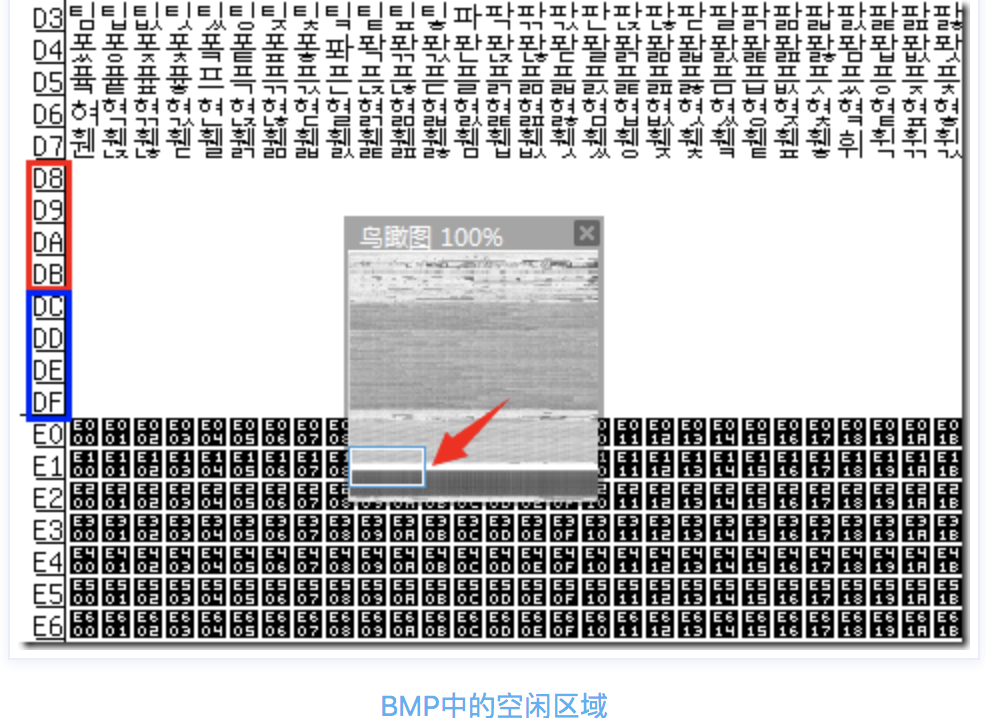
這種從一維存盤轉換到二維存盤的方式就可以實作空間增大的效果了,UTF-16 也就有了能夠額外獲得碼點的方式了,
一個高代理區(即上圖中的 Lead(頭),行)的加一個低代理區(即上圖中的Trail(尾),列)的編碼組成一對代理對****(Surrogate Pair),在圖中就可以看到一些轉換的例子,如
(D8 00DC 00)—>U+10000,左上角,第一個增補字符
(DB FFDF FF)—>U+10FFFF,右下角,最后一個增補字符
從 UTF-16 轉換為字符代碼的演算法是什么?
分成兩部分:
-
BMP 中直接對應,無須做任何轉換;
-
增補平面 SP 中,則需要做相應的計算,其實由上圖中的表也可看出,碼點就是從上到下,從左到右排列過去的,所以只需做個簡單的除法,拿到除數和余數即可確定行與列,
拿到一個碼點,先減去 10000,再除以 400(=1024)就是所在行了,余數就是所在列了,再加上行與列所在的起始值,就得到了代理對了,
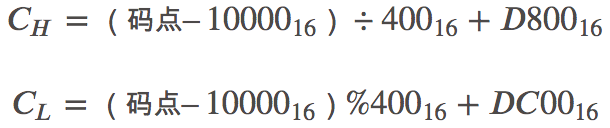
需要關注的是,最常用的字符依然是在 BMP 平面中編碼的,下表給出了各碼點范圍內 UTF-16 編碼取值方法:
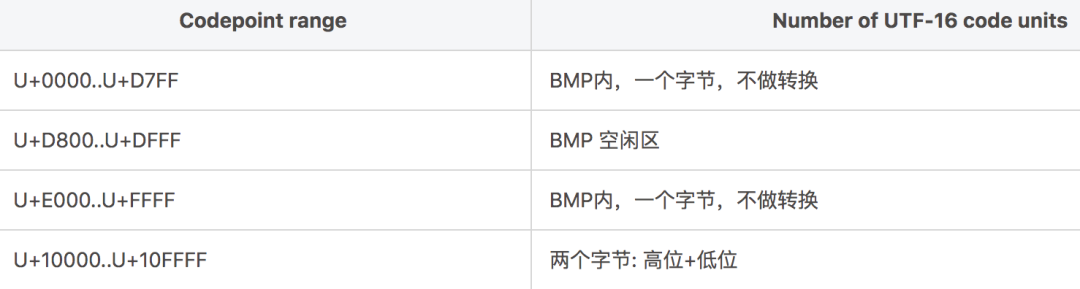
下面以碼點 U+1D11E 具體示例計算代理對:
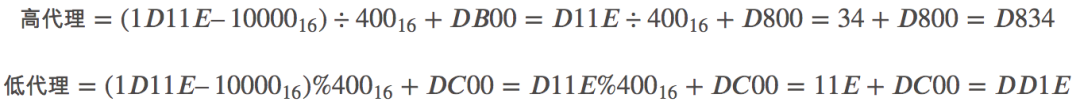
所以,碼點 U+1D11E 對應的代理對即是 D834 DD1E,下表又列舉出了其他字符的 UTF-16 的編碼程序:
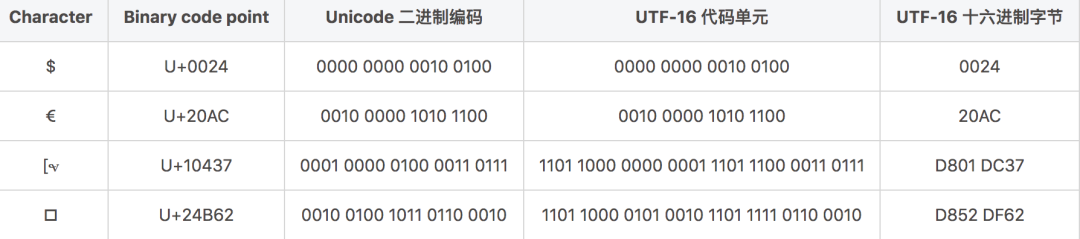
和 UTF-8 中高位保留的方式一樣,UTF-16 在各碼點范圍內同樣擁有一個二進制到實際編碼單元的映射表,如下:

按照上面的兩個表我們也不難發現其中的規律,在 U+10000 ~ U+10FFFF 范圍內的碼點在編碼時分別在第一個子節和第三個位元組的高位設為 110110 和 110111,然后再根據 Unicode 二進制碼各位填補即可(其中,這里的uuuuu = wwww + 1),
至此本篇文章就結束了,
本文轉自來自Joker's Blog,
著作權宣告: 本文采用 CC BY-NC-SA 4.0 許可協議,轉載請注明來自 Joker's Blog!
近期熱文推薦:
1.Java 15 正式發布, 14 個新特性,重繪你的認知!!
2.終于靠開源專案弄到 IntelliJ IDEA 激活碼了,真香!
3.我用 Java 8 寫了一段邏輯,同事直呼看不懂,你試試看,,
4.吊打 Tomcat ,Undertow 性能很炸!!
5.《Java開發手冊(嵩山版)》最新發布,速速下載!
覺得不錯,別忘了隨手點贊+轉發哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/244111.html
標籤:Java
下一篇:最全JVM總體概述