Python 爬蟲包含兩個重要的部分:正則運算式和Scrapy框架的運用, 正則運算式對于所有語言都是通用的,網路上可以找到各種資源,
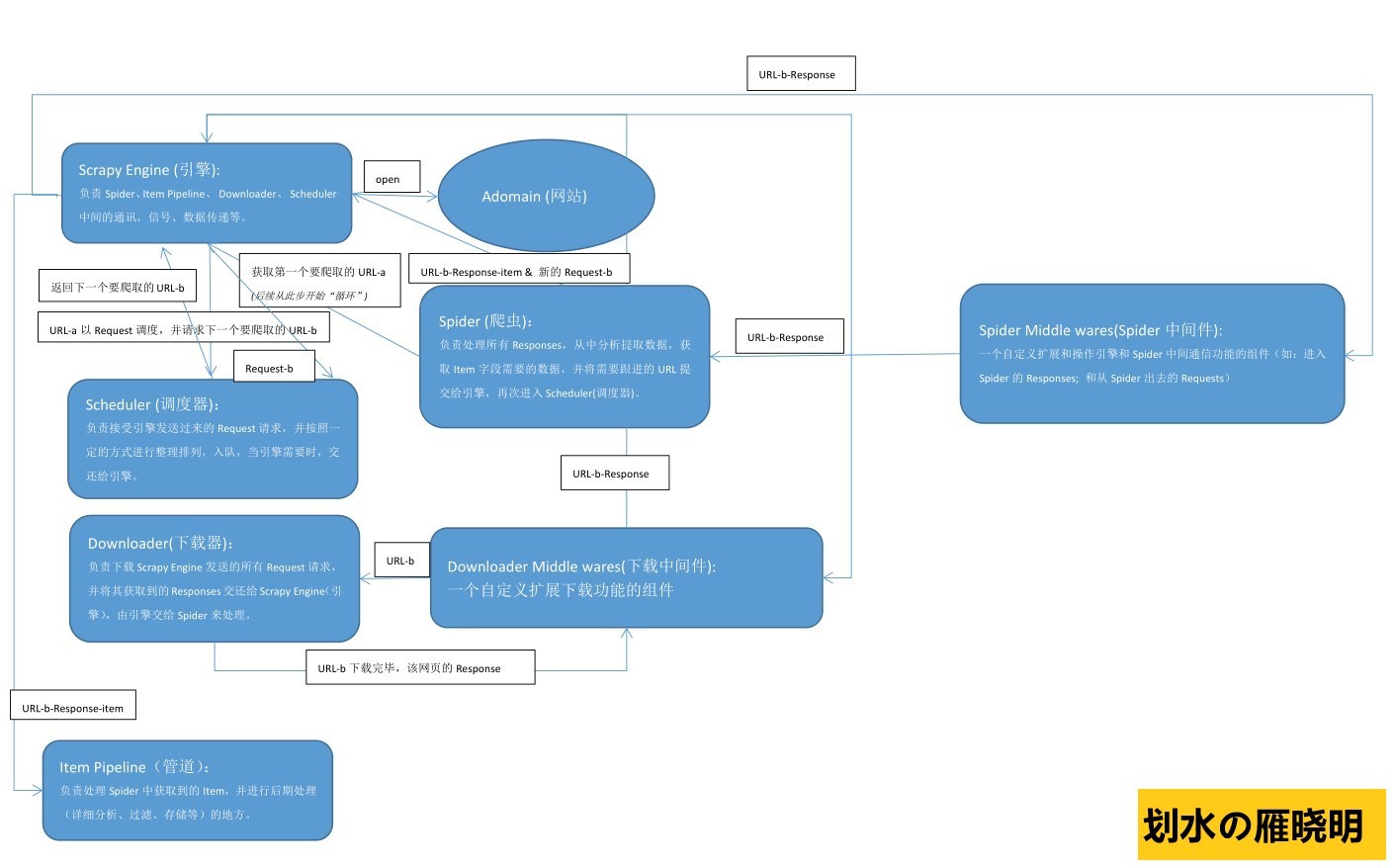
如下是手繪Scrapy框架原理圖,幫助理解
如下是一段運用Scrapy創建的spider:使用了內置的crawl模板,以利用Scrapy庫的CrawlSpider,相對于簡單的爬取爬蟲來說,Scrapy的CrawlSpider擁有一些網路爬取時可用的特殊屬性和方法:
$ scrapy genspider country_or_district example.python-scrapying.com--template=crawl
運行genspider命令后,下面的代碼將會在example/spiders/country_or_district.py中自動生成,


1 # -*- coding: utf-8 -*- 2 import scrapy 3 from scrapy.linkextractors import LinkExtractor 4 from scrapy.spiders import CrawlSpider, Rule 5 from example.items import CountryOrDistrictItem 6 7 8 class CountryOrDistrictSpider(CrawlSpider): 9 name = 'country_or_district' 10 allowed_domains = ['example.python-scraping.com'] 11 start_urls = ['http://example.python-scraping.com/'] 12 13 rules = ( 14 Rule(LinkExtractor(allow=r'/index/', deny=r'/user/'), 15 follow=True), 16 Rule(LinkExtractor(allow=r'/view/', deny=r'/user/'), 17 callback='parse_item'), 18 ) 19 20 def parse_item(self, response): 21 item = CountryOrDistrictItem() 22 name_css = 'tr#places_country_or_district__row td.w2p_fw::text' 23 item['name'] = response.css(name_css).extract() 24 pop_xpath = '//tr[@id="places_population__row"]/td[@]/text()' 25 item['population'] = response.xpath(pop_xpath).extract() 26 return itemView Code
爬蟲類包括的屬性:
- name: 識別爬蟲的字串,
- allowed_domains: 可以爬取的域名串列,如果沒有設定該屬性,則表示可以爬取任何域名,
- start_urls: 爬蟲起始URL串列,
- rules: 該屬性為一個通過正則運算式定義的Rule物件元組,用于告知爬蟲需要跟蹤哪些鏈接以及哪些鏈接包含抓取的有用內容,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/244129.html
標籤:Python