資料結構—B樹、B+樹、B*樹
博客說明
文章所涉及的資料來自互聯網整理和個人總結,意在于個人學習和經驗匯總,如有什么地方侵權,請聯系本人洗掉,謝謝!
多叉樹
多叉樹(multiway tree)允許每個節點可以有更多的資料項和更多的子節點
多叉樹通過重新組織節點,減少樹的高度,能對二叉樹進行優化
檔案系統及資料庫系統的設計者利用了磁盤預讀原理,將一個節點的大小設為等于一個頁(頁得大小通常為4k),這樣每個節點只需要一次I/O就可以完全載入
2-3樹
- 2-3樹的所有葉子節點都在同一層.(只要是B樹都滿足這個條件)
- 有兩個子節點的節點叫二節點,二節點要么沒有子節點,要么有兩個子節點.
- 有三個子節點的節點叫三節點,三節點要么沒有子節點,要么有三個子節點.
- 2-3樹是由二節點和三節點構成的樹
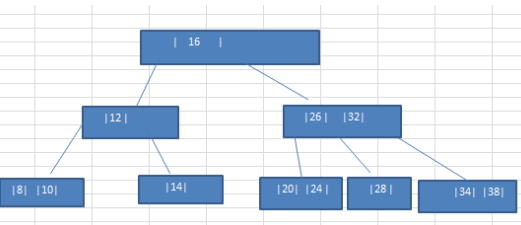
插入規則:
- 2-3樹的所有葉子節點都在同一層.(只要是B樹都滿足這個條件)
- 有兩個子節點的節點叫二節點,二節點要么沒有子節點,要么有兩個子節點.
- 有三個子節點的節點叫三節點,三節點要么沒有子節點,要么有三個子節點
- 當按照規則插入一個數到某個節點時,不能滿足上面三個要求,就需要拆,先向上拆,如果上層滿,則拆本層,拆后仍然需要滿足上面3個條件,
- 對于三節點的子樹的值大小仍然遵守(BST 二叉排序樹)的規則
B樹
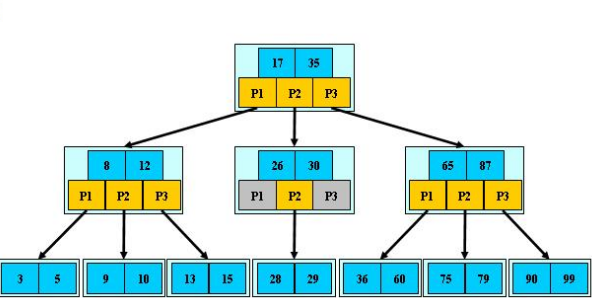
- B樹的階:節點的最多子節點個數,比如2-3樹的階是3,2-3-4樹的階是4
- B-樹的搜索,從根結點開始,對結點內的關鍵字(有序)序列進行二分查找,如果命中則結束,否則進入查詢
- 關鍵字所屬范圍的兒子結點;重復,直到所對應的兒子指標為空,或已經是葉子結點
- 關鍵字集合分布在整顆樹中, 即葉子節點和非葉子節點都存放資料.
- 搜索有可能在非葉子結點結束
- 其搜索性能等價于在關鍵字全集內做一次二分查找
B+樹
B+樹是B樹的變體,也是一種多路搜索樹
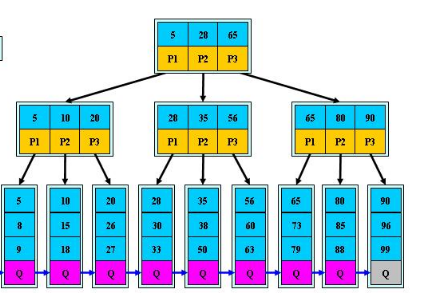
- B+樹的搜索與B樹也基本相同,區別是B+樹只有達到葉子結點才命中(B樹可以在非葉子結點命中),其性能也等價于在關鍵字全集做一次二分查找
- 所有關鍵字都出現在葉子結點的鏈表中(即資料只能在葉子節點【也叫稠密索引】),且鏈表中的關鍵字(資料)恰好是有序的,
- 不可能在非葉子結點命中
- 非葉子結點相當于是葉子結點的索引(稀疏索引),葉子結點相當于是存盤(關鍵字)資料的資料層
更適合檔案索引系統
B*樹
B*樹是B+樹的變體,在B+樹的非根和非葉子結點再增加指向兄弟的指標
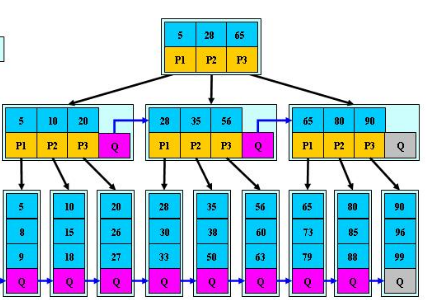
- B樹定義了非葉子結點關鍵字個數至少為(2/3)M,即塊的最低使用率為2/3,而B+樹的塊的最低使用率為B+樹的1/2,
- 從第1個特點我們可以看出,B*樹分配新結點的概率比B+樹要低,空間使用率更高
感謝
尚硅谷
以及勤勞的自己,個人博客,GitHub

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/24424.html
標籤:Java
上一篇:Java集合之泛型類和泛型介面