寫在前面
之前因為在組里做和nlp相關的專案,需要自己構建資料集,采用selenium爬取了幾十萬條微博資料,學習了很多,想在這里分享一下如何用selenium爬取微博上任何你想要的資料,這里默認大家都會最基本的python操作哈~
為什么要用selenium
selenium庫的好處:Selenium 測驗直接在瀏覽器中運行,就像真實用戶所做的一樣,用通俗的話來說,當你在爬取微博資料的時候,就仿佛有一只 “無形的手”幫你登錄微博,搜索你想要的內容,下載你想要的圖片等等,這只手就是你寫的代碼啦~
安裝selenium和chromedriver
廢話不多說,我們需要先安裝兩個工具
selenium
直接pip或conda安裝就可以啦
conda install selenium
chromedriver
chromedriver是操作chrome的驅動,首先我們要找到和我們的瀏覽器適配的chromedriver版本
selenium除了chrome還有很多瀏覽器都可以配合使用的,比如firefox啥的都可以滴,大家不想使用chrome的話可以去找找相關博客安裝,大同小異~
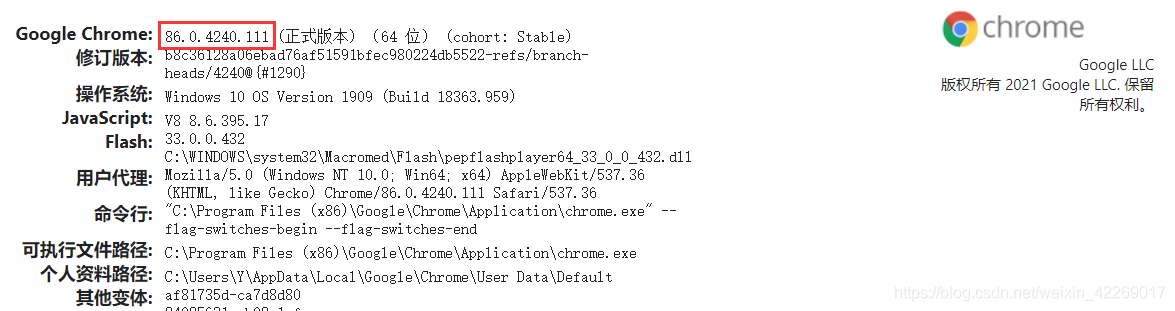
- 查看瀏覽器版本,在瀏覽器中輸入
chrome://version/就能看到啦,我的版本是86.0.4240.111
- 查找chrome瀏覽器對應的版本chromedriver驅動版本,可以在這里查看
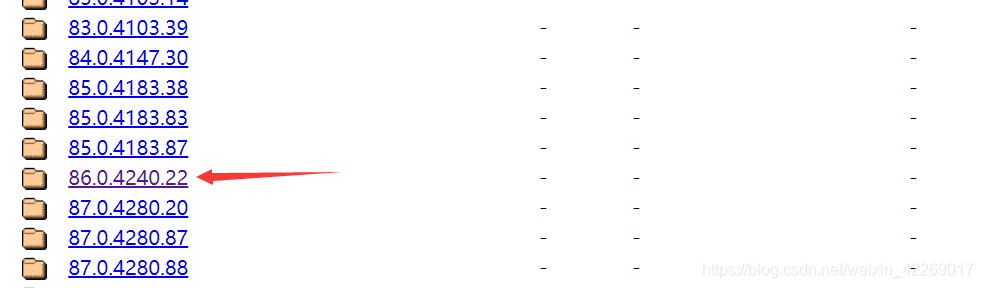
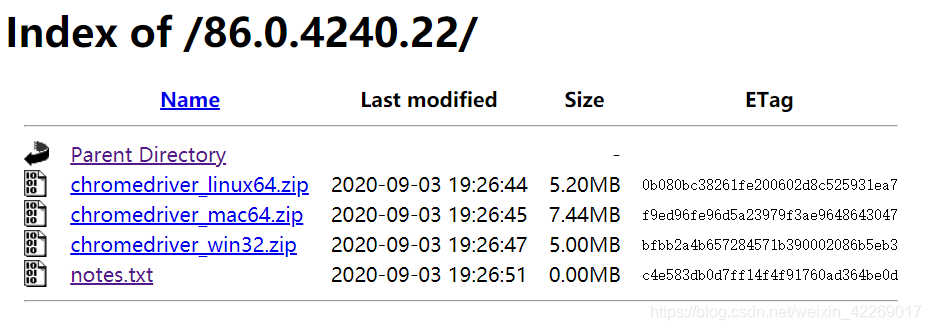
點進去,選擇適合自己系統的壓縮包下載就行
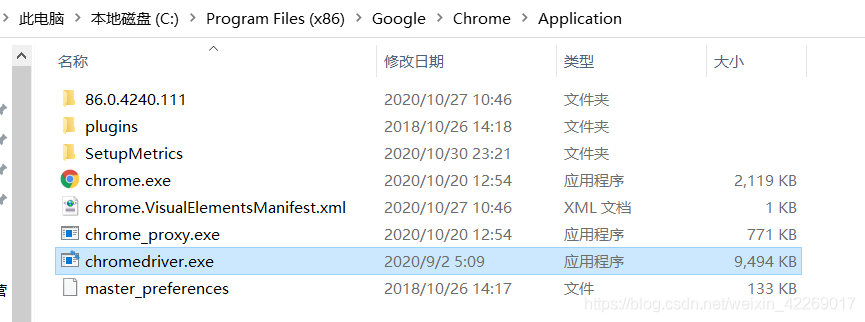
- 之后把壓縮包中的chromedriver.exe解壓縮到chrome檔案夾中
其實可以解壓到任何一個路徑,只要最后添加好環境變數就好了,或者直接使用絕對路徑~
4. 添加環境變數(此電腦-屬性-高級系統設定-環境變數)
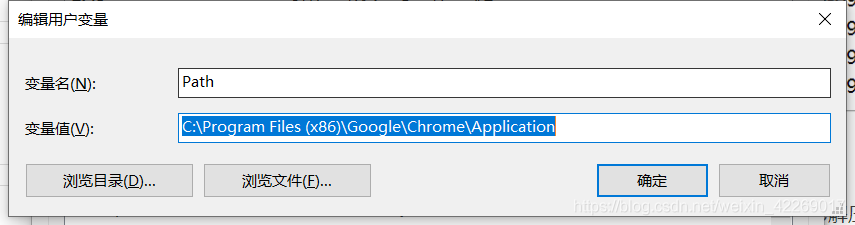
測驗一下
這個時候配置作業就完成啦,可以運行一下測驗代碼~
from selenium import webdriver
driver = webdriver.Chrome()
#上面是配置好環境變數的寫法,像下面這樣用絕對路徑也是ok滴
#driver = webdriver.Chrome('C:/Program Files (x86)/Google/Chrome/Application/chromedriver.exe')
driver.get('https://www.baidu.com')
別忘了改成自己的路徑
下一篇會正式帶大家使用selenium在微博上爬取資料~有問題歡迎大家及時指出!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/244284.html
標籤:python