灰狼優化演算法的理解和應用
- 一、背景介紹
- 二、演算法原理
- 三、構建演算法數學模型
- 四、Python實作GWO
- 五、演算法分析
一、背景介紹
灰狼優化演算法(Grey Wolf Optimizer,GWO)由澳大利亞格里菲斯大學學者 Mirjalili 等人于2014年提出來的一種群智能優化演算法,該演算法受到了灰狼捕食獵物活動的啟發而開發的一種優化搜索方法,它具有較強的收斂性能、引數少、易實作等特點,近年來受到了學者的廣泛關注,它己被成功地應用到了車間調度、引數優化、影像分類等領域中,
二、演算法原理
狼群中有α、β、γ三只狼做頭狼,其中α是狼王,β、γ分別排第二、第三,β、γ都要聽α的,γ要聽β的,這三匹狼指導者其他的狼尋找獵物,狼群尋找獵物的程序就是我們尋找最優解的程序,
GWO具體優化程序包含了社會等級分層、跟蹤、包圍和攻擊獵物和尋找獵物,
但其核心行為只有捕獵,
為了模擬灰狼的搜索行為,假設α、β、γ具有較強識別潛在獵物的能力,因此,在每次迭代程序中,保留當前種群中最好的三只狼(α、β、γ),然后根據他們的位置資訊來更新其他搜索代理的位置,
三、構建演算法數學模型
1)社會等級分層
GWO的優化程序主要有每代種群中的最好三匹狼(具體構建時表示為三個最好的解)來指導完成,
2)包圍獵物
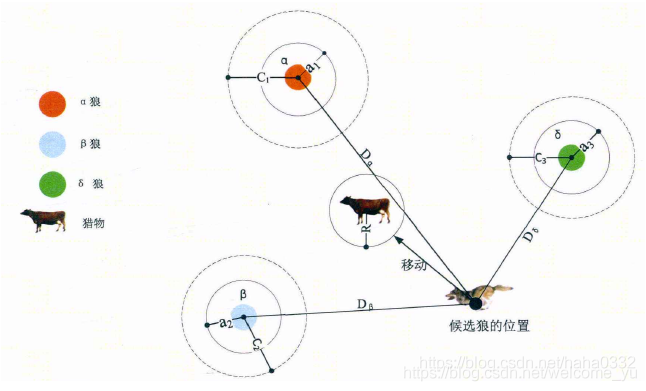
灰狼捜索獵物時會逐漸地接近獵物并包圍它,該行為的數學模型如下:
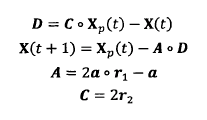

3)狩獵行為的數學模型
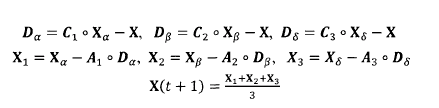

4)攻擊獵物
5)尋找獵物
更多關于灰狼演算法原理的詳細內容
四、Python實作GWO
import random
import numpy
def GWO(objf, lb, ub, dim, SearchAgents_no, Max_iter):
# 初始化 alpha, beta, and delta_pos
Alpha_pos = numpy.zeros(dim) # 位置.形成30的串列
Alpha_score = float("inf") # 這個是表示“正負無窮”,所有數都比 +inf 小;正無窮:float("inf"); 負無窮:float("-inf")
Beta_pos = numpy.zeros(dim)
Beta_score = float("inf")
Delta_pos = numpy.zeros(dim)
Delta_score = float("inf") # float() 函式用于將整數和字串轉換成浮點數,
# list串列型別
if not isinstance(lb, list): # 作用:來判斷一個物件是否是一個已知的型別, 其第一個引數(object)為物件,第二個引數(type)為型別名,若物件的型別與引數二的型別相同則回傳True
lb = [lb] * dim # 生成[100,100,.....100]30個
if not isinstance(ub, list):
ub = [ub] * dim
# Initialize the positions of search agents初始化所有狼的位置
Positions = numpy.zeros((SearchAgents_no, dim))
for i in range(dim): # 形成5*30個數[-100,100)以內
Positions[:, i] = numpy.random.uniform(0, 1, SearchAgents_no) * (ub[i] - lb[i]) + lb[
i] # 形成[5個0-1的數]*100-(-100)-100
Convergence_curve = numpy.zeros(Max_iter)
#迭代尋優
for l in range(0, Max_iter): # 迭代1000
for i in range(0, SearchAgents_no): # 5
# 回傳超出搜索空間邊界的搜索代理
for j in range(dim): # 30
Positions[i, j] = numpy.clip(Positions[i, j], lb[j], ub[
j]) # clip這個函式將將陣列中的元素限制在a_min(-100), a_max(100)之間,大于a_max的就使得它等于 a_max,小于a_min,的就使得它等于a_min,
# 計算每個搜索代理的目標函式
fitness = objf(Positions[i, :]) # 把某行資料帶入函式計算
# print("經過計算得到:",fitness)
# Update Alpha, Beta, and Delta
if fitness < Alpha_score:
Alpha_score = fitness # Update alpha
Alpha_pos = Positions[i, :].copy()
if (fitness > Alpha_score and fitness < Beta_score):
Beta_score = fitness # Update beta
Beta_pos = Positions[i, :].copy()
if (fitness > Alpha_score and fitness > Beta_score and fitness < Delta_score):
Delta_score = fitness # Update delta
Delta_pos = Positions[i, :].copy()
# 以上的回圈里,Alpha、Beta、Delta
a = 2 - l * ((2) / Max_iter); # a從2線性減少到0
for i in range(0, SearchAgents_no):
for j in range(0, dim):
r1 = random.random() # r1 is a random number in [0,1]主要生成一個0-1的隨機浮點數,
r2 = random.random() # r2 is a random number in [0,1]
A1 = 2 * a * r1 - a; # Equation (3.3)
C1 = 2 * r2; # Equation (3.4)
# D_alpha表示候選狼與Alpha狼的距離
D_alpha = abs(C1 * Alpha_pos[j] - Positions[
i, j]); # abs() 函式回傳數字的絕對值,Alpha_pos[j]表示Alpha位置,Positions[i,j])候選灰狼所在位置
X1 = Alpha_pos[j] - A1 * D_alpha; # X1表示根據alpha得出的下一代灰狼位置向量
r1 = random.random()
r2 = random.random()
A2 = 2 * a * r1 - a; #
C2 = 2 * r2;
D_beta = abs(C2 * Beta_pos[j] - Positions[i, j]);
X2 = Beta_pos[j] - A2 * D_beta;
r1 = random.random()
r2 = random.random()
A3 = 2 * a * r1 - a;
C3 = 2 * r2;
D_delta = abs(C3 * Delta_pos[j] - Positions[i, j]);
X3 = Delta_pos[j] - A3 * D_delta;
Positions[i, j] = (X1 + X2 + X3) / 3 # 候選狼的位置更新為根據Alpha、Beta、Delta得出的下一代灰狼地址,
Convergence_curve[l] = Alpha_score;
if (l % 1 == 0):
print(['迭代次數為' + str(l) + ' 的迭代結果' + str(Alpha_score)]); # 每一次的迭代結果
#函式
def F1(x):
s=numpy.sum(x**2);
return s
#主程式
func_details = ['F1', -100, 100, 30]
function_name = func_details[0]
Max_iter = 1000#迭代次數
lb = -100#下界
ub = 100#上屆
dim = 30#狼的尋值范圍
SearchAgents_no = 5#尋值的狼的數量
x = GWO(F1, lb, ub, dim, SearchAgents_no, Max_iter)
運行結果截圖:

五、演算法分析
灰狼優化演算法的位置更新方程存在開發能力強而探索能力弱的缺點.
灰狼演算法的全域搜索能力強、精度稍差,
參考鏈接:
https://blog.csdn.net/haha0332/article/details/88805910
https://www.it610.com/article/1288128297732976640.htm
推薦閱讀:
https://www.jianshu.com/p/97206c3fc51f
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/244287.html
標籤:python