Python 爬取Steam熱銷榜資訊
最近學習了一下爬蟲,練練手,第一次寫文章,請多多包涵O(∩_∩)O
爬取Steam熱銷榜:游戲排名、游戲名字、價格、好評率、游戲詳情頁面跳轉鏈接,
Steam熱銷榜爬蟲
- Python 爬取Steam熱銷榜資訊
- 一、開始爬蟲前
- 1.引入庫
- 2.讀入資料
- 二、分析網頁
- 1.首先觀察價格,有兩種形式,一種是原價,一種是打折后的價格
- 2.名字、游戲詳情頁鏈接
- 3.好評率
- 三、爬取資訊并處理
- 1.游戲詳情頁面鏈接
- 2.好評率
- 3.名字、價格
- 四、資訊保存
- 五、主函式
- 六、全部代碼
- 七、總結
- 1.心情
一、開始爬蟲前
1.引入庫
熱銷榜為靜態頁面,所需要的庫:requests,pandas,BeautifulSoup
import requests
import pandas as pd
from bs4 import BeautifulSoup
2.讀入資料
headers里需要加入 ‘Accept-Language’: 'zh-CN ',不然回傳來的游戲名字是英文
def get_text(url):
try:
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/85.0.4183.102 Safari/537.36', 'Accept-Language': 'zh-CN '
}
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "爬取網站失敗!"
二、分析網頁
熱銷榜鏈接:
https://store.steampowered.com/search/?filter=globaltopsellers&page=1&os=win
1.首先觀察價格,有兩種形式,一種是原價,一種是打折后的價格
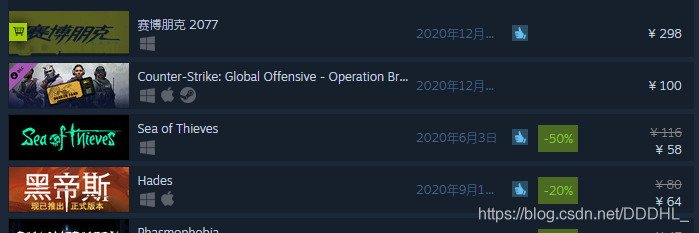
(1)正常價格

(2)打折后價格,對比可發現class = “col search_discount responsive_secondrow” 是用于儲存折扣的,原價為None,打折不為None,以此做為判斷條件提取價格,
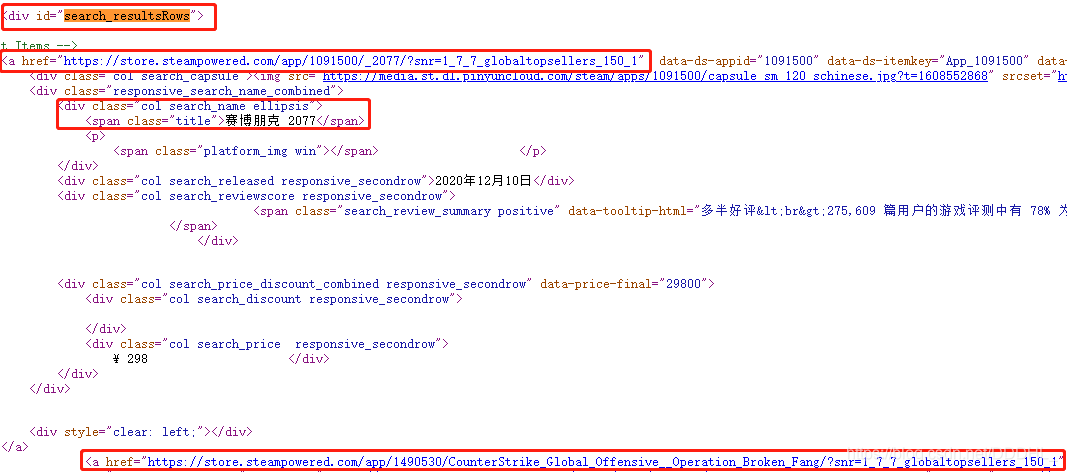
2.名字、游戲詳情頁鏈接
由代碼可以知道:
游戲詳情頁鏈接全在 id = “search_resultsRows” 的a.href 標簽里
名字在 class = “title” 里
3.好評率
由圖可以發現有些游戲沒有評價
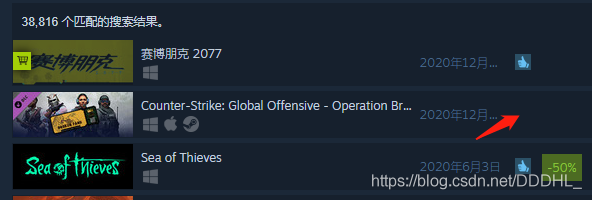
查看代碼發現:
好評率在 class = “col search_reviewscore responsive_secondrow” 中,無評價為None


三、爬取資訊并處理
1.游戲詳情頁面鏈接
提取a[‘href’] 保存到 jump_link 串列
link_text = soup.find_all("div", id="search_resultsRows")
for k in link_text:
b = k.find_all('a')
for j in b:
jump_link.append(j['href'])
2.好評率
提前好評率和評價數到 game_evaluation 串列,
u.span["data-tooltip-html"].split("<br>")[0] # 評價
例:多半好評
u.span["data-tooltip-html"].split("<br>")[-1]) # 好評率
例:276,144 篇用戶的游戲評測中有 78% 為好評,
w = soup.find_all(class_="col search_reviewscore responsive_secondrow")
for u in w:
if u.span is not None: # 判斷是否評價為None,
game_evaluation.append(
u.span["data-tooltip-html"].split("<br>")[0] + "," + u.span["data-tooltip-html"].split("<br>")[-1])
else:
game_evaluation.append("暫無評價!")
3.名字、價格
用strip去除多余空格,用split切割,提取其中的價格
global num 是游戲排名,
game_info 是串列,存盤所有的資訊,
price = z.find(class_="col search_price discounted responsive_secondrow").text.strip().split("¥")
print(price) # 切割后的打折price
print(price[2].strip()) # 需要保存的價格
結果為:
['', ' 116', ' 58']
58
global num
name_text = soup.find_all('div', class_="responsive_search_name_combined")
for z in name_text:
# 每個游戲的價格
name = z.find(class_="title").string.strip()
# 判斷折扣是否為None,提取價格
if z.find(class_="col search_discount responsive_secondrow").string is None:
price = z.find(class_="col search_price discounted responsive_secondrow").text.strip().split("¥")
game_info.append([num + 1, name, price[2].strip(), game_evaluation[num], jump_link[num]])
else:
price = z.find(class_="col search_price responsive_secondrow").string.strip().split("¥")
game_info.append([num + 1, name, price[1], game_evaluation[num], jump_link[num]])
num = num + 1
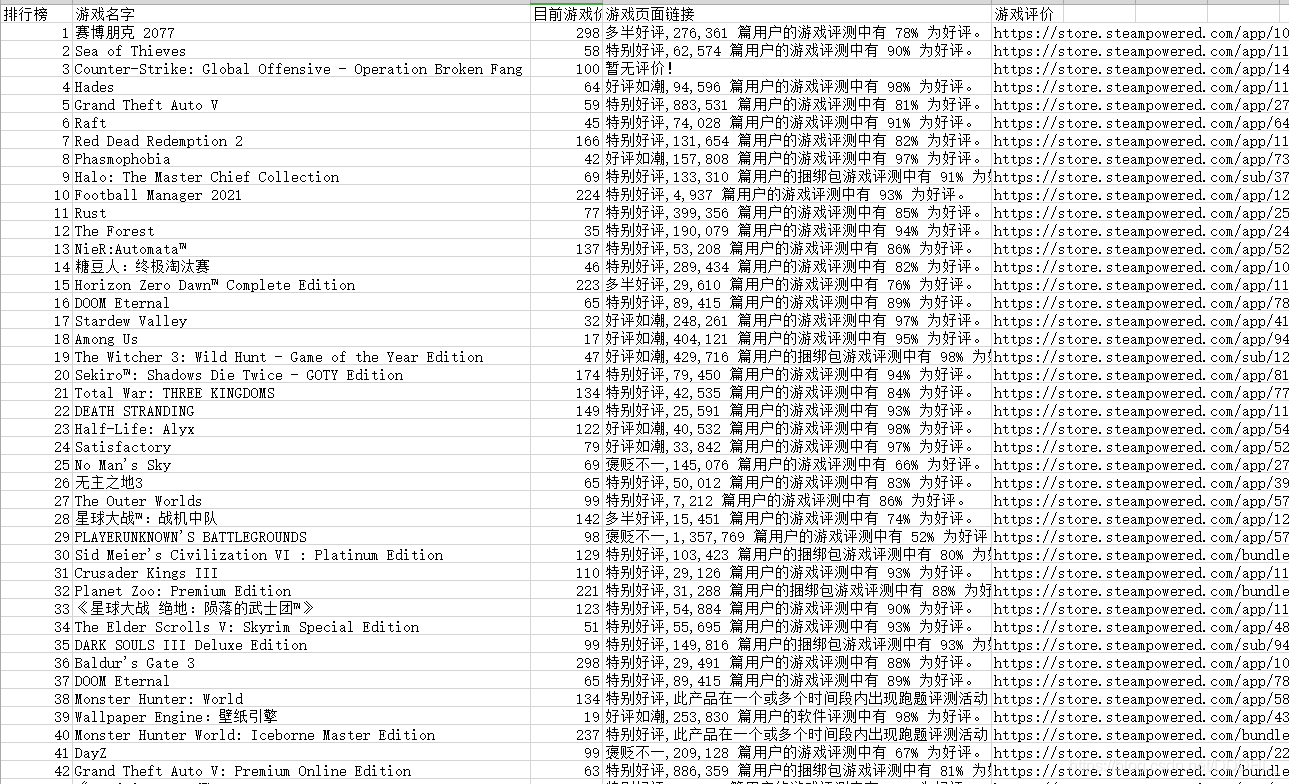
四、資訊保存
def save_data(game_info):
save_path = "E:/Steam.csv" # 保存路徑
df = pd.DataFrame(game_info, columns=['排行榜', '游戲名字', '目前游戲價格¥', '游戲頁面鏈接', '游戲評價'])
df.to_csv(save_path, index=0)
print("檔案保存成功!")
五、主函式
一頁有25個游戲,翻頁鏈接直接在原鏈接后面加 &page= 第幾頁
想爬取多少頁游戲,就把 range(1,11)的11改成多少頁+1
if __name__ == "__main__":
Game_info = [] # 所有游戲資訊
Turn_link = [] # 翻頁鏈接
Jump_link = [] # 游戲詳情頁面鏈接
Game_evaluation = [] # 游戲好評率和評價
for i in range(1, 11):
Turn_link.append("https://store.steampowered.com/search/?filter=globaltopsellers&page=1&os=win" + str("&page=" + str(i)))
run(Game_info, Jump_link, Game_evaluation, get_text(Turn_link[i-1]))
save_data(Game_info)
六、全部代碼
num 是排名;run 函式里要呼叫 BeautifulSoup 函式決議
import requests
import pandas as pd
from bs4 import BeautifulSoup
num = 0
def get_text(url):
try:
headers = {
"User-Agent": 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/85.0.4183.102 Safari/537.36', 'Accept-Language': 'zh-CN '
}
r = requests.get(url, headers=headers)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
return "爬取網站失敗!"
def run(game_info, jump_link, game_evaluation, text):
soup = BeautifulSoup(text, "html.parser")
# 游戲評價
w = soup.find_all(class_="col search_reviewscore responsive_secondrow")
for u in w:
if u.span is not None:
game_evaluation.append(
u.span["data-tooltip-html"].split("<br>")[0] + "," + u.span["data-tooltip-html"].split("<br>")[-1])
else:
game_evaluation.append("暫無評價!")
# 游戲詳情頁面鏈接
link_text = soup.find_all("div", id="search_resultsRows")
for k in link_text:
b = k.find_all('a')
for j in b:
jump_link.append(j['href'])
# 名字和價格
global num
name_text = soup.find_all('div', class_="responsive_search_name_combined")
for z in name_text:
# 每個游戲的價格
name = z.find(class_="title").string.strip()
# 判斷折扣是否為None,提取價格
if z.find(class_="col search_discount responsive_secondrow").string is None:
price = z.find(class_="col search_price discounted responsive_secondrow").text.strip().split("¥")
game_info.append([num + 1, name, price[2].strip(), game_evaluation[num], jump_link[num]])
else:
price = z.find(class_="col search_price responsive_secondrow").string.strip().split("¥")
game_info.append([num + 1, name, price[1], game_evaluation[num], jump_link[num]])
num = num + 1
def save_data(game_info):
save_path = "E:/Steam.csv"
df = pd.DataFrame(game_info, columns=['排行榜', '游戲名字', '目前游戲價格¥', '游戲評價', '游戲頁面鏈接'])
df.to_csv(save_path, index=0)
print("檔案保存成功!")
if __name__ == "__main__":
Game_info = [] # 游戲全部資訊
Turn_link = [] # 翻頁鏈接
Jump_link = [] # 游戲詳情頁面鏈接
Game_evaluation = [] # 游戲好評率和評價
for i in range(1, 11):
Turn_link.append("https://store.steampowered.com/search/?filter=globaltopsellers&page=1&os=win" + str("&page=" + str(i)))
run(Game_info, Jump_link, Game_evaluation, get_text(Turn_link[i-1]))
save_data(Game_info)
七、總結
以上就是今天要講的內容,本文僅僅簡單介紹了request 和 BeautifulSoup 的使用,突破點在于:有些頁面資訊的位置不同,能否找出判斷條件
1.心情
初學爬蟲,也是第一次寫博客,對于優化和多執行緒目前沒有太多了解,本文的代碼可能有點繁瑣,不過也能做到輕松爬取資訊,O(∩_∩)O
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/244289.html
標籤:python