REDIS簡單動態字串
在 redis 中,沒有直接使用 c語言 傳統的字串(以空字串結尾的字符陣列),而是自己構建了一種名為簡單動態字串(simple dynamic string,SDS)的抽象型別,并將 SDS 用作 redis 的默認字串表示,
舉個例子:
redis> SET msg "hello world"
OK
執行上訴陳述句之后,redis 將在資料庫中創建一個新的鍵值對,該鍵值對包括:
- 鍵是一個字串物件,底層實作是一個保存著字串 "msg" 的 SDS
- 值也是一個字串物件,底層實作是一個保存著字串 "hello world" 的 SDS,
SDS的定義
/* Note: sdshdr5 is never used, we just access the flags byte directly.
* However is here to document the layout of type 5 SDS strings. */
struct __attribute__ ((__packed__)) sdshdr5 {
unsigned char flags; /* 3 lsb of type, and 5 msb of string length */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr8 {
uint8_t len; /* used */
uint8_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr16 {
uint16_t len; /* used */
uint16_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr32 {
uint32_t len; /* used */
uint32_t alloc; /* excluding the header and null terminator */
unsigned char flags; /* 3 lsb of type, 5 unused bits */
char buf[];
};
struct __attribute__ ((__packed__)) sdshdr64 {
//記錄buf陣列中已使用的位元組數量
uint64_t len;
//分配的buf陣列長度,不包括頭和空字符結尾
uint64_t alloc;
// 標志位, 最低3位表示型別,另外5個位沒有使用
unsigned char flags;
char buf[];
};
通過原始碼可以看出 SDS 有5中 header 型別,主要是為了讓不同的字串使用不同程度的header,從而節省記憶體,
SDS 結構體的組成:
- len 記錄 buf 陣列中已使用的位元組數量
- alloc 分配的 buf 陣列長度,不包括頭和空字符結尾
- flags 標志位,最低3為表示 header 型別,另外 5 個位沒有使用,型別對應下面5中型別,
#define SDS_TYPE_5 0
#define SDS_TYPE_8 1
#define SDS_TYPE_16 2
#define SDS_TYPE_32 3
#define SDS_TYPE_64 4
- buf[] 字符陣列,用于存放字串,
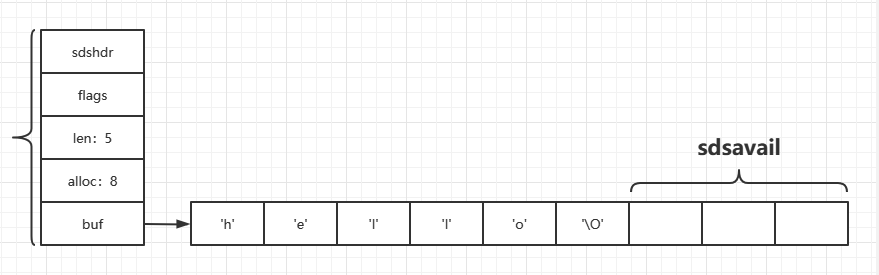
redis 雖然不是使用 c 中的字串格式,但是遵循了 c 字串以空字符結尾的慣例,保存空字符的 1 個位元組不計算在 SDS 的 len 屬性里,這樣做的好處是,可以直接重用一部分 c 字串函式庫里面的函式,
SDS相對C字串的優勢
獲取字串的長度復雜度為 O(1)
由于 C 字串并不記錄自身的長度資訊,所以為了獲取一個 C 字串的長度,程式必須遍歷整個字串,對遇到的每個字符進行計數,直到遇到代表字串結尾的空字符為止,這個操作的復雜度為 O(N) ,
和C字串不同,因為SDS在len屬性中記錄了SDS 身的長度,寫代碼時只要直接獲取len屬性值,就可以知道字串長度,所以獲取一個SDS長度的復雜度僅為 O(1) ,
防止緩沖去溢位(buffer overflow)
舉個例子,<string.h>/strcat 函式可以將 src 字串中的內容拼接到 dest 字串的末尾:
char *strcat(char *dest, const char *src);
因為 C 字串不記錄自身的長度,所以 strcat 假定用戶在執行這個函式時,已經為 dest 分配了足夠多的記憶體,可以容納 src 字串中的所有內容,而一旦這個假定不成立時,就會產生緩沖區溢位,
舉個例子,假設程式里有兩個在記憶體中緊鄰著的 C 字串 s1 和 s2 ,其中 s1 保存了字串 "hello" ,而 s2 則保存了字串 "redis",如下所示:

此時,如果執行:
strcat(s1,' world')
將 s1 的內容修改為 "hello world" ,但粗心的他卻忘了在執行 strcat 之前為 s1 分配足夠的空間,那么在 strcat 函式執行之后,s1 的資料將溢位到 s2 所在的空間中,導致 s2 保存的內容被意外地修改,
與 c 字串不同的是
SDS 的空間分配策略完全杜絕了發生緩沖區溢位的可能性:
當 SDS API 需要對 SDS 進行修改時,API 會先檢查 SDS 的空間是否滿足修改所需的要求,如果不滿足的話,API 會自動將 SDS 的空間擴展至執行修改所需的大小(即:sdsMakeRoomFor),然后才執行實際的修改操作,所以使用 SDS 既不需要手動修改 SDS 的空間大小,也不會出現前面所說的緩沖區溢位問題,
sds sdscatlen(sds s, const void *t, size_t len) {
size_t curlen = sdslen(s);
s = sdsMakeRoomFor(s,len);
if (s == NULL) return NULL;
memcpy(s+curlen, t, len);
sdssetlen(s, curlen+len);
s[curlen+len] = '\0';
return s;
}
減少因修改字串帶來的記憶體重分配次數
因為 C 字串的長度和底層陣列的長度之間存在著關聯性, 所以每次增長或者縮短一個 C 字串, 程式都總要對保存這個 C 字串的陣列進行一次記憶體重分配操作:
- 如果程式執行的是增長字串的操作, 比如拼接操作(append), 那么在執行這個操作之前, 程式需要先通過記憶體重分配來擴展底層陣列的空間大小 —— 如果忘了這一步就會產生緩沖區溢位,
- 如果程式執行的是縮短字串的操作, 比如截斷操作(trim), 那么在執行這個操作之后, 程式需要通過記憶體重分配來釋放字串不再使用的那部分空間 —— 如果忘了這一步就會產生記憶體泄漏,
因為記憶體重分配涉及復雜的演算法,并且可能需要執行系統呼叫,所以它通常是一個比較耗時的操作:
- 在一般程式中,如果修改字串長度的情況不太常出現,那么每次修改都執行一次記憶體重分配是可以接受的,
- Redis 作為資料庫,經常被用于速度要求嚴苛、資料被頻繁修改的場合,如果每次修改字串的長度都需要執行一次記憶體重分配的話,那么光是執行記憶體重分配的時間就會占去修改字串所用時間的一大部分,如果這種修改頻繁地發生的話,可能還會對性能造成影響,
為了避免 C 字串的這種缺陷, SDS 通過已使用空間解除了字串長度和底層陣列長度之間的關聯,在更改字串的時候可以只更改len屬性,而不重新分配記憶體,
空間預分配
對字串進行增長操作時,會使用一個sdsMakeRoomFor函式來擴展字串,
sds sdsMakeRoomFor(sds s, size_t addlen) {
void *sh, *newsh;
size_t avail = sdsavail(s);
size_t len, newlen;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen;
/* Return ASAP if there is enough space left. */
if (avail >= addlen) return s;
len = sdslen(s);
sh = (char*)s-sdsHdrSize(oldtype);
newlen = (len+addlen);
if (newlen < SDS_MAX_PREALLOC)
newlen *= 2;
else
newlen += SDS_MAX_PREALLOC;
type = sdsReqType(newlen);
/* Don't use type 5: the user is appending to the string and type 5 is
* not able to remember empty space, so sdsMakeRoomFor() must be called
* at every appending operation. */
if (type == SDS_TYPE_5) type = SDS_TYPE_8;
hdrlen = sdsHdrSize(type);
if (oldtype==type) {
newsh = s_realloc(sh, hdrlen+newlen+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+hdrlen;
} else {
/* Since the header size changes, need to move the string forward,
* and can't use realloc */
newsh = s_malloc(hdrlen+newlen+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, newlen);
return s;
}
sdsMakeRoomFor是sds實作中很重要的一個函式,關于它的實作代碼,我們需要注意的是:
- 如果原來字串中的空余空間夠用(avail >= addlen),那么它什么也不做,直接回傳,
- 如果需要分配空間,它會比實際請求的要多分配一些,以防備接下來繼續追加,它在字串已經比較長(長度將大于等于 1 MB)的情況下要至少多分配 SDS_MAX_PREALLOC 個位元組,這個常量在sds.h中定義為(1024*1024)=1MB,
- 按分配后的空間大小,可能需要更換 header 型別(原來 header 的 alloc 欄位太短,表達不了增加后的容量),
- 如果需要更換 header,那么整個字串空間(包括 header )都需要重新分配(s_malloc),并拷貝原來的資料到新的位置,
- 如果不需要更換header(原來的 header 夠用),那么呼叫一個比較特殊的 s_realloc,試圖在原來的地址上重新分配空間,s_realloc 的具體實作得看Redis編譯的時候選用了哪個 allocator(在Linux上默認使用jemalloc),但不管是哪個 realloc 的實作,它所表達的含義基本是相同的:它盡量在原來分配好的地址位置重新分配,如果原來的地址位置有足夠的空余空間完成重新分配,那么它回傳的新地址與傳入的舊地址相同;否則,它分配新的地址塊,并進行資料搬遷,
總結:在擴展SDS空間之前, SDS API 會先檢查未使用空間是否足夠, 如果足夠的話, API 就會直接使用未使用空間, 而無須執行記憶體重分配,通過這樣的空間預分配策略, Redis可以減少連續執行字串增長操作所需的記憶體重分配次數,
惰性空間釋放
惰性空間釋放用于優化 SDS 的字串縮短操作: 當 SDS 的 API 需要縮短 SDS 保存的字串時,程式并不立即使用記憶體重分配來回收縮短后多出來的位元組,而是把縮短后的長度記錄在len屬性中,剩余空間用于未來擴展字串用,
如 sdstrim 函式:
/* Remove the part of the string from left and from right composed just of
* contiguous characters found in 'cset', that is a null terminted C string.
*
* After the call, the modified sds string is no longer valid and all the
* references must be substituted with the new pointer returned by the call.
*
* Example:
*
* s = sdsnew("AA...AA.a.aa.aHelloWorld :::");
* s = sdstrim(s,"Aa. :");
* printf("%s\n", s);
*
* Output will be just "HelloWorld".
*/
sds sdstrim(sds s, const char *cset) {
char *start, *end, *sp, *ep;
size_t len;
sp = start = s;
ep = end = s+sdslen(s)-1;
while(sp <= end && strchr(cset, *sp)) sp++;
while(ep > sp && strchr(cset, *ep)) ep--;
len = (sp > ep) ? 0 : ((ep-sp)+1);
if (s != sp) memmove(s, sp, len);
s[len] = '\0';
sdssetlen(s,len);
return s;
}
可以看出程式結束時并沒有reallocate記憶體空間,而是修改結構體中len的屬性,
當用戶真正想free掉空閑空間時,可以使用sdsRemoveFreeSpace函式:
/* Reallocate the sds string so that it has no free space at the end.
* 重新分配sds字串,使其末尾沒有可用空間,
* The contained string remains not altered, but next concatenation operations
* will require a reallocation.
* 其中包含的字串保持不變,但進行后續連接操作將需要重新分配,
*
* After the call, the passed sds string is no longer valid and all the
* references must be substituted with the new pointer returned by the call.
* 呼叫后,傳遞的sds字串不再有效,并且所有參考必須替換為呼叫回傳的新指標,
*/
sds sdsRemoveFreeSpace(sds s) {
void *sh, *newsh;
char type, oldtype = s[-1] & SDS_TYPE_MASK;
int hdrlen, oldhdrlen = sdsHdrSize(oldtype);
size_t len = sdslen(s);
size_t avail = sdsavail(s);
sh = (char*)s-oldhdrlen;
/* Return ASAP if there is no space left. */
if (avail == 0) return s;
/* Check what would be the minimum SDS header that is just good enough to
* fit this string. */
type = sdsReqType(len);
hdrlen = sdsHdrSize(type);
/* If the type is the same, or at least a large enough type is still
* required, we just realloc(), letting the allocator to do the copy
* only if really needed. Otherwise if the change is huge, we manually
* reallocate the string to use the different header type. */
if (oldtype==type || type > SDS_TYPE_8) {
newsh = s_realloc(sh, oldhdrlen+len+1);
if (newsh == NULL) return NULL;
s = (char*)newsh+oldhdrlen;
} else {
newsh = s_malloc(hdrlen+len+1);
if (newsh == NULL) return NULL;
memcpy((char*)newsh+hdrlen, s, len+1);
s_free(sh);
s = (char*)newsh+hdrlen;
s[-1] = type;
sdssetlen(s, len);
}
sdssetalloc(s, len);
return s;
}
可以存放二進制資料
C 字串中的字符必須符合某種編碼(比如 ASCII), 并且除了字串的末尾之外, 字串里面不能包含空字符, 否則最先被程式讀入的空字符將被誤認為是字串結尾 —— 這些限制使得 C 字串只能保存文本資料, 而不能保存像圖片、音頻、視頻、壓縮檔案這樣的二進制資料,
因此, 為了確保 Redis 可以適用于各種不同的使用場景, SDS 的 API 都是二進制安全的(binary-safe): 所有 SDS API 都會以處理二進制的方式來處理 SDS 存放在 buf 陣列里的資料, 程式不會對其中的資料做任何限制、過濾、或者假設 —— 資料在寫入時是什么樣的, 它被讀取時就是什么樣,
這也是我們將 SDS 的 buf 屬性稱為位元組陣列的原因 —— Redis 不是用這個陣列來保存字符, 而是用它來保存一系列二進制資料,
SDS相關 API 總結
參考書籍:Redis 設計與實作
| 函式 | 作用 | 時間復雜度 |
|---|---|---|
sdsnew |
創建一個包含給定 C 字串的 SDS , | O(N) , N 為給定 C 字串的長度, |
sdsempty |
創建一個不包含任何內容的空 SDS , | O(1) |
sdsfree |
釋放給定的 SDS , | O(1) |
sdslen |
回傳 SDS 的已使用空間位元組數, | 這個值可以通過讀取 SDS 的 len 屬性來直接獲得,復雜度為 O(1) , |
sdsavail |
回傳 SDS 的未使用空間位元組數, | 這個值可以通過讀取 SDS 的 free 屬性來直接獲得,復雜度為 O(1) , |
sdsdup |
創建一個給定 SDS 的副本(copy), | O(N) , N 為給定 SDS 的長度, |
sdsclear |
清空 SDS 保存的字串內容, | 因為惰性空間釋放策略,復雜度為 O(1) , |
sdscat |
將給定 C 字串拼接到 SDS字串的末尾, | O(N) , N 為被拼接 C 字串的長度, |
sdscatsds |
將給定 SDS 字串拼接到另一個 SDS字串的末尾, | O(N) , N 為被拼接 SDS 字串的長度, |
sdscpy |
將給定的 C 字串復制到 SDS 里面,覆寫 SDS 原有的字串, | O(N) , N 為被復制 C 字串的長度, |
sdsgrowzero |
用空字符將 SDS 擴展至給定長度, | O(N) , N 為擴展新增的位元組數, |
sdsrange |
保留 SDS 給定區間內的資料,不在區間內的資料會被覆寫或清除, | O(N) , N 為被保留資料的位元組數, |
sdstrim |
接受一個 SDS 和一個 C 字串作為引數,從 SDS 左右兩端分別移除所有在 C字串中出現過的字符, | O(M*N) , M 為 SDS 的長度,N 為給定 C 字串的長度, |
sdscmp |
對比兩個 SDS 字串是否相同, | O(N) , N 為兩個 SDS 中較短的那個 SDS的長度, |
字串相關命令及解釋
- SET
如果 key 已經持有其他值,SET 就覆寫舊值,無視型別,
當 SET 命令對一個帶有生存時間(TTL)的鍵進行設定之后,該鍵原有的 TTL 將被清除,
- SETNX
只在鍵 key 不存在的情況下,將鍵 key 的值設定為 value ,
若鍵 key 已經存在,則 SETNX 命令不做任何動作,
- SETEX
將鍵 key 的值設定為 value ,并將鍵 key 的生存時間設定為 seconds 秒鐘,
如果鍵 key 已經存在,那么 SETEX 命令將覆寫已有的值,
SET key value
EXPIRE key seconds # 設定生存時間
SETEX 和這兩個命令的不同之處在于 SETEX 是一個原子(atomic)操作,它可以在同一時間內完成設定值和設定過期時間這兩個操作,因此 SETEX 命令在儲存快取的時候非常實用,
- PSETEX
這個命令和 SETEX 命令相似,但它以毫秒為單位設定 key 的生存時間,
- GET
回傳與鍵 key 相關聯的字串值,
- GETSET
將鍵 key 的值設為 value ,并回傳鍵 key 在被設定之前的舊值,
- STRLEN
回傳鍵 key 儲存的字串值的長度,
- APPEND
如果鍵 key 已經存在并且它的值是一個字串,APPEND 命令將把 value 追加到鍵 key 現有值的末尾,
如果 key 不存在,APPEND 就簡單地將鍵 key 的值設為 value ,就像執行 SET key value 一樣,
- SETRANGE (SETRANGE key offset value)
從偏移量 offset 開始,用 value 引數覆寫(overwrite)鍵 key 儲存的字串值,
不存在的鍵 key 當作空白字串處理,
SETRANGE 命令會確保字串足夠長以便將 value 設定到指定的偏移量上,如果鍵 key 原來儲存的字串長度比偏移量小(比如字串只有 5 個字符長,但你設定的 offset 是 10 ),那么原字符和偏移量之間的空白將用零位元組(zerobytes, "\x00" )進行填充,
- GETRANGE (GETRANGE key start end)
回傳鍵 key 儲存的字串值的指定部分,字串的截取范圍由 start 和 end 兩個偏移量決定(包括 start 和 end 在內),
- INCR
為鍵 key 儲存的數字值加上一,
如果鍵 key 不存在,那么它的值會先被初始化為 0 ,然后再執行 INCR 命令,
如果鍵 key 儲存的值不能被解釋為數字,那么 INCR 命令將回傳一個錯誤,
本操作的值限制在 64 位(bit)有符號數字表示之內,
- INCRBY
為鍵 key 儲存的數字值加上增量 increment ,
如果鍵 key 不存在,那么鍵 key 的值會先被初始化為 0 ,然后再執行 INCRBY 命令,
如果鍵 key 儲存的值不能被解釋為數字,那么 INCRBY 命令將回傳一個錯誤,
本操作的值限制在 64 位(bit)有符號數字表示之內,
- INCRBYFLOAT
為鍵 key 儲存的值加上浮點數增量 increment
- DECR
為鍵 key 儲存的數字值減去一
- DECRBY
將鍵 key 儲存的整數值減去減量 decrement ,
EG: DECRBY key decrement
- MSET (MSET key value [key value …])
如果某個給定鍵已經存在,那么 MSET 將使用新值去覆寫舊值,如果這不是你所希望的效果,請考慮使用 MSETNX 命令,這個命令只會在所有給定鍵都不存在的情況下進行設定,
MSET 是一個原子性(atomic)操作,所有給定鍵都會在同一時間內被設定,不會出現某些鍵被設定了但是另一些鍵沒有被設定的情況,
- MSETNX
當且僅當所有給定鍵都不存在時,為所有給定鍵設定值,
即使只有一個給定鍵已經存在,MSETNX 命令也會拒絕執行對所有鍵的設定操作,
MSETNX 是一個原子性(atomic)操作,所有給定鍵要么就全部都被設定,要么就全部都不設定,不可能出現第三種狀態,
- MGET
回傳給定的一個或多個字串鍵的值,
如果給定的字串鍵里面,有某個鍵不存在,那么這個鍵的值將以特殊值 nil 表示,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/244583.html
標籤:其他
上一篇:javaSE 8
下一篇:Redis--部署操作