1.資料抓取
資料集的獲取是我們進行資料分析的第一步,現在獲取資料的主要途徑一般為:現成資料;自己寫爬蟲去爬取資料;使用現有的爬蟲工具爬取所需內容,保存到資料庫,或以檔案的形式保存到本地,
博主用的是用自己撰寫的爬蟲代碼獲得資料,(爬蟲源代碼可以找博主要,在評論區回復即可)
爬蟲的設計思路
1.首先確定需要爬取網頁URL地址
2.通過HTTP/HTTPS協議來獲取相應的HTML頁面
3.提取HTML頁面里有用的資料
a.如果是需要的資料就保存起來
b.如果是頁面里的其他URL,那就繼續執行第二步,
爬蟲基本流程
發起請求
通過HTTP庫向目標站點發起請求,就是發送一個Request,請求可以包含額外的header等資訊,等待服務器的回應
獲取回應內容
如果服務器正常回應,會得到一個Reponse,Reponse的內容便是所要獲取的頁面內容,型別可能有HTML,json字串,二進制資料(如圖片視頻)等型別,
決議內容
得到的內容可能是HTML,可以用正則運算式,網頁決議庫進行決議,可能是json,可以直接轉為JSON決議物件決議,可能是二進制資料,可以做保存或者進一步處理,
保存資料
保存的形式多種多樣,可以保存成文本,也可以保存到資料庫,或者保存特定格式檔案
反爬蟲機制與對策
1 通過分析用戶請求的Headers資訊進行反爬蟲,網站中應用的最多
2通過驗證用戶行為進行反爬蟲,不如通過判斷同一個ip在短時間內是否頻繁訪問對應網站等進行分析,
3通過動態頁面增加爬取的難度,達到反爬蟲目的,
對策
1 在爬蟲中構造這些用戶請求的headers資訊,以此將爬蟲偽裝成瀏覽器
2 使用代理服務器并經常切換代理服務器方式,一般就能夠攻克限制,
3.利用一些軟體,比如selenium+phantomJS就可以攻克
反爬蟲的手段 :user-agent、代理、驗證碼、動態資料加載、加密資料
資料的選擇與處理
1 網頁文本 如HTML檔案 json格式文本
2.圖片 獲取到的是二進制檔案保存為圖片格式
3.視頻 獲取的二進制檔案保存為視頻格式即可
4.其他 只要能請求到的,都能獲取
決議方式
1 直接處理
2 json決議
3 正則運算式
4 BeautifulSoup
5 PyQuery
6 XPath
2.資料清洗
資料得到手,我們就需要對我們爬取的資料進行清洗作業,為之后的資料分析做鋪墊,如果清洗的不到位勢必會對之后的資料分析造成影響,
下文將從資料格式統一、空值處理,
格式統一
去掉資料的空格中
在用爬蟲進行資料爬取時用strip()對爬取的字串進行處理
將中文資料轉換為阿拉伯數字
例如1.7萬變成17000,代碼如下
def get_int(s):
if s[-1]=="萬":
s=s[0:-1]
s=int(float(s)*10000)
else:
s=int(s)
return s
遠行結果如下
if __name__ == '__main__':
s="1.2萬"
price = get_int(s)
print(price)#12000
空值處理
用爬蟲對資料爬取的時候,若爬取的值不存在會報錯,用例外處理陳述句try{}except:pass(try為爬取視頻資訊的代碼),跳過不存在的視頻資訊資料,
try:
html=requests.get(Link).text
doc=BeautifulSoup(html);
List=doc.find('div',{'class':'ops'}).findAll('span')
like=List[0].text.strip()#點贊
like=self.getint(like)
coin=List[1].text.strip()#投幣
coin=self.getint(coin)
collection=List[2].text.strip()#收藏
collection=self.getint(collection)
print('點贊',like)
print('投幣',coin)
print('收藏',collection)
# #將資料 拼合成字典
data={
'Title':Title,
'link':Link,
'Up':Up,
'Play':Play,
'Like':like,
'Coin':coin,
'Collection':collection,
}
# 存盤到csv檔案
self.write_dictionary_to_csv(data,'blibli2.csv')
pass
except:
pass
3.資料分析及可視化
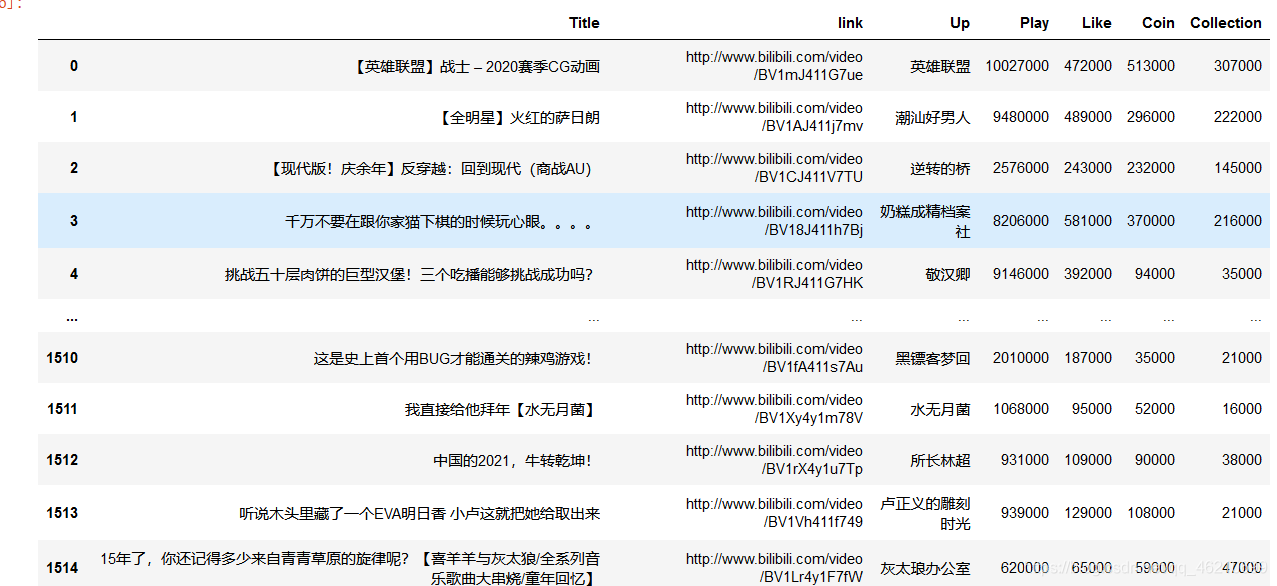
表格引數資訊如圖
對視頻排放量進行分析
對B站熱門播放量進行分析,對2020年熱門視頻的播放量分為4個等級
一千萬排放量以上為一個等級
五百萬到一千萬播放量為一個等級
五百萬到一百萬播放量為一個等級
一百萬播放量以下為一個等級
l1=len(data[data['Play'] >= 10000000])
l2=len(data[(data['Play'] < 10000000) & (data['Play'] >=5000000)])
l3=len(data[(data['Play'] < 5000000) & (data['Play'] >=1000000)])
l4=len(data[data['Play'] < 1000000])
再資料通過matplotlib庫進行可視化,得到下圖,
plt.figure(figsize=(9,13)) #調節圖形大小
labels = ['大于一千萬','一千萬到五百萬','五百萬到一百萬','小于一百萬'] #定義標簽
sizes = [l1, l2, l3, l4] #每塊值
colors = ['green', 'yellow', 'blue', 'red'] #每塊顏色定義
explode = (0,0,0,0) #將某一塊分割出來,值越大分割出的間隙越大
# 中文亂碼和坐標軸負號處理
plt.rcParams['font.sans-serif'] = ['KaiTi']
plt.rcParams['axes.unicode_minus'] = False
patches,text1,text2 = plt.pie(sizes,
explode=explode,
labels=labels,
colors=colors,
autopct = '%3.2f%%', #數值保留固定小數位
shadow = False, #無陰影設定
startangle =90, #逆時針起始角度設定
pctdistance = 0.6) #數值距圓心半徑倍數距離
#patches餅圖的回傳值,texts1餅圖外label的文本,texts2餅圖內部的文本
# x,y軸刻度設定一致,保證餅圖為圓形
plt.axis('equal')
plt.title("B站熱門播放量分布圖")
plt.legend() # 右上角顯示
plt.show()
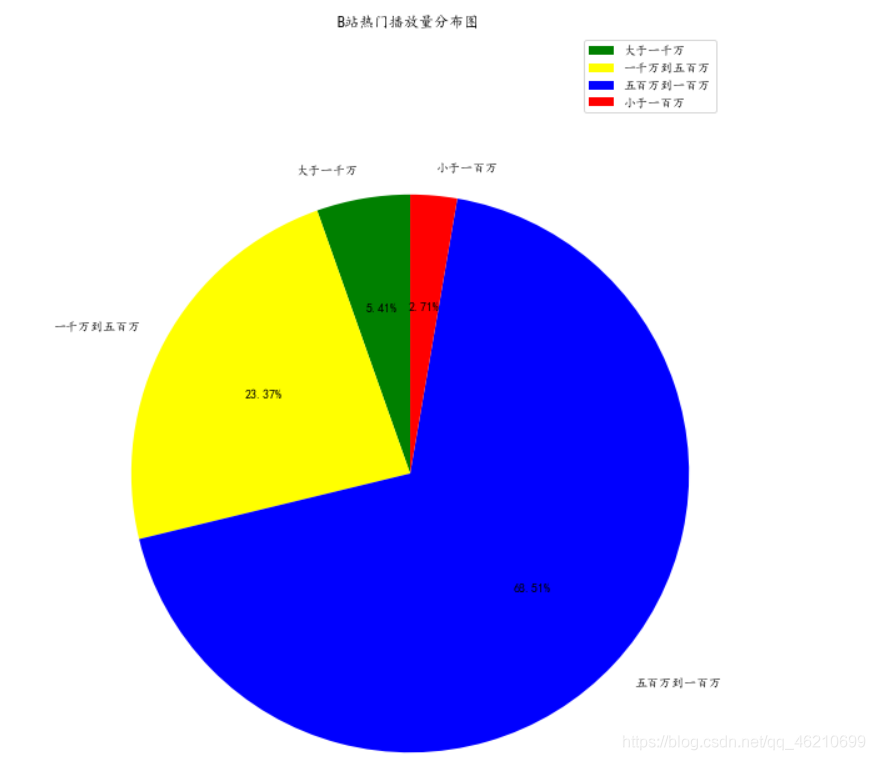 從圖中可以看出,在B站能上每周必看熱門推薦的視頻播放量大部分在五百萬到一百萬播放量,低于一百萬播放量的視頻很難上每周必看熱門推薦,而一年中播放量達到于一千萬的視頻也很少,
從圖中可以看出,在B站能上每周必看熱門推薦的視頻播放量大部分在五百萬到一百萬播放量,低于一百萬播放量的視頻很難上每周必看熱門推薦,而一年中播放量達到于一千萬的視頻也很少,
讓我們一起看看播放量排名前10的視頻是那些好看的視頻
data.nlargest(10,columns='Play')
 再資料通過matplotlib庫進行可視化,得到下圖,
再資料通過matplotlib庫進行可視化,得到下圖,
d.plot.bar(figsize = (10,8),x='Title',y='Play',title='Play top 10')
plt.xticks(rotation=60)#夾角旋轉60度
plt.show()
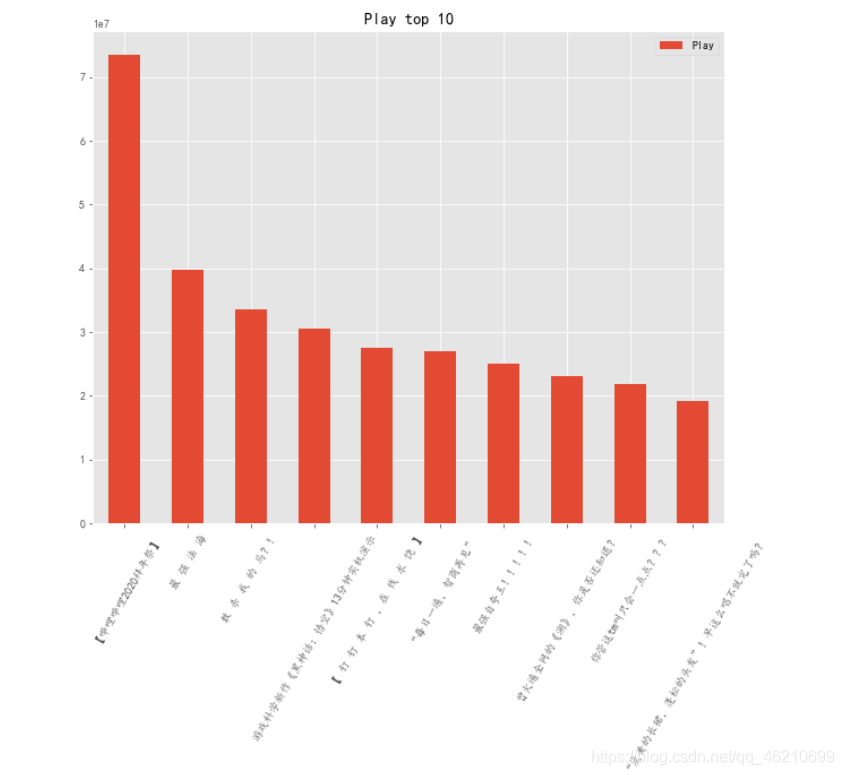 從圖中可以看出嗶哩嗶哩拜年祭最受歡迎且播放量遠遠高于其它視頻,說明B站2020年拜年祭節目進行的比較成功,
從圖中可以看出嗶哩嗶哩拜年祭最受歡迎且播放量遠遠高于其它視頻,說明B站2020年拜年祭節目進行的比較成功,
對作者進行分析
通過資料分析看那個作者的作品上熱門次數最多,從而判斷那個作者在2020年中最受歡迎,
對作者進行劃分,統計出現的次數
d2=data.loc[:,'Up'].value_counts()
d2=d2.head(10)
再資料通過matplotlib庫進行可視化,得到下圖,
d2.plot.bar(figsize = (10,8),title='UP top 10')
plt.show()
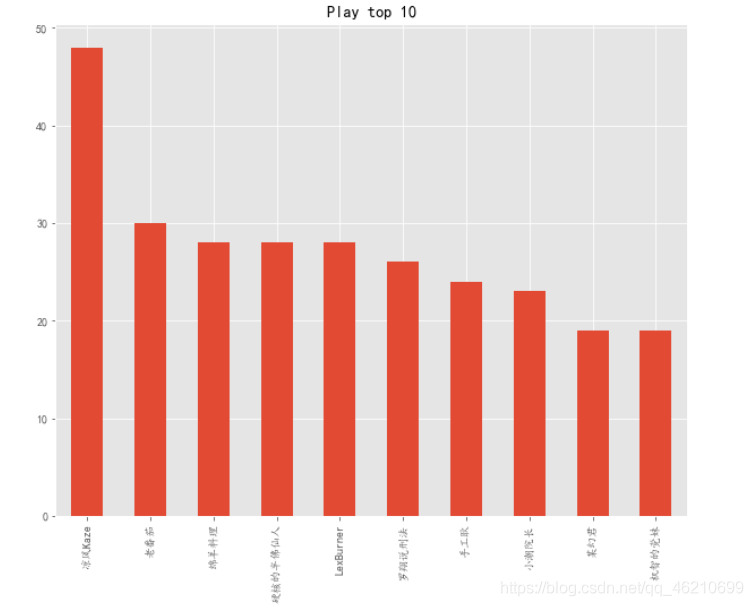 說明B站上每周熱門次數最多的作者是涼風Kaze,一年52周熱門推薦,一共出現了48次,幾乎每周熱門都有他的視頻出現,從資料來看,2020年最受歡迎的作者是涼風Kaze,
說明B站上每周熱門次數最多的作者是涼風Kaze,一年52周熱門推薦,一共出現了48次,幾乎每周熱門都有他的視頻出現,從資料來看,2020年最受歡迎的作者是涼風Kaze,
對視頻引數分析
對熱門視頻的點贊,投幣,收藏平均比例進行分析
data['點贊比例'] = data['Like'] /data['Play']
data['投幣比例'] = data['Coin'] /data['Play']
data['收藏比例'] = data['Collection'] /data['Play']
d3=data.iloc[:,8:11]
d3=d3.mean()

再資料通過matplotlib庫進行可視化,得到下圖,
d3.plot.bar(figsize = (10,8),title='UP top 10')
plt.show()
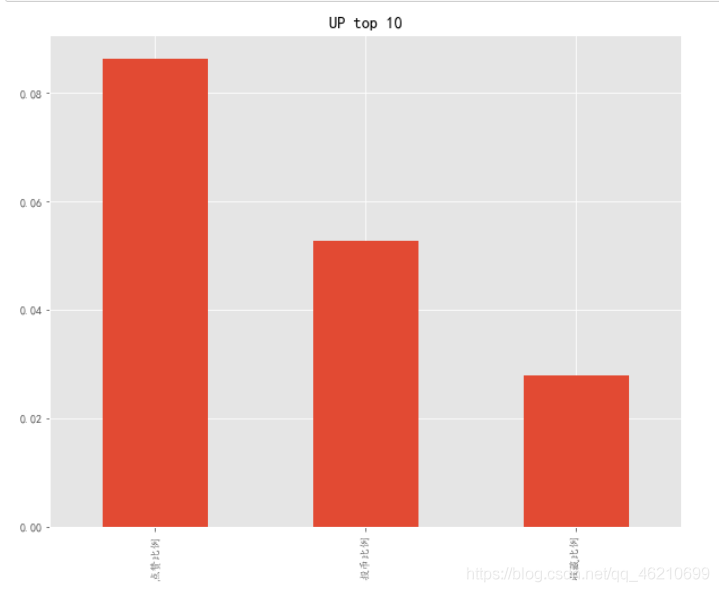 2020年中點贊比例最高,達到大約9%,說明在B站看視頻的人,平均10個人中才會有一個人點贊,而平均平均20個人中才會有一個人對視頻進行投幣,
2020年中點贊比例最高,達到大約9%,說明在B站看視頻的人,平均10個人中才會有一個人點贊,而平均平均20個人中才會有一個人對視頻進行投幣,
對標題進行分析
對標題高頻次進行提取,看那類標題比較受歡迎
首先對所有標題進行遍歷,儲存在字串s中
d4=data['Title']
s=''
for i in d4:
s=s+i
然后用詞云進行可視化
 標題中帶有“朱一旦,半佛,羅翔”等作者名或“英雄聯盟,原神”等游戲熱門視頻比較多,
標題中帶有“朱一旦,半佛,羅翔”等作者名或“英雄聯盟,原神”等游戲熱門視頻比較多,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/244678.html
標籤:python
上一篇:opencv cuda加速編譯后呼叫python介面后報錯ImportError: DLL load failed while importing cv2記錄