本文主要通過對豆瓣電影爬取的資料進行的簡要分析,觀察得出各部分之間對應的關系影響,
一.資料抓取
我們要想進行資料分析,首先就要通過爬蟲對分析物件網頁的資料爬取保存,可以保存到資料庫或者檔案形式到本地,這里我是保存在表格中,既然獲取了資料,那肯定要分析一下,豆瓣電影的各種詳細的資料,評分,影評等等在國內同型別網站中,算是高質量的,所以進行資料分析也是有價值的,下面是爬取資料的關鍵步驟:
1.HTML決議
決議的工具有很多,比如:正則運算式、Beautifulsoup、Xpath、css等,這里采用xpath方法,
# 構造第i頁的網址
url='https://movie.douban.com/top250?start='+str(25*i)
header={'user-agent':'Mozilla/5.0 (Windows NT 6.2; WOW64; rv:21.0) Gecko/20100101 Firefox/21.0'}
# 發送請求,獲得回傳的html代碼并保存在變數html中
html = requests.get(url,headers=header)
#將回傳的字串格式的html代碼轉換成xpath能處理的物件
html=etree.HTML(html.text)
headers是設定反爬蟲的措施
2.逐層查詢資訊
首先滑鼠右鍵檢查或者F12,打開當前網頁的html代碼,然后先單擊右上角處的箭頭,把滑鼠移動到你要查找的資訊上,右邊就會顯示你點擊資訊在html代碼中的位置,一個網頁的html代碼是一層一層結構化的,非常規整的,每一對尖括號包起來的是一個標簽,比如…,這就是一個span標簽,span叫標簽名,class="title"是標簽的屬性,“肖申克的救贖”是標簽的內容,標簽span在html代碼中的完整路徑應該是:
用xpath查找元素就是按照路徑一層層找下去,[@id=“wrapper”]表示查找的標簽的屬性,用標簽加上屬性,我們可以更方便的定位,不用從頭找到尾,div[1]、span[1]表示要查找的是該標簽下的第1個div標簽,第1個span標簽,找到span標簽可以用方法span[1]/text()取出其中的內容,pan[1]/@class可以取出屬性值,
datas = html.xpath('//ol[@class="grid_view"]/li')
for data in datas:
data_title=data.xpath('div/div[2]/div[@class="hd"]/a/span[1]/text()')#電影名稱
data_info=data.xpath('div/div[2]/div[@class="bd"]/p[1]/text()')#電影導演、主演、上映時間
data_score=data.xpath('div/div[2]/div[@class="bd"]/div/span[@class="rating_num"]/text()')#評分
data_num=data.xpath('div/div[2]/div[@class="bd"]/div/span[4]/text()')#評論人數
3.保存到CSV檔案
def write_dictionary_to_csv(self,dic,filename):
#file_name='{}.csv'.format(filename)
file_exists = os.path.isfile(filename)#判斷是否為檔案
with open(filename, 'a',encoding='utf-8',newline='') as f:
headers=dic.keys()#dic是字典形式最后獲取的所有資訊
w =csv.DictWriter(f,delimiter=',',lineterminator='\n',fieldnames=headers)
#以字典形式向w中寫入
if not file_exists :
w.writeheader()#保存資料
w.writerow(dic)#單行寫入
print('當前行寫入csv成功!')
二.資料可視化分析
2.1中國電影分布情況
首先對電影評分進行統計分析,由于電影資料只有top50,資料較少且都是排名靠前的電影,所以進行相應能得到符合現實情況的分析,
我們先來看看其中中國的影片:
mask1=data['country'].isin(['中國大陸','中國香港'])
data.loc[mask1]#找country列中名字是'中國大陸','中國香港'的行
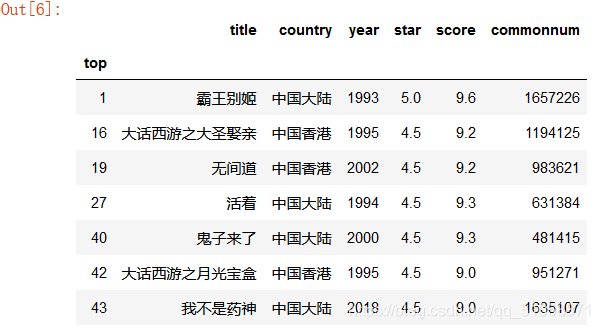 可以發現中國影片在前50就占了7個,14%分布,其中霸王別姬排名第二(top從0開始)
可以發現中國影片在前50就占了7個,14%分布,其中霸王別姬排名第二(top從0開始)
這里我們可以把中國大陸和中國香港統稱為中國,畢竟咱們都是一家人嘛,可以
countrys=list(data.country.unique())
data.loc[data['country']=='中國香港','country']='中國'#把country列中名字是中國香港的國家改為中國
data.loc[data['country']=='中國大陸','country']='中國'
mask2=data['country'].isin(['中國'])
data.loc[mask2]
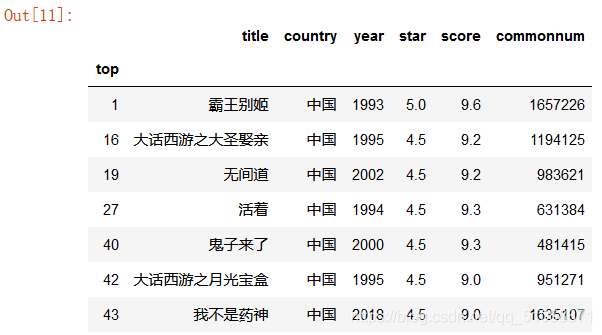
對比上一個圖可以看到全部改為了中國
2.2評分分布情況
plt.rcParams['figure.figsize']=(8,3)#圖形大小
data.groupby(['year']).sum().plot(kind='bar')#x軸
plt.xticks(rotation=60)#夾角旋轉60度
plt.ylabel('score',fontsize=15)#y軸及字號
plt.xlabel('Date',fontsize=15)#x軸及字號
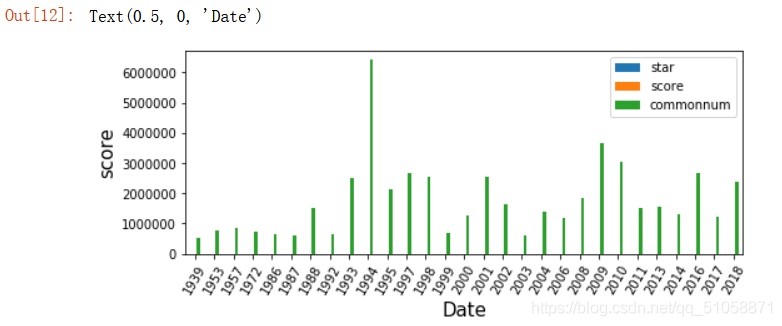 這里本想著借助圖形表分析隨著年份的推移,有沒有更好的電影出現,但這里由于評論人數基數相對于評分,星級太大,所以沒有顯示出來,不過根據評論人數的多少也是可以看出電影的受歡迎度,因此這個影響不大
這里本想著借助圖形表分析隨著年份的推移,有沒有更好的電影出現,但這里由于評論人數基數相對于評分,星級太大,所以沒有顯示出來,不過根據評論人數的多少也是可以看出電影的受歡迎度,因此這個影響不大
data.groupby('year').sum()['score']#每年好的評分作品有多少
plt.figure(figsize=(5,4))
data.groupby('year').sum()['score'].plot()#圖形顯示
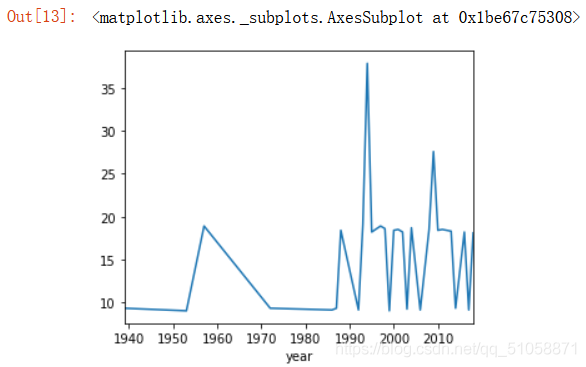 電影所代表的那個年份里,對應的評分總和比較,發現在上世紀90年代好的電影層出不窮,達到頂峰
電影所代表的那個年份里,對應的評分總和比較,發現在上世紀90年代好的電影層出不窮,達到頂峰
還可以對最受大眾討論熱烈的電影進行劃分三個等級,分析以評論人數為標準,得出熱度等級
from matplotlib import pyplot as plt1
data=pd.read_csv(r'C:\Users\許元宵\Desktop\d.csv',encoding='gbk')
len1=len(data[data['commonnum'] >= 1500000])
len2=len(data[(data['commonnum'] < 1500000) & (data['commonnum'] >=1000000)])
len3=len(data[(data['commonnum'] < 1000000) & (data['commonnum'] >=100000)])
plt1.figure(figsize=(10,15)) #調節圖形大小
labels = ['大于一百五十萬','一百萬到一百五十萬','十萬到一百萬'] #定義標簽
sizes = [len1,len2,len3]
colors = ['yellow', 'blue', 'red'] #每塊顏色定義
explode = (0,0,0) #將某一塊分割出來,值越大分割出的間隙越大
# 中文亂碼和坐標軸負號處理
plt1.rcParams['font.sans-serif'] = ['KaiTi']
plt1.rcParams['axes.unicode_minus'] = False
patches,text1,text2 = plt.pie(sizes,
explode=explode,
labels=labels,
colors=colors,
autopct = '%3.2f%%', #數值保留固定小數位
shadow = False, #無陰影設定
startangle =90, #逆時針起始角度設定
pctdistance = 0.6) #數值距圓心半徑倍數距離
#patches餅圖的回傳值,texts1餅圖外label的文本,texts2餅圖內部的文本
# x,y軸刻度設定一致,保證餅圖為圓形
plt1.axis('equal')
plt1.title("豆瓣熱門電影分布圖")
plt1.legend()
plt1.show()
通過matplotlib可視化分析得出
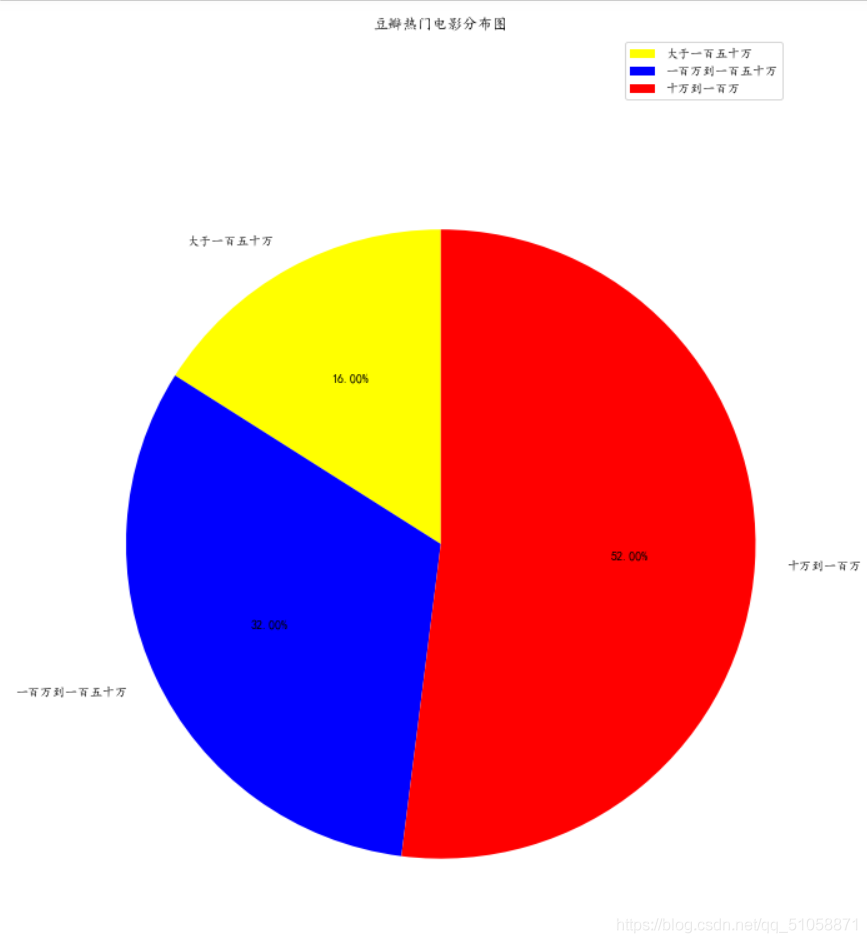 熱度第一的電影占16%,第二占32%,第三占52%,說明評論越多的電影數量越少,
熱度第一的電影占16%,第二占32%,第三占52%,說明評論越多的電影數量越少,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/245678.html
標籤:python
上一篇:python:竊取攝像頭照片
下一篇:NBA球員資訊盤點(資料分析)