2020年英文取名大資料資料分析
- 前言
- 一、概要
- 二、資料處理
- 1、資料清洗
- 2、感興趣的英文名
- 3、中文名
- 三、圖形化及分析
- 1、女生
- 2、男生
- 3、總體資料
前言
一、概要
本文主要通過pandas,NumPy來對大資料進行處理,使用matplotlib來進行資訊的圖形化顯示,
二、資料處理
1、資料清洗
資料得到手,我們就需要對我們爬取的資料進行清洗作業,為之后的資料分析做鋪墊,如果清洗的不到位勢必會對之后的資料分析造成影響,
下文將從資料格式統一、空值處理、資料去重等方面來介紹,
-
資料樣式
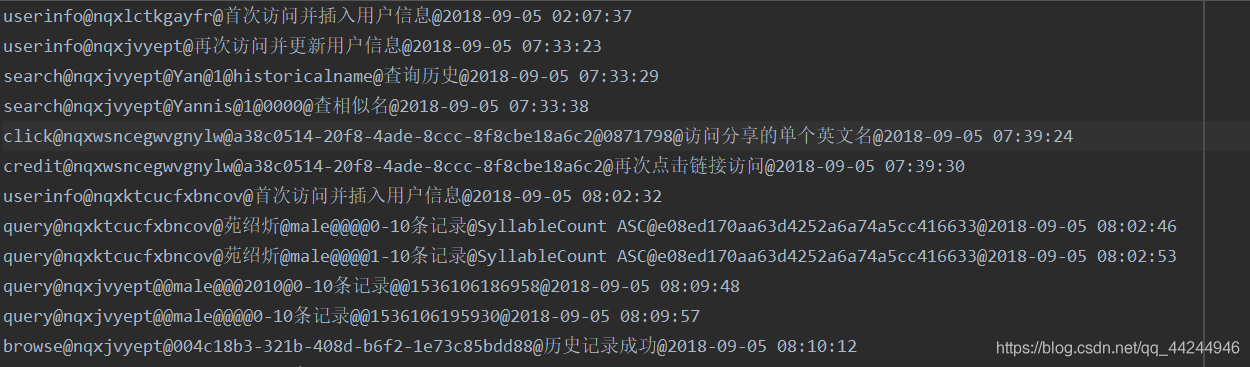
該檔案以`csv`的格式存盤,存放在我的電腦(`r"C:\Users\22392\Desktop\enName.csv"`) 中其中的資料以`@`符號作為分隔符,僅只有`search`操作/`query`操作之中可以找到名字 `search`操作中式用戶搜索的英文名字,`query`操作中則是用戶想要找到對英文名字的中文名字 (在此假定為該用戶的中文名字), -
資料清洗
1 .通過pd.read_csv("路徑"),來讀取csv檔案,得到pandas.core.frame.DataFrame物件
2 .將得到的data物件轉化為陣列,并且遍歷陣列
3 .通過split("@")方法對陣列中的每一條字串資料進行遍歷分割
4 .將資料分類,分別存放于二維串列query_lst和search_lst中
5 .把串列資訊分別設定列索引,并轉化為DataFrame物件(search_data 和query_data)
6 .search_data存放中文名字,query_data存放英文名字
import pandas as pd
import numpy as np
from pandas import DataFrame
data = pd.read_csv(r"C:\Users\22392\Desktop\enName.csv",sep="@ ",encoding='utf-8', engine='python')
dataset = np.asarray(data)
lst=[]
query_lst=[]
search_lst=[]
query_search_lst=[]
for x in dataset:
lst = str(x).split("@")
if lst[0]=="['query":
lst[0]='query'
lst[-1]=lst[-1][0:-2]
query_lst.append(lst)
query_search_lst.append(lst)
elif lst[0]=="['search":
lst[0]='search'
lst[-1] = lst[-1][0:-2]
search_lst.append(lst)
query_search_lst.append(lst)
search_columns = ["operate","user",'name','路徑',"描述","state","時間"]
search_data = DataFrame(search_lst,columns =search_columns)
query_columns =["operate","user","name","sex","條件1","條件2","條件3","條件4","條件5","條件6","時間"]
query_data = DataFrame(query_lst,columns=query_columns)
query_data = query_data.loc[:, ["operate","user","name","sex"]]
-
資料去重
搜索獲得的:search["operate","user",'name',"state"]
1 .去掉search_data中name為空的行
2 .去掉['user','name']完全相同的行,只保留一個
3 .只保留有用的列的資訊查詢獲得的:
query_data["operate","user","name","sex"]
1.去掉['user','name']完全相同的行,只保留一個
2 .去掉query中name為空的行
3 .去掉user重復的行,只保留第一個,確保一個用戶,一個姓名
#去掉'user','name'相同的行,且name不為空
search=search_data[search_data["name"] != ""].drop_duplicates(subset=['user','name'],keep='first',inplace=False)
search=search.loc[: ,["operate","user","name","state"]]
q_data=query_data.drop_duplicates(subset=['user','name'],keep='first',inplace=False)
#將用戶的名字保存在串列中
name=(q_data[q_data["name"]!=""].drop_duplicates(subset=['user'],keep='first',inplace=False)).name.tolist()
2、感興趣的英文名
此處只列出對女生的演算法分析:
1 選擇sex為female,且name不為空的user資訊存放在一個串列中f2_list,遍歷搜索資訊;
2 由于search中不包含性別資訊,所以要通過user是否存在于f2_list中來進行判斷,該用戶是否為female,然后將female搜索的名字,保存在一個串列中;
3 通過dataframe物件的value_counts()方法獲取top20資料,
#選出女生的用戶
female=q_data[(q_data["sex"]=="female" )&(q_data["name"]!="") ]
f1=female.drop_duplicates(subset=['user'],keep='first',inplace=False)
f2_list=f1.user.tolist()
#選出男生的用戶
male = q_data[(q_data["sex"]=="male")&(q_data["name"]!="")]
m1=male.drop_duplicates(subset=['user'],keep='first',inplace=False)
m2_list=male.user.tolist()
f3_list=[]#女生搜索的英文名字
m3_list=[]#男生搜索的英文名字
for x in range(0,len(search)):
#當用戶編號出現在存盤女上的用戶編號的串列中的時候
if search.iloc[x,1] in f2_list:
#用戶為女生
f3_list.append(search_data.iloc[x,2])
elif search.iloc[x,1] in m2_list:
#用戶為男生
m3_list.append(search.iloc[x,2])
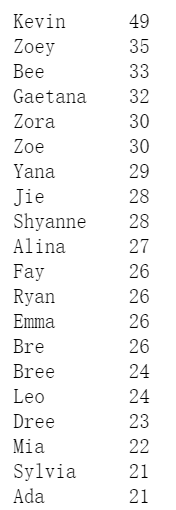
#女生top20英文名數量統計
f4=DataFrame(f3_list).value_counts()
print(f4[0:20])
#男生top20英文名統計
m4=DataFrame(m3_list).value_counts()
print(m4[0:20])
獲取資料如下
女生:
男生:

3、中文名
女生名字中最多的漢字top20
#對女生用戶資訊進行處理 {篩選掉一個用戶多次輸入姓名的,只保留第一個}
#出現在女生名字中對多的20個漢字(除去姓式)
f1=female.drop_duplicates(subset=['user'],keep='first',inplace=False)
f2=f1.name.tolist()
#存放姓
f3=[]
#存放名
f4=[]
book_names = ["趙", "錢", "孫", "李", "周", "吳", "鄭", "王", "馮", "陳", "褚", "衛", "蔣", "沈", "韓", "楊", "朱", "秦", "尤", "許", "何", "呂", "施", "張", "孔", "曹", "嚴", "華", "金", "魏", "陶", "姜", "戚", "謝", "鄒", "喻", "柏", "水", "竇", "章", "云", "蘇", "潘", "葛", "奚", "范", "彭", "郎", "魯", "韋", "昌", "馬", "苗", "鳳", "花", "方", "俞", "任", "袁", "柳", "酆", "鮑", "史", "唐", "費", "廉", "岑", "薛", "雷", "賀", "倪", "湯", "滕", "殷", "羅", "畢", "郝", "鄔", "安", "常", "樂", "于", "時", "傅", "皮", "卞", "齊", "康", "伍", "余", "元", "卜", "顧", "孟", "平", "黃", "和", "穆", "蕭", "尹", "姚", "邵", "湛", "汪", "祁", "毛", "禹", "狄", "米", "貝", "明", "臧", "計", "伏", "成", "戴", "談", "宋", "茅", "龐", "熊", "紀", "舒", "屈", "項", "祝", "董", "梁", "杜", "阮", "藍", "閔", "席", "季", "麻", "強", "賈", "路", "婁", "危", "江", "童", "顏", "郭", "梅", "盛", "林", "刁", "鐘", "徐", "邱", "駱", "高", "夏", "蔡", "田", "樊", "胡", "凌", "霍", "虞", "萬", "支", "柯", "昝", "管", "盧", "莫", "經", "房", "裘", "繆", "干", "解", "應", "宗", "丁", "宣", "賁", "鄧", "郁", "單", "杭", "洪", "包", "諸", "左", "石", "崔", "吉", "鈕", "龔", "程", "嵇", "邢", "滑", "裴", "陸", "榮", "翁", "荀", "羊", "於", "惠", "甄", "曲", "家", "封", "芮", "羿", "儲", "靳", "汲", "邴", "糜", "松", "井", "段", "富", "巫", "烏", "焦", "巴", "弓", "牧", "隗", "山", "谷", "車", "侯", "宓", "蓬", "全", "郗", "班", "仰", "秋", "仲", "伊", "宮", "寧", "仇", "欒", "暴", "甘", "鈄", "厲", "戎", "祖", "武", "符", "劉", "景", "詹", "束", "龍", "葉", "幸", "司", "韶", "郜", "黎", "薊", "薄", "印", "宿", "白", "懷", "蒲", "臺", "叢", "鄂", "索", "咸", "籍", "賴", "卓", "藺", "屠", "蒙", "池", "喬", "陰", "郁", "胥", "能", "蒼", "雙", "聞", "莘", "黨", "翟", "譚", "貢", "勞", "逄", "姬", "申", "扶", "堵", "冉", "宰", "酈", "雍", "卻", "璩", "桑", "桂", "濮", "牛", "壽", "通", "邊", "扈", "燕", "冀", "郟", "浦", "尚", "農", "溫", "別", "莊", "晏", "柴", "瞿", "閻", "充", "慕", "連", "茹", "習", "宦", "艾", "魚", "容", "向", "古", "易", "慎", "戈", "廖", "庚", "終", "暨", "居", "衡", "步", "都", "耿", "滿", "弘", "匡", "國", "文", "寇", "廣", "祿", "闕", "東", "毆", "殳", "沃", "利", "蔚", "越", "夔", "隆", "師", "鞏", "厙", "聶", "晁", "勾", "敖", "融", "冷", "訾", "辛", "闞", "那", "簡", "饒", "空", "曾", "毋", "沙", "乜", "養", "鞠", "須", "豐", "巢", "關", "蒯", "相", "查", "后", "荊", "紅", "游", "竺", "權逯", "蓋益", "桓", "公", "萬俟", "司馬", "上官", "歐陽", "夏侯", "諸葛", "聞人", "東方", "赫連", "皇甫", "尉遲", "公羊", "澹臺", "公冶", "宗政", "濮陽", "淳于", "單于", "太叔", "申屠", "公孫", "仲孫", "軒轅", "令狐", "鐘離", "宇文", "長孫", "慕容", "鮮于", "閭丘", "司徒", "司空", "亓官", "司寇", "仉", "督", "子車", "顓孫", "端木", "巫馬", "公西", "漆雕", "樂正", "壤駟", "公良", "拓跋", "夾谷", "宰父", "谷粱", "晉", "楚", "閆", "法", "汝", "鄢", "涂", "欽", "段干", "百里", "東郭", "南門", "呼延", "歸海", "羊舌", "微生", "岳", "帥", "緱", "亢", "況", "郈", "有", "琴", "梁丘", "左丘", "東門", "西門", "商", "牟", "佘", "佴", "伯", "賞", "宮", "墨", "哈", "譙", "笪", "年", "愛", "陽", "佟", "第五", "言福"]
for x in f2:
if len(x)<2 or len(x)>4:
f2.remove(x)
elif x[0] in book_names and len(x)<4:
f3.append(x[0])
for y in x[1:]:
f4.append(y)
elif x[:2] in book_names and len(x)>2:
f3.append(x[:2])
for y in x[1:]:
f4.append(y)
else:
f2.remove(x)
#f31=DataFrame(f3).value_counts()
#print(f31[0:20])
f41=DataFrame(f4).value_counts()
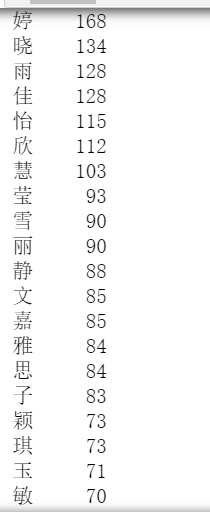
#女生名字中最多的漢字top20
print(f41[0:20])
女生名字中最多的漢字top20
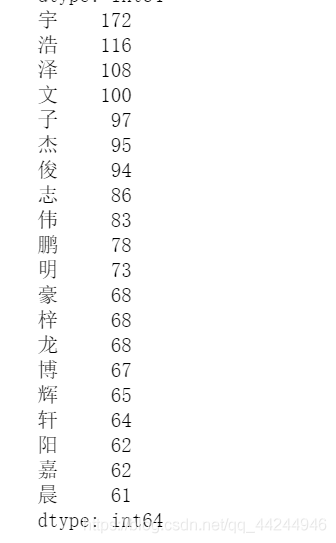
男生姓名中最多的漢字top20
名字字數以及單姓和復姓人數
在name串列中,進行篩選,條件為
1 姓名字數在[2,4]
2 若是單姓,則姓名長度小于4
3 若是復姓,則姓名長度大于2
4 將名字字數資訊,存放在字典之中
名字中子的個數:
#單姓人數
single_count = []
#復姓人數
double_count = []
d={"2":0,"3":0,"4":0}
book_names = ["趙", "錢", "孫", "李", "周", "吳", "鄭", "王", "馮", "陳", "褚", "衛", "蔣", "沈", "韓", "楊", "朱", "秦", "尤", "許", "何", "呂", "施", "張", "孔", "曹", "嚴", "華", "金", "魏", "陶", "姜", "戚", "謝", "鄒", "喻", "柏", "水", "竇", "章", "云", "蘇", "潘", "葛", "奚", "范", "彭", "郎", "魯", "韋", "昌", "馬", "苗", "鳳", "花", "方", "俞", "任", "袁", "柳", "酆", "鮑", "史", "唐", "費", "廉", "岑", "薛", "雷", "賀", "倪", "湯", "滕", "殷", "羅", "畢", "郝", "鄔", "安", "常", "樂", "于", "時", "傅", "皮", "卞", "齊", "康", "伍", "余", "元", "卜", "顧", "孟", "平", "黃", "和", "穆", "蕭", "尹", "姚", "邵", "湛", "汪", "祁", "毛", "禹", "狄", "米", "貝", "明", "臧", "計", "伏", "成", "戴", "談", "宋", "茅", "龐", "熊", "紀", "舒", "屈", "項", "祝", "董", "梁", "杜", "阮", "藍", "閔", "席", "季", "麻", "強", "賈", "路", "婁", "危", "江", "童", "顏", "郭", "梅", "盛", "林", "刁", "鐘", "徐", "邱", "駱", "高", "夏", "蔡", "田", "樊", "胡", "凌", "霍", "虞", "萬", "支", "柯", "昝", "管", "盧", "莫", "經", "房", "裘", "繆", "干", "解", "應", "宗", "丁", "宣", "賁", "鄧", "郁", "單", "杭", "洪", "包", "諸", "左", "石", "崔", "吉", "鈕", "龔", "程", "嵇", "邢", "滑", "裴", "陸", "榮", "翁", "荀", "羊", "於", "惠", "甄", "曲", "家", "封", "芮", "羿", "儲", "靳", "汲", "邴", "糜", "松", "井", "段", "富", "巫", "烏", "焦", "巴", "弓", "牧", "隗", "山", "谷", "車", "侯", "宓", "蓬", "全", "郗", "班", "仰", "秋", "仲", "伊", "宮", "寧", "仇", "欒", "暴", "甘", "鈄", "厲", "戎", "祖", "武", "符", "劉", "景", "詹", "束", "龍", "葉", "幸", "司", "韶", "郜", "黎", "薊", "薄", "印", "宿", "白", "懷", "蒲", "臺", "叢", "鄂", "索", "咸", "籍", "賴", "卓", "藺", "屠", "蒙", "池", "喬", "陰", "郁", "胥", "能", "蒼", "雙", "聞", "莘", "黨", "翟", "譚", "貢", "勞", "逄", "姬", "申", "扶", "堵", "冉", "宰", "酈", "雍", "卻", "璩", "桑", "桂", "濮", "牛", "壽", "通", "邊", "扈", "燕", "冀", "郟", "浦", "尚", "農", "溫", "別", "莊", "晏", "柴", "瞿", "閻", "充", "慕", "連", "茹", "習", "宦", "艾", "魚", "容", "向", "古", "易", "慎", "戈", "廖", "庚", "終", "暨", "居", "衡", "步", "都", "耿", "滿", "弘", "匡", "國", "文", "寇", "廣", "祿", "闕", "東", "毆", "殳", "沃", "利", "蔚", "越", "夔", "隆", "師", "鞏", "厙", "聶", "晁", "勾", "敖", "融", "冷", "訾", "辛", "闞", "那", "簡", "饒", "空", "曾", "毋", "沙", "乜", "養", "鞠", "須", "豐", "巢", "關", "蒯", "相", "查", "后", "荊", "紅", "游", "竺", "權逯", "蓋益", "桓", "公", "萬俟", "司馬", "上官", "歐陽", "夏侯", "諸葛", "聞人", "東方", "赫連", "皇甫", "尉遲", "公羊", "澹臺", "公冶", "宗政", "濮陽", "淳于", "單于", "太叔", "申屠", "公孫", "仲孫", "軒轅", "令狐", "鐘離", "宇文", "長孫", "慕容", "鮮于", "閭丘", "司徒", "司空", "亓官", "司寇", "仉", "督", "子車", "顓孫", "端木", "巫馬", "公西", "漆雕", "樂正", "壤駟", "公良", "拓跋", "夾谷", "宰父", "谷粱", "晉", "楚", "閆", "法", "汝", "鄢", "涂", "欽", "段干", "百里", "東郭", "南門", "呼延", "歸海", "羊舌", "微生", "岳", "帥", "緱", "亢", "況", "郈", "有", "琴", "梁丘", "左丘", "東門", "西門", "商", "牟", "佘", "佴", "伯", "賞", "宮", "墨", "哈", "譙", "笪", "年", "愛", "陽", "佟", "第五", "言福"]
for x in name:
if len(x)<2 or len(x)>4:
name.remove(x)
elif x[0] in book_names and len(x)<4:4
d[str(len(x))]+=1
single_count.append(x)
elif x[:2] in book_names and len(x)>2:
d[str(len(x))]+=1
double_count.append(x)
else:
name.remove(x)


三、圖形化及分析
1、女生
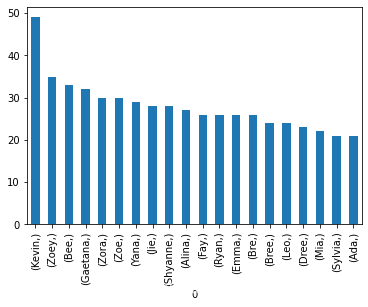
- 最感興趣的top20個英文名
柱狀圖表示
利用series物件的plot(kind='bar')方法,可實作柱狀圖的顯示,
#女生top20
import matplotlib.pyplot as plt
f4=DataFrame(f3_list).value_counts()
(f4[0:20]).plot(kind='bar')
在jupyter中運行顯示如下:
詞云圖

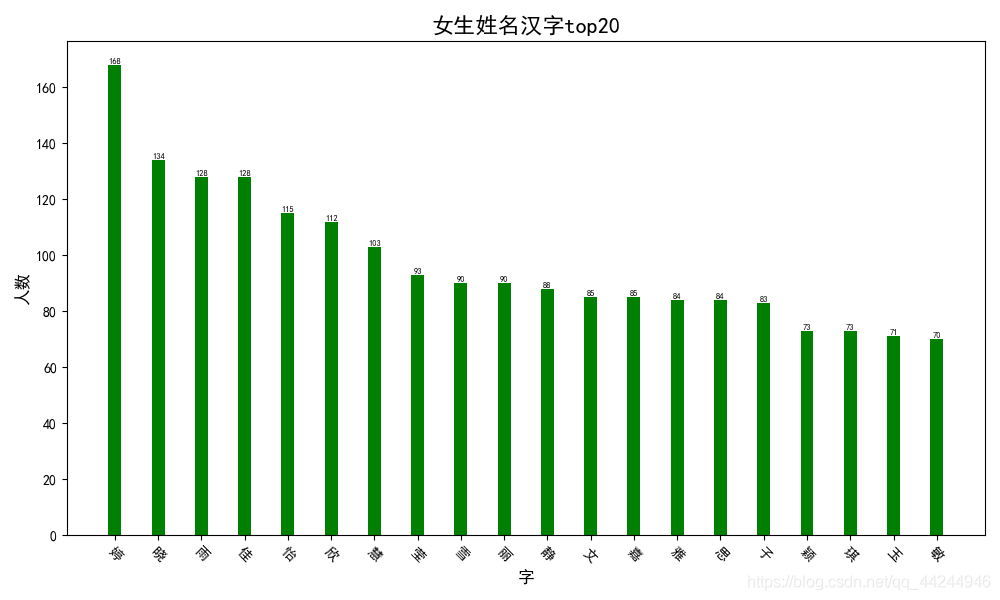
3. 女生中文名字中最常出現的漢字
詞云顯示:
f5 =((DataFrame(f4).value_counts())[0:20]).index
lst=[]
for x in f5:
lst.append(str(x)[2])
# # #生成詞云
import matplotlib.pyplot as plt
import wordcloud
plt.rcParams['font.sans-serif']=['KaiTi']
plt.rcParams['axes.unicode_minus'] = False
word_clean=" ".join(lst)
wc = wordcloud.WordCloud(font_path='C:/Windows/Fonts/simkai.ttf',#指定字體型別
background_color = "white",#指定背景顏色
max_words = 20, # 詞云顯示的最大詞數
max_font_size = 255#指定最大字號
) #指定模板
wc = wc.generate(word_clean)##生成詞云
plt.imshow(wc)
plt.axis("off")
plt.show()
 繪制柱狀圖
繪制柱狀圖
import matplotlib.pyplot as plt
import numpy as np
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用來正常顯示中文標簽
plt.rcParams['axes.unicode_minus'] = False # 用來正常顯示負號
# 獲取資料
names =lst
nums = (DataFrame(f4).value_counts())[0:20].values
print(names)
print(nums)
# 繪圖
plt.figure(figsize=[10, 6])
plt.bar(names, nums, width=0.3, color='green')
# 設定標題
plt.xlabel("字", fontproperties='SimHei', size=12)
plt.ylabel("人數", fontproperties='SimHei', rotation=90, size=12)
plt.title("女生姓名漢字top20", fontproperties='SimHei', size=16)
plt.xticks(list(names), fontproperties='SimHei', rotation=-45, size=10)
# 顯示數字
for a, b in zip(list(names), list(nums)):
plt.text(a, b, b, ha='center', va='bottom', size=6)
plt.show()
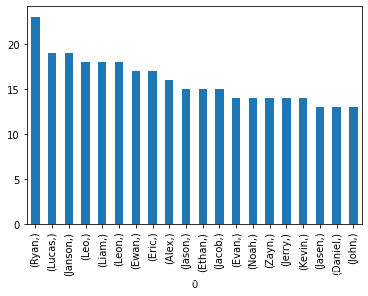
2、男生
- 最感興趣的top20個英文名
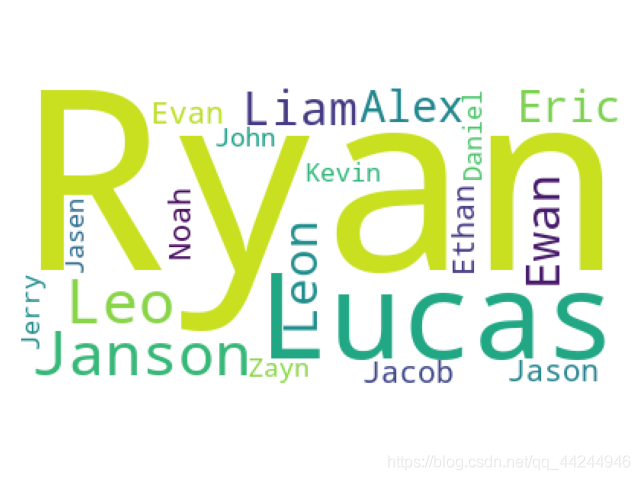
- 男生中文名字中最常出現的漢字
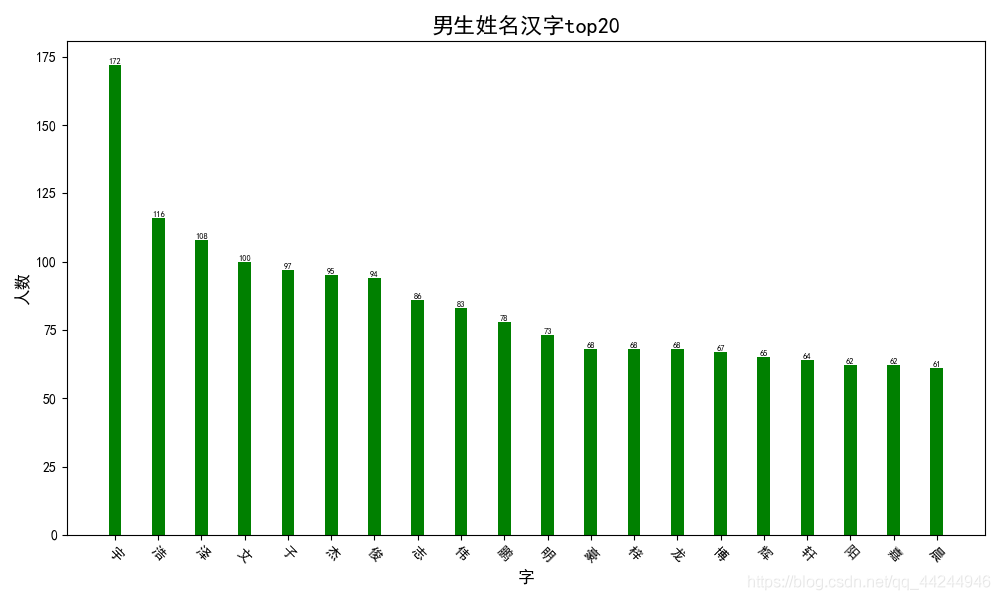

3、總體資料
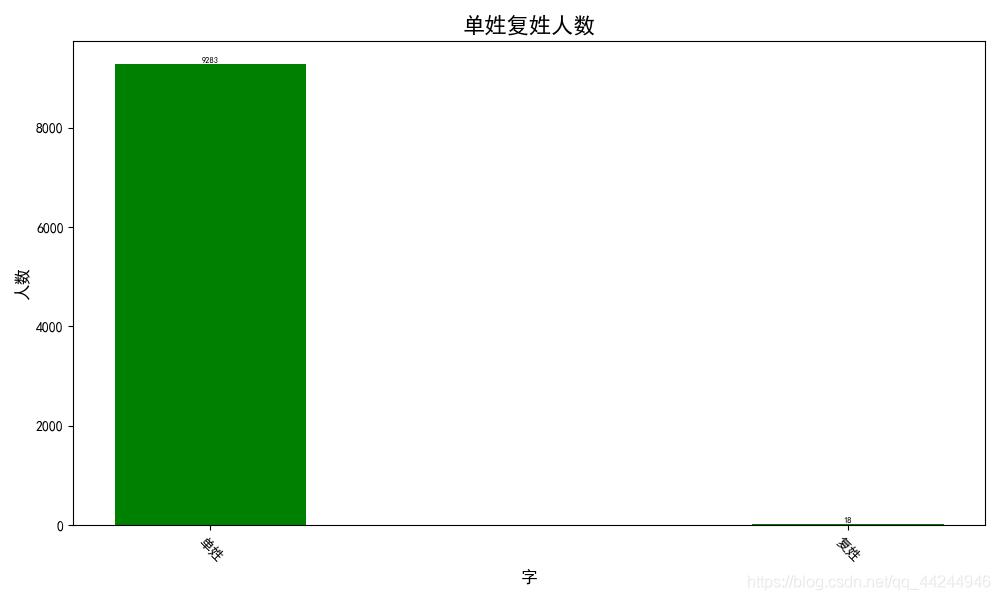
- 單姓以及復姓人數
單姓人數明顯多余復姓人數
單姓:復姓=9293:12
- 名字中的漢字個數
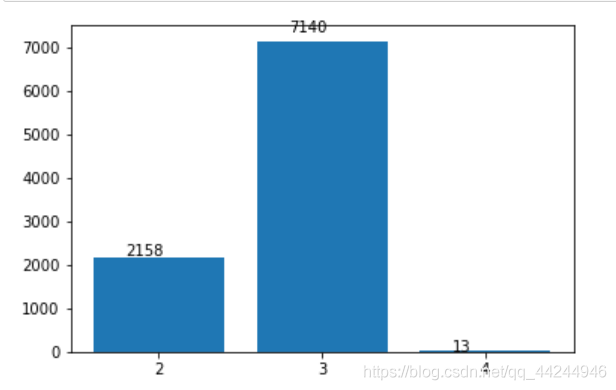
由影像可以看出,三個字的中文名人數遠遠大于兩個字的人數,四字姓名更是稀少, - 搜索的英文名未包含在資料庫中統計
#推薦的相似名,未在庫中現
s1=search_data.loc[: ,["name","state"]]
s2=s1[s1["state"]=="推薦的相似名"]
s2.name.value_counts()

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/245681.html
標籤:python
上一篇:1499飛天茅臺腳本使用程序中遇到的Python問題匯總索引目錄【淘寶-天貓超市、京東】
下一篇:豆瓣高分電影資訊分析(資料分析)