前言
本文的文字及圖片過濾網路,可以學習,交流使用,不具有任何商業用途,如有問題請及時聯系我們以作處理,
本篇文章就使用python爬蟲框架scrapy采集網站的一些資料,
Python爬蟲、資料分析、網站開發等案例教程視頻免費在線觀看
https://space.bilibili.com/523606542
基本開發環境
- Python 3.6
- pycharm
如何安裝scrapy
在cmd命令列當中 pip install scrapy就可以安裝了,但是一般情況都會出現網路超時的情況,
建議切換國內常規源安裝 pip install -i國內常規地址包名
例如:
pip install -i https://mirrors.aliyun.com/pypi/simple/ scrapy
國內常用源別名地址:
清華:https://pypi.tuna.tsinghua.edu.cn/simple 阿里云:http://mirrors.aliyun.com/pypi/simple/ 中國科技大學 https://pypi.mirrors.ustc.edu.cn/simple/ 華中理工大學:http://pypi.hustunique.com/ 山東理工大學:http://pypi.sdutlinux.org/ 豆瓣:http://pypi.douban.com/simple/
你可能會出現的報錯:
在安裝Scrapy的程序中可能會遇到VC ++等錯誤,可以安裝洗掉模塊的離線包

Scrapy如何爬取網站資料
本篇文章以豆瓣電影Top250的資料為例,講解一下scrapy框架爬取資料的基本流程,
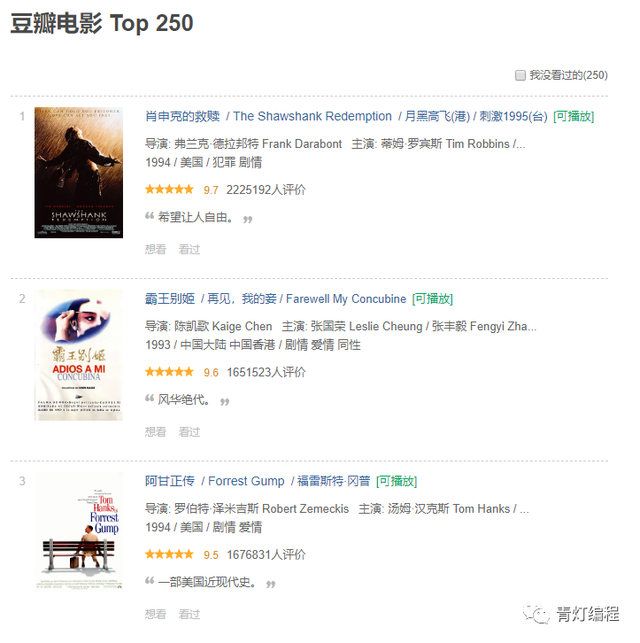
豆瓣Top250這個資料就不過多分析,靜態網站,網頁結構十分適合寫爬取,所以很多基礎入門的爬蟲案例都是以豆瓣電影資料以及貓眼電影資料為例的,
Scrapy的爬蟲專案的創建流程
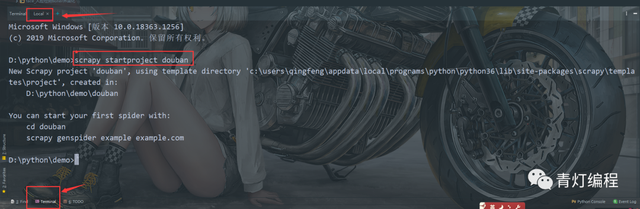
1.創建一個爬蟲專案
在Pycharm中選擇Terminal在Local里面輸入
scrapy startproject +(專案名字<獨一無二>)
2.cd切換到爬蟲專案目錄
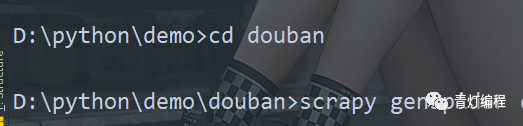
3.創建爬蟲檔案
scrapy genspider(+爬蟲檔案的名字<獨一無二的>)(+域名限制)

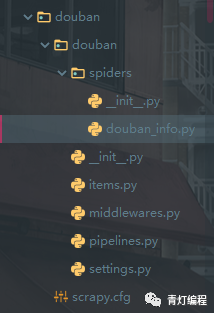
這就對于scrapy的專案創建以及爬蟲檔案創建完成了,
Scrapy的爬蟲代碼撰寫
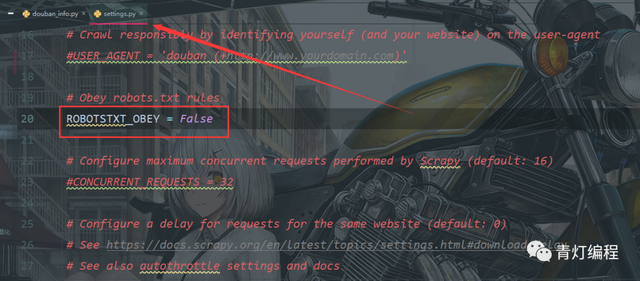
1,在settings.py檔案中關閉robots協議默認是True
2,在爬蟲檔案下修改起始網址
start_urls = ['https://movie.douban.com/top250?filter=']
把start_urls改成豆瓣導航網址的鏈接,也就是你爬取資料的第一頁的url地址
3,寫決議資料的業務邏輯
爬取內容如下:

douban_info.py
import scrapy from ..items import DoubanItem class DoubanInfoSpider(scrapy.Spider): name = 'douban_info' allowed_domains = ['douban.com'] start_urls = ['https://movie.douban.com/top250?start=0&filter='] def parse(self, response): lis = response.css('.grid_view li') print(lis) for li in lis: title = li.css('.hd span:nth-child(1)::text').get() movie_info = li.css('.bd p::text').getall() info = ''.join(movie_info).strip() score = li.css('.rating_num::text').get() number = li.css('.star span:nth-child(4)::text').get() summary = li.css('.inq::text').get() print(title) yield DoubanItem(title=title, info=info, score=score, number=number, summary=summary) href = response.css('#content .next a::attr(href)').get() if href: next_url = 'https://movie.douban.com/top250' + href yield scrapy.Request(url=next_url, callback=self.parse)
itmes.py
import scrapy class DoubanItem(scrapy.Item): # define the fields for your item here like: title = scrapy.Field() info = scrapy.Field() score = scrapy.Field() number = scrapy.Field() summary = scrapy.Field()
middlewares.py
import faker def get_cookies(): """獲取cookies的函式""" headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36'} response = requests.get(url='https://movie.douban.com/top250?start=0&filter=', headers=headers) return response.cookies.get_dict() def get_proxies(): """代理請求的函式""" proxy_data = requests.get(url='http://127.0.0.1:5000/get/').json() return proxy_data['proxy'] class HeadersDownloaderMiddleware: """headers中間件""" def process_request(self, request, spider): # 可以拿到請求體 fake = faker.Faker() # request.headers 拿到請求頭, 請求頭是一個字典 request.headers.update( { 'user-agent': fake.user_agent(), } ) return None class CookieDownloaderMiddleware: """cookie中間件""" def process_request(self, request, spider): # request.cookies 設定請求的cookies, 是字典 # get_cookies() 呼叫獲取cookies的方法 request.cookies.update(get_cookies()) return None class ProxyDownloaderMiddleware: """代理中間件""" def process_request(self, request, spider): # 獲取請求的 meta , 字典 request.meta['proxy'] = get_proxies() return None
pipelines.py
import csv class DoubanPipeline: def __init__(self): self.file = open('douban.csv', mode='a', encoding='utf-8', newline='') self.csv_file = csv.DictWriter(self.file, fieldnames=['title', 'info', 'score', 'number', 'summary']) self.csv_file.writeheader() def process_item(self, item, spider): dit = dict(item) dit['info'] = dit['info'].replace('\n', "").strip() self.csv_file.writerow(dit) return item def spider_closed(self, spider) -> None: self.file.close()
setting.py
# Scrapy settings for douban project # # For simplicity, this file contains only settings considered important or # commonly used. You can find more settings consulting the documentation: # # https://docs.scrapy.org/en/latest/topics/settings.html # https://docs.scrapy.org/en/latest/topics/downloader-middleware.html # https://docs.scrapy.org/en/latest/topics/spider-middleware.html BOT_NAME = 'douban' SPIDER_MODULES = ['douban.spiders'] NEWSPIDER_MODULE = 'douban.spiders' # Crawl responsibly by identifying yourself (and your website) on the user-agent #USER_AGENT = 'douban (+http://www.yourdomain.com)' # Obey robots.txt rules ROBOTSTXT_OBEY = False # Configure maximum concurrent requests performed by Scrapy (default: 16) #CONCURRENT_REQUESTS = 32 # Configure a delay for requests for the same website (default: 0) # See https://docs.scrapy.org/en/latest/topics/settings.html#download-delay # See also autothrottle settings and docs #DOWNLOAD_DELAY = 3 # The download delay setting will honor only one of: #CONCURRENT_REQUESTS_PER_DOMAIN = 16 #CONCURRENT_REQUESTS_PER_IP = 16 # Disable cookies (enabled by default) #COOKIES_ENABLED = False # Disable Telnet Console (enabled by default) #TELNETCONSOLE_ENABLED = False # Override the default request headers: #DEFAULT_REQUEST_HEADERS = { # 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8', # 'Accept-Language': 'en', #} # Enable or disable spider middlewares # See https://docs.scrapy.org/en/latest/topics/spider-middleware.html # SPIDER_MIDDLEWARES = { # 'douban.middlewares.DoubanSpiderMiddleware': 543, # } # Enable or disable downloader middlewares # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html DOWNLOADER_MIDDLEWARES = { 'douban.middlewares.HeadersDownloaderMiddleware': 543, } # Enable or disable extensions # See https://docs.scrapy.org/en/latest/topics/extensions.html #EXTENSIONS = { # 'scrapy.extensions.telnet.TelnetConsole': None, #} # Configure item pipelines # See https://docs.scrapy.org/en/latest/topics/item-pipeline.html ITEM_PIPELINES = { 'douban.pipelines.DoubanPipeline': 300, } # Enable and configure the AutoThrottle extension (disabled by default) # See https://docs.scrapy.org/en/latest/topics/autothrottle.html #AUTOTHROTTLE_ENABLED = True # The initial download delay #AUTOTHROTTLE_START_DELAY = 5 # The maximum download delay to be set in case of high latencies #AUTOTHROTTLE_MAX_DELAY = 60 # The average number of requests Scrapy should be sending in parallel to # each remote server #AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0 # Enable showing throttling stats for every response received: #AUTOTHROTTLE_DEBUG = False # Enable and configure HTTP caching (disabled by default) # See https://docs.scrapy.org/en/latest/topics/downloader-middleware.html#httpcache-middleware-settings #HTTPCACHE_ENABLED = True #HTTPCACHE_EXPIRATION_SECS = 0 #HTTPCACHE_DIR = 'httpcache' #HTTPCACHE_IGNORE_HTTP_CODES = [] #HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
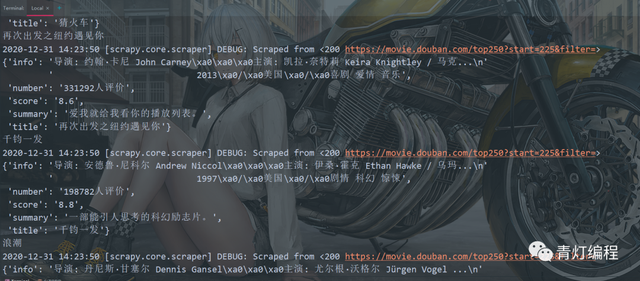
4,運行爬蟲程式

輸入命令 scrapy crawl +爬蟲檔案名
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/245976.html
標籤:其他
上一篇:xposed繞過ssl校驗新玩具