python爬蟲及資料可視化分析
- 1.前言
- 2.資料爬取
- 2.1定位到爬取資料
- 2.2爬蟲實作方法
- 3.資料可視化分析
- 3.1將短文學網的各類文章做一個統計
- 3.2對某一類文章進行分析
1.前言
本篇文章主要介紹python爬蟲及對爬取的資料進行可視化分析,本次介紹所用的網站是(https://www.duanwenxue.com/jingdian/zheli/)
2.資料爬取
2.1定位到爬取資料
打開我們要爬取的網頁,右鍵選擇檢查,在視窗中單擊左上角箭頭,即可查看我們需要爬取的內容:
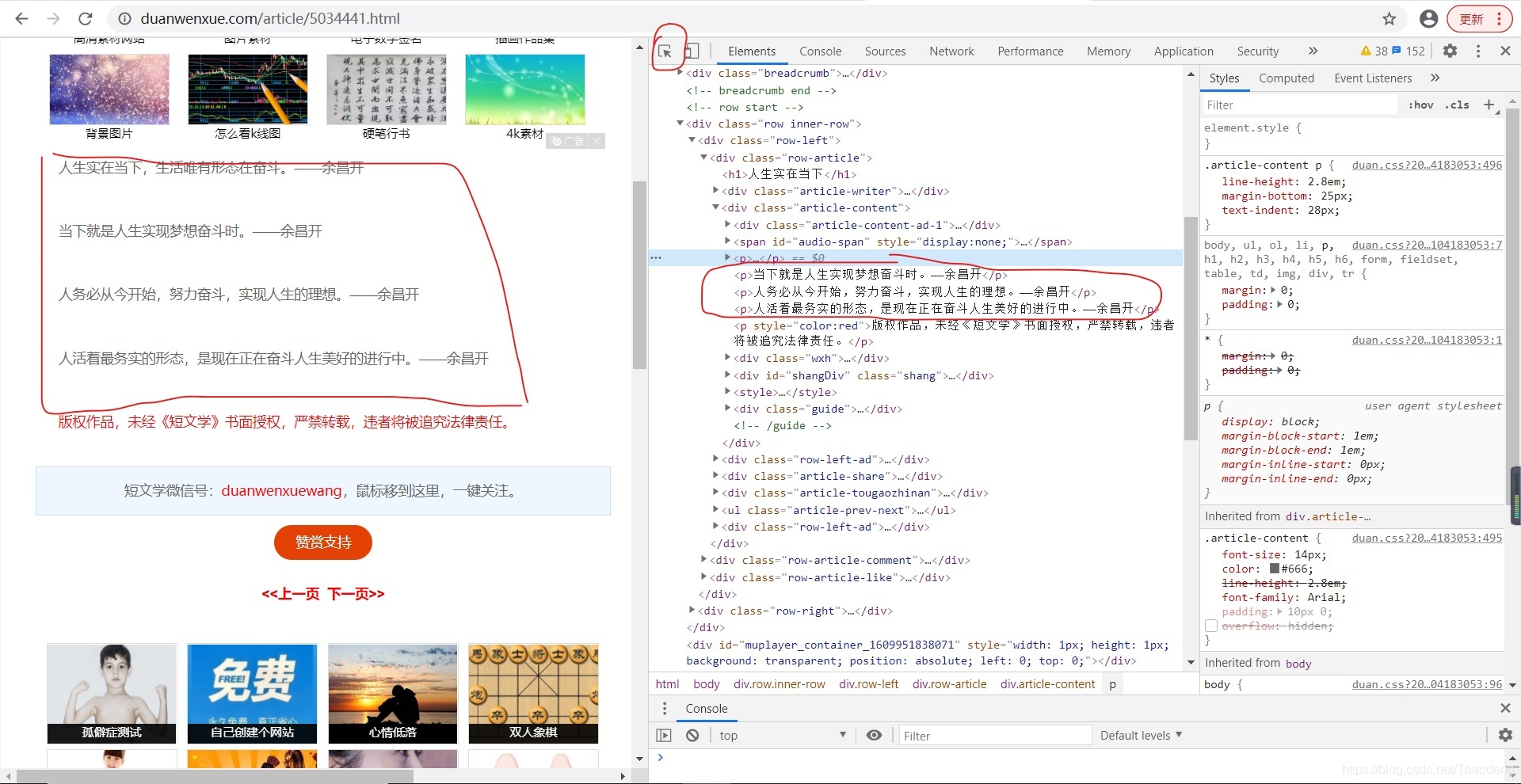
2.2爬蟲實作方法
我們要爬取一個網頁,首先我們需要向網頁發送一個請求,然后用get方法抓取資料(例如我要爬取https://www.duanwenxue.com/jingdian/zheli/的內容)
import requests
url = 'https://www.duanwenxue.com/article/5034441.html'
doc = requests.get(url)
print(doc.text)
通過這個方法獲得資料是整個網頁的原始碼,接下來我們,接下來要從原始碼中找到并提取資料,Beautiful Soup 是 python 的一個庫,其最主要的功能是從網頁中抓取資料,(例如我要獲得https://www.duanwenxue.com/article/5035160.html的散文)
import requests
from bs4 import BeautifulSoup
url='https://www.duanwenxue.com/article/5034441.html'
html=requests.get(url)
html.encoding='gbk'
doc=BeautifulSoup(html.text,'lxml')
a=doc.find('span',{'id':'audio-span'})
c=doc.find('div',{'id':'shangDiv'})
a.decompose() # 洗掉無用資訊
c.decompose()
cont=doc.find('div',{'class':'article-content'}).findAll('p')
content=''
for i in cont:
print(i.text)
輸出結果:
人生實在當下,生活唯有形態在奮斗,——余昌開
當下就是人生實作夢想奮斗時,——余昌開
人務必從今開始,努力奮斗,實作人生的理想,——余昌開
人活著最務實的形態,是現在正在奮斗人生美好的進行中,——余昌開
著作權作品,未經《短文學》書面授權,嚴禁轉載,違者將被追究法律責任,
3.資料可視化分析
資料可視化是資料分析很重要的一部分,將資料進行可視化,更直觀的呈現使資料更加客觀、更具說服力,
matplotlib是用來創建圖表的工具包之一,是一個Python 2D繪圖庫,它可以在各種平臺上以各種硬拷貝格式和互動式環境生成出具有出版品質的圖形,
3.1將短文學網的各類文章做一個統計
柱形圖:
plt.rcParams['font.sans-serif']=['SimHei']
plt.figure(figsize=(10,10))
plt.xticks(rotation=45)
plt.title("各類文章數目")# 標題
plt.xlabel("文章型別")#橫坐標名字
plt.ylabel("數量")#縱坐標名字
plt.bar(x, y)
for x,y in zip(x,y):
plt.text(x,y,"{f}".format(f=y),ha="center",va='bottom')
plt.show()
結果:
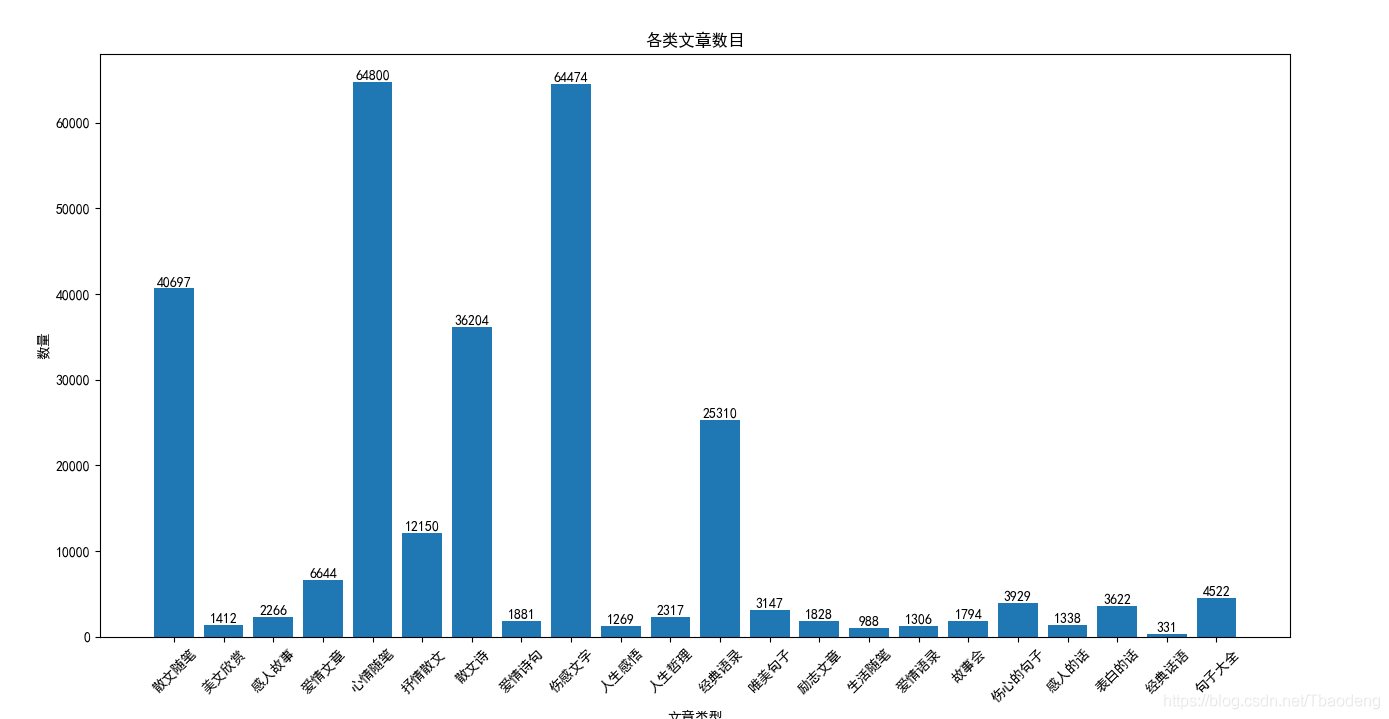
餅狀圖:
plt.figure(figsize=(30, 30)) #設定大小
plt.pie(y,labels = x, autopct='%1.1f%%')
plt.axis('equal')
plt.show()
結果:
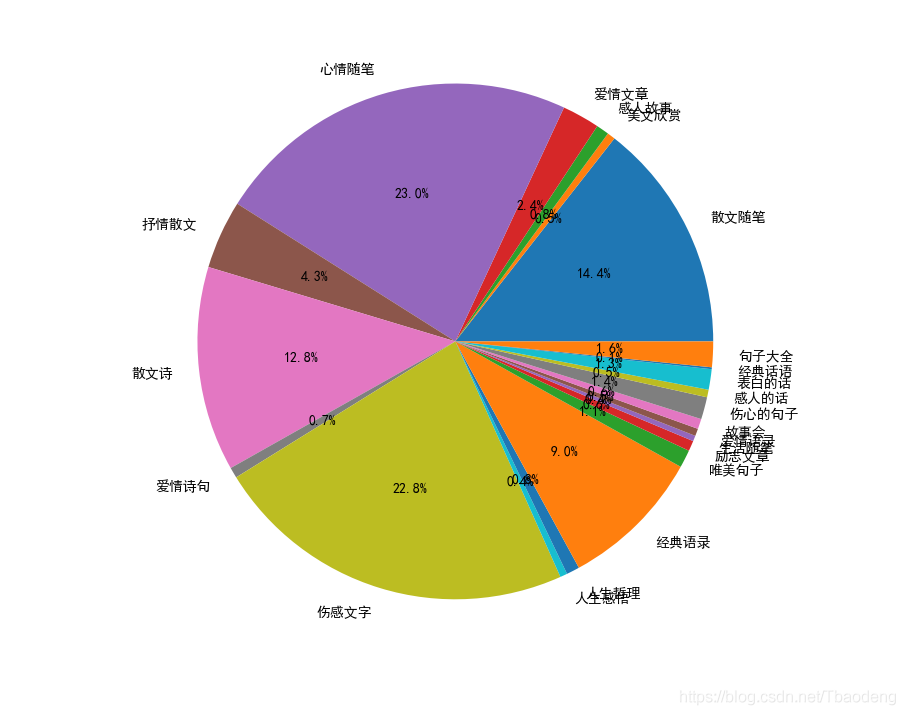
通過對柱形圖和餅狀圖的觀察,可以發現在短文學中,“散文隨筆”,“心情隨筆”,“散文詩”,“散文文字”,“經典語錄”類的文學作品占大部分(82%),而其他型別的作品占小部分(18%),
3.2對某一類文章進行分析
我們選擇對勵志文章的標題進行分析,通過標題的重點詞匯生成詞云,反映出這類文章的大致內容趨向于哪一方面,
代碼如下:
stopwords={'你','我','的','自己'}# 去掉無用的詞
word_cut=jieba.cut(word_content)
word_cut_join=" ".join(word_cut)#把分詞用空格連起來
#生成詞云
wc=WordCloud(
font_path='simsun.ttc',#設定字體
max_words=100,#詞云顯示的最大詞數
# mask=mask_img,#設定背景圖片
stopwords=stopwords,
background_color='white'#背景顏色
).generate(word_cut_join)
plt.imshow(wc)
plt.axis('off')#去掉坐標軸
plt.savefig('title.jpg')
plt.show()
結果:

可以看到,多次出現的大學有 “河南”,“科技”,“大學”,“農學院”,
以上便是本文全部內容,代碼只包含主要部分,關于資料可視化還有其他幾種方法,具體可查看python使用Matplotlib畫圖,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/246180.html
標籤:python
上一篇:疫情資料分析與可視化