本文的文字及圖片來源于網路,僅供學習、交流使用,不具有任何商業用途,如有問題請及時聯系我們以作處理,
以下文章來源于編碼珠璣 ,作者劉亞曦
Python爬蟲、資料分析、網站開發等案例教程視頻免費在線觀看
https://space.bilibili.com/523606542

想必大多數小伙伴們已經對百度搜索的廣告推薦機制深痛惡絕了,但凡哪怕涉及到一點點商業內容的搜索,出來的結果幾乎全是廣告,其實,除了谷歌搜索外,還有一個小眾的搜索引擎,效果也并不比百度差多少,關鍵是搜索結果幾乎沒有廣告,他就是微軟的親兒子,必應搜索,
每次打開必應搜索,我們都會看到一張精美的背景圖片,而且每天都更新,之前微軟還提供了每張圖片的下載地址,后來就直接取消了,但是如果我們能夠獲取這些背景圖片并把它們設為電腦壁紙,豈不是一件很有趣的事情呢,那么如何才能獲取到這些照片呢,今天我手把手教你寫個Python腳本來抓取必應搜索的背景圖片,
首先,我們安裝IDE,這里我選擇Python最流行的PyCharm,大家可以到官網上下載:
https://www.jetbrains.com/pycharm/download/#section=windows
安裝方法非常簡單,直接下一步就行,
安裝完成后,打開IDE,我們創建一個Python的專案
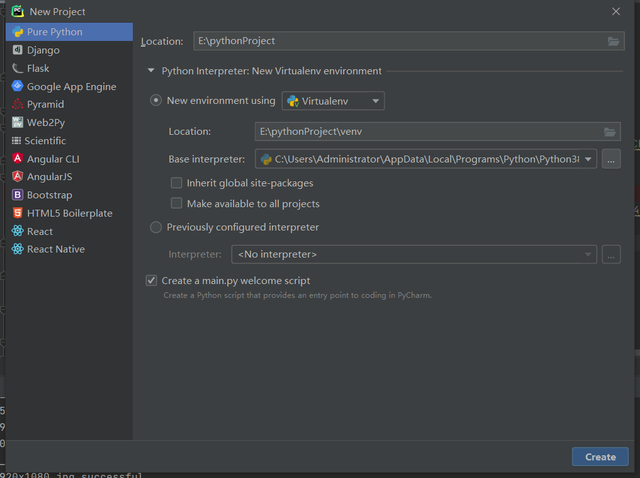
完成后,還要事先安裝幾個庫,方便我們后面寫代碼使用,分別是:
request
BeautifulSoup4
lxml
安裝方法很簡單,我們點擊編譯器左上角的File->Settings彈出對話框:
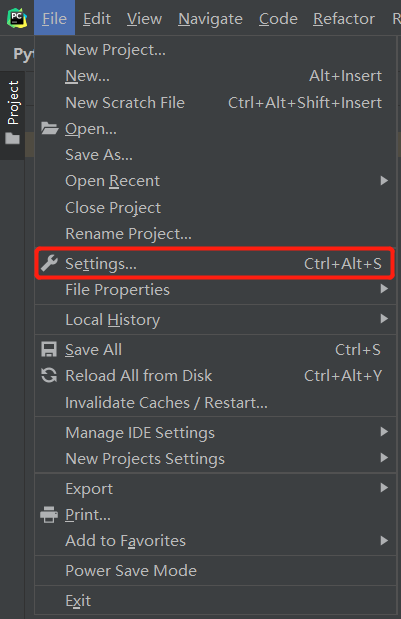
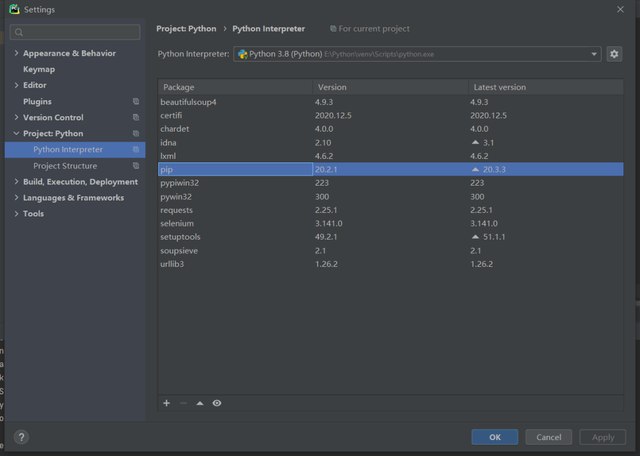
我們雙擊上圖中的pip,在彈出的對話框里面分別搜索上面羅列的三個庫名字,然后點擊左下角的InstallPackage即可完成安裝:
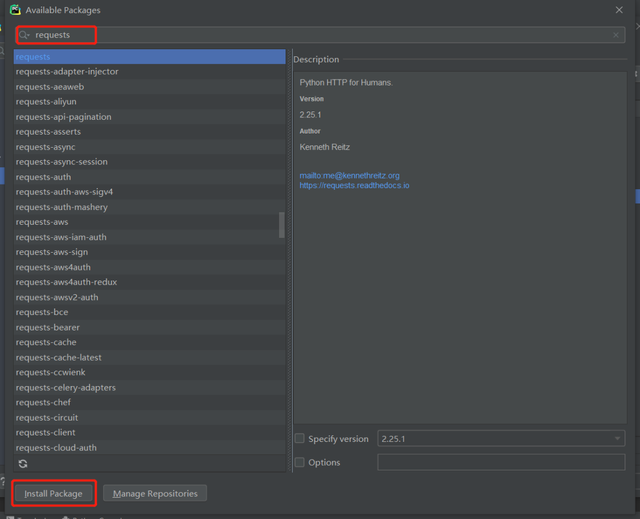
完成以后,我們開始寫代碼:
首先我們引入四個我們需要的包代碼:
if __name__=='__main__':
for i in range(8):
url = 'https://cn.bing.com/HPImageArchive.aspx?idx={}&n=1'.format(i)
html = get_page(url)
soup = BeautifulSoup(html, 'lxml')
text = soup.find(name='url').string
img_url = 'https://cn.bing.com' + text
img_name = re.match('^/th\?id=(.*?)&', text).group(1)
download(img_url, '填你自己想保存的檔案路徑c:/..', img_name)然后我們定義一個get_page的函式來獲取request請求得到的網頁內容,不過為了偽裝成瀏覽器訪問,我們這里要更改一下User-Agent欄位:
def get_page(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.109 Safari/537.36'
}
response = requests.get(url, headers=headers)
if response.status_code == 200: #回應狀態碼表示服務器對請求的回應結果,200代表服務器回應成功,403代表禁止訪問,404代表頁面未找到
return response.text再來定義一個下載圖片的函式download,傳入的引數包含圖片的url路徑,你自己定義的檔案夾路徑還有圖片的名稱:
def download(url, path, fname):
response = requests.get(url)
if response:
with open(os.path.join(path, fname), 'wb') as f:
f.write(response.content)
print('successful: {} .'.format(fname))
else:
print('faild: {}.'.format(fname))好了,上面兩個主要的函式定義好了以后,我們再定義main函式,來不斷呼叫他們,注意download函式的路徑要填寫你自己的檔案夾路徑,由于必應官方只保存了八張原圖,所以我們就簡單粗暴地只回圈8次即可,代碼如下:
if __name__=='__main__':
for i in range(8):
url = 'https://cn.bing.com/HPImageArchive.aspx?idx={}&n=1'.format(i)
html = get_page(url)
soup = BeautifulSoup(html, 'lxml')
text = soup.find(name='url').string
img_url = 'https://cn.bing.com' + text
img_name = re.match('^/th\?id=(.*?)&', text).group(1)
download(img_url, '填你自己想保存的檔案路徑c:/..', img_name)好了,上面就是完整的代碼內容,我們試著運行一次:
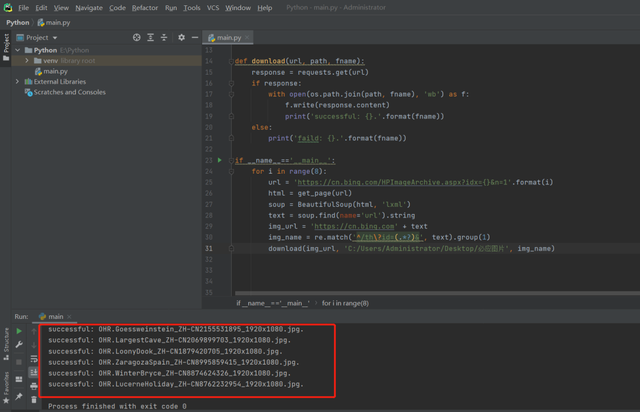
結果完全沒問題,看檔案夾里面的圖片也保存下來了:

隨便打開一張,都是非常精美的:

有沒有發現圖片非常的漂亮,隨便找一張設定成電腦桌面看一下效果吧:
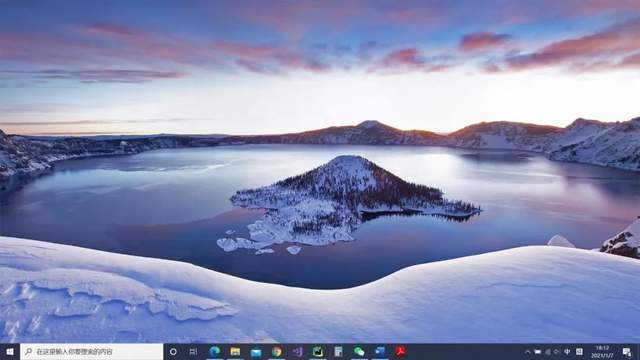
可以看到效果非常的精美,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/246419.html
標籤:其他