前言
本文的文字及圖片來源于網路,僅供學習、交流使用,不具有任何商業用途,如有問題請及時聯系我們以作處理,
以下文章來源于青燈教育 ,作者清風
Python爬蟲、資料分析、網站開發等案例教程視頻免費在線觀看
https://space.bilibili.com/523606542
基本開發環境
- Python 3.6
- Pycharm
相關模塊的使用
import os import re import requests
看標題是爬取P站的資料資源,是不是很興奮,是不是很刺激?

“啊?P站?哪個P站?”,
我不知道你們說的P站是哪個P站,主要面向二次元的P站,應該只有一個吧,

pixiv是一個以插圖、漫畫和小說、藝術為中心的社交網路服務里的虛擬社區網站,于2007年9月10日推出第一個測驗版,公司總部位于日本東京都澀谷區千馱谷,pixiv創辦初衷是為全球藝術家提供一個能發表他們的作品,并透過評級系統反應其他用戶意見的地方,網站以用戶投稿的原創圖畫為中心,輔以標簽、書簽、作品回應、排行榜等功能形成具有其特色的社交網路,
百度百科


這些圖片壁紙還是非常高清的,這個網站有一個非常有意思的地方:
你復制圖片地址,第一次可以訪問,點擊重繪第二次就會是403
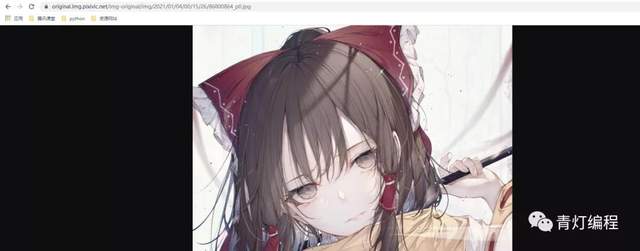

這些問題都不大,經過測驗,當你給了cookie 以及 Referer 就可以下載爬取,哪怕是第二次也是可以的,
如何獲取圖片地址
1、網站是瀑布流加載,打開開發者工具,下滑網頁就可以看到相關的資料介面了,
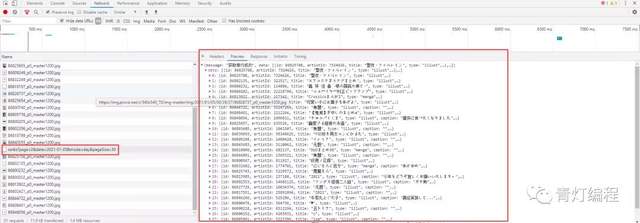
里面有圖片的名字以及圖片的ID 鏈接等等,

資料介面中獲取的圖片地址和真實的圖片地址還是有點差別的
比如:
# 資料介面中的圖片地址 # https://i.pximg.net/img-original/img/2021/01/03/02/51/59/86774115_p0.jpg # 圖片真實地址 # https://original.img.pixivic.net/img-original/img/2021/01/03/02/51/59/86774115_p0.jpg
所以提取url之后需要對其拼接,
完整代碼
import os import re import requests def get_response(html_url): headers = { 'cookie': '你自己的cookie', 'Referer': 'https://pixivic.com/', 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36' } response = requests.get(url=html_url, headers=headers) return response def save(img_url, title): path = 'img\\' if not os.path.exists(path): os.makedirs(path) img_data = get_response(img_url).content with open(path + title, mode='wb') as f: f.write(img_data) print(title) def main(html_url): html_data = get_response(html_url).text img_url = re.findall('"original":"(.*?)"', html_data) title = re.findall('"title":"(.*?)"', html_data) picture_data = zip(img_url, title) for i in picture_data: # 正則匹配的地址 # https://i.pximg.net/img-original/img/2021/01/03/02/51/59/86774115_p0.jpg # 圖片真實地址 # https://original.img.pixivic.net/img-original/img/2021/01/03/02/51/59/86774115_p0.jpg picture_1 = i[0].split('net/')[-1] # img-original/img/2021/01/03/02/51/59/86774115_p0.jpg picture_2 = i[0].split('/')[-1] # 86774115_p0.jpg picture_url = 'https://original.img.pixivic.net/' + picture_1 picture_title = i[1] + picture_2 save(picture_url, picture_title) if __name__ == '__main__': for page in range(1, 11): url = f'https://pix.ipv4.host/ranks?page={page}&date=2021-01-04&mode=day&pageSize=30' main(url)
最后說明
雖然可以爬取資料,但是爬取的速度相對而言有點慢了,因為有一些圖片資料比較大,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/246430.html
標籤:其他
上一篇:游戲編程:為什么C++游戲開發比Java更好,其實是因為這兩個點!
下一篇:PHP設計模式之訪問者模式