python的Tesseract-OCR-04-識別,使用jTessBoxEditor 提高數字驗證碼識別準確率
文章目錄
- 前言
- 一、訓練圖庫的生成
- 1.生成訓練圖庫
- 2.影像讀取以及二值化
- 3.形態學操作
- 4.保存影像以及批量生成
- 二、數字驗證碼識別
- 1.安裝訓練工具
- 2.獲取訓練圖庫
- 3.Merge樣本檔案
- 4.生成BOX檔案
- 5.字符組態檔
- 6.編輯字符
- 7.執行批處理檔案
- 7.移動num.traineddata檔案
- 三、識別數字驗證碼
- 四、總結
前言
第二次寫博文了,也可以說是自己的學習筆記,希望對你們也有幫助,有問題有錯誤,歡迎指正,我都會一一更正,謝謝各位,
文章可能會稍微比較長,我會分成三個部分來介紹:訓練圖庫的生成、訓練圖庫、數字驗證碼的識別,
一、訓練圖庫的生成
首先就是批量生成數字驗證碼這部分的操作以及代碼的實作我都在我的另一個文章中寫了,我就不過多贅述了,下面的鏈接就是了,
https://blog.csdn.net/weixin_46874767/article/details/111406957
1.生成訓練圖庫
因為有之前的代碼作為基礎,所以可以接著之前已經撰寫過的代碼直接生成批量的訓練影像,因為數字驗證碼都帶有噪點和噪線,所以需要進行形態學操作,將噪點和噪線去除掉,
代碼最好是結合之前自動生成數字驗證碼一起來看,我這里就不貼出完整的代碼,如果想要完整的代碼可以直接在評論區那里說一下,也可以直接找我,
代碼如下(示例):
# 讀取影像以及二值化
image = cv.imread(r'G:\image1\noise_verification code\%s.png' %name, cv.IMREAD_GRAYSCALE)
ret, binary = cv.threshold(image, 225, 255, cv.THRESH_BINARY_INV)
#形態學操作
kernel = cv.getStructuringElement(cv.MORPH_RECT, (2, 2))
bin1 = cv.morphologyEx(binary, cv.MORPH_OPEN, kernel)
# cv.imshow('image1', bin1)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (2, 2))
bin2 = cv.morphologyEx(bin1, cv.MORPH_CLOSE, kernel)
# cv.imshow('image2', bin2)
cv.waitKey(0)
cv.bitwise_not(bin2, bin2)
#保存影像
cv.imwrite(r'G:\image1\train2\%s.tif' % name, bin2)
#回圈生成訓練影像,想要多少張就回圈多少次,
for i in range(30):
generate_image()
2.影像讀取以及二值化
首先就是讀取影像,讀取之前已經生成好的帶有噪點噪線的數字驗證碼影像,這一步就不過多介紹了,
3.形態學操作
上面用到的形態學是開操作和閉操作,首先就是生成一個卷積核,
第一個引數是卷積核的形狀,這里選擇矩形就可以
第二個引數卷積核大小,因為我們這里的影像不是很大,而且噪聲噪點也不多所以就(2,2)或(3,3)大小的卷積核就夠了,我這里選了(2,2)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (2, 2))
然后就開閉操作,開閉操作可以理解成也是腐蝕膨脹的一種,但是他們的腐蝕膨脹的程度比直接腐蝕膨脹會稍微弱一點,先使用開操作將噪點噪線去除掉,然后再進行閉操作恢復數字的形狀,
bin1 = cv.morphologyEx(binary, cv.MORPH_OPEN, kernel)
# cv.imshow('image1', bin1)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (2, 2))
bin2 = cv.morphologyEx(bin1, cv.MORPH_CLOSE, kernel)
4.保存影像以及批量生成
cv.imwrite(r'G:\image1\train2\%s.tif' % name, bin2)
#回圈生成訓練影像,想要多少張就回圈多少次,
for i in range(30):
generate_image()
二、數字驗證碼識別
這一步的內容是文章的重點,步驟也會比較多,下面我會細講
.
1.安裝訓練工具
安裝 jTessBoxEditor:
官方網址:https://sourceforge.net/projects/vietocr/files/jTessBoxEditor/
在使用jTessBoxEditor之前需要安裝JRE,因為這是由JAVA開發的,
JRE下載官網:http://www.oracle.com/technetwork/java/javase/downloads/jre8-downloads-2133155.html
按照自己的電腦情況來進行下載,
jTessBoxEditor下載完之后不用進行安裝直接解壓就好了,
2.獲取訓練圖庫
就是第上面的第一章:獲取訓練圖庫,
3.Merge樣本檔案
在你解壓jTessBoxEditor的地址,找到一個train.bat雙擊打開,點擊Tools>>Merge TIFF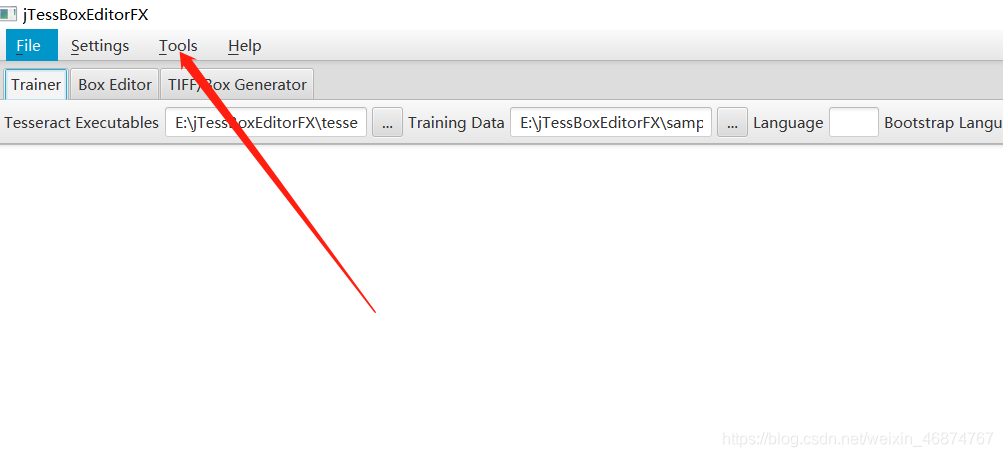
按住ctrl鍵,選擇你所有的樣本影像,然后點擊打開
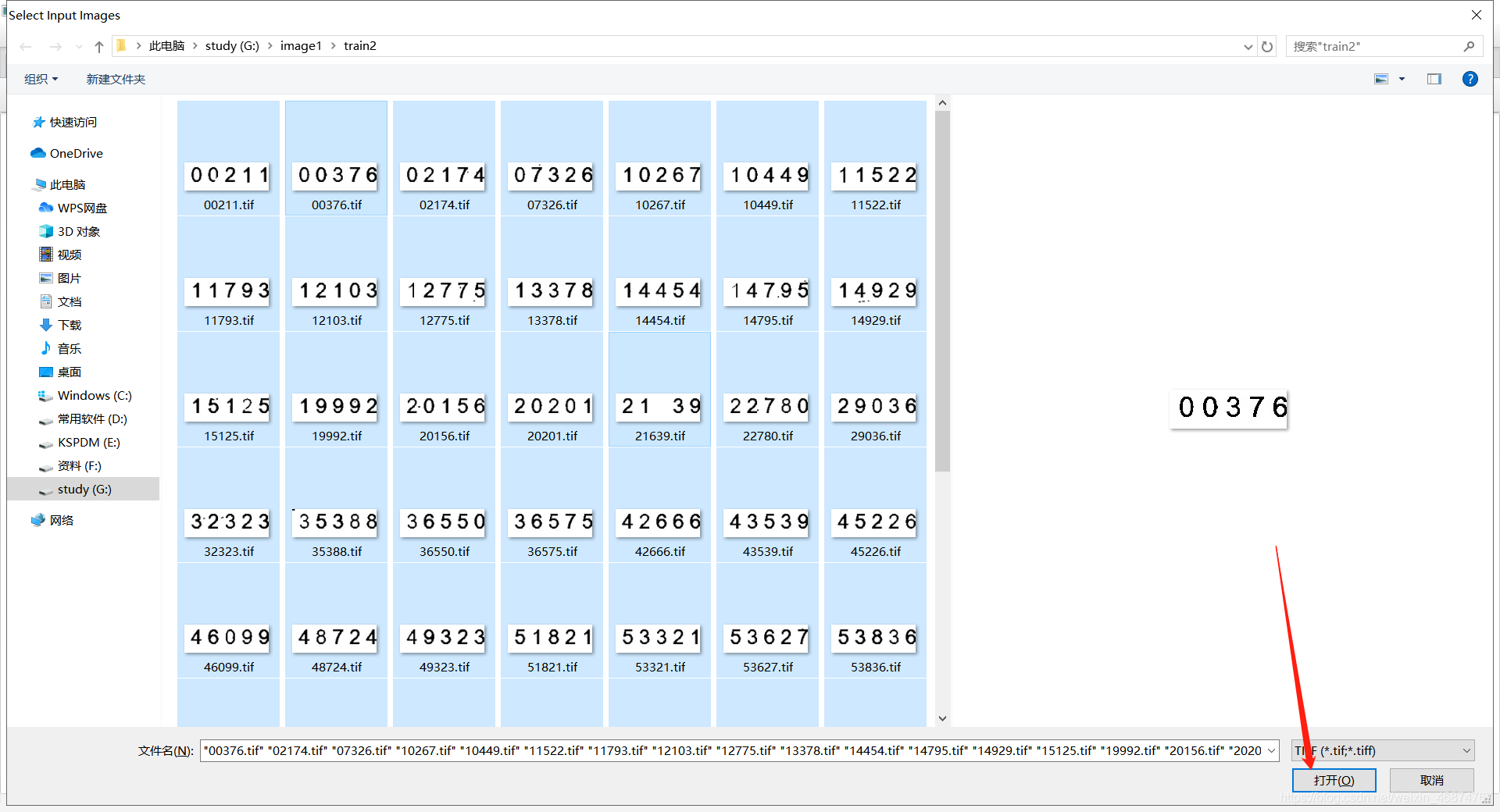
之后合并保存,為了方便 tif文面命名格式[lang].[fontname].exp[num].tif
lang為語言名稱,fontname為字體名稱,num為序號;在tesseract中,一定要注意格式
例如和可以命名成num.font.exp[0].tif
4.生成BOX檔案
打開cmd命令,切換到你影像保存的位置,
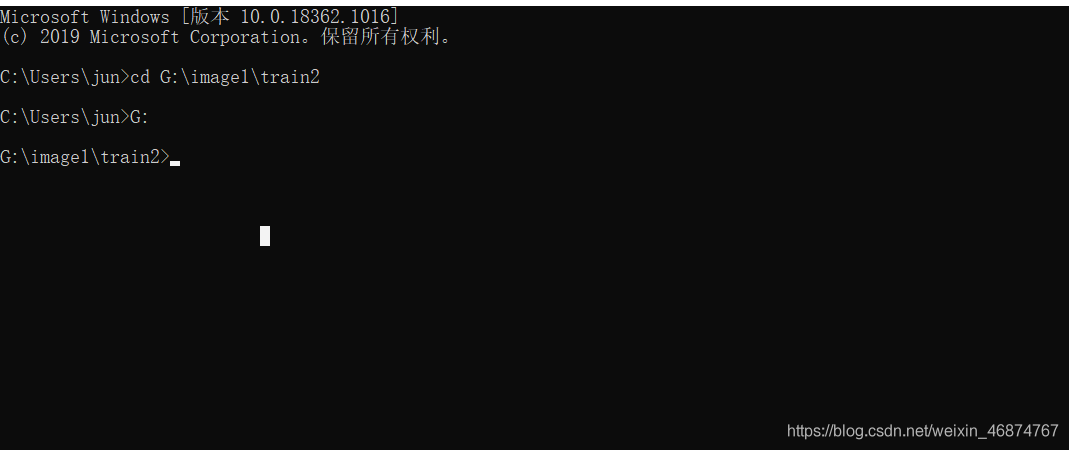
輸入下面的命令:
tesseract num.font.exp[0].tif num.font.exp[0] batch.nochop makebox
在訓練圖庫中就會生成一個box檔案

5.字符組態檔
在檔案夾內,新建一個文本檔案,名為font_properties,記住不要帶后綴,用記事本打開,寫入內容為:
font 0 0 0 0 0
【語法】:fontname italic bold fixed serif fraktur
【語法】:fontname為字體名稱,italic為斜體,bold為黑體字,
fixed為默認字體,serif為襯線字體,fraktur德文黑字體,
1和0代表有和無,精細區分時可使用
6.編輯字符
打開 jTessBoxEditor,依次點擊Box Editor、Open,選擇num.font.exp[0].tif檔案打開
將每一張訓練影像都進行校正,主要有兩個方向,一個就是char,還有一個就是字符框的大小,
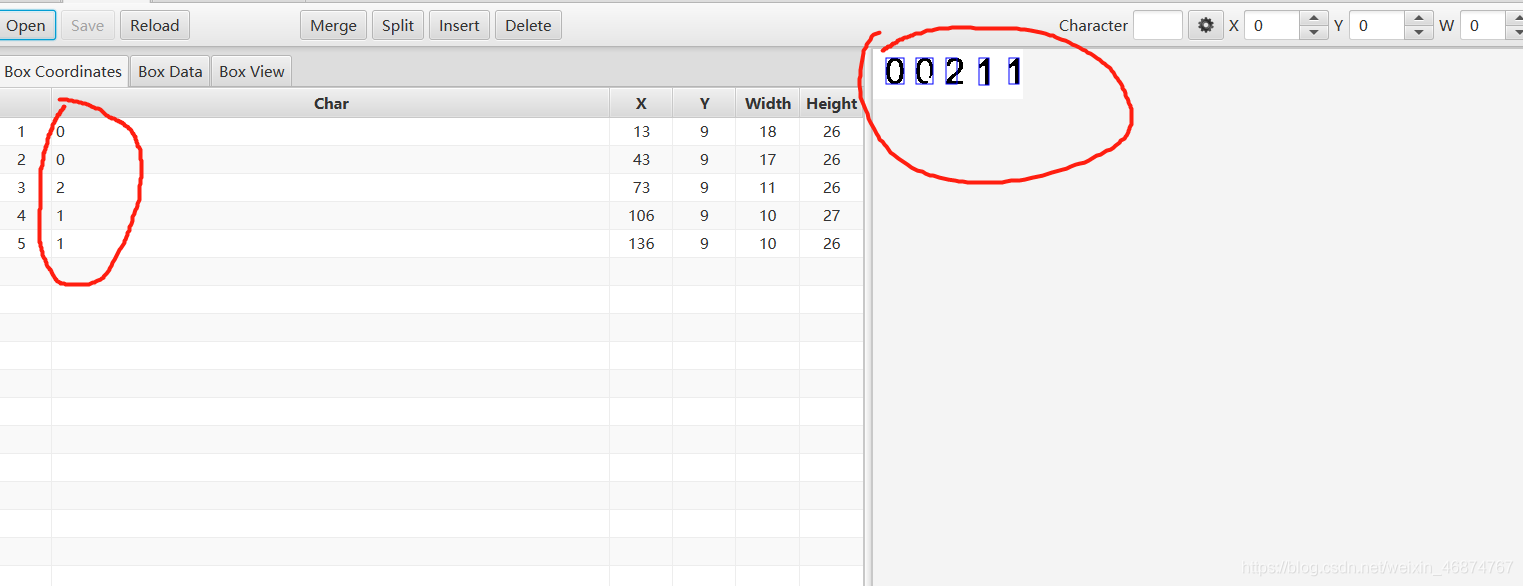
訓練完成之后記得保存
替換掉之前的box檔案,
7.執行批處理檔案
在目標目錄下,新建一個txt檔案,復制代碼,重命名為 do.bat,直接更改后綴名就可以
代碼如下
echo Run Tesseract for Training..
tesseract.exe num.font.exp[0].tif num.font.exp[0] nobatch box.train
echo Compute the Character Set..
unicharset_extractor.exe num.font.exp[0].box
mftraining -F font_properties -U unicharset -O num.unicharset num.font.exp[0].tr
echo Clustering..
cntraining.exe num.font.exp0.tr
echo Rename Files..
rename normproto num.normproto
rename inttemp num.inttemp
rename pffmtable num.pffmtable
rename shapetable num.shapetable
echo Create Tessdata..
combine_tessdata.exe num.
echo. & pause
執行完do.bat檔案之后,會生成很多檔案
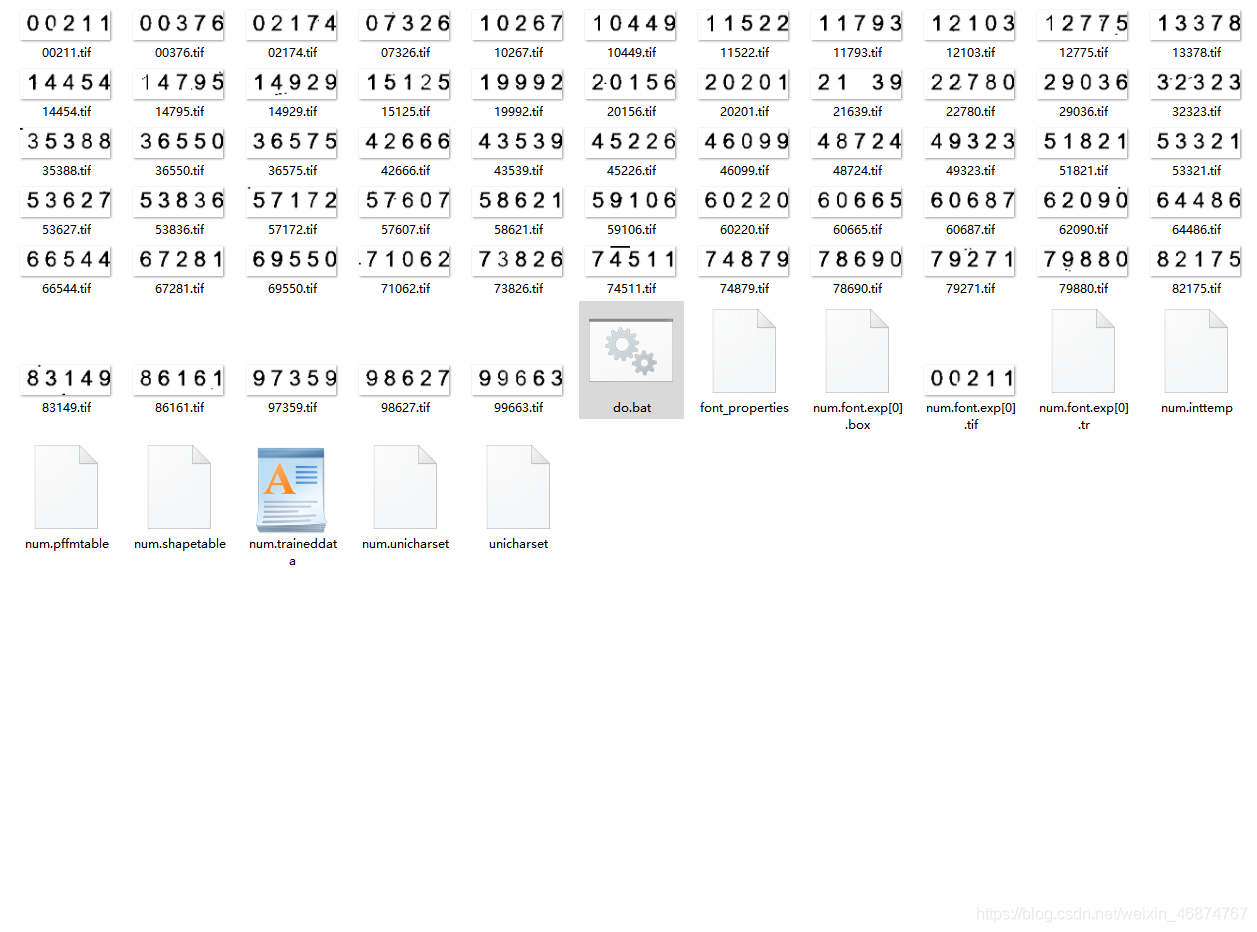
7.移動num.traineddata檔案
把num.traineddata檔案移動到Tesseract-OCR 安裝目錄下的 tessdata 檔案夾
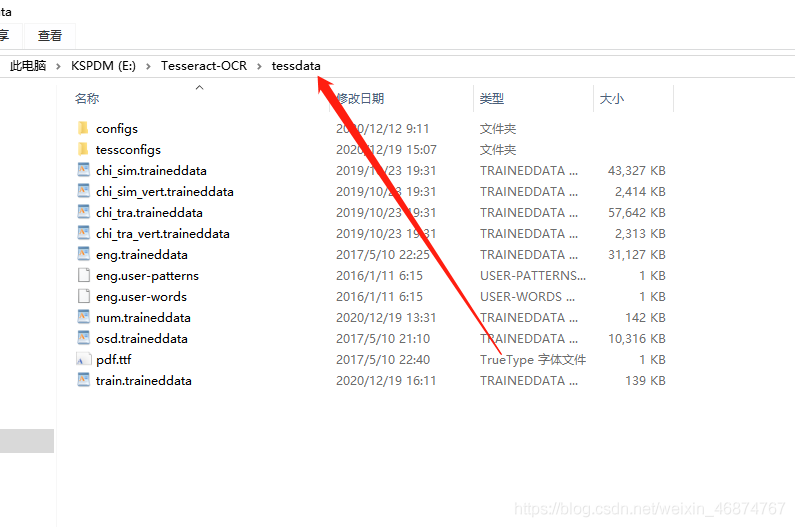
至此訓練的步驟以及完成了,距離勝利還差一步就是識別了,
三、識別數字驗證碼
直接給出代碼:
for path in paths:
image = cv.imread(path, cv.IMREAD_GRAYSCALE)
ret, binary = cv.threshold(image, 225, 255, cv.THRESH_BINARY_INV)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (2, 2))
bin1 = cv.morphologyEx(binary, cv.MORPH_OPEN, kernel)
# cv.imshow('image1', bin1)
kernel = cv.getStructuringElement(cv.MORPH_RECT, (2, 2))
bin2 = cv.morphologyEx(bin1, cv.MORPH_CLOSE, kernel)
# cv.imshow('image2', bin2)
cv.waitKey()
cv.bitwise_not(bin2, bin2)
textImage = Image.fromarray(bin2)
text = tess.image_to_string(textImage, lang='num')
number.append(text)
# 保存識別出來的數字
with open(r"G:\image1\noise_verification code\result.txt", 'w', encoding='UTF-8') as f:
for i in range(30):
f.write(number[i])
著重了解這句代碼:
第一個引數:就是你要識別的影像,一般是二值化影像,識別前景區域(即白色區域)
第二個引數:就是你要使用的語言,也就是你訓練之后得到的語言,在上述的2.7章節那里的檔案
text = tess.image_to_string(textImage, lang='train')
最后的效果圖如下:基本都可以識別出來,也不會有錯誤,(至于其中的橫線就使需要形態學的優化了),而且程式執行的時間也很快

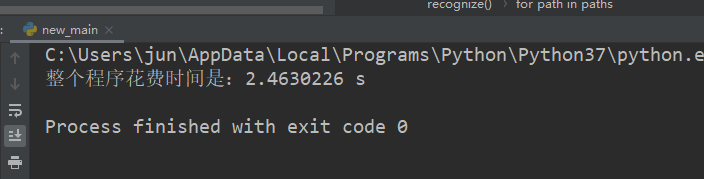
下面是不訓練,直接識別的效果:
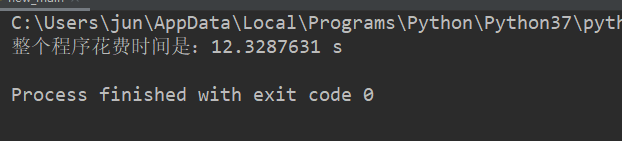
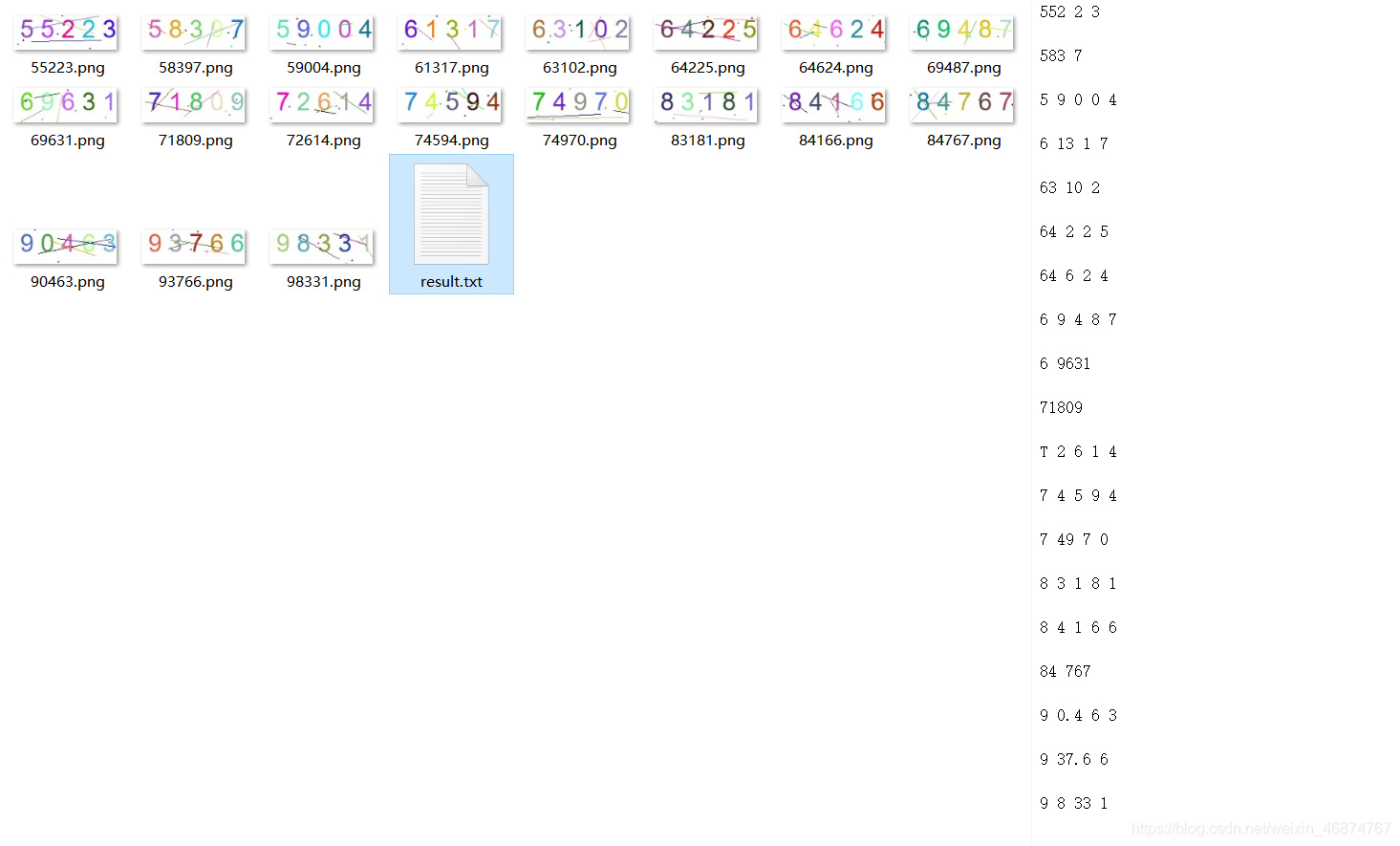
四、總結
對比過后,效果不言而喻,經過訓練之后識別的速度也有提升,準確率也很高,當然形態學部分的去噪點噪聲就是需要優化的部分了,
因為文章內容比較多,也是一次性寫完的,難免會有錯誤,或者紕漏之處,歡迎在評論區指出,我都會一一改正
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/246558.html
標籤:python