作者:huashiou
https://segmentfault.com/a/1190000018626163
本文以設計淘寶網的后臺架構為例,介紹從一百個并發到千萬級并發情況下服務端的架構的14次演程序序,同時列舉出每個演進階段會遇到的相關技術,讓大家對架構的演進有一個整體的認知,
文章最后匯總了一些架構設計的原則,
基本概念
在介紹架構之前,為了避免部分讀者對架構設計中的一些概念不了解,下面對幾個最基礎的概念進行介紹,
1)什么是分布式?
系統中的多個模塊在不同服務器上部署,即可稱為分布式系統,如Tomcat和資料庫分別部署在不同的服務器上,或兩個相同功能的Tomcat分別部署在不同服務器上,
2)什么是高可用?
系統中部分節點失效時,其他節點能夠接替它繼續提供服務,則可認為系統具有高可用性,
3)什么是集群?
一個特定領域的軟體部署在多臺服務器上并作為一個整體提供一類服務,這個整體稱為集群,
如Zookeeper中的Master和Slave分別部署在多臺服務器上,共同組成一個整體提供集中配置服務,
在常見的集群中,客戶端往往能夠連接任意一個節點獲得服務,并且當集群中一個節點掉線時,其他節點往往能夠自動的接替它繼續提供服務,這時候說明集群具有高可用性,
4)什么是負載均衡?
請求發送到系統時,通過某些方式把請求均勻分發到多個節點上,使系統中每個節點能夠均勻的處理請求負載,則可認為系統是負載均衡的,
5)什么是正向代理和反向代理?
系統內部要訪問外部網路時,統一通過一個代理服務器把請求轉發出去,在外部網路看來就是代理服務器發起的訪問,此時代理服務器實作的是正向代理;
當外部請求進入系統時,代理服務器把該請求轉發到系統中的某臺服務器上,對外部請求來說,與之互動的只有代理服務器,此時代理服務器實作的是反向代理,
簡單來說,正向代理是代理服務器代替系統內部來訪問外部網路的程序,反向代理是外部請求訪問系統時通過代理服務器轉發到內部服務器的程序,
純真年代:單機架構
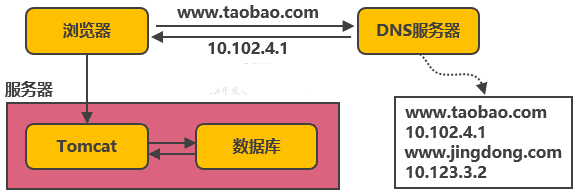
以淘寶作為例子:在網站最初時,應用數量與用戶數都較少,可以把Tomcat和資料庫部署在同一臺服務器上,瀏覽器往www.taobao.com發起請求時,首先經過DNS服務器(域名系統)把域名轉換為實際IP地址10.102.4.1,瀏覽器轉而訪問該IP對應的Tomcat,
架構瓶頸:隨著用戶數的增長,Tomcat和資料庫之間競爭資源,單機性能不足以支撐業務,
第一次演進:Tomcat與資料庫分開部署

Tomcat和資料庫分別獨占服務器資源,顯著提高兩者各自性能,
架構瓶頸:隨著用戶數的增長,并發讀寫資料庫成為瓶頸,
第二次演進:引入本地快取和分布式快取
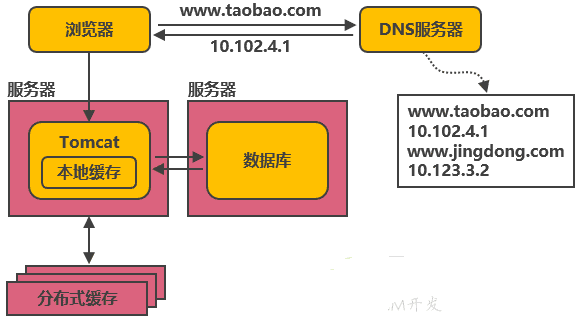
在Tomcat同服務器上或同JVM中增加本地快取,并在外部增加分布式快取,快取熱門商品資訊或熱門商品的html頁面等,通過快取能把絕大多數請求在讀寫資料庫前攔截掉,大大降低資料庫壓力,
其中涉及的技術包括:使用memcached作為本地快取,使用Redis作為分布式快取,還會涉及快取一致性、快取穿透/擊穿、快取雪崩、熱點資料集中失效等問題,
架構瓶頸:快取抗住了大部分的訪問請求,隨著用戶數的增長,并發壓力主要落在單機的Tomcat上,回應逐漸變慢,
第三次演進:引入反向代理實作負載均衡
=====================
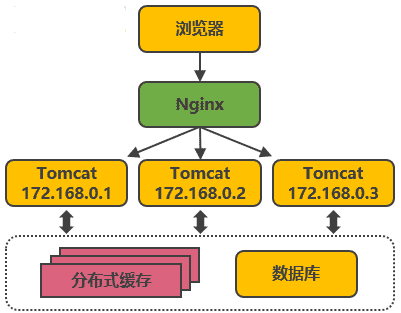
在多臺服務器上分別部署Tomcat,使用反向代理軟體(Nginx)把請求均勻分發到每個Tomcat中,此處假設Tomcat最多支持100個并發,Nginx最多支持50000個并發,那么理論上Nginx把請求分發到500個Tomcat上,就能抗住50000個并發,
其中涉及的技術包括:Nginx、HAProxy,兩者都是作業在網路第七層的反向代理軟體,主要支持http協議,還會涉及session共享、檔案上傳下載的問題,
架構瓶頸:反向代理使應用服務器可支持的并發量大大增加,但并發量的增長也意味著更多請求穿透到資料庫,單機的資料庫最終成為瓶頸,
第四次演進:資料庫讀寫分離
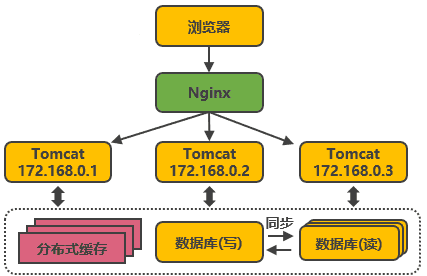
把資料庫劃分為讀庫和寫庫,讀庫可以有多個,通過同步機制把寫庫的資料同步到讀庫,對于需要查詢最新寫入資料場景,可通過在快取中多寫一份,通過快取獲得最新資料,
其中涉及的技術包括:Mycat,它是資料庫中間件,可通過它來組織資料庫的分離讀寫和分庫分表,客戶端通過它來訪問下層資料庫,還會涉及資料同步,資料一致性的問題,
架構瓶頸:業務逐漸變多,不同業務之間的訪問量差距較大,不同業務直接競爭資料庫,相互影響性能,
第五次演進:資料庫按業務分庫
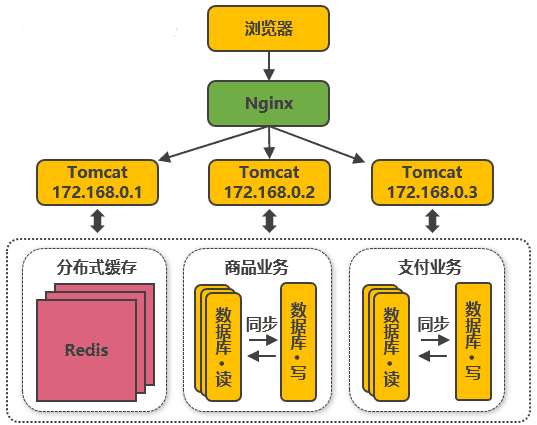
把不同業務的資料保存到不同的資料庫中,使業務之間的資源競爭降低,對于訪問量大的業務,可以部署更多的服務器來支撐,這樣同時導致跨業務的表無法直接做關聯分析,需要通過其他途徑來解決,但這不是本文討論的重點,有興趣的可以自行搜索解決方案,
架構瓶頸:隨著用戶數的增長,單機的寫庫會逐漸會達到性能瓶頸,
第六次演進:把大表拆分為小表
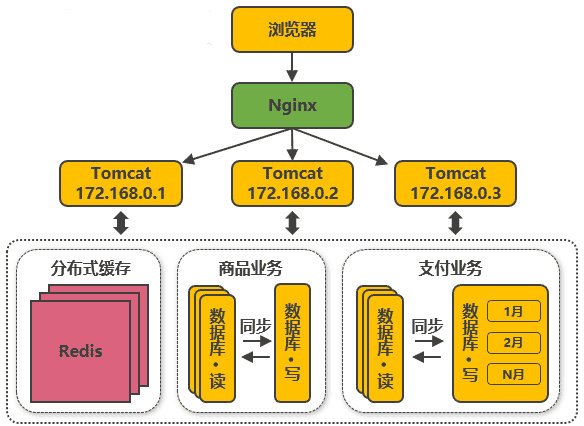
比如針對評論資料,可按照商品ID進行hash,路由到對應的表中存盤;針對支付記錄,可按照小時創建表,每個小時表繼續拆分為小表,使用用戶ID或記錄編號來路由資料,只要實時操作的表資料量足夠小,請求能夠足夠均勻的分發到多臺服務器上的小表,那資料庫就能通過水平擴展的方式來提高性能,其中前面提到的Mycat也支持在大表拆分為小表情況下的訪問控制,
這種做法顯著的增加了資料庫運維的難度,對DBA的要求較高,資料庫設計到這種結構時,已經可以稱為分布式資料庫,但是這只是一個邏輯的資料庫整體,資料庫里不同的組成部分是由不同的組件單獨來實作的,如分庫分表的管理和請求分發,由Mycat實作,SQL的決議由單機的資料庫實作,讀寫分離可能由網關和訊息佇列來實作,查詢結果的匯總可能由資料庫介面層來實作等等,這種架構其實是MPP(大規模并行處理)架構的一類實作,
目前開源和商用都已經有不少MPP資料庫,開源中比較流行的有Greenplum、TiDB、Postgresql XC、HAWQ等,商用的如南大通用的GBase、睿帆科技的雪球DB、華為的LibrA等等,不同的MPP資料庫的側重點也不一樣,如TiDB更側重于分布式OLTP場景,Greenplum更側重于分布式OLAP場景,這些MPP資料庫基本都提供了類似Postgresql、Oracle、MySQL那樣的SQL標準支持能力,能把一個查詢決議為分布式的執行計劃分發到每臺機器上并行執行,最終由資料庫本身匯總資料進行回傳,也提供了諸如權限管理、分庫分表、事務、資料副本等能力,并且大多能夠支持100個節點以上的集群,大大降低了資料庫運維的成本,并且使資料庫也能夠實作水平擴展,推薦:大廠在用的分庫分表方案,都在這了!
架構瓶頸:資料庫和Tomcat都能夠水平擴展,可支撐的并發大幅提高,隨著用戶數的增長,最終單機的Nginx會成為瓶頸,
第七次演進:使用LVS或F5來使多個Nginx負載均衡
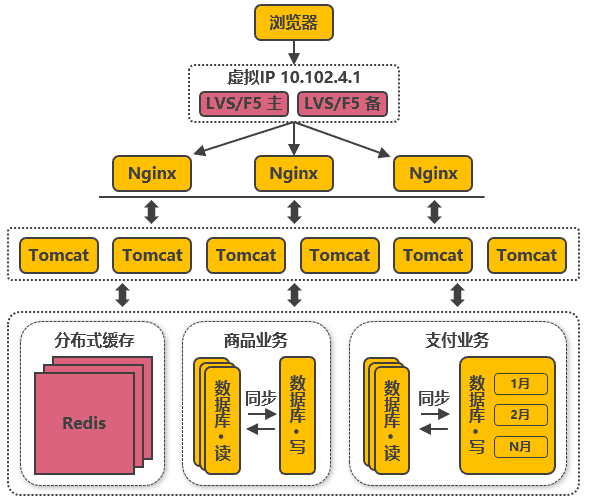
由于瓶頸在Nginx,因此無法通過兩層的Nginx來實作多個Nginx的負載均衡,圖中的LVS和F5是作業在網路第四層的負載均衡解決方案,其中LVS是軟體,運行在作業系統內核態,可對TCP請求或更高層級的網路協議進行轉發,因此支持的協議更豐富,并且性能也遠高于Nginx,可假設單機的LVS可支持幾十萬個并發的請求轉發;F5是一種負載均衡硬體,與LVS提供的能力類似,性能比LVS更高,但價格昂貴,由于LVS是單機版的軟體,若LVS所在服務器宕機則會導致整個后端系統都無法訪問,因此需要有備用節點,可使用keepalived軟體模擬出虛擬IP,然后把虛擬IP系結到多臺LVS服務器上,瀏覽器訪問虛擬IP時,會被路由器重定向到真實的LVS服務器,當主LVS服務器宕機時,keepalived軟體會自動更新路由器中的路由表,把虛擬IP重定向到另外一臺正常的LVS服務器,從而達到LVS服務器高可用的效果,
此處需要注意的是,上圖中從Nginx層到Tomcat層這樣畫并不代表全部Nginx都轉發請求到全部的Tomcat,在實際使用時,可能會是幾個Nginx下面接一部分的Tomcat,這些Nginx之間通過keepalived實作高可用,其他的Nginx接另外的Tomcat,這樣可接入的Tomcat數量就能成倍的增加,
架構瓶頸:由于LVS也是單機的,隨著并發數增長到幾十萬時,LVS服務器最侄訓達到瓶頸,此時用戶數達到千萬甚至上億級別,用戶分布在不同的地區,與服務器機房距離不同,導致了訪問的延遲會明顯不同,
第八次演進:通過DNS輪詢實作機房間的負載均衡
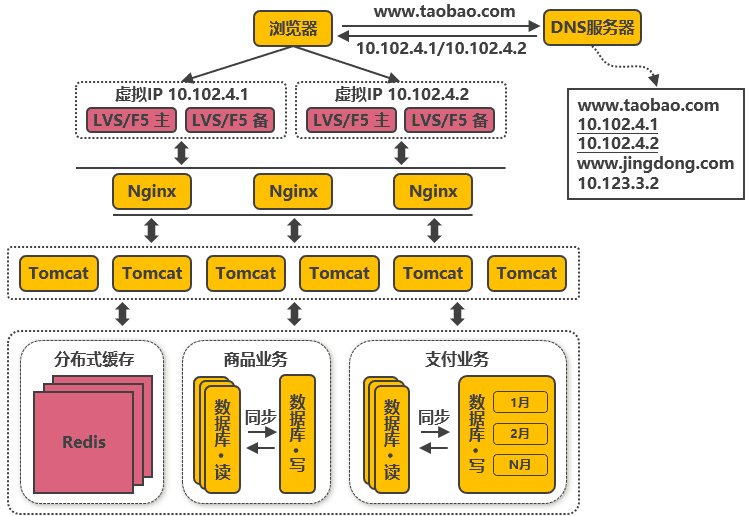
在DNS服務器中可配置一個域名對應多個IP地址,每個IP地址對應到不同的機房里的虛擬IP,當用戶訪問www.taobao.com時,DNS服務器會使用輪詢策略或其他策略,來選擇某個IP供用戶訪問,此方式能實作機房間的負載均衡,至此,系統可做到機房級別的水平擴展,千萬級到億級的并發量都可通過增加機房來解決,系統入口處的請求并發量不再是問題,
架構瓶頸:隨著資料的豐富程度和業務的發展,檢索、分析等需求越來越豐富,單單依靠資料庫無法解決如此豐富的需求,
第九次演進:引入NoSQL資料庫和搜索引擎等技術
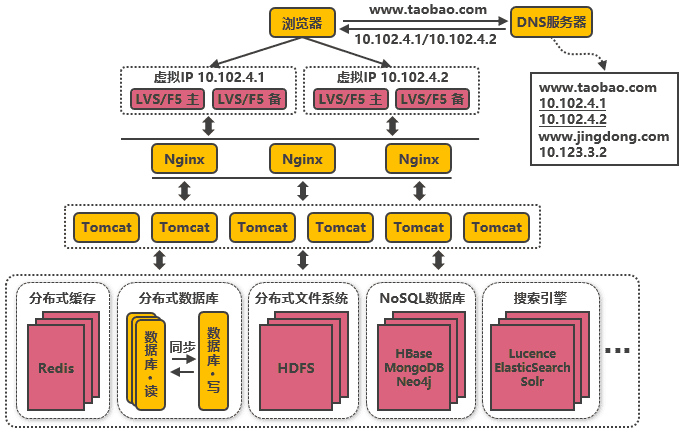
當資料庫中的資料多到一定規模時,資料庫就不適用于復雜的查詢了,往往只能滿足普通查詢的場景,對于統計報表場景,在資料量大時不一定能跑出結果,而且在跑復雜查詢時會導致其他查詢變慢,對于全文檢索、可變資料結構等場景,資料庫天生不適用,因此需要針對特定的場景,引入合適的解決方案,如對于海量檔案存盤,可通過分布式檔案系統HDFS解決,對于key value型別的資料,可通過HBase和Redis等方案解決,對于全文檢索場景,可通過搜索引擎如ElasticSearch解決,對于多維分析場景,可通過Kylin或Druid等方案解決,
當然,引入更多組件同時會提高系統的復雜度,不同的組件保存的資料需要同步,需要考慮一致性的問題,需要有更多的運維手段來管理這些組件等,
架構瓶頸:引入更多組件解決了豐富的需求,業務維度能夠極大擴充,隨之而來的是一個應用中包含了太多的業務代碼,業務的升級迭代變得困難,
第十次演進:大應用拆分為小應用

按照業務板塊來劃分應用代碼,使單個應用的職責更清晰,相互之間可以做到獨立升級迭代,這時候應用之間可能會涉及到一些公共配置,可以通過分布式配置中心Zookeeper來解決,
架構瓶頸:不同應用之間存在共用的模塊,由應用單獨管理會導致相同代碼存在多份,導致公共功能升級時全部應用代碼都要跟著升級,
第十一次演進:復用的功能抽離成微服務
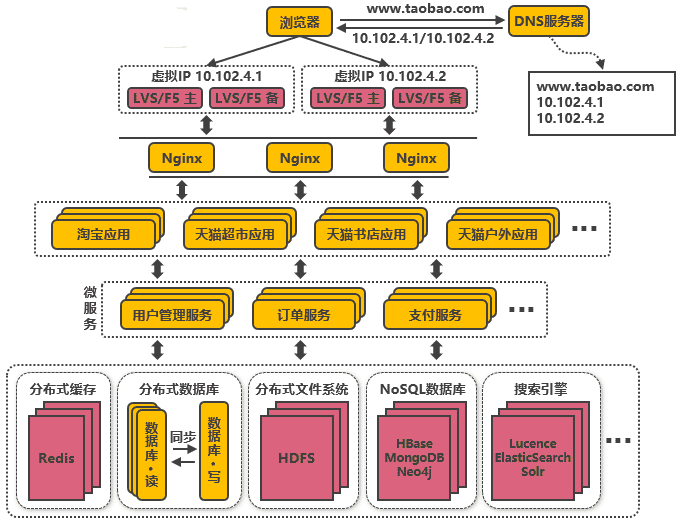
如用戶管理、訂單、支付、鑒權等功能在多個應用中都存在,那么可以把這些功能的代碼單獨抽取出來形成一個單獨的服務來管理,這樣的服務就是所謂的微服務,應用和服務之間通過HTTP、TCP或RPC請求等多種方式來訪問公共服務,每個單獨的服務都可以由單獨的團隊來管理,此外,可以通過Dubbo、SpringCloud等框架實作服務治理、限流、熔斷、降級等功能,提高服務的穩定性和可用性,微服務為什么選Spring Cloud?這篇看下吧!
架構瓶頸:不同服務的介面訪問方式不同,應用代碼需要適配多種訪問方式才能使用服務,此外,應用訪問服務,服務之間也可能相互訪問,呼叫鏈將會變得非常復雜,邏輯變得混亂,
第十二次演進:引入企業服務總線ESB屏蔽服務介面的訪問差異

通過ESB統一進行訪問協議轉換,應用統一通過ESB來訪問后端服務,服務與服務之間也通過ESB來相互呼叫,以此降低系統的耦合程度,
這種單個應用拆分為多個應用,公共服務單獨抽取出來來管理,并使用企業訊息總線來解除服務之間耦合問題的架構,就是所謂的SOA(面向服務)架構,這種架構與微服務架構容易混淆,因為表現形式十分相似,
個人理解,微服務架構更多是指把系統里的公共服務抽取出來單獨運維管理的思想,而SOA架構則是指一種拆分服務并使服務介面訪問變得統一的架構思想,SOA架構中包含了微服務的思想,
架構瓶頸:業務不斷發展,應用和服務都會不斷變多,應用和服務的部署變得復雜,同一臺服務器上部署多個服務還要解決運行環境沖突的問題,此外,對于如大促這類需要動態擴縮容的場景,需要水平擴展服務的性能,就需要在新增的服務上準備運行環境,部署服務等,運維將變得十分困難,
第十三次演進:引入容器化技術實作運行環境隔離與動態服務管理

目前最流行的容器化技術是Docker,最流行的容器管理服務是Kubernetes(K8S),應用/服務可以打包為Docker鏡像,通過K8S來動態分發和部署鏡像,Docker鏡像可理解為一個能運行你的應用/服務的最小的作業系統,里面放著應用/服務的運行代碼,運行環境根據實際的需要設定好,把整個“作業系統”打包為一個鏡像后,就可以分發到需要部署相關服務的機器上,直接啟動Docker鏡像就可以把服務起起來,使服務的部署和運維變得簡單,
在大促的之前,可以在現有的機器集群上劃分出服務器來啟動Docker鏡像,增強服務的性能,大促過后就可以關閉鏡像,對機器上的其他服務不造成影響(在第18節之前,服務運行在新增機器上需要修改系統配置來適配服務,這會導致機器上其他服務需要的運行環境被破壞),
架構瓶頸:使用容器化技術后服務動態擴縮容問題得以解決,但是機器還是需要公司自身來管理,在非大促的時候,還是需要閑置著大量的機器資源來應對大促,機器自身成本和運維成本都極高,資源利用率低,
第十四次演進:以云平臺承載系統

系統可部署到公有云上,利用公有云的海量機器資源,解決動態硬體資源的問題,在大促的時間段里,在云平臺中臨時申請更多的資源,結合Docker和K8S來快速部署服務,在大促結束后釋放資源,真正做到按需付費,資源利用率大大提高,同時大大降低了運維成本,
所謂的云平臺,就是把海量機器資源,通過統一的資源管理,抽象為一個資源整體,在之上可按需動態申請硬體資源(如CPU、記憶體、網路等),并且之上提供通用的作業系統,提供常用的技術組件(如Hadoop技術堆疊,MPP資料庫等)供用戶使用,甚至提供開發好的應用,用戶不需要關系應用內部使用了什么技術,就能夠解決需求(如音視頻轉碼服務、郵件服務、個人博客等),
在云平臺中會涉及如下幾個概念:SaaS,PaaS,IaaS都是什么鬼?這篇看下吧,
1)IaaS:基礎設施即服務,對應于上面所說的機器資源統一為資源整體,可動態申請硬體資源的層面;
2)PaaS:平臺即服務,對應于上面所說的提供常用的技術組件方便系統的開發和維護;
3)SaaS:軟體即服務,對應于上面所說的提供開發好的應用或服務,按功能或性能要求付費,
至此:以上所提到的從高并發訪問問題,到服務的架構和系統實施的層面都有了各自的解決方案,但同時也應該意識到,在上面的介紹中,其實是有意忽略了諸如跨機房資料同步、分布式事務實作等等的實際問題,這些問題以后有機會再拿出來單獨討論,
架構設計經驗小結
1)架構的調整是否必須按照上述演變路徑進行?
不是的,以上所說的架構演變順序只是針對某個側面進行單獨的改進,在實際場景中,可能同一時間會有幾個問題需要解決,或者可能先達到瓶頸的是另外的方面,這時候就應該按照實際問題實際解決,如在政府類的并發量可能不大,但業務可能很豐富的場景,高并發就不是重點解決的問題,此時優先需要的可能會是豐富需求的解決方案,
2)對于將要實施的系統,架構應該設計到什么程度?
對于單次實施并且性能指標明確的系統,架構設計到能夠支持系統的性能指標要求就足夠了,但要留有擴展架構的介面以便不備之需,對于不斷發展的系統,如電商平臺,應設計到能滿足下一階段用戶量和性能指標要求的程度,并根據業務的增長不斷的迭代升級架構,以支持更高的并發和更豐富的業務,
3)服務端架構和大資料架構有什么區別?
所謂的“大資料”其實是海量資料采集清洗轉換、資料存盤、資料分析、資料服務等場景解決方案的一個統稱,在每一個場景都包含了多種可選的技術,如資料采集有Flume、Sqoop、Kettle等,資料存盤有分布式檔案系統HDFS、FastDFS,NoSQL資料庫HBase、MongoDB等,資料分析有Spark技術堆疊、機器學習演算法等,
總的來說大資料架構就是根據業務的需求,整合各種大資料組件組合而成的架構,一般會提供分布式存盤、分布式計算、多維分析、資料倉庫、機器學習演算法等能力,而服務端架構更多指的是應用組織層面的架構,底層能力往往是由大資料架構來提供,
4)有沒有一些架構設計的原則?
a. N+1設計:系統中的每個組件都應做到沒有單點故障;
b. 回滾設計:確保系統可以向前兼容,在系統升級時應能有辦法回滾版本;
c. 禁用設計:應該提供控制具體功能是否可用的配置,在系統出現故障時能夠快速下線功能;
d. 監控設計:在設計階段就要考慮監控的手段;
e. 多活資料中心設計:若系統需要極高的高可用,應考慮在多地實施資料中心進行多活,至少在一個機房斷電的情況下系統依然可用;
f. 采用成熟的技術:剛開發的或開源的技術往往存在很多隱藏的bug,出了問題沒有商業支持可能會是一個災難;
g. 資源隔離設計:應避免單一業務占用全部資源;
h. 架構應能水平擴展:系統只有做到能水平擴展,才能有效避免瓶頸問題;
i. 非核心則購買:非核心功能若需要占用大量的研發資源才能解決,則考慮購買成熟的產品;
j. 使用商用硬體:商用硬體能有效降低硬體故障的機率;
k. 快速迭代:系統應該快速開發小功能模塊,盡快上線進行驗證,早日發現問題大大降低系統交付的風險;
l. 無狀態設計:服務介面應該做成無狀態的,當前介面的訪問不依賴于介面上次訪問的狀態,
近期熱文推薦:
1.Java 15 正式發布, 14 個新特性,重繪你的認知!!
2.終于靠開源專案弄到 IntelliJ IDEA 激活碼了,真香!
3.我用 Java 8 寫了一段邏輯,同事直呼看不懂,你試試看,,
4.吊打 Tomcat ,Undertow 性能很炸!!
5.《Java開發手冊(嵩山版)》最新發布,速速下載!
覺得不錯,別忘了隨手點贊+轉發哦!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/246718.html
標籤:Java
上一篇:Go語言開篇
下一篇:IO操作