小編在去年的時候,寫過一篇轟動全網的文章《你需要的不是實時數倉 | 你需要的是一款強大的OLAP資料庫》,這篇文章當時被各大門戶網站和自媒體瘋狂轉載,保守閱讀量也在50萬+UV,在這篇文章中提到過Preto,Presto作為OLAP計算領域的一員有著獨特的優勢和特點,
本篇文章是作者作為Presto小白時期,經過調研、線上除錯、生產環境穩定運行這個程序中大量的實踐經驗和資料檢索,沉淀下來的一個讀書筆記,本文從原理入門、線上調優、典型應用等幾個方面為讀者全面剖析Presto,希望對大家有幫助,
我是誰?我從哪里來?要到哪里去?
Presto is an open source distributed SQL query engine for running interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes.
Presto allows querying data where it lives, including Hive, Cassandra, relational databases or even proprietary data stores. A single Presto query can combine data from multiple sources, allowing for analytics across your entire organization.
Presto is targeted at analysts who expect response times ranging from sub-second to minutes. Presto breaks the false choice between having fast analytics using an expensive commercial solution or using a slow "free" solution that requires excessive hardware.
這是官網對Presto的定義,Presto 是由 Facebook 開源的大資料分布式 SQL 查詢引擎,適用于互動式分析查詢,可支持眾多的資料源,包括 HDFS,RDBMS,KAFKA 等,而且提供了非常友好的介面開發資料源連接器,
Presto之所以能在各個記憶體計算型資料庫中脫穎而出,在于以下幾點:
- 清晰的架構,是一個能夠獨立運行的系統,不依賴于任何其他外部系統,例如調度,presto自身提供了對集群的監控,可以根據監控資訊完成調度,
- 簡單的資料結構,列式存盤,邏輯行,大部分資料都可以輕易的轉化成presto所需要的這種資料結構,
- 豐富的插件介面,完美對接外部存盤系統,或者添加自定義的函式,
為了給大家一個更為清晰一點的印象,我們可以把Presto和Mysql進行一下對比:
首先Mysql是一個資料庫,具有存盤和計算分析能力,而Presto只有計算分析能力;其次資料量方面,Mysql作為傳統單點關系型資料庫不能滿足當前大資料量的需求,于是有各種大資料的存盤和分析工具產生,Presto就是這樣一個可以滿足大資料量分析計算需求的一個工具,
一覽無余之Presto的架構
我們借用美團的博客中的一張架構圖:
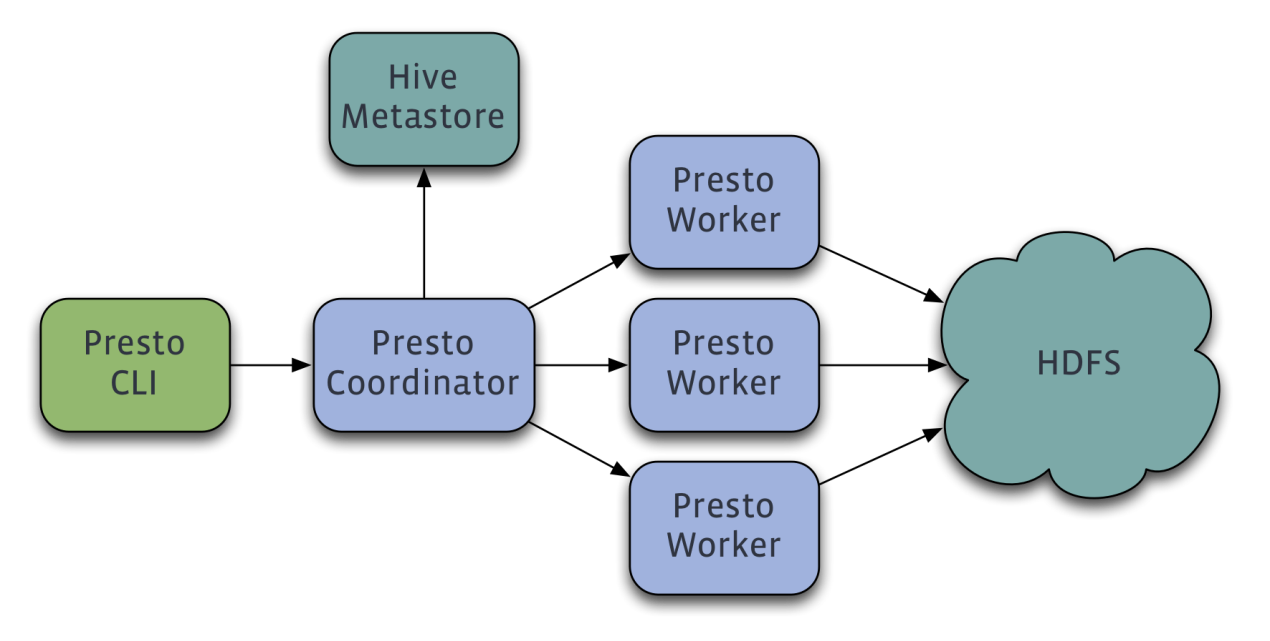
Presto查詢引擎是一個Master-Slave的架構,由一個Coordinator節點,一個Discovery Server節點,多個Worker節點組成,Discovery Server通常內嵌于Coordinator節點中,Coordinator負責決議SQL陳述句,生成執行計劃,分發執行任務給Worker節點執行,Worker節點負責實際執行查詢任務,Worker節點啟動后向Discovery Server服務注冊,Coordinator從Discovery Server獲得可以正常作業的Worker節點,如果配置了Hive Connector,需要配置一個Hive MetaStore服務為Presto提供Hive元資訊,Worker節點與HDFS互動讀取資料,
Presto的服務行程
Presto集群中有兩種行程,Coordinator服務行程和worker服務行程,coordinator主要作用是接收查詢請求,決議查詢陳述句,生成查詢執行計劃,任務調度和worker管理,worker服務行程執行被分解的查詢執行任務task,
Coordinator 服務行程部署在集群中的單獨節點之中,是整個presto集群的管理節點,主要作用是接收查詢請求,決議查詢陳述句,生成查詢執行計劃Stage和Task并對生成的Task進行任務調度,和worker管理,Coordinator行程是整個Presto集群的master行程,需要與worker進行通信,獲取最新的worker資訊,有需要和client通信,接收查詢請求,Coordinator提供REST服務來完成這些作業,
Presto集群中存在一個Coordinator和多個Worker節點,每個Worker節點上都會存在一個worker服務行程,主要進行資料的處理以及Task的執行,worker服務行程每隔一定的時間會發送心跳包給Coordinator,Coordinator接收到查詢請求后會從當前存活的worker中選擇合適的節點運行task,
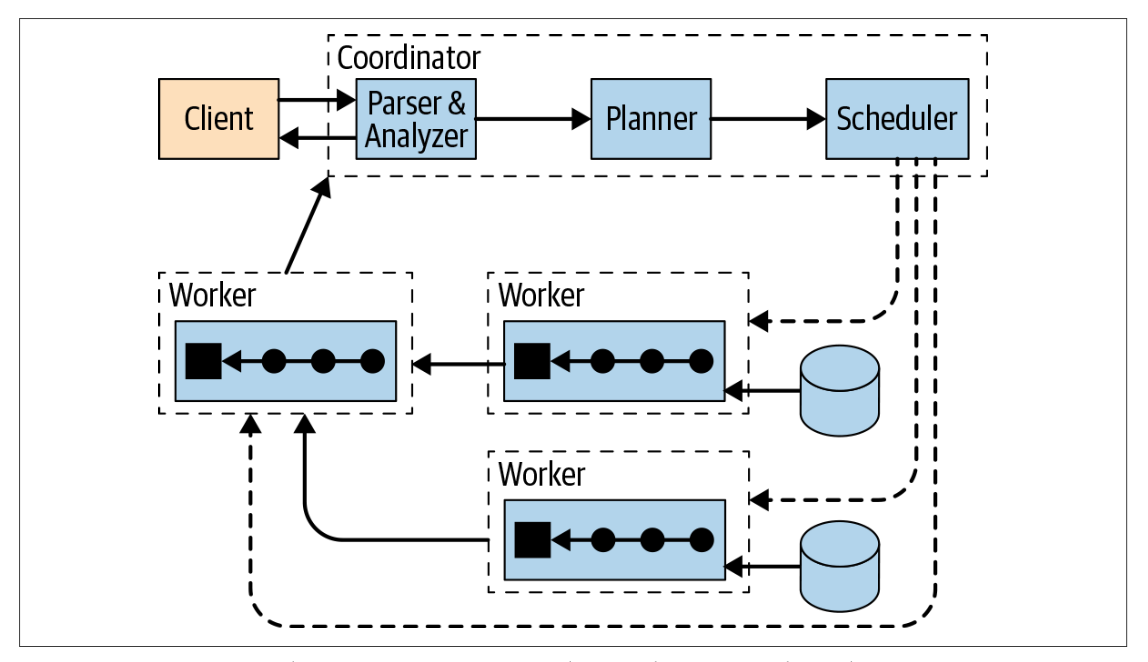
上圖展示了從宏觀層面概括了Presto的集群組件:1個coordinator,多個worker節點,用戶通過客戶端連接到coordinator,可以短可以是JDBC驅動或者Presto命令列cli,
Presto是一個分布式的SQL查詢引擎,組裝了多個并行計算的資料庫和查詢引擎(這就是MPP模型的定義),Presto不是依賴單機環境的垂直擴展性,她有能力在水平方向,把所有的處理分布到集群內的各個機器上,這意味著你可以通過添加更多節點來獲得更大的處理能力,
利用這種架構,Presto查詢引擎能夠并行的在集群的各個機器上,處理大規模資料的SQL查詢,Presto在每個節點上都是單行程的服務,多個節點都運行Presto,相互之間通過配置相互協作,組成了一個完整的Presto集群,
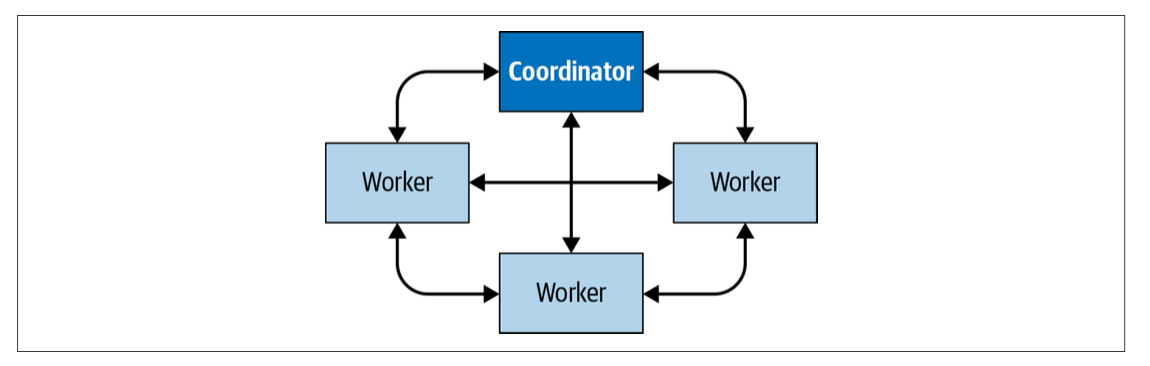
上圖展示了集群內coordinator和worker之間,以及worker和worker之間的通信,coordinator向多個worker通信,用于分配任務,更新狀態,獲得最終的結果回傳用戶,worker之間相互通信,向任務的上游節點獲取資料,所有的worker都會向資料源讀取資料,
Coordinator
Coordinator的作用是:
- 從用戶獲得SQL陳述句
- 決議SQL陳述句
- 規劃查詢的執行計劃
- 管理worker節點狀態
Coordinator是Presto集群的大腦,并且是負責和客戶端溝通,用戶通過PrestoCLI、JDBC、ODBC驅動、其他語言工具庫等工具和coordinator進行互動,Coordinator從客戶端接受SQL陳述句,例如select陳述句,才能進行計算,
每個Presto集群必須有一個coordinator,可以有一個或多個worker,在開發和測驗環境中,一個Presto行程可以同時配置成兩種角色,Coordinator追蹤每個worker上的活動,并且協調查詢的執行程序,Coordinator給查詢創建了一個包含多階段的邏輯模型,一旦接受了SQL陳述句,Coordinator就負責決議、分析、規劃、調度查詢在多個worker節點上的執行程序,陳述句被翻譯成一系列的任務,跑在多個worker節點上,worker一邊處理資料,結果會被coordinator拿走并且放到output快取區上,暴露給客戶端,一旦輸出緩沖區被客戶完全讀取,coordinator會代表客戶端向worker讀取更多資料,worker節點,和資料源打交道,從資料源獲取資料,因此,客戶端源源不斷的讀取資料,資料源源源不斷的提供資料,直到查詢執行結束,
Coordinator通過基于HTTP的協議和worker、客戶端之間進行通信,
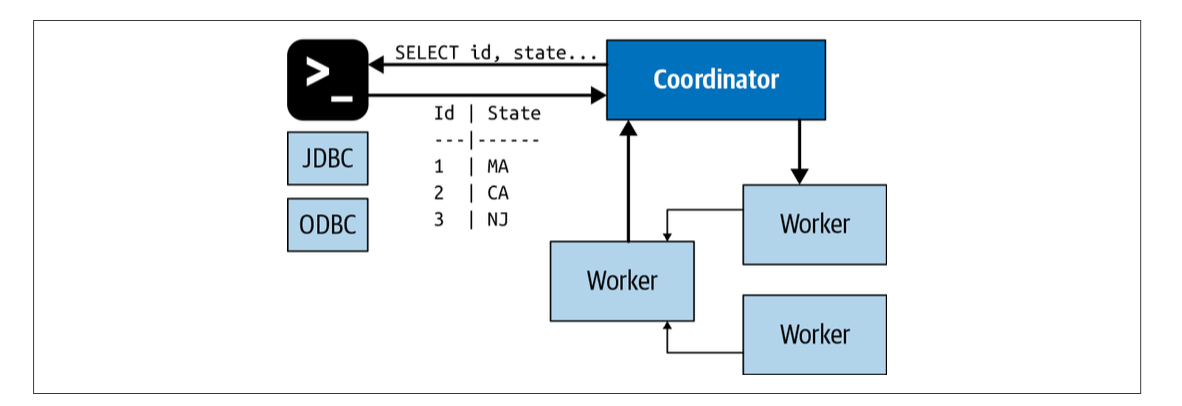
上圖給我們展示了客戶端、coordinator,worker之間的通信,
Workers
Presto的worker是Presto集群中的一個服務,它負責運行coordinator指派給它的任務,并處理資料,worker節點通過連接器(connector)向資料源獲取資料,并且相互之間可以交換資料,最終結果會傳遞給coordinator, coordinator負責從worker獲取最終結果,并傳遞給客戶端,
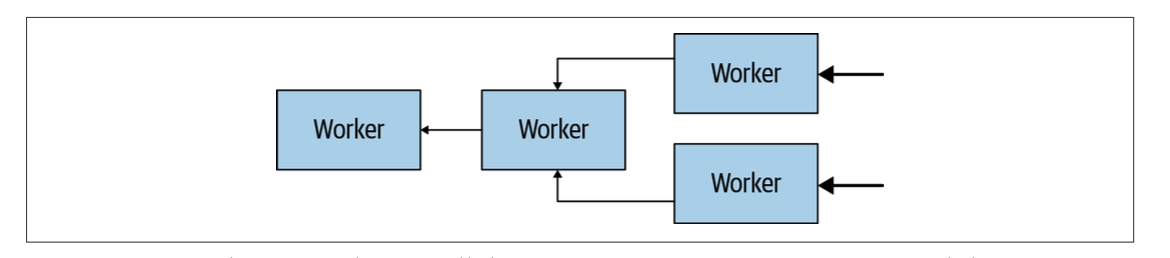
Worker之間的通信、worker和coordinator之間的通信采用基于HTTP的協議,下圖展示了多個worker如何從資料源獲取資料,并且合作處理資料的流程,直到某一個worker把資料提供給了coordinator,
一層一層剝開你的心之Presto資料模型
Presto采取了三層表結構,我們可以和Mysql做一下類比:
- catalog 對應某一類資料源,例如hive的資料,或mysql的資料
- schema 對應mysql中的資料庫
- table 對應mysql中的表
在Presto中定位一張表,一般是catalog為根,例如:一張表的全稱為 hive.testdata.test,標識 hive(catalog)下的 testdata(schema)中test表,
可以簡理解為:資料源.資料庫.資料表,
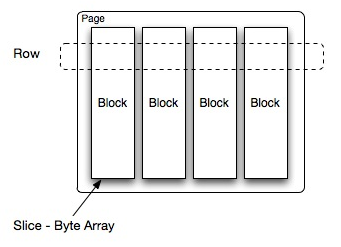
另外,presto的存盤單元包括:
- Page: 多行資料的集合,包含多個列的資料,內部僅提供邏輯行,實際以列式存盤,
- Block:一列資料,根據不同型別的資料,通常采取不同的編碼方式,了解這些編碼方式,有助于自己的存盤系統對接presto,
Presto中處理的最小資料單元是一個Page物件,Page物件的資料結構如下圖所示,一個Page物件包含多個Block物件,每個Block物件是一個位元組陣列,存盤一個欄位的若干行,多個Block橫切的一行是真實的一行資料,一個Page最大1MB,最多16 * 1024行資料,
核心問題之Presto為什么這么快?
我們在選擇Presto時很大一個考量就是計算速度,因為一個類似SparkSQL的計算引擎如果沒有速度和效率加持,那么很快就就會被拋棄,
美團的博客中給出了這個答案:
- 完全基于記憶體的并行計算
- 流水線式的處理
- 本地化計算
- 動態編譯執行計劃
- 小心使用記憶體和資料結構
- 類BlinkDB的近似查詢
- GC控制
和Hive這種需要調度生成計劃且需要中間落盤的核心優勢在于:Presto是常駐任務,接受請求立即執行,全記憶體并行計算;Hive需要用yarn做資源調度,接受查詢需要先申請資源,啟動行程,并且中間結果會經過磁盤,
欲先攻其事,必先利其器之Presto調優
合理設定磁區
與Hive類似,Presto會根據元資訊讀取磁區資料,合理的磁區能減少Presto資料讀取量,提升查詢性能,
使用列式存盤
Presto對ORC檔案讀取做了特定優化,因此在Hive中創建Presto使用的表時,建議采用ORC格式存盤,相對于Parquet,Presto對ORC支持更好,
使用壓縮
資料壓縮可以減少節點間資料傳輸對IO帶寬壓力,對于即席查詢需要快速解壓,建議采用snappy壓縮
預排序
對于已經排序的資料,在查詢的資料過濾階段,ORC格式支持跳過讀取不必要的資料,比如對于經常需要過濾的欄位可以預先排序,
記憶體調優
Presto有三種記憶體池,分別為GENERAL_POOL、RESERVED_POOL、SYSTEM_POOL,這三個記憶體池占用的記憶體大小是由下面演算法進行分配的:
builder.put(RESERVED_POOL, new MemoryPool(RESERVED_POOL, config.getMaxQueryMemoryPerNode()));
builder.put(SYSTEM_POOL, new MemoryPool(SYSTEM_POOL, systemMemoryConfig.getReservedSystemMemory()));
long maxHeap = Runtime.getRuntime().maxMemory();
maxMemory = new DataSize(maxHeap - systemMemoryConfig.getReservedSystemMemory().toBytes(), BYTE);
DataSize generalPoolSize = new DataSize(Math.max(0, maxMemory.toBytes() - config.getMaxQueryMemoryPerNode().toBytes()), BYTE);
builder.put(GENERAL_POOL, new MemoryPool(GENERAL_POOL, generalPoolSize));
簡單的說,RESERVED_POOL大小由config.properties里的query.max-memory-per-node指定;SYSTEM_POOL由config.properties里的resources.reserved-system-memory指定,如果不指定,默認值為Runtime.getRuntime().maxMemory() * 0.4,即0.4 * Xmx值;而GENERAL_POOL值為 總記憶體(Xmx值)- 預留的(max-memory-per-node)- 系統的(0.4 * Xmx),
從Presto的開發手冊中可以看到:
GENERAL_POOL is the memory pool used by the physical operators in a query.
SYSTEM_POOL is mostly used by the exchange buffers and readers/writers.
RESERVED_POOL is for running a large query when the general pool becomes full.
簡單說GENERAL_POOL用于普通查詢的physical operators;SYSTEM_POOL用于讀寫buffer;而RESERVED_POOL比較特殊,大部分時間里是不參與計算的,只有當同時滿足如下情形下,才會被使用,然后從所有查詢里獲取占用記憶體最大的那個查詢,然后將該查詢放到 RESERVED_POOL 里執行,同時注意RESERVED_POOL只能用于一個Query,
我們經常遇到的幾個錯誤:
Query exceeded per-node total memory limit of xx
適當增加query.max-total-memory-per-node,
Query exceeded distributed user memory limit of xx
適當增加query.max-memory,
Could not communicate with the remote task. The node may have crashed or be under too much load
記憶體不夠,導致節點crash,可以查看/var/log/message,
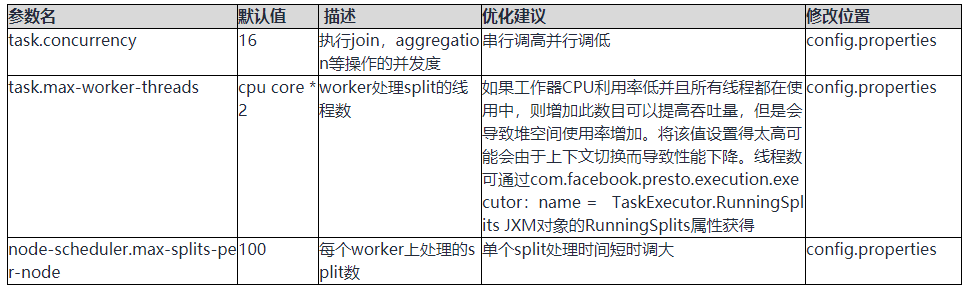
并行度
我們可以通過調整執行緒數增大task的并發以提高效率,
SQL優化
- 只選擇使用必要的欄位: 由于采用列式存盤,選擇需要的欄位可加快欄位的讀取、減少資料量,避免采用 * 讀取所有欄位
- 過濾條件必須加上磁區欄位
- Group By陳述句優化: 合理安排Group by陳述句中欄位順序對性能有一定提升,將Group By陳述句中欄位按照每個欄位distinct資料多少進行降序排列, 減少GROUP BY陳述句后面的排序一句欄位的數量能減少記憶體的使用.
- Order by時使用Limit, 盡量避免ORDER BY: Order by需要掃描資料到單個worker節點進行排序,導致單個worker需要大量記憶體
- 使用近似聚合函式: 對于允許有少量誤差的查詢場景,使用這些函式對查詢性能有大幅提升,比如使用approx_distinct() 函式比Count(distinct x)有大概2.3%的誤差
- 用regexp_like代替多個like陳述句: Presto查詢優化器沒有對多個like陳述句進行優化,使用regexp_like對性能有較大提升
- 使用Join陳述句時將大表放在左邊: Presto中join的默認演算法是broadcast join,即將join左邊的表分割到多個worker,然后將join右邊的表資料整個復制一份發送到每個worker進行計算,如果右邊的表資料量太大,則可能會報記憶體溢位錯誤,
- 使用Rank函式代替row_number函式來獲取Top N
- UNION ALL 代替 UNION :不用去重
- 使用WITH陳述句: 查詢陳述句非常復雜或者有多層嵌套的子查詢,請試著用WITH陳述句將子查詢分離出來
當然還有很多優化的方式,建議大家都在網上搜一些資料,并且參考Presto操作手冊,
它山之石可以攻玉之行業典型應用
這部分內容是小編參考的各大公司的行業應用進行的總結,目的是可以幫大家找到適合自己公司業務的應用方式,具體的原文可以再最后的參考鏈接中找到,
Presto 在滴滴的應用
滴滴 Presto 用了3年時間逐漸接入公司各大資料平臺,并成為了公司首選 Ad-Hoc 查詢引擎及 Hive SQL 加速引擎,支持了包含以下的業務場景:
- Hive SQL查詢加速
- 資料平臺Ad-Hoc查詢
- 報表(BI報表、自定義報表)
- 活動營銷
- 資料質量檢測
- 資產管理
- 固定資料產品
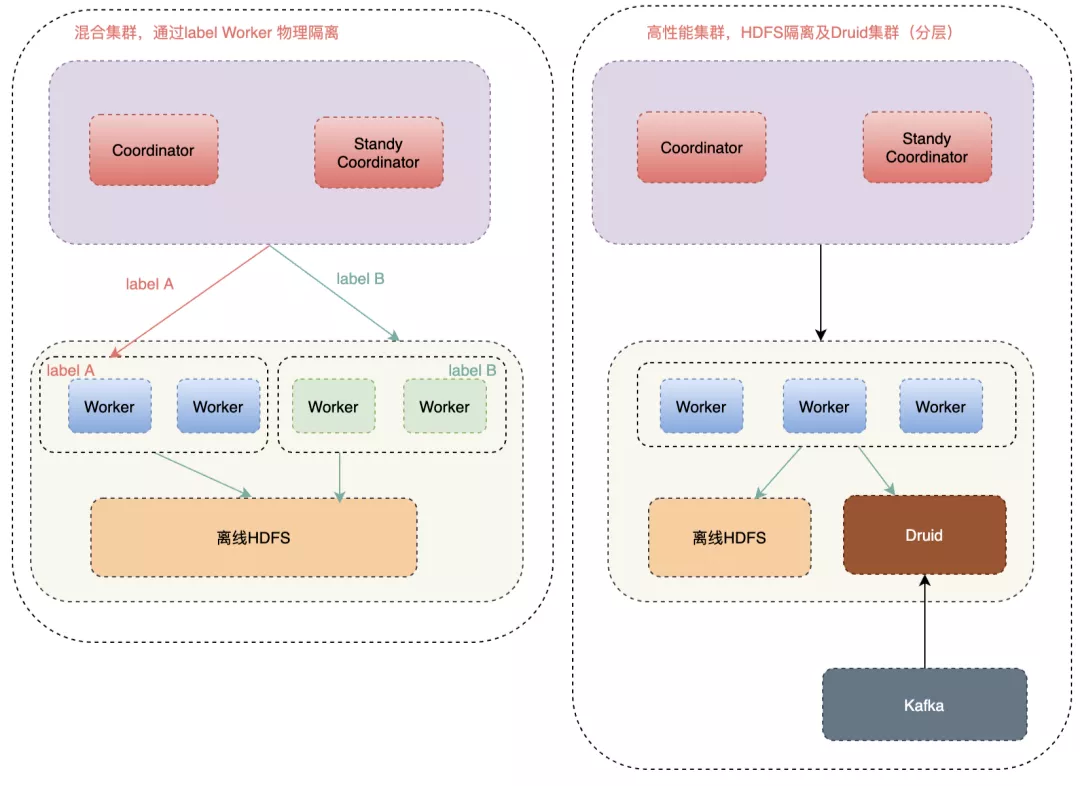
為了適配各個業務線,二次開發了 JDBC、Go、Python、Cli、R、NodeJs 、HTTP 等多種接入方式,打通了公司內部權限體系,讓業務方方便快捷的接入 Presto 的,滿足了業務方多種技術堆疊的接入需求,
Presto 接入了查詢路由 Gateway,Gateway 會智能選擇合適的引擎,用戶查詢優先請求 Presto,如果查詢失敗,會使用 Spark 查詢,如果依然失敗,最后會請求 Hive,在 Gateway 層,我們做了一些優化來區分大查詢、中查詢及小查詢,對于查詢時間小于 3 分鐘的,我們即認為適合 Presto 查詢,比如通過 HBO(基于歷史的統計資訊)及 JOIN 數量來區分查詢大小,架構圖如下:
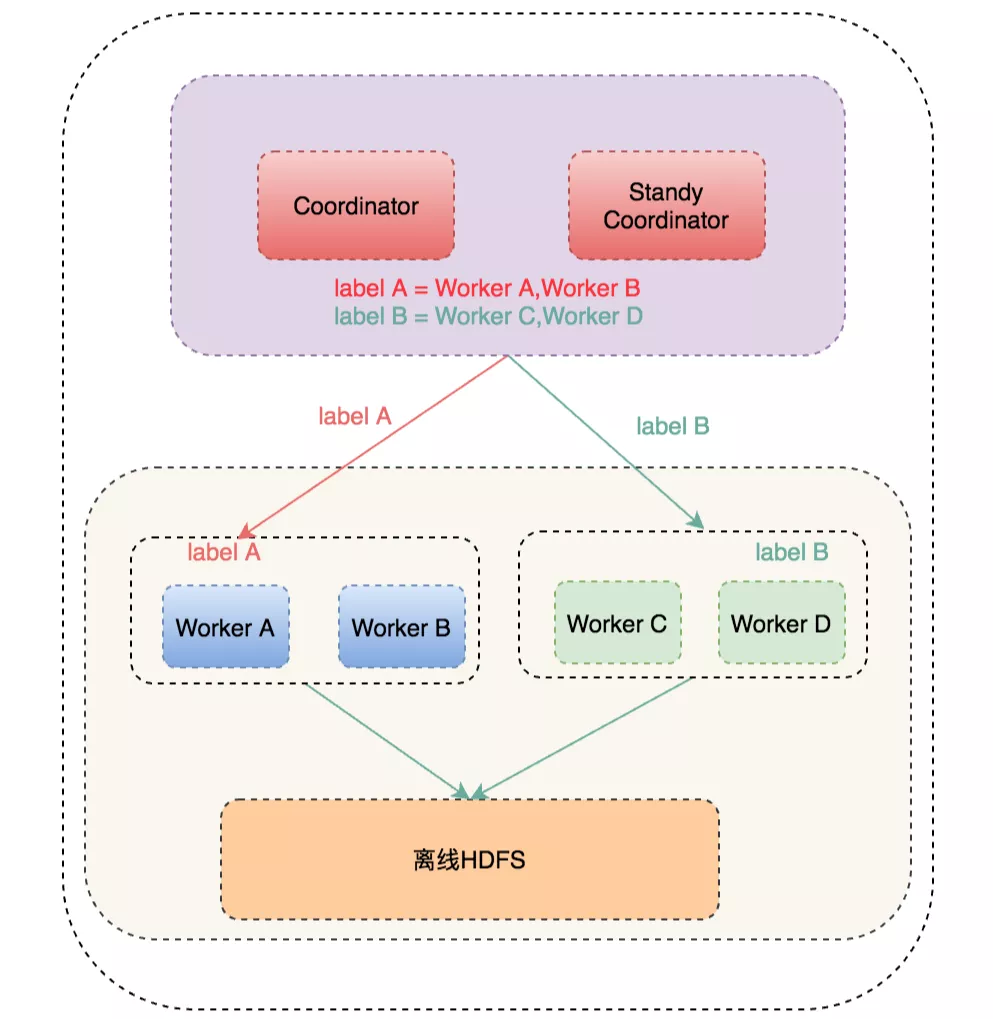
在滴滴內部,Presto 主要用于 Ad-Hoc 查詢及 Hive SQL 查詢加速,為了方便用戶能盡快將 SQL 遷移到 Presto 引擎上,且提高 Presto 引擎查詢性能,我們對 Presto 做了大量二次開發,這些功能主要包括:
- Hive SQL 兼容
- 物理資源隔離
- 直連Druid 的 Connector
- 多租戶等
Presto 在使用程序中會遇到很多穩定性問題,比如 Coordinator OOM,Worker Full GC 等,
滴滴給我們總結了 Coordinator 常見的問題和解決方法:
- 使用HDFS FileSystem Cache導致記憶體泄漏,解決方法禁止FileSystem Cache,后續Presto自己維護了FileSystem Cache
- Jetty導致堆外記憶體泄漏,原因是Gzip導致了堆外記憶體泄漏,升級Jetty版本解決
- Splits太多,無可用埠,TIME_WAIT太高,修改TCP引數解決
- Presto內核Bug,查詢失敗的SQL太多,導致Coordinator記憶體泄漏,社區已修復
而 Presto Worker 主要用于計算,性能瓶頸點主要是記憶體和 CPU,記憶體方面通過三種方法來保障和查找問題:
- 通過Resource Group控制業務并發,防止嚴重超賣
- 通過JVM調優,解決一些常見記憶體問題,如Young GC Exhausted
- 善用MAT工具,發現記憶體瓶頸
Presto 在有贊的應用
有贊在Presto上主要用來進行以下業務支持:
- 資料平臺(DP)的臨時查詢: 有贊的大資料團隊使用臨時查詢進行探索性的資料分析的統一入口,同時也提供了脫敏,審計等功能,
- BI 報表引擎:為商家提供了各類分析型的報表,
- 元資料資料質量校驗等:元資料系統會使用 Presto 進行資料質量校驗,
- 資料產品:比如 CRM 資料分析,人群畫像等會使用 Presto 進行計算,
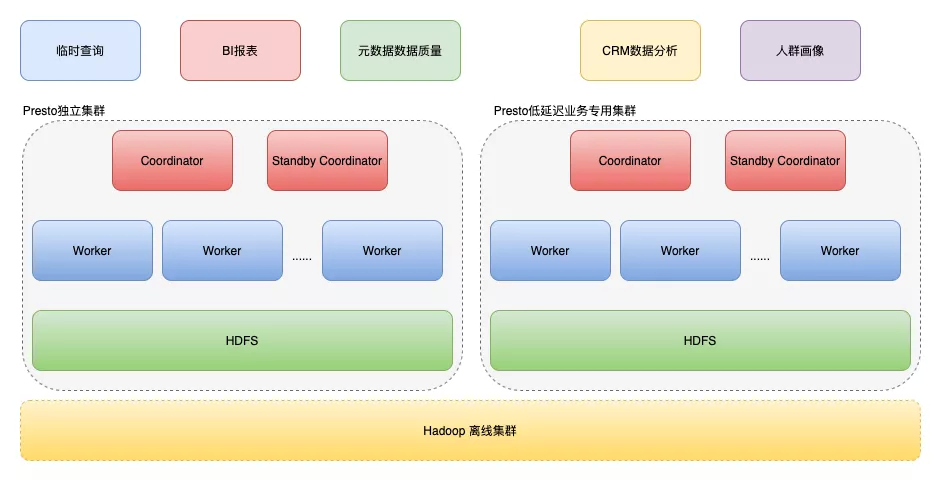
當然,有贊在使用Presto的程序中也經歷了漫長的迭代:
- 第一階段: Presto 和 Hadoop 混合部署
- 第二階段: Presto 集群完全獨立階段
- 第三階段: 低延時業務專用 Presto 集群階段
在第二階段的資源隔離主要還是靠 Resource Group,但是這種隔離方式相對比較弱,不能提供細粒度的隔離,任務之間還是會互相影響,此外,不同業務的 sql 型別,查詢資料量,查詢時間,可容忍的 SLA,可提供的最優配置都是不一樣的,有些業務方需要一個特別低的回應時間保證,于是有贊給這類業務部署了專門的集群去處理,
部署在這個集群上的業務要求低延時,通常是 3 秒內,甚至有些能夠達到 1 秒內,而且會有一定量的并發,不過這類業務通常資料量不是非常大,而且通常都是大寬表,也就不需要再去 Join 別的資料,Group By 形成的 Group 基數和產生的聚合資料量不是特別大,查詢時間主要消耗在資料掃描讀取時間上,同樣也提供了資源完全獨立,具有本地 HDFS 的專用 Presto 集群給這類業務方去使用,此外,會為這種業務提供深度的性能測驗,調整相應的配置,比如將 Task Concurrency 改成 1,在并發量高的測驗場景中,反而由于減少了執行緒間切換,性能會更好,
最后,有贊在使用Presto的程序中發生的主要問題包括:
- HDFS 小檔案問題
HDFS 小檔案問題在大資料領域是個常見的問題,數倉 Hive 表有些表的檔案有幾千個,查詢特別慢,Presto 下面這兩個引數限制了 Presto 每個節點每個 Task 可執行的最大 Split 數目:
node-scheduler.max-splits-per-node=100
node-scheduler.max-pending-splits-per-task=10
- 多個列 Distinct 的問題
簡單的說,正常的優化器應該使用 grouping sets 去將多個 group by 整合到一起來提升性能:
SELECT a1, a2,..., an, F1(b1), F2(b2), F3(b3), ...., Fm(bm), F1(distinct c1), ...., Fm(distinct cm) FROM Table GROUP BY a1, a2, ..., an
轉換為
SELECT a1, a2,..., an, arbitrary(if(group = 0, f1)),...., arbitrary(if(group = 0, fm)), F(if(group = 1, c1)), ...., F(if(group = m, cm)) FROM
SELECT a1, a2,..., an, F1(b1) as f1, F2(b2) as f2,...., Fm(bm) as fm, c1,..., cm group FROM
SELECT a1, a2,..., an, b1, b2, ... ,bn, c1,..., cm FROM Table GROUP BY GROUPING SETS ((a1, a2,..., an, b1, b2, ... ,bn), (a1, a2,..., an, c1), ..., ((a1, a2,..., an, cm)))
GROUP BY a1, a2,..., an, c1,..., cm group
GROUP BY a1, a2,..., an
但是很遺憾,Presto并沒有實作這樣的功能,以上就是有贊在使用Presto的一些經驗,
總結
小編在學習Presto的程序中和其他的OLAP一樣,也是通過漫長的檔案搜索,官網摸索主鍵精進的,事實上在任何一門新技術的使用程序中大家都會遇到各種各樣的問題,如果利用現在有的資料解決問題就是考驗我們的時候了,
歡迎關注,《大資料成神之路》系列文章
歡迎關注,《大資料成神之路》系列文章
歡迎關注,《大資料成神之路》系列文章
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/246720.html
標籤:Java
上一篇:IO操作