Shuffle的本意是洗牌、混洗的意思,把一組有規則的資料盡量打亂成無規則的資料,而在MapReduce中,Shuffle更像是洗牌的逆程序,指的是將map端的無規則輸出按指定的規則“打亂”成具有一定規則的資料,以便reduce端接收處理,其在MapReduce中所處的作業階段是map輸出后到reduce接收前,具體可以分為map端和reduce端前后兩個部分,
在Shuffle之前,也就是在map階段,MapReduce會對要處理的資料進行分片(split)操作,為每一個分片分配一個MapTask任務,接下來map會對每一個分片中的每一行資料進行處理得到鍵值對(key,value)此時得到的鍵值對又叫做“中間結果”,此后便進入reduce階段,由此可以看出Shuffle階段的作用是處理“中間結果”,
由于Shuffle涉及到了磁盤的讀寫和網路的傳輸,因此Shuffle性能的高低直接影響到了整個程式的運行效率,
我們先放一張圖,下圖說明了二者shuffle的主要區別:
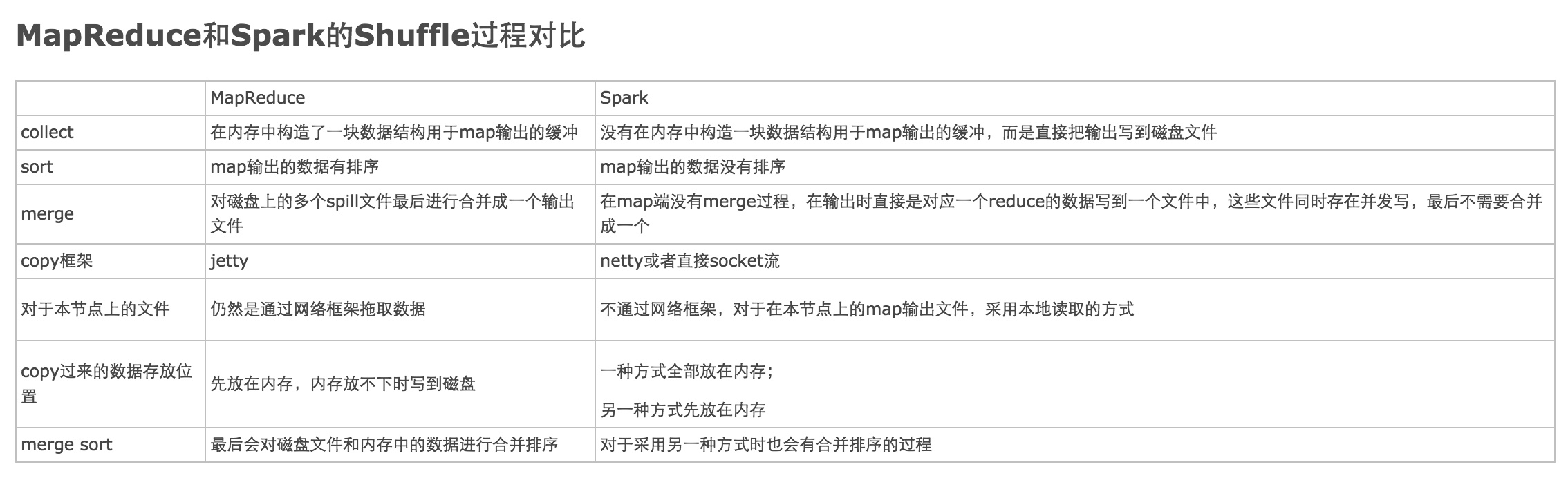
MapReduce Shuffle
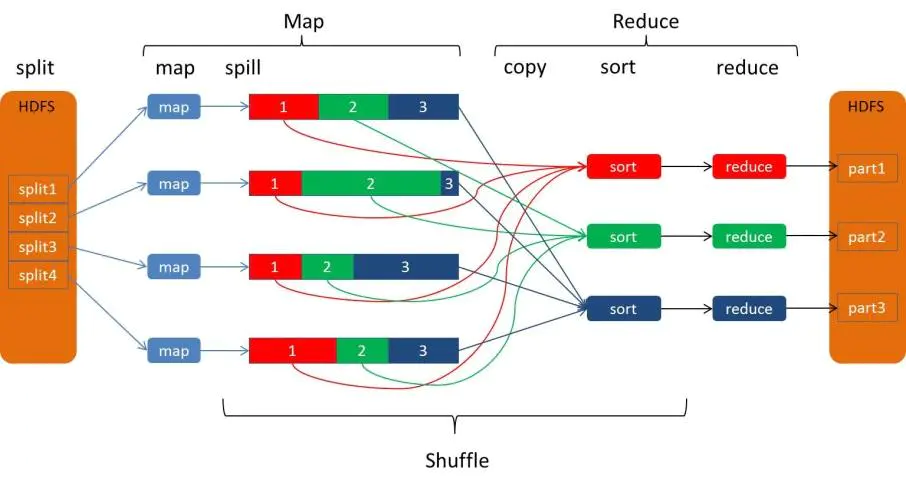
我們在《大資料嗶嗶集20210107》中詳細講解過MapReduce的shuffle程序:
map階段
- 在map task執行時,它的輸入資料來源于HDFS的block,當然在MapReduce概念中,map task只讀取split,Split與block的對應關系可能是多對一,默認是一對一,
- 在經過mapper的運行后,我們得知mapper的輸出是這樣一個key/value對: key是“hello”, value是數值1,因為當前map端只做加1的操作,在reduce task里才去合并結果集,這個job有3個reduce task,到底當前的“hello”應該交由哪個reduce去做呢,是需要現在決定的,
-
磁區(partition)
MapReduce提供Partitioner介面,它的作用就是根據key或value及reduce的數量來決定當前的這對輸出資料最終應該交由哪個reduce task處理,默認對key hash后再以reduce task數量取模,默認的取模方式只是為了平均reduce的處理能力,如果用戶自己對Partitioner有需求,可以訂制并設定到job上,
一個split被分成了3個partition, -
排序sort
在spill寫入之前,會先進行二次排序,首先根據資料所屬的partition進行排序,然后每個partition中的資料再按key來排序,partition的目是將記錄劃分到不同的Reducer上去,以期望能夠達到負載均衡,以后的Reducer就會根據partition來讀取自己對應的資料,接著運行combiner(如果設定了的話),combiner的本質也是一個Reducer,其目的是對將要寫入到磁盤上的檔案先進行一次處理,這樣,寫入到磁盤的資料量就會減少, -
溢寫(spill)
Map端會處理輸入資料并產生中間結果,這個中間結果會寫到本地磁盤,而不是HDFS,每個Map的輸出會先寫到記憶體緩沖區中, 緩沖區的作用是批量收集map結果,減少磁盤IO的影響,我們的key/value對以及Partition的結果都會被寫入緩沖區,當然寫入之前,key與value值都會被序列化成位元組陣列, 當寫入的資料達到設定的閾值時,系統將會啟動一個執行緒將緩沖區的資料寫到磁盤,這個程序叫做spill,
這個溢寫是由單獨執行緒來完成,不影響往緩沖區寫map結果的執行緒,溢寫執行緒啟動時不應該阻止map的結果輸出,所以整個緩沖區有個溢寫的比例spill.percent,這個比例默認是0.8,
將資料寫到本地磁盤產生spill檔案(spill檔案保存在{mapred.local.dir}指定的目錄中,MapReduce任務結束后就會被洗掉), -
合并(merge)
每個Map任務可能產生多個spill檔案,在每個Map任務完成前,會通過多路歸并演算法將這些spill檔案歸并成一個檔案,這個操作就叫merge(spill檔案保存在{mapred.local.dir}指定的目錄中,Map任務結束后就會被洗掉),一個map最侄訓溢寫一個檔案,
至此,Map的shuffle程序就結束了,
Reduce階段
Reduce端的shuffle主要包括三個階段,copy、sort(merge)和reduce,
-
copy
首先要將Map端產生的輸出檔案拷貝到Reduce端,但每個Reducer如何知道自己應該處理哪些資料呢?因為Map端進行partition的時候,實際上就相當于指定了每個Reducer要處理的資料(partition就對應了Reducer),所以Reducer在拷貝資料的時候只需拷貝與自己對應的partition中的資料即可,每個Reducer會處理一個或者多個partition,但需要先將自己對應的partition中的資料從每個Map的輸出結果中拷貝過來, -
merge
Copy過來的資料會先放入記憶體緩沖區中,這里的緩沖區大小要比map端的更為靈活,它基于JVM的heap size設定,因為Shuffle階段Reducer不運行,所以應該把絕大部分的記憶體都給Shuffle用,
這里需要強調的是:
merge階段,也稱為sort階段,因為這個階段的主要作業是執行了歸并排序,從Map端拷貝到Reduce端的資料都是有序的,所以很適合歸并排序,
merge有三種形式:1)記憶體到記憶體 2)記憶體到磁盤 3)磁盤到磁盤,默認情況下第一種形式不啟用,讓人比較困惑,是吧,
當copy到記憶體中的資料量到達一定閾值,就啟動記憶體到磁盤的merge,即第二種merge方式,與map 端類似,這也是溢寫的程序,這個程序中如果你設定有Combiner,也是會啟用的,然后在磁盤中生成了眾多的溢寫檔案,這種merge方式一直在運行,直到沒有map端的資料時才結束,然后啟動第三種磁盤到磁盤的merge方式生成最終的那個檔案,
- reduce
不斷地merge后,最后會生成一個“最終檔案”,為什么加引號?因為這個檔案可能存在于磁盤上,也可能存在于記憶體中,對我們來說,當然希望它存放于記憶體中,直接作為Reducer的輸入,但默認情況下,這個檔案是存放于磁盤中的,至于怎樣才能讓這個檔案出現在記憶體中,參見性能優化篇,
然后就是Reducer執行,在這個程序中產生了最終的輸出結果,并將其寫到HDFS上,
Spark Shuffle
我們在之前的文章《Spark性能優化總結》中提到過,Spark Shuffle 的原理和演程序序,
Spark在DAG階段以寬依賴shuffle為界,劃分stage,上游stage做map task,每個map task將計算結果資料分成多份,每一份對應到下游stage的每個partition中,并將其臨時寫到磁盤,該程序叫做shuffle write,
下游stage做reduce task,每個reduce task通過網路拉取上游stage中所有map task的指定磁區結果資料,該程序叫做shuffle read,最后完成reduce的業務邏輯,
下圖中,上游stage有3個map task,下游stage有4個reduce task,那么這3個map task中每個map task都會產生4份資料,而4個reduce task中的每個reduce task都會拉取上游3個map task對應的那份資料,
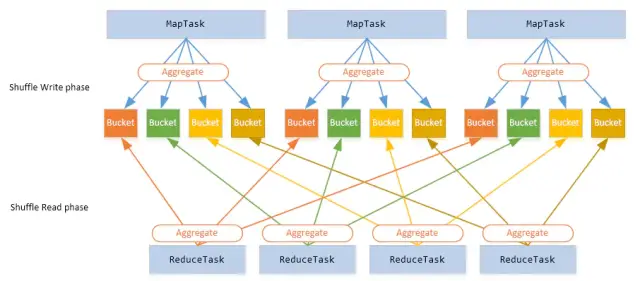
Spark Shuffle演進
-
< 0.8 hashBasedShuffle
每個map端的task為每個reduce端的partition/task生成一個檔案,通常會產生大量的檔案,伴隨大量的隨機磁盤IO操作與大量的記憶體開銷M * R -
0.8.1 引入檔案合并File Consolidation機制
每個executor為每個reduce端的partition生成一個檔案E*R -
0.9 引入External AppendOnlyMap
combine時可以將資料spill到磁盤,然后通過堆排序merge -
1.1 引入sortBasedShuffle
每個map task不會為每個reducer task生成一個單獨的檔案,而是會將所有的結果寫到一個檔案里,同時會生成一個index檔案,reducer可以通過這個index檔案取得它需要處理的資料M -
1.4 引入Tungsten-Sort Based Shuffle
亦稱unsafeShuffle,將資料記錄用序列化的二進制方式存盤,把排序轉化成指標陣列的排序,引入堆外記憶體空間和新的記憶體管理模型 -
1.6 Tungsten-sort并入Sort Based Shuffle
由SortShuffleManager自動判斷選擇最佳Shuffle方式,如果檢測到滿足Tungsten-sort條件會自動采用Tungsten-sort Based Shuffle,否則采用Sort Based Shuffle -
2.0 hashBasedShuffle退出歷史舞臺
從此Spark只有sortBasedShuffle
總結
到此為止,我們已經把二者的原理完完整整的講了一遍,最后,總結參考ITStar總結過的二者的不同精簡要點版本:
Hadoop Shuffle:通過Map端處理的資料到Reduce端的中間的程序就是Shuffle.
Spark Shuffle:在DAG調度程序中,stage階段的劃分是根據shuffle程序,也就是存在ShuffleDependency寬窄依賴的時候,需要進行shuffle,(這時候會將作業Job劃分成多個stage;并且在劃分stage的時候,構建shuffleDependency的時候進行shuffle注冊,獲取后續資料讀取所需要的shuffleHandle),最終每一個Job提交后都會生成一個ResultStage和若干個ShuffleMapStage.
shuffle程序排序次數不同
Hadoop Shuffle程序中總共發生3次排序,詳細分別如下:
第一次排序行為:在map階段,由環形緩沖區溢位到磁盤上時,落地磁盤的檔案會按照key進行磁區和排序,屬于磁區內有序,排序演算法為快速排序.
第二次排序行為:在map階段,對溢位的檔案進行combiner合并程序中,需要對溢位的小檔案進行歸檔排序,合并,排序演算法為歸并排序.
第三次排序行為:在map階段,reduce task將不同map task端檔案拉取到同一個reduce磁區后,對檔案進行合并,排序,排序演算法為歸并排序.
spark shuffle程序在滿足shuffle manager為sortshuffleManager,且運行模式為普通模式的情況下才會發生排序行為,排序行為發生在資料結構中保存資料記憶體達到閥值,再溢位磁盤檔案之前會對記憶體資料結構中資料進行排序;
spark中sorted-Based Shuffle在Mapper端是進行排序的,包括partition的排序和每個partition內部元素進行排序,但是在Reducer端沒有進行排序,所有job的結果默認情況下不是排序的.Sprted-Based Shuffle 采用 Tim-Sort排序演算法,好處是可以極為高效的使用Mapper端的排序成果完成全域排序.
shuffle 邏輯流劃分
Hadoop是基于檔案的資料結構,Spark是基于RDD的資料結構,計算性能要比Hadoop要高,
Shuffle Fetch后資料存放位置
Hadoopreduce 端將 map task 的檔案拉取到同一個reduce磁區,是將檔案進行歸并排序,合并,將檔案直接保存在磁盤上,
SparkShuffle Read 拉取來的資料首先肯定是放在Reducer端的記憶體快取區中的,現在的實作都是記憶體+磁盤的方式(資料結構使用 ExternalAppendOnlyMap),當然也可以通過Spark.shuffle.spill=false來設定只能使用記憶體.使用ExternalAppendOnlyMap的方式時候如果記憶體的使用達到一定臨界值,會首先嘗試在記憶體中擴大ExternalAppendOnlyMap(內部有實作演算法),如果不能擴容的話才會spil到磁盤.
什么時候進行Shuffle Fetch操作
Hadoop Shuffle把資料拉過來之后,然后進行計算,如果用MapReduce求平均值的話,它的演算法就會很好實作,Spark Shuffle的程序是邊拉取資料邊進行Aggregrate操作,
Fetch操作與資料計算粒度
Hadoop的MapReduce是粗粒度的,Hadoop Shuffle Reducer Fetch 到的資料record先暫時被存放到Buffer中,當Buffer快滿時才進行combine()操作,Spark的Shuffle Fetch是細粒度的,Reducer是對Map端資料Record邊拉取邊聚合,
性能優化的角度
Hadoop MapReduce的shuffle方式單一.Spark針對不同型別的操作,不同型別的引數,會使用不同的shuffle write方式;而spark更加全面,
歡迎關注,《大資料成神之路》系列文章
歡迎關注,《大資料成神之路》系列文章
歡迎關注,《大資料成神之路》系列文章
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/246722.html
標籤:Java
下一篇:企業大資料平臺倉庫架構建設思路