復制功能是Redis高可用的基礎,Redis提供了主從復制的功能,實作了相同資料的多個Redis副本,從而解決分布式環境下的單點問題以及故障恢復和負載均衡等需求,
創建復制
創建主從復制有以下幾種方式,一種是在redis服務啟動之前在組態檔中配置好直接啟動,第二種是啟動redis服務時的啟動命令,第三種是在啟動以后使用命令列的方式創建
組態檔方式
編輯redis.conf檔案,修改replicaof引數的值為主節點的ip地址和埠號,主節點有密碼的還需要設定masterauth引數的值為主節點密碼
replicaof 192.168.216.128 6379
masterauth 123456
修改以上引數值以后使用指定組態檔啟動redis即可,redis啟動以后可以在日志中看到如下的提示資訊

啟動命令時配置
使用redis-server命令啟動redis時,添加replicaof引數即可,如下所示:
$ redis-server --port 6379 --replicaof 192.168.216.128 6379
命令列配置
在redis-cli客戶端中執行slaveof命令:
$ redis-cli> slaveof 192.168.216.128 6379
使用以上任意一種方式都可以創建主從復制,可以根據具體情況擇優使用,需要注意的一點就是以上的命令或者修改組態檔都是以從節點為執行節點的,也就是要在從節點上執行,
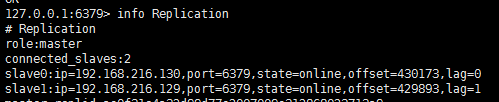
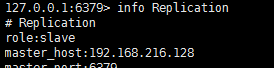
主從創建成功以后,可以通過info Replication查看主從情況,比如我有一個一主兩從的結構,查詢結果如下:
主節點:
從節點:
主從拓撲結構
Redis的主從拓撲結構按照復雜度可以分為一主一從、一主多從以及樹狀主從結構,一主一從以及一主多從很容易理解,重點要看一下樹狀主從結構,拓撲結構圖如下所示:
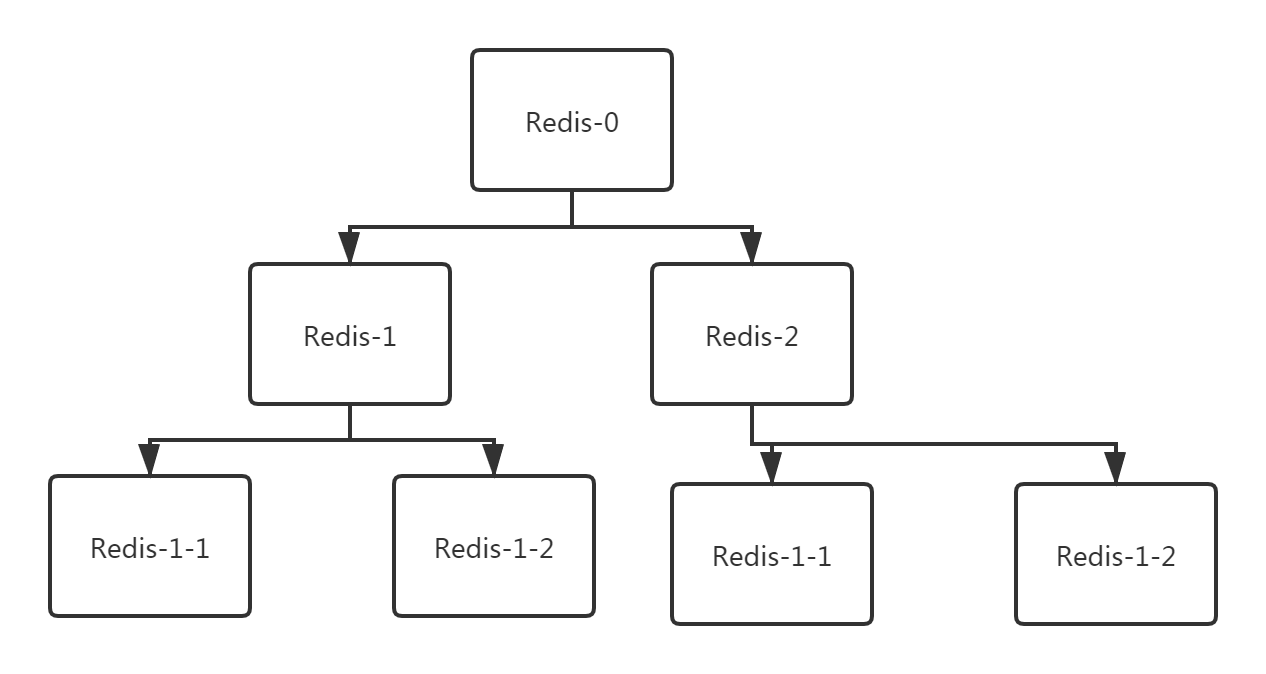
從上圖可以看出來,樹狀主從是將一部分從節點作為另外一部分的從節點的主節點從而形成樹形結構,那為什么要使用樹狀主從,直接使用一主多從不是更簡單嗎?這個主要是為了避免影響主節點的性能,這個等后面我們說到復制原理的時候再具體說,
斷開復制
斷開復制在不停止服務的情況下,同樣適用slaveof命令,將主從斷開,將從節點升級為主節點,在從節點中執行如下命令:
$ redis-cli> slaveof no one
執行以上命令后,可以看到對應的redis日志中出現以下內容:

意思就是說已失去主節點的連接,master模式已啟動,此時在主節點執行info Replication命令就可以發現從節點已經不存在了,
slaveof host port是創建主從,slaveof no one是斷開主從,兩者結合可以實作切換主節點的功能,但是有一點需要注意,在切換主節點后,當前節點的歷史資料就會被清空,然后再從新的主節點全量復制新的資料
資料復制流程
執行slaveof命令或者使用指定組態檔啟動從節點以后,從主節點到從節點的復制流程就開始了,復制流程圖如下所示
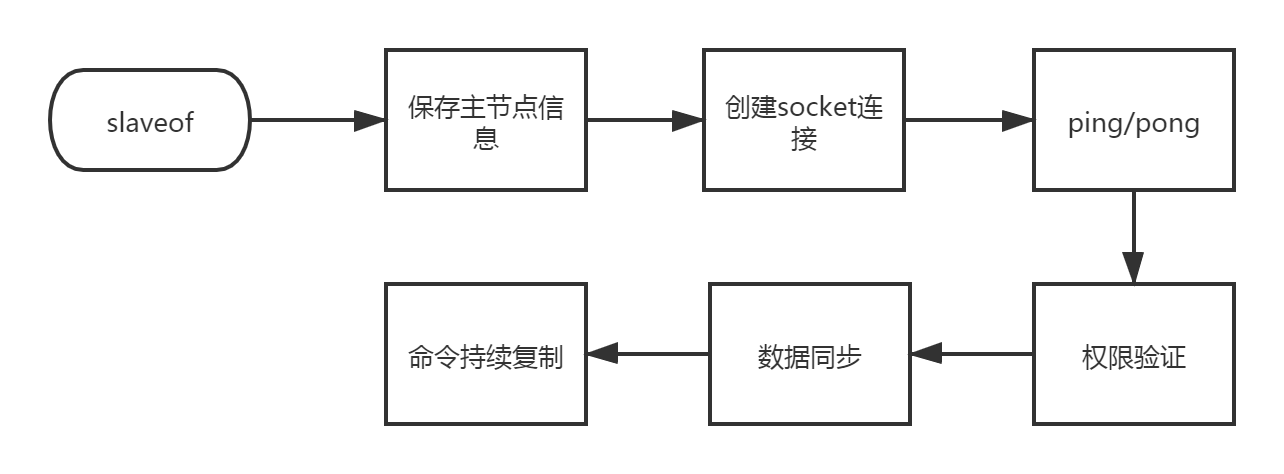
- 從節點執行slaveof 主節點host 主節點port命令后,在redis會列印如下所示的日志資訊:
* REPLICAOF 192.168.216.129:6379 enabled (user request from 'id=4 addr=127.0.0.1:58476 fd=9 name= age=142 idle=0 flags=N db=0 sub=0 psub=0 multi=-1 qbuf=49 qbuf-free=32719 argv-mem=26 obl=0 oll=0 omem=0 tot-mem=61490 events=r cmd=slaveof use
r=default')
slaveof是異步命令,執行完該命令后從節點保存主節點的host和port資訊,但是并未真正開始復制;
- 創建socket連接,從節點內部定時每秒執行一次復制定時函式
replicationCron,當發現存在可以連接主節點時就會根據主節點的資訊創建socket連接,如果節點無法連接就會無限重試或者直到執行slaveof no one命令,此時redis會列印如下所示日志:
* Connecting to MASTER 192.168.216.129:6379
* MASTER <-> REPLICA sync started
此時主節點會給從節點的socket連接創建客戶端狀態并將其當作主節點上的一個客戶端,使用client list命令是可以明確看到這個客戶端的,如下所示:

3. 從節點發送ping命令,等待主節點回復pong,用以檢測socket是否可用以及主節點是否可接受處理命令,如果從節點接收回應超時或者接受到pong以外的回應,從節點就會斷開復制鏈接,等待下次定時任務時再發起重連,日志如下:
* Master replied to PING, replication can continue...
-
masterauth驗證,如果主節點設定了密碼,那么此時需要驗證密碼才可以進行下一步操作,密碼驗證失敗的話會斷開連接,等待下一次重連;
-
資料同步,資料同步其實就是從節點的初始化的程序,資料同步包含全量同步以及部分同步,同步的程序后面具體分析,另外要注意一點的是在資料同步階段主節點需要主動向從節點發送請求,因此此時主從節點互為客戶端,資料同步對應的日志如下所示:
* Trying a partial resynchronization (request 6c4167e7160b6bb316de536f24a93b1f260b2f10:1).
* Full resync from master: ac0f31e4a32d99d77c2007009c312868023713a9:840612
* Discarding previously cached master state.
* MASTER <-> REPLICA sync: receiving 269 bytes from master to disk
* MASTER <-> REPLICA sync: Flushing old data
* MASTER <-> REPLICA sync: Loading DB in memory
* Loading RDB produced by version 6.0.9
* RDB age 0 seconds
* RDB memory usage when created 1.85 Mb
* MASTER <-> REPLICA sync: Finished with success
- 持續性復制,經過前面五個步驟,正常情況下主從已經創建成功,之后主節點會源源不斷的將寫命令發送到從節點,從而保證主從一致性;
全量復制
全量復制是一個比較重型的操作,需要將主節點上的全部資料復制到從節點上,用于初次復制或者無法進行部分復制的情況,在實際使用中應該盡量避免全量復制,
《Redis開發和運維》以及查詢的資料中看到的都是初次執行slaveof或者之前執行過slaveof no one的節點在第一次資料同步時會發送psync-1,主節點根據psync-1決議出是全量復制,從而開啟全量復制,但是在6.0.9中測驗時發送的是復制id:1
全量復制的流程(以列印的日志來分析):
- 從節點向主節點發送psync請求,對應日志如下:
* Trying a partial resynchronization (request 56530e3cbd0c37b80143315ef8ef535172eab781:1).
- 主節點接收到從節點的psync請求,判斷是否是全量同步,如果是就回應從節點Full resync,主節點對應日志如下:
# 部分復制沒有被接受,復制id不匹配
* Partial resynchronization not accepted: Replication ID mismatch (Replica asked for '56530e3cbd0c37b80143315ef8ef535172eab781', my replication IDs are 'c6a9a35ad63a0ce35b6574641a3d01bc3f586f7f' and '0000000000000000000000000000000000000000'
)
* Replication backlog created, my new replication IDs are 'adbec8fcdbcafeb97c46e1b8cd209b6121b353d8' and '0000000000000000000000000000000000000000'
此時從節點接收到主節點發出的全量復制回應,包含新的復制id以及offset值:
* Full resync from master: adbec8fcdbcafeb97c46e1b8cd209b6121b353d8:0
- 主節點執行bgsave生成rdb檔案,關于生成rdb檔案的細節請參考拙作redis之持久化,主節點日志如下:
* Starting BGSAVE for SYNC with target: disk
* Background saving started by pid 21
* DB saved on disk
* RDB: 6 MB of memory used by copy-on-write
* Background saving terminated with succeed
- 主節點把生成的rdb檔案發送給從節點,從節點把接收到的rdb檔案直接作為自己的資料檔案,對應從節點日志如下:
* MASTER <-> REPLICA sync: receiving 175 bytes from master to disk
注意:此處是為了演示,所以生成的rdb檔案較小,但是正式環境的資料量較大特別是超過6GB時資料傳輸就會比較依賴寬帶了,如果資料傳輸的時間超過配置的
repl-timeout默認的60s就會導致從節點放棄接收的rdb檔案并清理已下載的rdb檔案,導致全量復制失敗,因此在實際使用程序中要根據實際情況適當調大該引數的值,防止超時導致的復制失敗,
- 從節點在接收rdb檔案時,主節點仍然在繼續回應其他客戶端的命令,此時主節點會將這個程序中的寫命令對應的資料寫入到復制緩沖區中,當從節點加載完rdb檔案后再把復制緩沖區中的資料發給從節點,從而達到主從一致性的目的,
注意:
復制緩沖區默認配置是client-output-buffer-limit replica 256mb 64mb 60,也就是60s內緩沖區持續消耗64m或者直接超過256m時,主節點將直接關閉復制客戶端連接,導致全量同步失敗,因此在高流量寫入的情況下全量復制比較容易導致緩沖區溢位,從而導致復制失敗,這個也要根據實際情況要調整引數大小,
- 從節點接收完成rdb檔案后,清空自身原有資料,日志如下
* MASTER <-> REPLICA sync: Flushing old data
- 開始加載rdb檔案中的資料,對于較大的rdb檔案,加載也比較耗時,對應日志如下
* MASTER <-> REPLICA sync: Loading DB in memory
* RDB age 0 seconds
* RDB memory usage when created 1.85 Mb
* MASTER <-> REPLICA sync: Finished with success
- rdb檔案加載完以后從節點的狀態就變成了主節點執行bgsave時的狀態了,此時再把復制緩沖區的寫命令發送給從節點,從節點執行完成后狀態就和主節點一致了,
- 上述步驟執行完以后,如果從節點開啟了aof,那么就會立刻執行bgrewriteaof操作,這是為了保證全量復制以后aof持久化檔案立刻可用;
經過以上9個步驟就完成了全量復制,可以發現全量復制在主節點要執行bgsave,還要把生成的rdb檔案網路傳輸,到了從節點還要加載rdb檔案,甚至可能要進行aof檔案重寫,這些都是比較耗費資源的操作,因此還是要盡可能地減少全量復制,
前面拓撲結構中提到不建議使用一主多從的拓撲結構,其實就是基于這個考慮,多個從節點同時對一個主節點進行全量復制,雖然redis能夠使多個從節點復用一個rdb檔案,但是rdb檔案向多個從節點發送以及在寫并發較高時,主節點需要向多個從節點發送訊息從而浪費大量的網路帶寬,同時也加重了主節點的負載從而影響主節點的穩定性,
部分復制
部分復制是為了解決全量復制開銷過大的一種優化措施,當從節點復制主節點資料程序中,如果出現網路中斷或者命令丟失等例外情況,此時從節點可以向主節點要求補發丟失的命令資料,如果主節點的復制緩沖區中剛好存在這一部分資料,那就直接發送給從節點以此來保證主從一致性,在了解部分復制之前我們需要先知道三個概念:
runid
runid就是主節點的運行id,是redis啟動時隨機分配的一個40位的十六進制字串,運行id用來唯一識別redis節點,從節點保存主節點的runid從而知道自己需要從哪個節點來復制資料,
之所以使用runid而不是使用host+port的方式是因為一旦aof或者rdb檔案發生改變并重啟了redis服務,那么從節點再基于偏移量(offset)去復制資料是不安全的,
那么已經構建的主從架構,如果要主節點出現故障需要重啟怎么辦呢?可以使用slaveof no one先將從節點升級為主節點,待真正的主節點重啟完成后再使用slaveof重新創建主從,當然這是一種很low的做法,高級的一點做法可以使用哨兵或者集群等高可用方案,
offset
offset是復制偏移量,表示主節點向從節點傳遞的位元組數,主節點每次向從節點傳遞N個位元組資料時,主節點的復制偏移量增加N,從節點從主節點接收N個位元組資料時,從節點的復制偏移量增加N,
復制偏移量可以用來判斷主從節點的一致性,如果兩者復制偏移量相同,那么就是主從一致,如果主節點偏移量大于從節點偏移量,且遠遠大于,那么此時可能出現了網路延遲或者命令阻塞,主節點的偏移量比從節點偏移量大的部分就存在于復制緩沖區中,當從節點請求部分復制時就從復制緩沖區中獲取到對應偏移量的資料傳遞給從節點,
復制緩沖區
顧名思義,復制緩沖區就是一個緩沖區,它是保存在主節點上一個固定長度、先進先出的佇列,默認大小時1M,當主節點存在從節點時,不管是幾個從節點,主節點都會將寫命令發送給從節點的同時快取到復制緩沖區中,當緩沖區占滿時就會將最先進入緩沖區的資料擠出緩沖區,
當主從節點斷開重連時,從節點帶著offset請求復制,主節點判斷從節點的offset是否存在于緩沖區中,如果存在,那么就進行部分復制,將緩沖區中的資料直接回傳給從節點,如果從節點傳遞的offset已經超過緩沖區中的offset的值,那么就需要開啟全量復制,基于此,要根據具體的業務需求調整復制緩沖區的大小,盡可能地使用部分復制,
部分復制實體
我在兩臺機器上分別安裝了一個redis,其中一個作為另外一個的從節點,從節點:
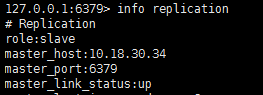
主節點:

為了驗證部分復制,現在將兩臺機器之間的網路斷開(簡單粗暴的辦法,拔網線),經過一會兒之后查看主從節點的日志,可以看到各自都出現了lost,如下所示:
# 主節點日志
# Connection with slave 10.18.30.178:6379 lost.
# 從節點日志
1:S # MASTER timeout: no data nor PING received...
1:S # Connection with master lost.
1:S * Caching the disconnected master state.
1:S * Connecting to MASTER 10.18.30.34:6379
1:S * MASTER <-> REPLICA sync started
1:S # Error condition on socket for SYNC: No route to host
1:S * Connecting to MASTER 10.18.30.34:6379
在主從節點各自丟失對方的連接時,在主節點上執行寫操作(隨便寫入一些資料),如下所示:
經過一段時間以后,重新連通主從節點之間的網路,此時,在從節點的日志中可以看到如下所示的內容:
1:S * Connecting to MASTER 10.18.30.34:6379 # 連接上了主節點
1:S * MASTER <-> REPLICA sync started # 主從節點開始同步
1:S * Non blocking connect for SYNC fired the event.
1:S * Master replied to PING, replication can continue... # 主節點回復了ping,主從可以繼續
1:S * Trying a partial resynchronization (request eb32e34c84e7123e7ddb6ae1fab5e348bc58af31:1234). # 開始部分復制,offset是1234
1:S * Successful partial resynchronization with master. # 部分復制成功
從上面的日志可以看出來,從節點連接上主節點之后開始嘗試部分復制,并且最后部分復制成功,我們再看一下此時主節點的日志:
* Slave 10.18.30.178:6379 asks for synchronization # 從節點請求同步
* Partial resynchronization request from 10.18.30.178:6379 accepted. Sending 444 bytes of backlog starting from offset 1234. # 接受從節點的部分復制請求,從1234的offset位置發送444bytes的資料
也就是主節點此時判斷這次的同步請求符合部分復制,那么就從對應的offset位置發送資料給從節點,如果此時offset不在復制緩沖區的范圍內,那么開啟的就是全量復制,而不是部分復制了,
另外,如果部分復制完成后aof檔案達到了auto-aof-rewrite-min-size以及auto-aof-rewrite-percentage的要求,那么此時就會觸發aof的重寫,
總結一下重寫的程序,就是如下幾個步驟:
- 主從節點網路中斷,超過
repl-timeout時間后,主節點認為從節點故障,列印lost日志; - 主從斷開期間,主節點繼續回應請求,會將寫命令快取到大小為1M的復制緩沖區;
- 主從網路恢復后,從節點會再次連接上主節點,列印主從可以繼續的日志;
- 主從恢復后,從節點使用psync請求,帶著保存好的主節點運行id以及自身已經復制的偏移量去請求進行復制;
- 主節點接收到從節點的psync請求后,首先判斷runID是否一直,不一致的話表示之前復制的不是當前主節點,需要重新開始全量復制,一致的話再查找請求offset是否存在于復制緩沖區中,不存在的話同樣要開啟全量復制;
- runID和offset都符合部分復制的要求后,主節點會把復制緩沖區中相應的資料發送給從節點,保證主從進入正常復制;
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/246730.html
標籤:Java