酷狗音樂的爬取,從無到有完整教程-下:功能代碼講解
是的我又回來了,這次是代碼的講解哦,
引數項生成
上一章我們提到,在包含了歌曲url,歌曲資訊的請求中,有幾個引數項的值是亂數就可以,但是,你仔細看,雖然是亂數,有些引數項的值就是數字,有些就是數字和字符混合,所以這里我們不僅要生成亂數,還要分類生成不同的亂數,
給大家看一下我寫的的生成函式(目前是我感覺最明了的方法了>_<)

呼叫這個函式需要提供兩個引數,一是DataType,也就是要生成的型別,是純字符還是純數字還是混合,還有一個就是length,也就是生成的字串長度,這個很好理解就不多說嘻嘻
請求中等待時間的隨機
由于在請求網頁資料的時候需要等待網頁加載完在獲得網頁當前的元素,所以就會需要一個等待時間,但是固定的等待時間,容易讓瀏覽器覺得你是個假人,不能很好的偽裝(我也是從別人的blog看的哈哈),從而讓服務器抹掉你的cookies或者ip什么的,嗯對沒錯,就是這樣>//>
延時后再加個隨機秒數就好了
def gen_random_sec(fix = 1):
a = random.random()
a = a + fix
return a
創建虛擬瀏覽器并獲取各類榜單的href
用selenium庫中的webdriver來創建
edge_driver = r"E:\venv\Lib\site-packages\selenium\webdriver\msedge\msedgedriver.exe"
# 需要把該路徑加到windows運行環境中
browser = webdriver.Edge(executable_path=edge_driver)
請求酷狗排行榜頁面
def get_category_rank(url='https://www.kugou.com/yy/html/rank.html'):
browser.get(url)
# 請求頁面,即瀏覽器打開該頁面
time.sleep(gen_random_sec())
print(gen_random_sec())
data = browser.page_source
# 獲取當前頁面的html組成元素
soup = BeautifulSoup(data, 'html.parser')
# 網頁帶有16進制,需解碼,soup就等于網頁的元素了,可以用來提取想要的資料
rank_group = soup.findAll('a',attrs={'hidefocus':'true'})
# 這里抓取的就是左邊的各類排行榜元素,attrs={}里面是他們的元素屬性
category_rank = []
for i, value in enumerate(rank_group):
# 收集所有類別榜單的href
category_rank.append(value.attrs['href'])
return category_rank
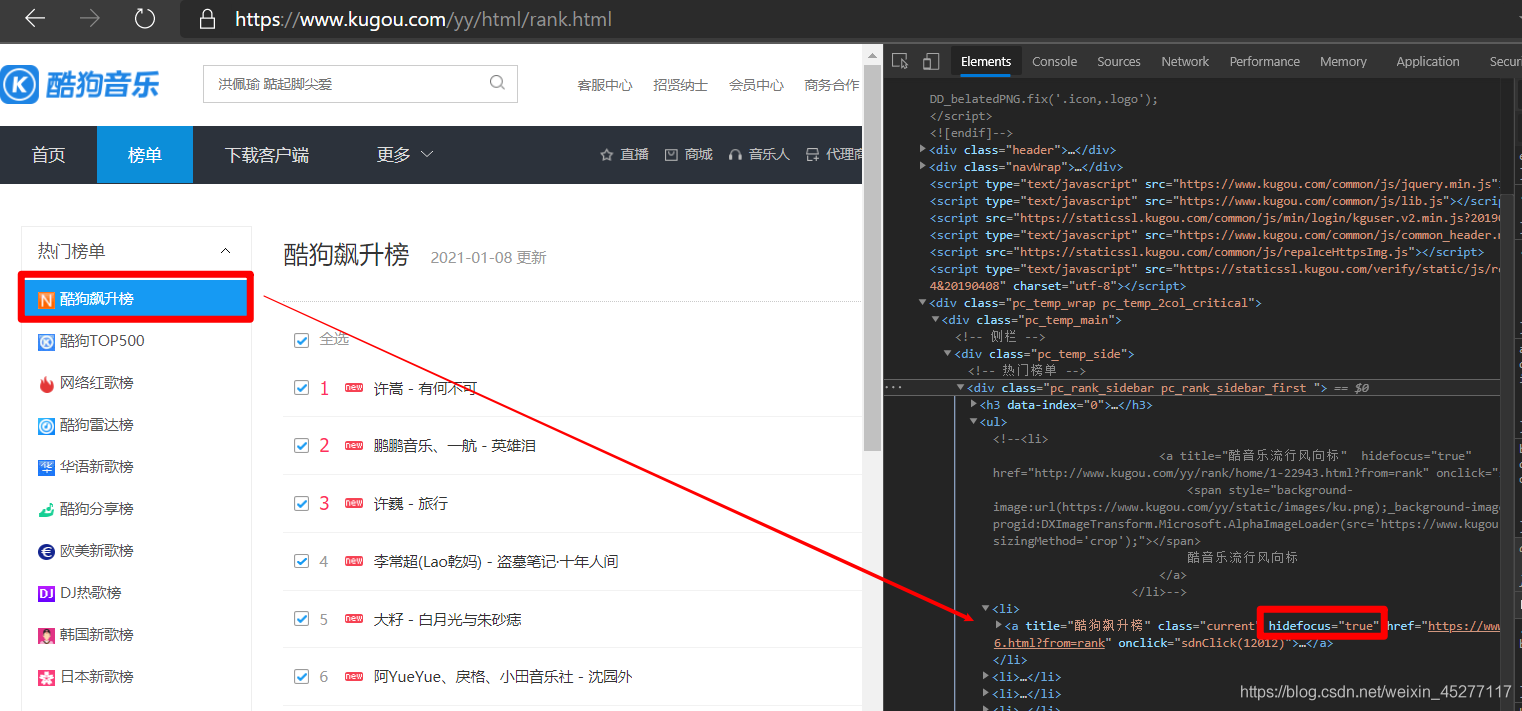
抓取各類排行榜的歌曲播放頁面href
這個直接根據attrs特征抓就完事了,上碼
def get_href_group(search_html):
browser.get(search_html)
time.sleep(gen_random_sec())
print(gen_random_sec())
data = browser.page_source
soup = BeautifulSoup(data, 'html.parser')
# 網頁帶有16進制,需解碼
href_list = soup.findAll('a', attrs="data-active=\"playDwn\"", class_="pc_temp_songname")
href_group = []
# 將歌曲播放頁面的href收集起來
for i, value in enumerate(href_list):
href_group.append(value.attrs['href'])
return href_group
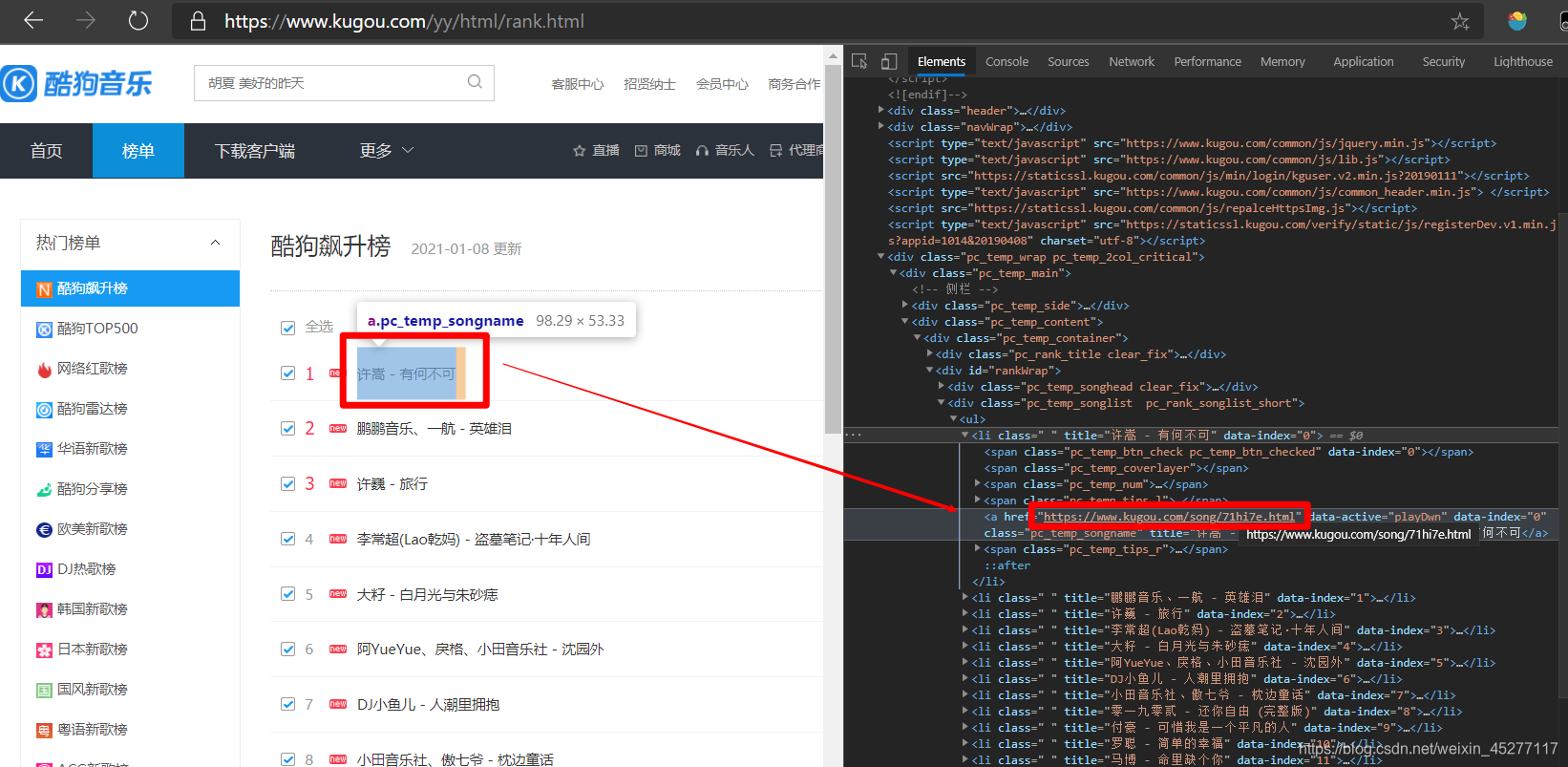
還有不知道怎么定位的小伙伴,點擊這個圖示之后再把你的滑鼠位置移到你想要定位的地方就可以自動定位到他的網頁元素組成部分
跳轉到歌曲播放頁面并提取引數項hash和album_id
def get_data_Url(href):
album_data = [0]
browser.get(href)
time.sleep(gen_random_sec())
a = browser.current_url
album_data = re.split("\.html#|&",a)
# ['', 'hash=AF2C86AE1836546B32778C18A2F37234', 'album_id=37515535']
album_data[0] = {"hash":album_data[-2],"album_id":album_data[-1]}
str1 = gen_random_str("int",19)
str2 = gen_random_str("int",13)
str3 = gen_random_str("mix",24)
str4 = gen_random_str("mix",32)
str5 = gen_random_str("int",13)
# str1,2,3,4,5都是之前說的引數項值(可隨機生成)
data_url = "https://wwwapi.kugou.com/yy/index.php?r=play/getdata&callback=jQuery"+str1+"_"+str2+"&"+album_data[0]['hash']+"&dfid="+str3+"&mid="+str4+"&platid=4&"+album_data[0]['album_id']+"&_="+str5+""
return data_url
有人就說,博主你不是說hash包含在href里面嗎,為什么不直接提取就好了,還要加一句browser.current_url來獲取當前網頁的url然后再提取hash,id,其實你可以仔細看看,你在上一步提取的href,跳轉過來等一會就變了,不信你看下面

—這是分割線—
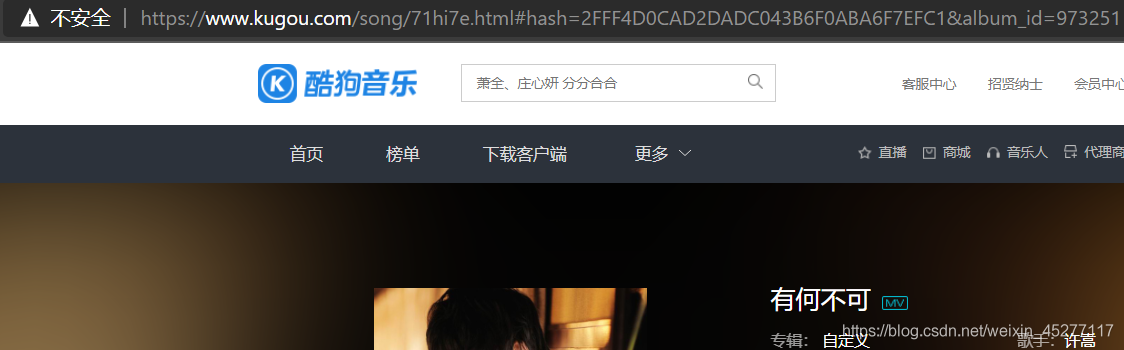
仔細看確實是不一樣的
提取資訊和下載的url
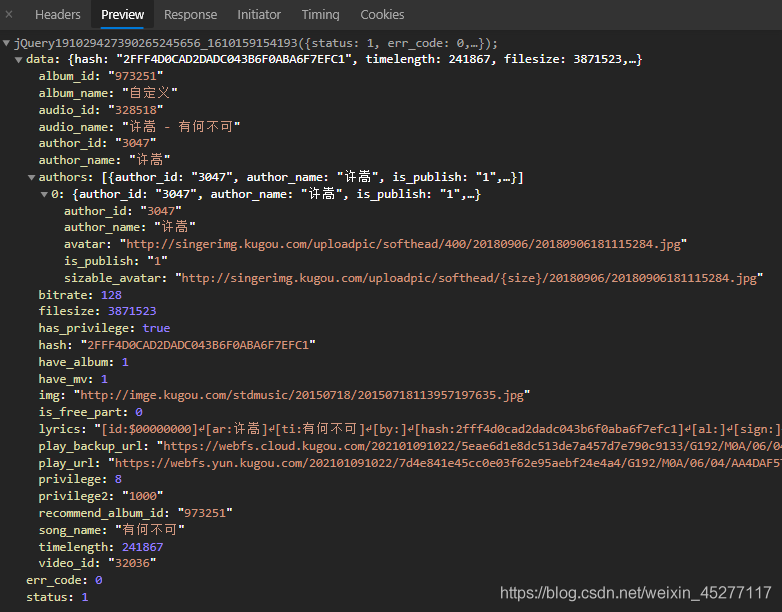
def get_playurl(data_url):
data = requests.get(data_url)
data = requests.get(data_url).text
a = re.split("\(|\)", data)
# 爬取回來的為response格式,需要用split提取其中json資料,然后再用json.loads(似憾訓會幫你解碼中文)將json轉化成字典
data_dict=json.loads(a[1])
play_url=data_dict['data']['play_url']
avatar=data_dict['data']['authors'][0]['avatar']
author_name=data_dict['data']['author_name']
audio_name=data_dict['data']['audio_name']
album_name=data_dict['data']['album_name']
song_name=data_dict['data']['song_name']
b={"play_url":play_url,"avator":avatar,"author_name":author_name,"audio_name":audio_name,"album_name":album_name,"song_name":song_name}
song_data.append(b)
json.loads可以幫我們把字符轉為字典(符合字典格式的字串),方便我們提取資料
下載至本地
def download(song_data):
for i in song_data:
FileName = FileRoot + '\\' + i['audio_name'] + '.mp3'
# 這個是你的保存路徑
DownloadUrl = i['play_url']
try:
with open(FileName, 'wb') as f:
f.write(requests.get(DownloadUrl).content)
# 此句作用等于下載網頁的內容,因為這是音頻流,所以等于直接下載音樂
#SetMp3Info(FileName, i)
print(i['audio_name']+'-----下載成功')
except:
print('該音頻無法正常下載---' + i['audio_name'] + ':' + DownloadUrl)
有人會好奇with open(FileName, ‘wb’) as f:中的wb代表什么,其實我一開始也不知道,只會用,后面我去查了下,才發現有一定的學問在里頭,具體看這,來自別人的blog

-----------------------------------------這是分割線---------------------------------------------
到此對酷狗的爬取就完結了,我誠摯感謝各位能人異士在各個網站上對我的幫助,程序中很多的報錯,很多的奇怪現象我都遇到過,有時候單靠我一人還真不知道從何下手,
在此給大家安利一個網站,以后你遇到什么莫名其妙的報錯,一般在這上面都可以找到你想要的答案
https://stackoverflow.com/
關于整篇的代碼,我已上傳,歡迎下載交流
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/246845.html
標籤:python
上一篇:【每日藍橋】1、一三年省賽JavaC組真題“猜年齡”
下一篇:人工AI — 神經網路構建初步