起點中文網月票榜爬取及資料分析
文章目錄
- 起點中文網月票榜爬取及資料分析
- 1. 資料爬取
- 1.1.1 準備
- 1.1.2 網頁分析
- 1.1.3 層次爬取
- 1.1.4 資料存盤
- 2. 資料分析及可視化
1. 資料爬取
資料爬取就是通過網路爬蟲程式來獲取需要的網站上的內容資訊,比如文字、視頻、圖片等資料,網路爬蟲(網頁蜘蛛)是一種按照一定的規則,自動的抓取萬維網資訊的程式或者腳本,一般是通過網頁的url獲取網頁的源代碼中,從源代碼中提取需要的資訊,
1.1.1 準備
運行cmd命令,通過 pip install +庫名 或者pip3 install +庫名,安裝好需要的庫,做好準備后即可開始爬取操作,
需要爬取的網頁為 https://www.qidian.com/rank/yuepiao?style=2
1.1.2 網頁分析
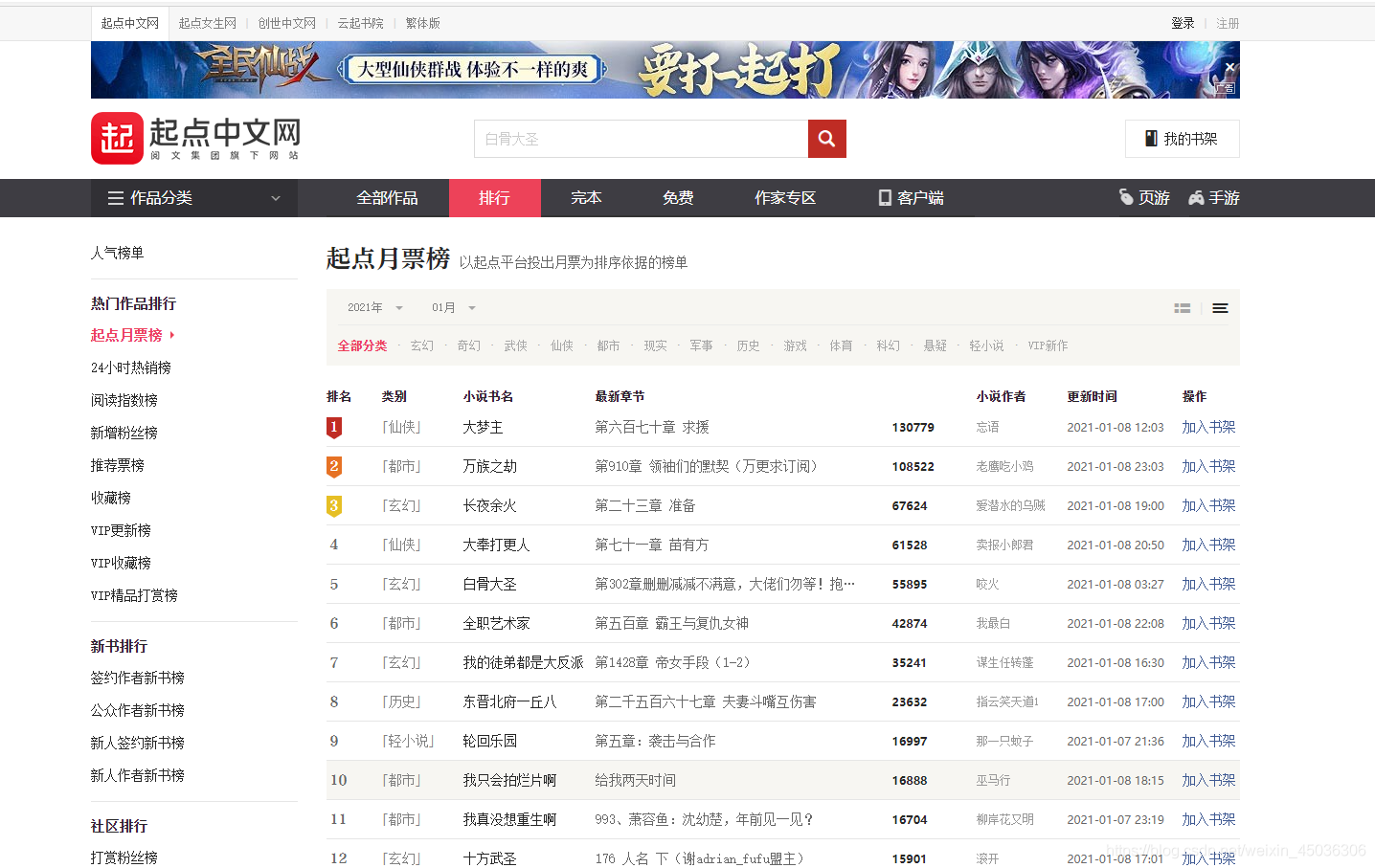
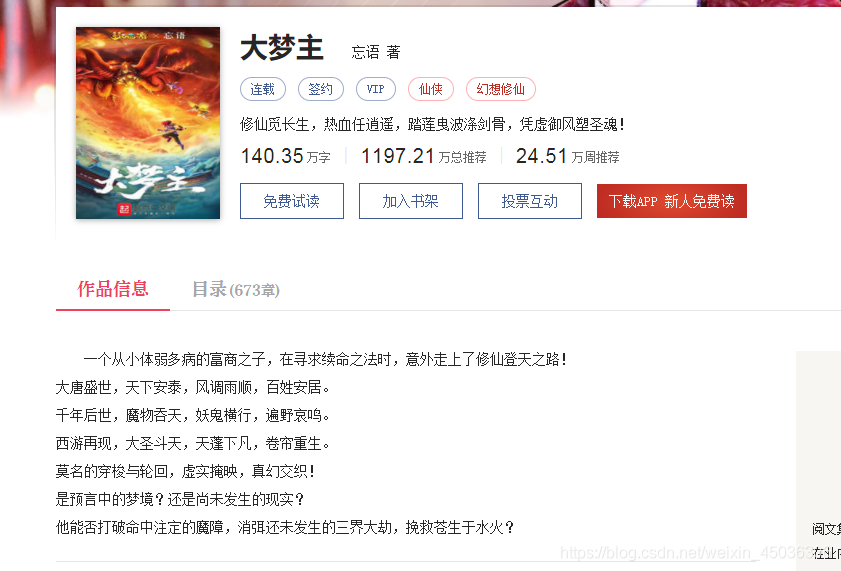
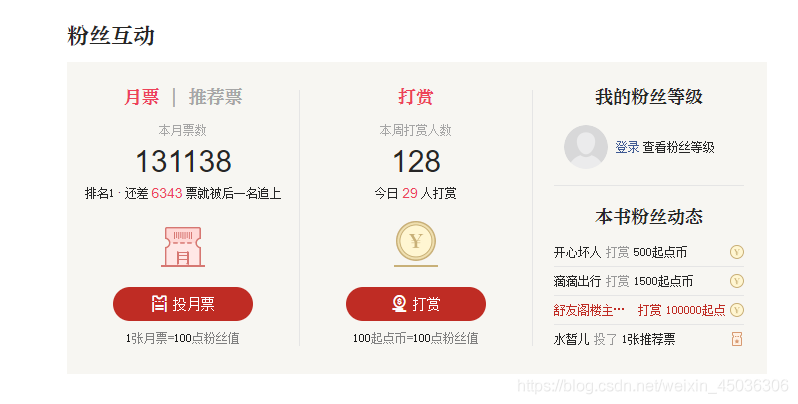
由上圖可知,該榜中需要的爬取的有用資訊為類名、書名、最新章節、月票數、小說作者、更新的時間、小說簡介以及周票數和打賞人數,
1.1.3 層次爬取
html=requests.get(url)
#爬取月票的html檔案
html.encoding='UTF-8'
#該網頁的編碼格式為UTF-8
doc=BeautifulSoup(html.text,'lxml')
#轉換為BeautifulSoup物件
排行榜總共有兩頁,先得到頁數,方便后續的訪問,先得到前50名上榜書籍,排行榜上能夠獲取到的資訊:

page=doc.find('div',class_="pagination fr")['data-pagemax']
#獲取網頁最大頁碼
list1=doc.find('table',class_='rank-table-list hot-new').find('tbody').find_all('tr')
#找出每款書在該頁面的資訊塊
for x in list1:
#通過回圈對每款書的資訊進行提取
name=x.find('a',class_='name').text.strip()
#取出書名
#strip() 方法用于移除字串頭尾指定的字符(默認為空格或換行符)或字符序列,
infrom='https:'+x.find('a',class_='name')['href']
#規范url格式,方便進行下一步的深度爬取
author=x.find('a',class_='author').text.strip()
#爬取作者
booktype=x.find('a',class_='type').text.strip()
#文本分類
month=x.find(class_='month').text
#月票數量
time=x.find(class_='time').text
#上傳日期
new=x.find('a',class_='chapter').text
#最新章節名稱
然后爬取每本上榜作品的詳細資訊
html1=requests.get(infrom)
#爬取第二層的html檔案
html1.encoding='UTF-8'
#該網頁的編碼格式為UTF-8
doc1=BeautifulSoup(html1.text,'lxml')
list1 = doc1.find('div',class_="book-intro")
bookIntrodaction = list1.find("p").text.strip()
#獲取小說簡介
listt2=doc1.find(class_="fans-interact cf")
monthTickets=listt2.find(class_ ='ticket month-ticket').find(class_ = 'num').text
#小說月票
weekTickets=listt2.find(class_ ='ticket rec-ticket hidden').find(class_ = 'num').text
#小說周票
people=listt2.find(class_= 'rewardNum').text
#小說本周打賞人數
經過以上操作后前50名的資訊就獲取成功了!!
1.1.4 資料存盤
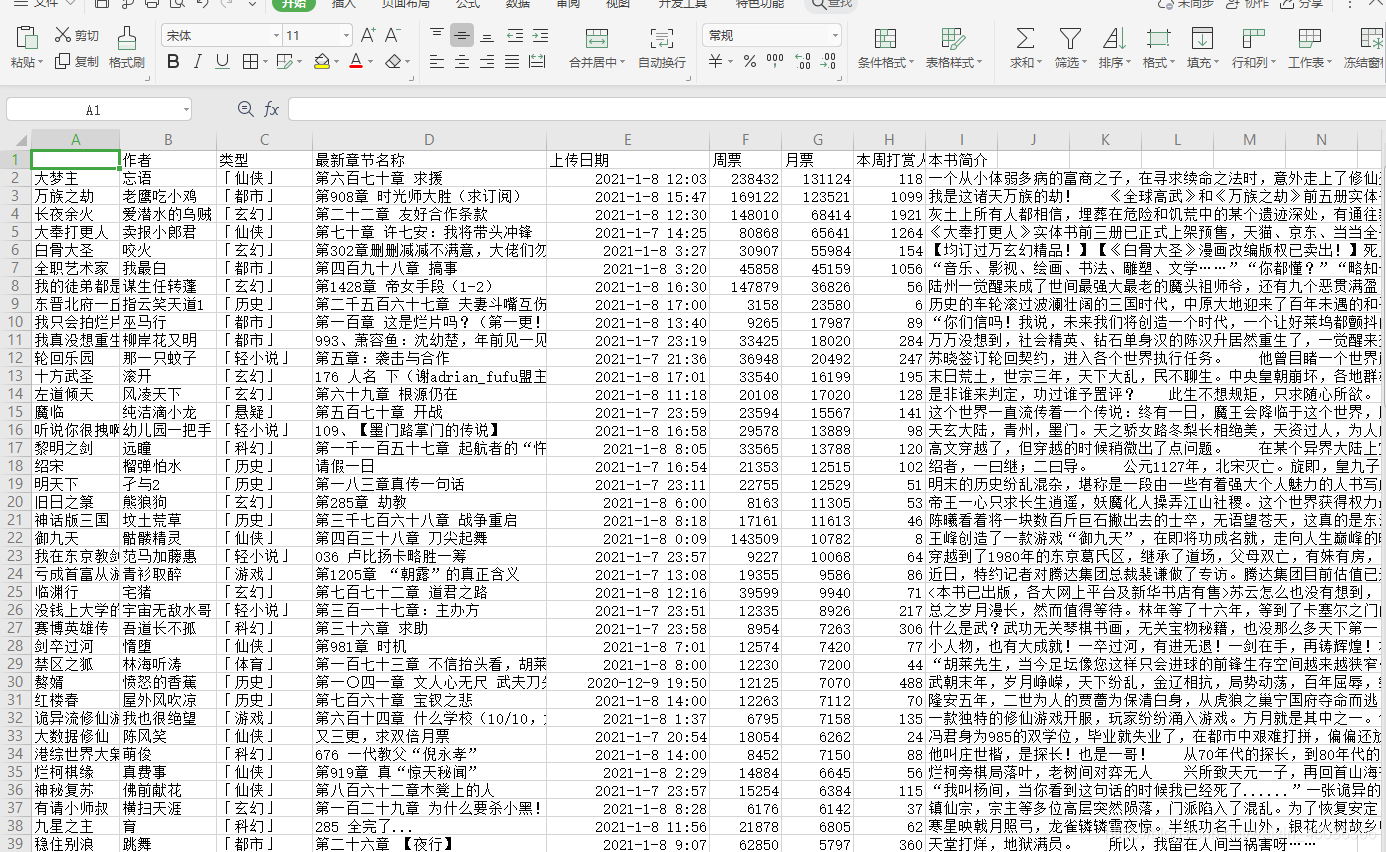
將爬取到的資訊存入到csv檔案中,方便后續的可視化分析,
file_exists = os.path.isfile('bookRooking.csv')
#判斷是否為檔案
with open('bookRooking.csv','a',encoding='utf-8',newline='') as f:
#newline = "" 表示讀取的換行符保持不變,原來是啥,讀出來還是啥
headers=data.keys()
#找出data的所有的鍵
w =csv.DictWriter(f,delimiter=',',lineterminator='\n',fieldnames=headers)
#創建一個物件
if not file_exists :
w.writeheader()
#第一次寫入資料先寫入表頭
w.writerow(data)
#單行寫入
print('當前行寫入csv成功!')
此處判斷是否為檔案,能夠有效的防止后面輸出的表頭不會重復,只有非表頭的情況可以寫入,
2. 資料分析及可視化
利用csv檔案對每個型別書籍的周票均值、月票均值、總共的打賞值繪制折線圖,可以一眼出周票、月票、以及打賞最多的型別的書籍,
plt.rcParams['font.sans-serif'] = ['SimHei']
#解決橫坐標不能顯示中文的況
plt.rcParams['axes.unicode_minus'] = False
#解決橫坐標不能顯示中文的情況
y1 = data.groupby('型別').sum()['本周打賞人數']
#求和
y2 = data.groupby('型別').mean()['周票']
#求平均值
y3 = data.groupby('型別').mean()['月票']
#求平均值
x=list(dict(y1).keys())
#橫坐標值
fig = plt.figure(figsize=(8,6), dpi=100)
#指定畫布大小
plt.plot(x,y1,c='red',label='打賞票和')
#指定折線的顏色和標簽
plt.plot(x,y2,c='yellow',label='周票均值')
plt.plot(x,y3,c='blue',label='月票均值')
plt.legend(loc='upper left')#標簽靠左
plt.title("小說票數折線圖")#圖名
plt.xlabel('小說型別',fontsize=15)
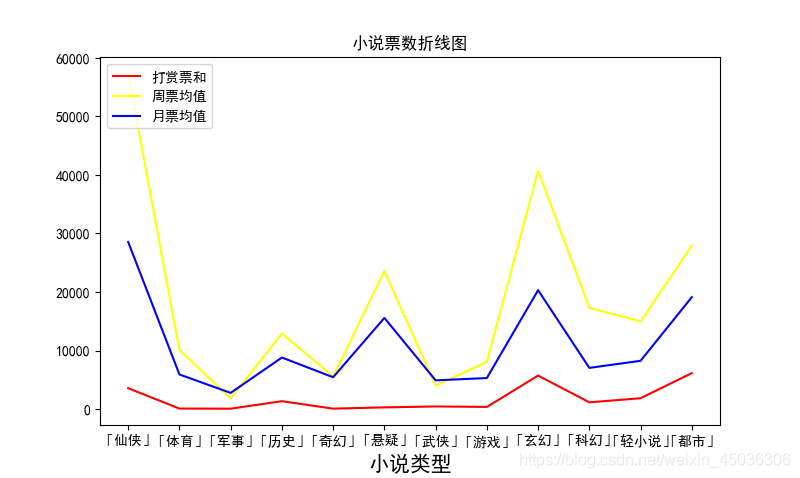
由上圖可以得知仙俠型別的書籍得到的周票和月票均值是最高的其次是玄幻型別的,且玄幻得到打賞的票數最多,軍事型別的書籍較少,
利用柱狀圖能夠的出項成績的具體資料,
plt.rcParams['figure.figsize']=(8,3)#圖形大小
data.groupby(['型別']).mean().plot(kind = 'bar')
plt.xticks(rotation=0)#橫坐標的角度
plt.ylabel('總票數',fontsize = 15)#縱坐標名
plt.xlabel('小說型別',fontsize = 15)#橫坐標名
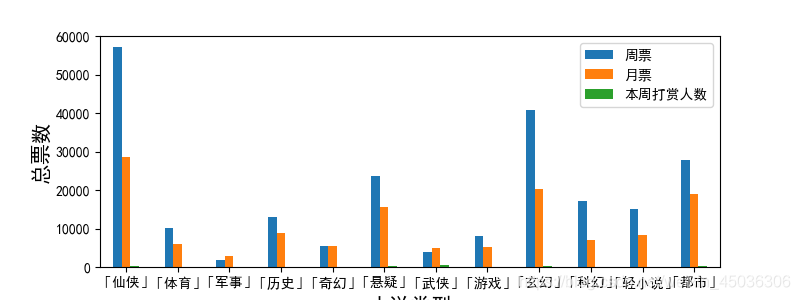
可以看出一周中給出打賞的人占極少數,月票甚至比周榜的人數還少,
通過餅狀圖可以看清楚在整體中所占的比重,
sizes = []
for booktype in x:#x是上文折線圖中橫坐標,即小說所有的型別,
bookTypeNum=len(data[data['型別']==booktype])#獲取各種小說的數量
sizes.append(bookTypeNum)
plt.figure(figsize=(20,20)) #調節圖形大小
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.pie(
sizes,
labels=x,#指定顯示的標簽
autopct='%1.1f%%'#資料保留固定小數位
)
plt.axis('equal')# x,y軸刻度設定一致#本文中可以不用
plt.title('小說型別受歡迎的分布圖比')
plt.legend(loc='upper left')# 左上角顯示
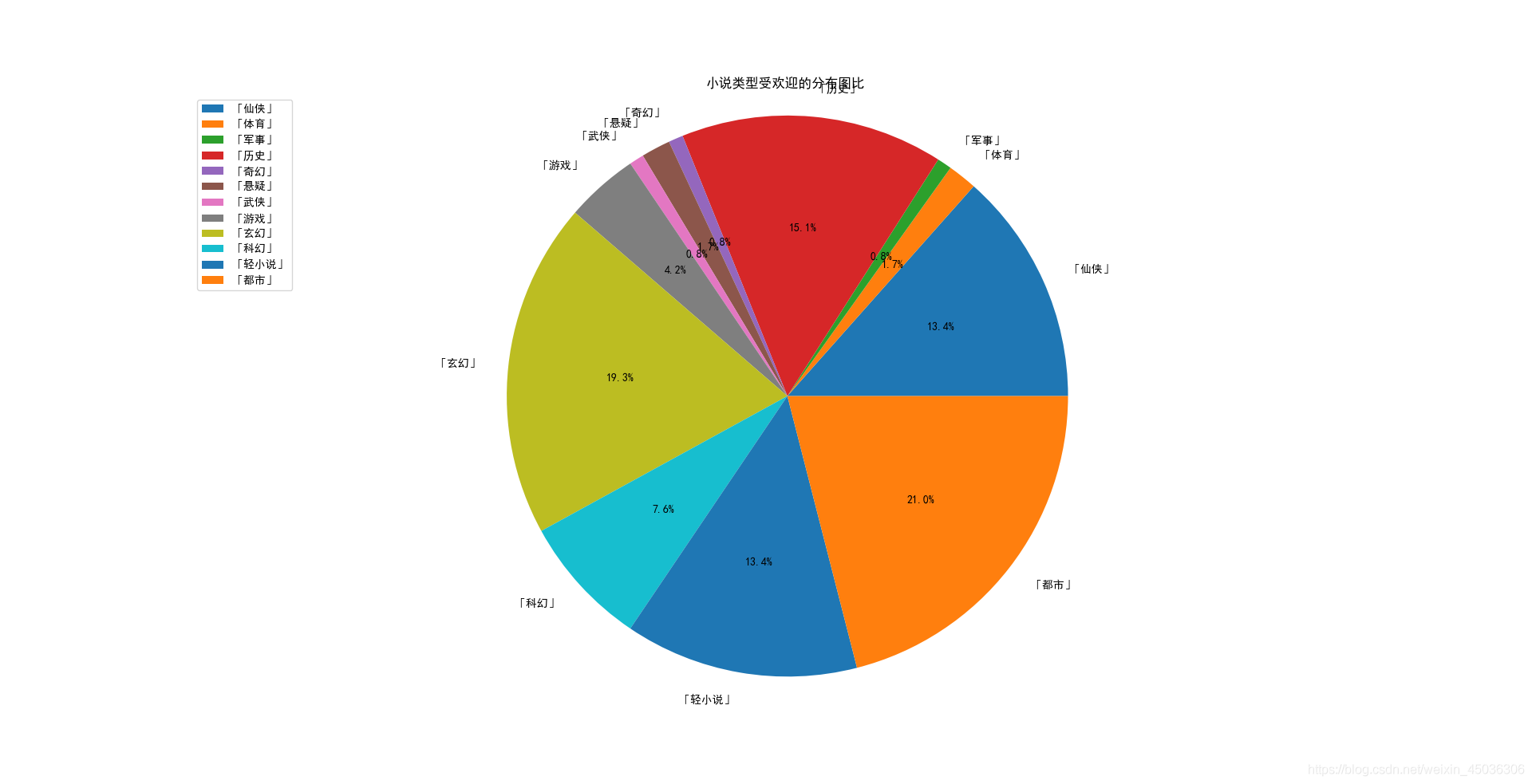
由此可以玄幻和都市型別的小說是現在網路小說最受歡迎的型別,兩種占據了40%的比重,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/246847.html
標籤:python
上一篇:人工AI — 神經網路構建初步