分布式高級篇(一)ElasticSearch和商城首頁
ElasticSearch--全文檢索
簡介
是什么
- ElasticSearch是一個分布式的開源搜索和分析引擎,適用于所有型別的資料,包括文本、數字、地理空間、結構化和非結構化資料
- ElasticSearch在Apache Lucene的基礎上開發而成,由Elastic于2010年首次發布,ElasticSearch以其簡單的REST風格API、分布式特性、速度和可擴展而聞名
用途
- ElasticSearch在速度和可擴展性方面都表現出色,而且還能夠索引多種型別的內容,這意味著其可用于多種用例:
- 應用程式搜索
- 網站搜索
- 企業搜索
- 日志處理和分析
- 基礎設施指標和容器監測
- 應用程式性能監測
- 地理空間資料分析和可視化
- 安全分析
- 業務分析
基本概念
-
關系圖
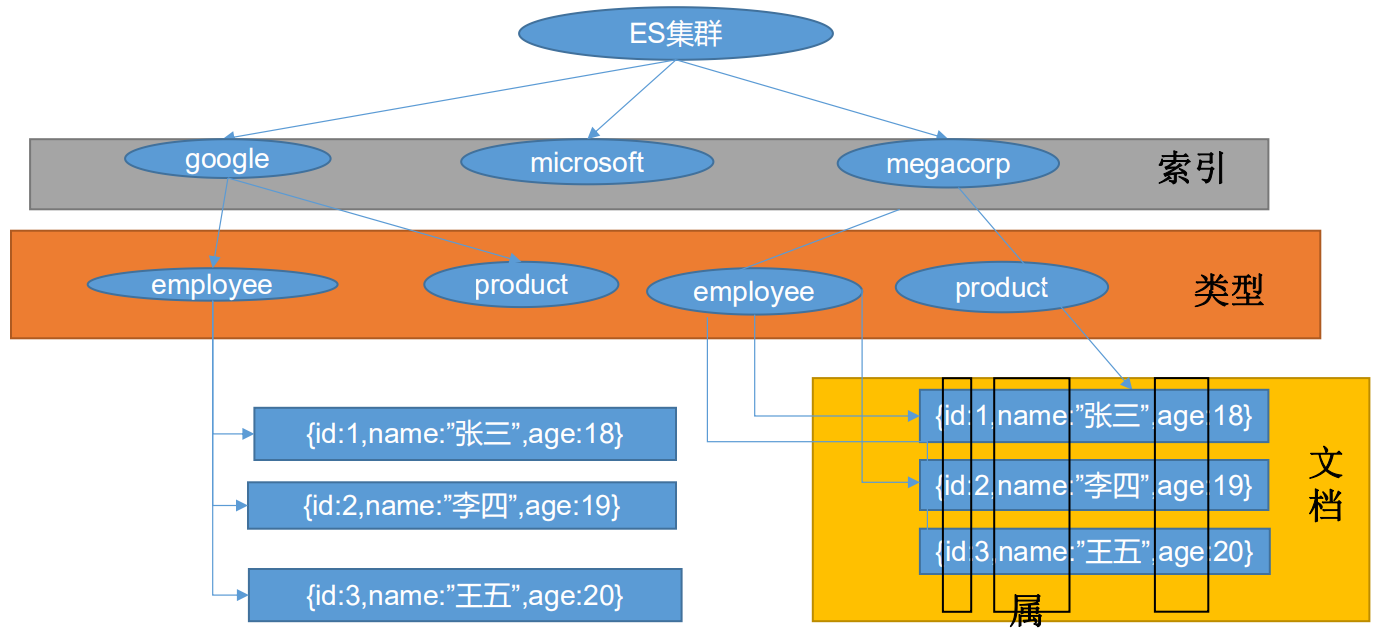
Index(索引)
-
動詞,相當于MySQL中的insert;mysql中插入(insert)一條資料,ES中索引一條資料
-
名詞,相當于MySQL中的DataBase
Type(型別)
- 在index(索引)中,可以定義一個或多個型別,類似于MySQL中的Table;每一種型別的資料放在一起
ElasticSearch7-去掉type概念
-
關系型資料庫中兩個資料表示是獨立的,即使他們里面有相同名稱的列也不影響使用但ES中不是這樣的而ES中不同type下名稱相同的filed最終在Lucene中的處理方式是一樣的
-
兩個不同type下的兩個user_name,在ES同一個索引下其實被認為是同一個filed,你必須在兩個不同的type中定義相同的filed映射,否則,不同type中的相同欄位名稱就會在處理中出現沖突的情況,導致Lucene處理效率下降
-
去掉type就是為了提高ES處理資料的效率
-
Elasticsearch 7.x
URL中的type引數為可選,比如,索引一個檔案不再要求提供檔案型別
-
Elasticsearch 8.x
不再支持URL中的type引數,解決:將索引從多型別遷移到單型別,每種型別檔案一個獨立索引
Document(檔案)
- 保存在某個索引(index)下,某種型別(Type)的一個資料(Document),檔案是JSON格式的,Document就像是MySQL中的某個Table中的記錄
倒排索引機制
-
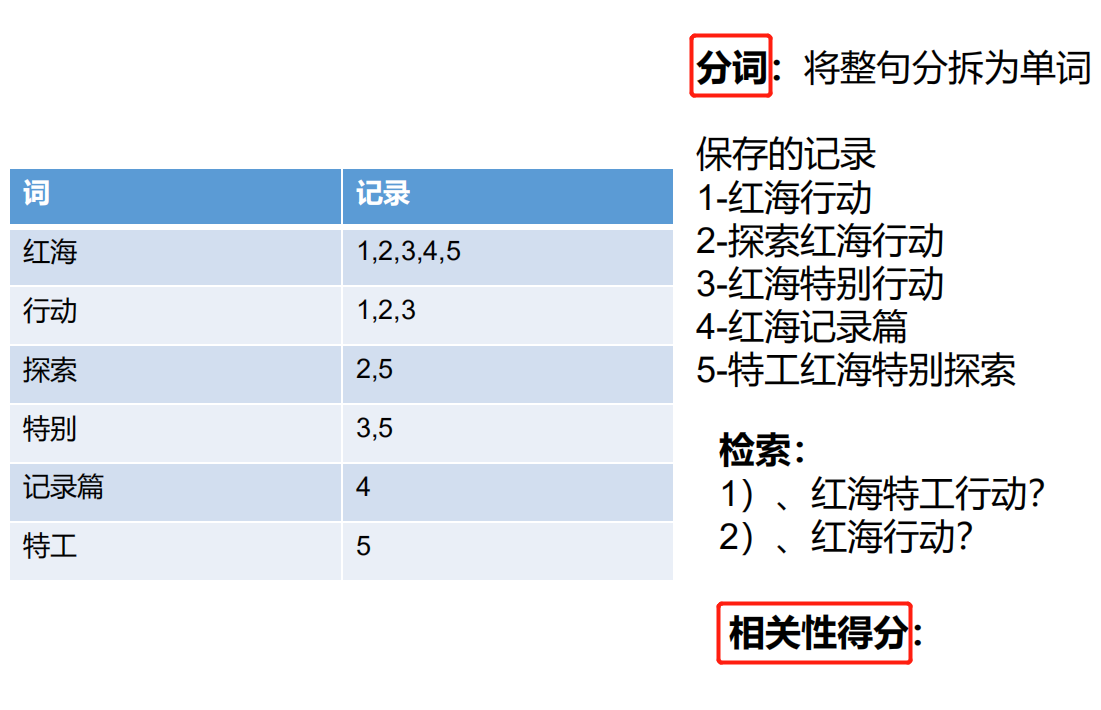
舉個簡單例子
-
在MySQL中保存一個資料:正向索引,每一條資料都有一個id對應著;這時如果想要檢索一個資料,比如電影表中檢索 紅海行動
like 紅海行動 這時候MySQL會匹配所有記錄,看是否有紅海行動,這種檢索顯然是非常慢的操作
-
而在ES中,在存盤資料的時候,同時會維護一張倒排索引表
怎么維護:在存盤資料時,首先會進行分詞:將整句分拆成單詞,比如 紅海行動 拆分成 紅海、行動、紅、海...... 這時候 ES中的1號檔案記錄的是紅海行動,同時倒排索引也維護了 紅海、行動 出現在1號檔案中
-
相關性得分:命中的分詞個數越多,分越高
-
Docker安裝
安裝ElasticSearch 7.6.1
-
拉取鏡像
docker pull elasticsearch:7.6.1 -
運行容器并掛載
-
啟動容器
docker run -d --name es -p 9200:9200 -p 9300:9300 \ -e "discovery.type=single-node" elasticsearch:7.6.1 -
將組態檔、資料目錄、插件目錄拷出來做掛載
docker cp es:/usr/share/elasticsearch/config/ /var/touchAirMallVolume/es/config/ docker cp es:/usr/share/elasticsearch/data/ /var/touchAirMallVolume/es/data/ docker cp es:/usr/share/elasticsearch/plugins/ /var/touchAirMallVolume/es/plugins/ vim /var/touchAirMallVolume/es/config/elasticsearch.yml #添加這2行 #設定允許跨域訪問 http.cors.enabled: true http.cors.allow-origin: "*" -
銷毀容器,重新以掛載方式運行
注意:ES默認記憶體需要2g,虛擬機記憶體不足的需要設定 ES_JAVA_OPTS,否則會卡死
#銷毀 docker rm -f es #掛載組態檔 docker run -d --name es -p 9200:9200 -p 9300:9300 -v /var/touchAirMallVolume/es/config:/usr/share/elasticsearch/config \ -v /var/touchAirMallVolume/es/data:/usr/share/elasticsearch/data \ -v /var/touchAirMallVolume/es/plugins:/usr/share/elasticsearch/plugins \ -e "discovery.type=single-node" \ --restart=always elasticsearch:7.6.1
-
-
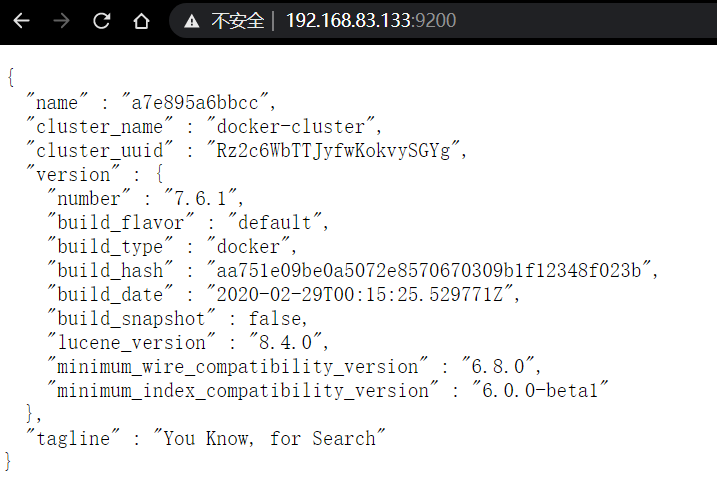
訪問宿主機ip的9200埠,查看是否啟動成功
安裝Kibana 7.6.1
- ES的可視化工具 版本要對應
拉取鏡像
docker pull kibana:7.6.1
運行容器
-
先運行容器
docker run -d --name kibana -p 5601:5601 kibana:7.6.1 -
拷出組態檔,后面做掛載
# 拷貝 docker cp kibana:/usr/share/kibana/config/ /var/touchAirMallVolume/kibana/config/ #修改配置 vim kibana.yml #放開訪問地址 0.0.0.0 #配置es地址 http://192.168.83.133:9200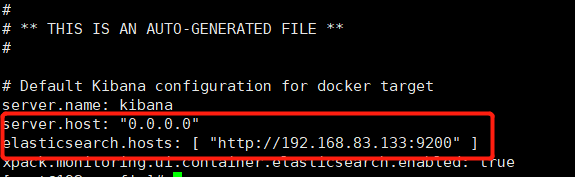
-
掛載運行
# 先銷毀容器 docker rm -f kibana # 運行容器 docker run -d --name kibana \ -p 5601:5601 --restart=always \ -v /var/touchAirMallVolume/kibana/config:/usr/share/kibana/config \ kibana:7.6.1 -
宿主機ip:5601,查看kibana圖形化界面
初步檢索
_cat
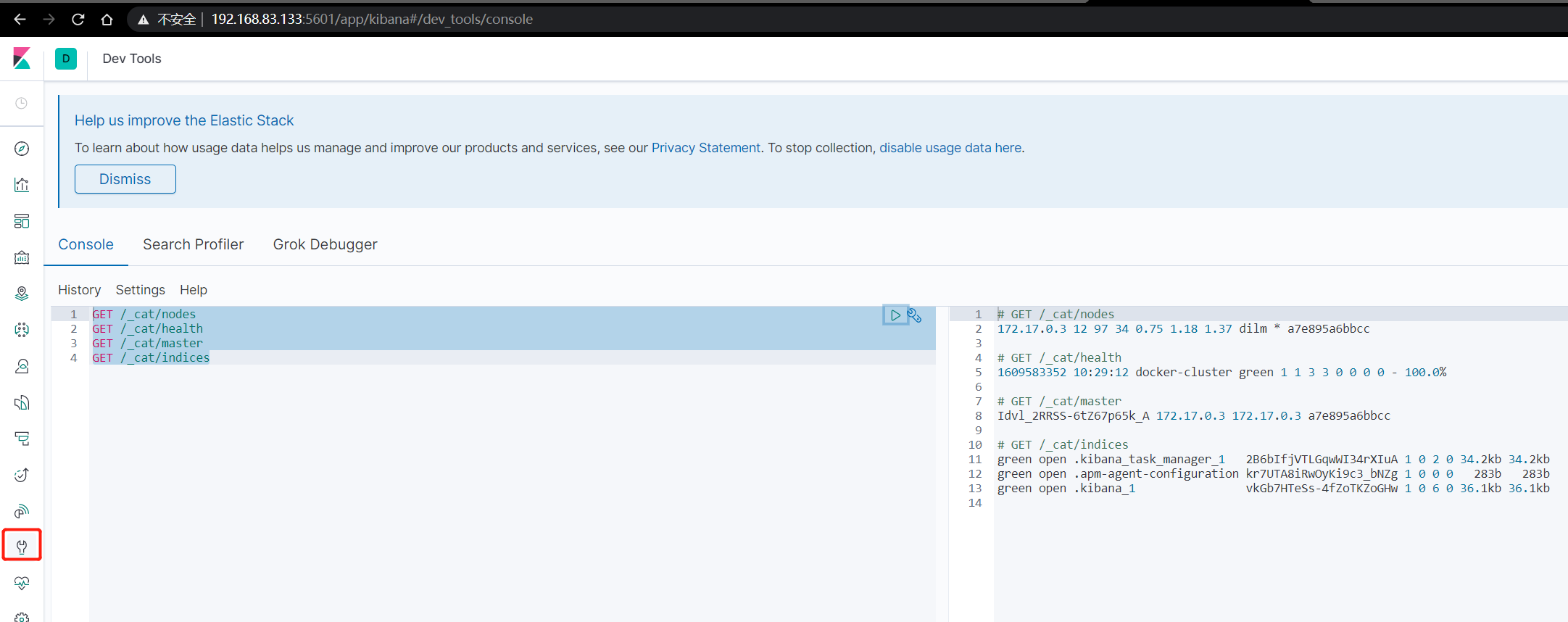
-
GET /_cat/nodes 查看所有節點
-
GET /_cat/health 查看es健康狀況
-
GET /_cat/master 查看主節點
-
GET /_cat/indices 查看所有索引 類似 show databases;
索引一個檔案(保存)
-
保存一個資料,保存在哪個索引的哪個型別下,指定用哪個唯一標識
PUT customer/external/1 { "name":"touchair" } #發送多次是一個更新操作
PUT和POST都可以
POST 新增:如果不指定id,會自動生成id,指定id就回去修改這個資料,并新增版本號
PUT 可以新增可以修改:PUT必須指定id,不指定會報錯,由于PUT需要指定id,一般用來做修改操作
查詢檔案
-
查詢剛剛新增的資料
GET customer/external/1

更新檔案
-
更新
POST customer/external/1/_update { "doc":{ "name":"touchair2" } } #或者 POST customer/external/1 { "name":"touchair3" } #或者 PUT customer/external/1 { "name":"touchair4" } -
區別:
? PUT操作總會將資料重新保存并增加version版本;
? POST操作 帶_update對比源資料如果一樣就不進行任何操作,檔案version不增加
? POST操作 不帶_update 就不會檢查源資料,始終更新
- 看場景
- 對于大并發更新,不帶update
- 對于大并發查詢偶爾更新,帶update;對比更新,重新計算分配規則
- 看場景
-
更新同時增加屬性
注意 帶_update 需要帶 doc 寫法
POST customer/external/1/_update { "doc":{ "name":"post_add_condition", "age":20 } }
洗掉檔案&索引
-
洗掉檔案
DELETE customer/external/1 -
洗掉索引
DELETE customer
bulk批量API
-
批量
POST customer/external/_bulk {"index":{"_id":3}} {"name":"奮斗逼"} {"index":{"_id":4}} {"name":"你他媽卷到我了"}#語法格式: #action 指定要操作的源資料 {action:{metadata}} \n {request body } \n {action:{metadata}} \n {request body } \n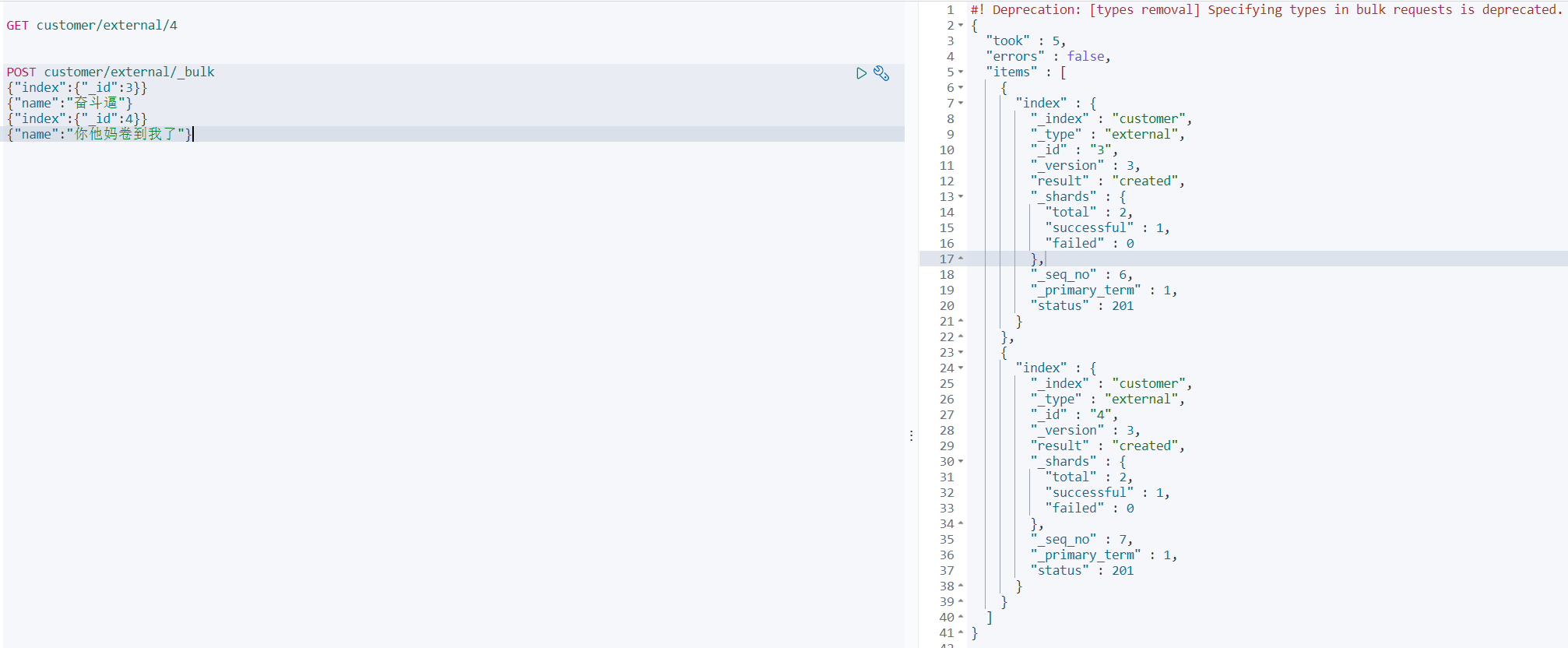
-
復雜實體
POST /_bulk {"delete":{"_index":"website","_type":"blog","_id":"123"}} {"create":{"_index":"website","_type":"blog","_id":"123"}} {"title":"My first blog post"} {"index":{"_index":"website","_type":"blog"}} {"title":"My second blog post"} {"update":{"_index":"website","_type":"blog","_id":"123","_retry_on_conflict":3}} {"doc":{"title":"My updated blog post"}}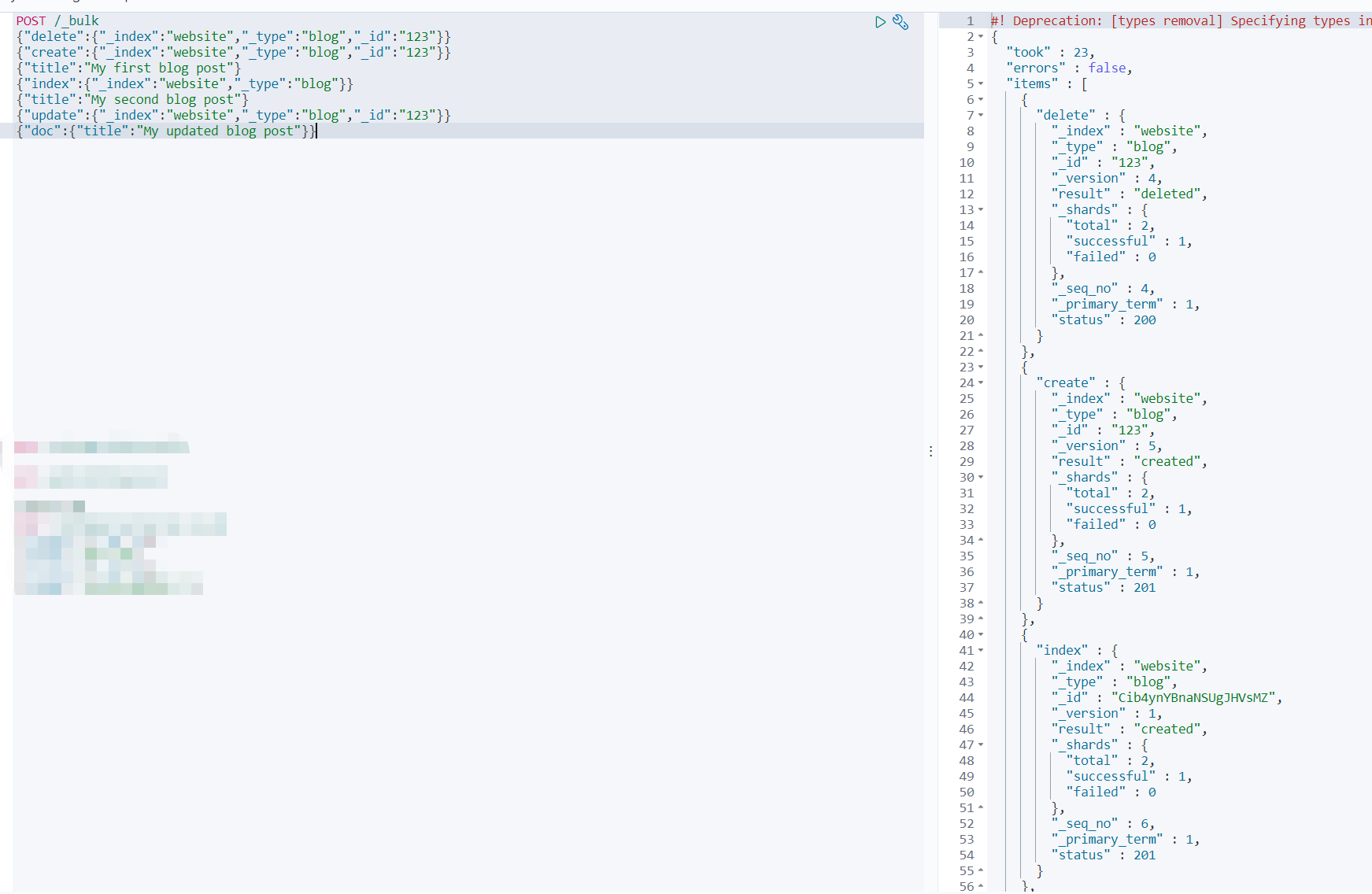
-
bulk API 以此順序執行所有的action(動作),如果一個單個的動作因任何原因而失敗,它將繼續處理后面剩余的動作,當bulk API回傳時,它將提供每個動作的狀態(與發送的順序相同),所以您可以檢查是否一個指定的動作是不是失敗了
樣本測驗資料
-
es官方提供的樣本資料地址
POST bank/accout/_bulk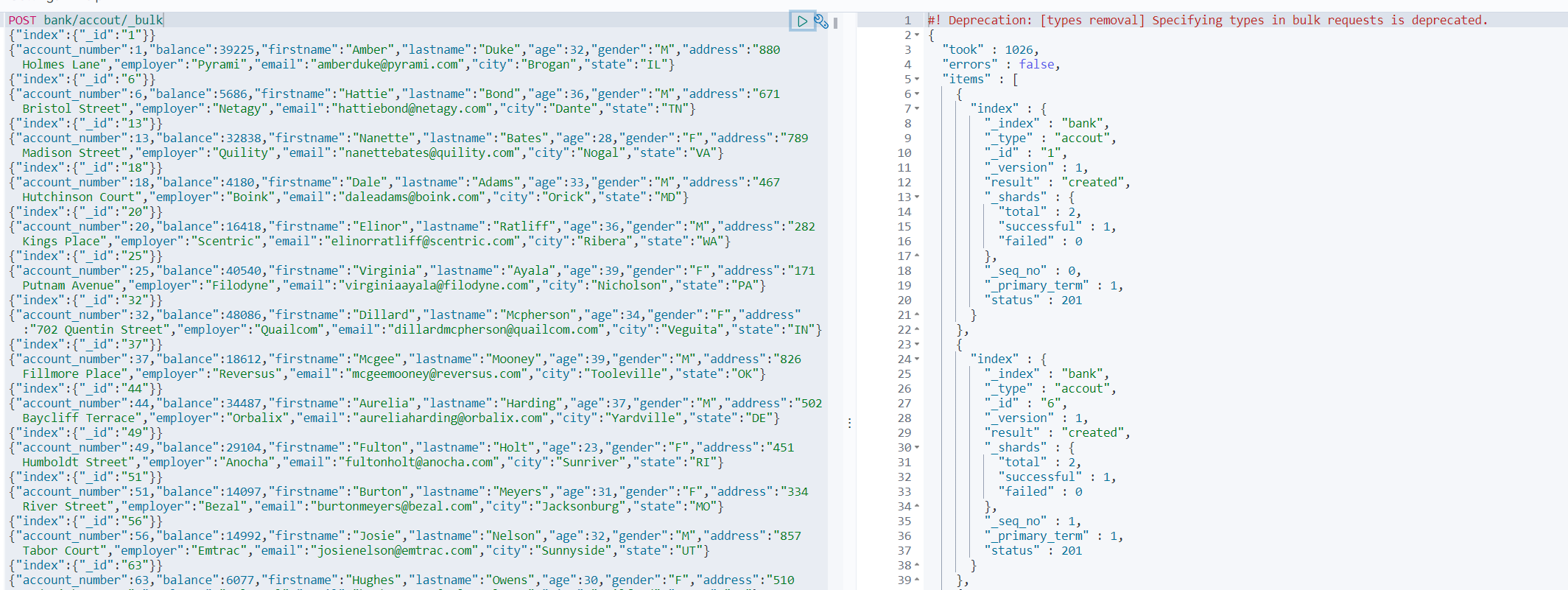

進階檢索
- 完全參照官方實體
Search API
- ES支持兩種基本方式檢索
- 一個是通過使用REST request URI 發送搜索引數(uri+檢索引數)
- 另一個是通過使用 REST request body 來發送它們(uri+請求體)
檢索資訊
-
請求檢索按帳號排序的銀行索引中的所有檔案
GET /bank/_search { "query": { "match_all": {} }, "sort": [ { "account_number": "asc" } ] }默認情況下,回應的命中部分包含與搜索條件匹配的前10個檔案
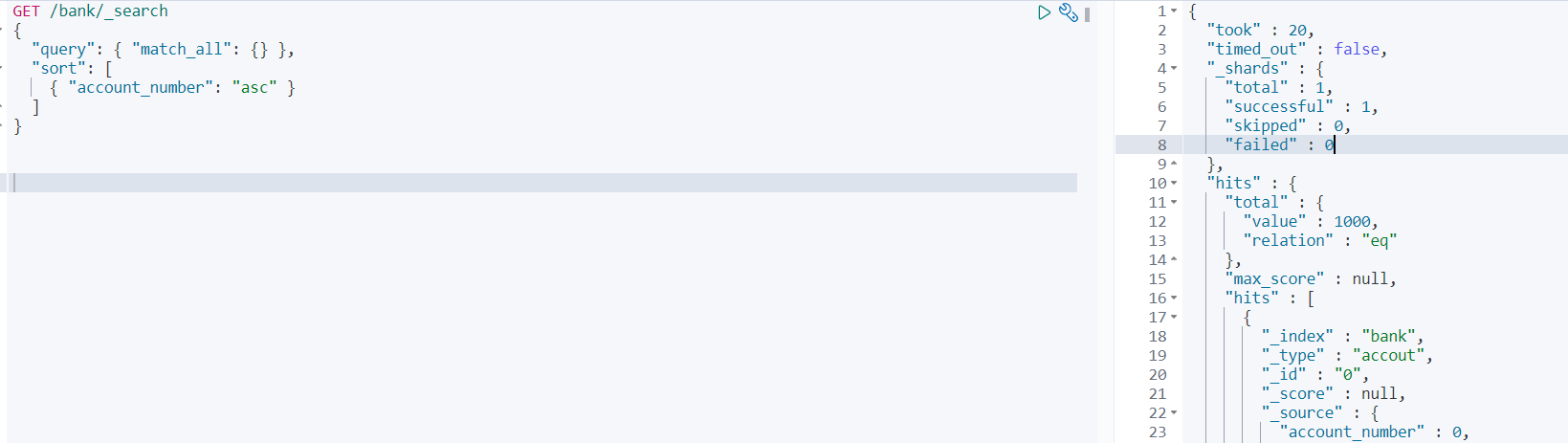
took:Elasticsearch 運行查詢需要多長時間(毫秒)timed_out:搜尋請求是否超時_shards:搜索了多少碎片,并分別列出成功、失敗或跳過的碎片數量max_score:找到的最相關檔案的分數hits.total.value:找到多少相符的檔案hits.sort:檔案的排序位置(當不按相關性得分排序時)hits._score:檔案的相關性得分(不適用于使用match_all)
-
每個搜索請求都是自包含的: Elasticsearch 不維護跨請求的任何狀態資訊,若要瀏覽搜索結果,請在請求中指定 from 和 size 引數
下面的請求會得到從10到19的結果
GET /bank/_search { "query": { "match_all": {} }, "sort": [ { "account_number": "asc" } ], "from": 10, "size": 10 }
Query DSL
基本語法格式
- ElasticSearch提供了一個可以執行查詢的json風格的DSL(domain-specific language 領域特點語言),這個被稱為Query DSL,該查詢語言非常全面,并且剛開始的時候感覺有點復雜,真正學好它的方法是從一些基礎的示例開始的
match(匹配查詢)
-
基本型別(非字串),精確匹配
GET /bank/_search { "query": { "match": { "account_number": 20 } } } -
字串,全文檢索
全文檢索按照評分進行排序,會對檢索條件進行分詞匹配
GET /bank/_search { "query": { "match": { "address": "Kings" } } }
match_phrase(短語匹配)
-
將需要匹配的值當成一個整體單詞(不分詞)進行檢索
GET /bank/_search { "query": { "match_phrase": { "address": "282 Kings" } } }
multi_match(多欄位匹配)
-
state 或者 address 包含 mill
GET /bank/_search { "query": { "multi_match": { "query": "mill", "fields": ["address","state"] } } }
bool(復合查詢)
-
bool用來做復合查詢:復合陳述句可以合并任何其它查詢陳述句,包括復合陳述句,了解這一點很重要,這就意味著,復合陳述句之間可以互相嵌套,可以表達非常復雜的邏輯
must:必須達到must列舉的所有條件must_not:必須排除must_not列舉的所有條件should:應該滿足 當然也可以不滿足
GET /_search { "query": { "bool": { "must": [ { "match": { "gender": "M" }}, { "match": { "address": "mill" }} ], "must_not": [ {"match": { "age": "28" }} ], "should": [ {"match": { "lastname": "Wallace" }} ] } } }
filter(結果過濾)
-
相關性得分是一個正浮點數,回傳到搜索 API 的 _ score 元欄位中,得分越高,檔案越相關,雖然每種查詢型別可以以不同的方式計算相關性分數,但分數計算還取決于查詢子句是在查詢中運行還是在過濾背景關系中運行
-
并不是所有的查詢都需要產生分數,特別是那些僅用于
filtering(過濾)的檔案,為了不計算分數ElasticSearch會自動檢查場景并且優化查詢的執行 -
must、should只有滿足條件,就會對對相關性得分提升,must_not則會被當成filter,fliter最大的一個特點就是不會對檔案的相關性得分產生影響 -
比較,主要觀察結果中的
_score#must GET bank/_search { "query": { "bool": { "must": [ {"range": { "age": { "gte": 18, "lte": 30 } }} ] } } } #filter GET bank/_search { "query": { "bool": { "filter": [ {"range": { "age": { "gte": 18, "lte": 30 } }} ] } } }
term(精確查找)
-
和match一樣,匹配某個屬性的值,全文檢索欄位用match,其他非text欄位匹配用term
GET bank/_search { "query": { "term": { "balance": "18607" } } } #加上keyword 進行精確匹配(不會進行分詞) GET bank/_search { "query": { "match": { "address.keyword": "789 Madision" } } } GET bank/_search { "query": { "match": { "address": "789 Madision" } } }
aggregation(執行聚合)
-
聚合提供了從資料中分組和提取資料的能力,最簡單的聚合方法大致等于SQL GROUP BY和SQL聚合函式,在ElasticSearch中,有執行搜索回傳
hits(命中結果),并且同時回傳聚合結果,把一個回應中的所有hits(命中結果)分隔開的能力,這是非常強大且有效的,可以執行查詢和多個聚合,并且在一次使用中得到各自的(任何一個的)回傳結果,使用一個簡潔和簡化的API來避免網路往返 -
搜索
address中包含mill的所有人的年齡分布以及平均年齡,但不顯示這些人的詳情GET bank/_search { "query": { "match": { "address": "mill" } }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 10 } }, "ageAvg":{ "avg": { "field": "age" } } }, "size": 0 } -
復雜聚合
-
按照年齡聚合,并且請求這些年齡段的這些人的平均薪資
(子聚合)
GET bank/_search { "query": { "match_all": {} }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 100 }, "aggs": { "ageAvg": { "avg": { "field": "balance" } } } } }, "size": 0 }-
查出所有年齡分布,并且這些年齡段中M的平均薪資和F的平均薪資以及這個年齡段的總體平均薪資
GET bank/_search { "query": { "match_all": {} }, "aggs": { "ageAgg": { "terms": { "field": "age", "size": 100 }, "aggs": { "fAvg": { "avg": { "field": "balance" } }, "genderAgg": { "terms": { "field": "gender.keyword", "size": 10 }, "aggs": { "balAvg": { "avg": { "field": "balance" } } } } } } }, "size": 0 }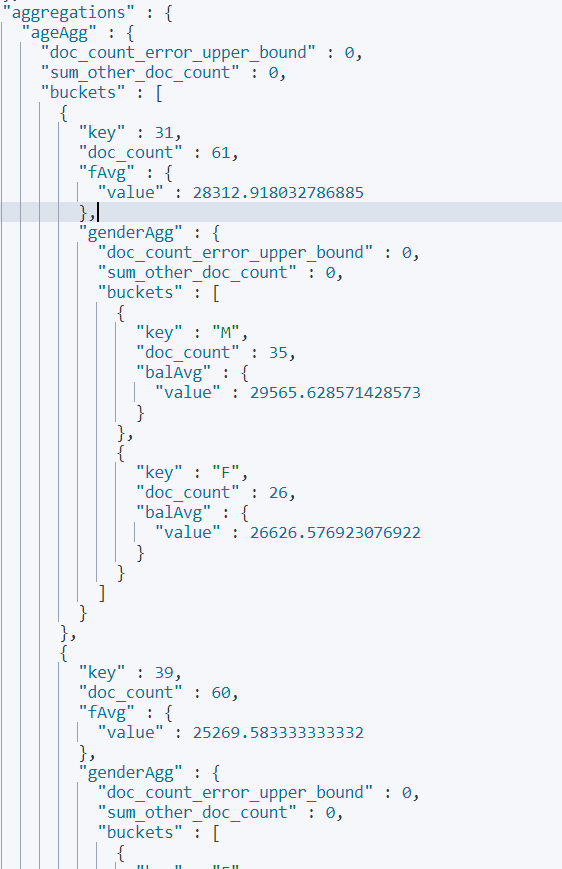
-
Mapping
- Mapping是用來定義一個檔案(document),以及它所包含的屬性(field)是如何存盤索引的,比如,使用mapping來定義:
- 哪些字串屬性應該被看做全文本屬性(full text fields)
- 哪些屬性包含數字,日期或者地理位置
- 檔案中的所有屬性是否都能被索引(_all配置)
- 日期的格式
- 自定義映射規則來執行動態添加屬性
6.0版本之后,移除了
type
-
查看映射
GET /bank/_mapping
分詞
-
一個
tokenizer(分詞器)接受一個字符流,將之分割為獨立的tokens(詞元,通常是獨立的單詞),然后輸出tokens流,例如,
whitespacetokenizer遇到空白字符時分割文本,它會將文本“Quick brown fox!”分割為[Quick,brown,fox!]該
tokenizer(分詞器)還負責記錄各個term(詞條)的順序或position位置(用于phrase短語和word proximity詞近鄰查詢),以及term(詞條)所代表的的原始word(單詞)的開始和結束的字符偏移量(character offsets)用于高亮顯示搜索的內容 -
ElasticSearch 提供了很多內置的分詞器,可以用來構建 custom analyzers(自定義分詞器)
安裝ik分詞器
-
下載地址 7.6.1
-
進入容器內部 plugins目錄 或者宿主機的掛載目錄
- 解壓下載的檔案
- 洗掉壓縮包
- 修改目錄名字為 ik
-
重啟es,并驗證是否安裝成功
-
進入容器 /bin 目錄下執行
elasticsearch-plugin list
-
-
測驗分詞
-
ik_smart最少切分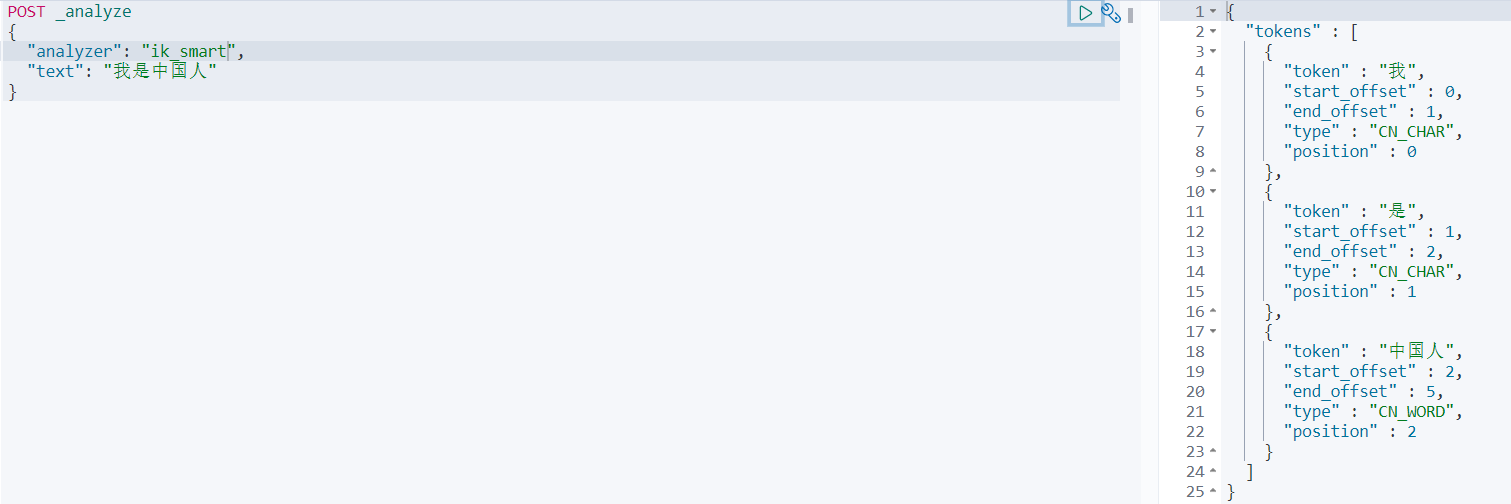
-
ik_max_word最細力度劃分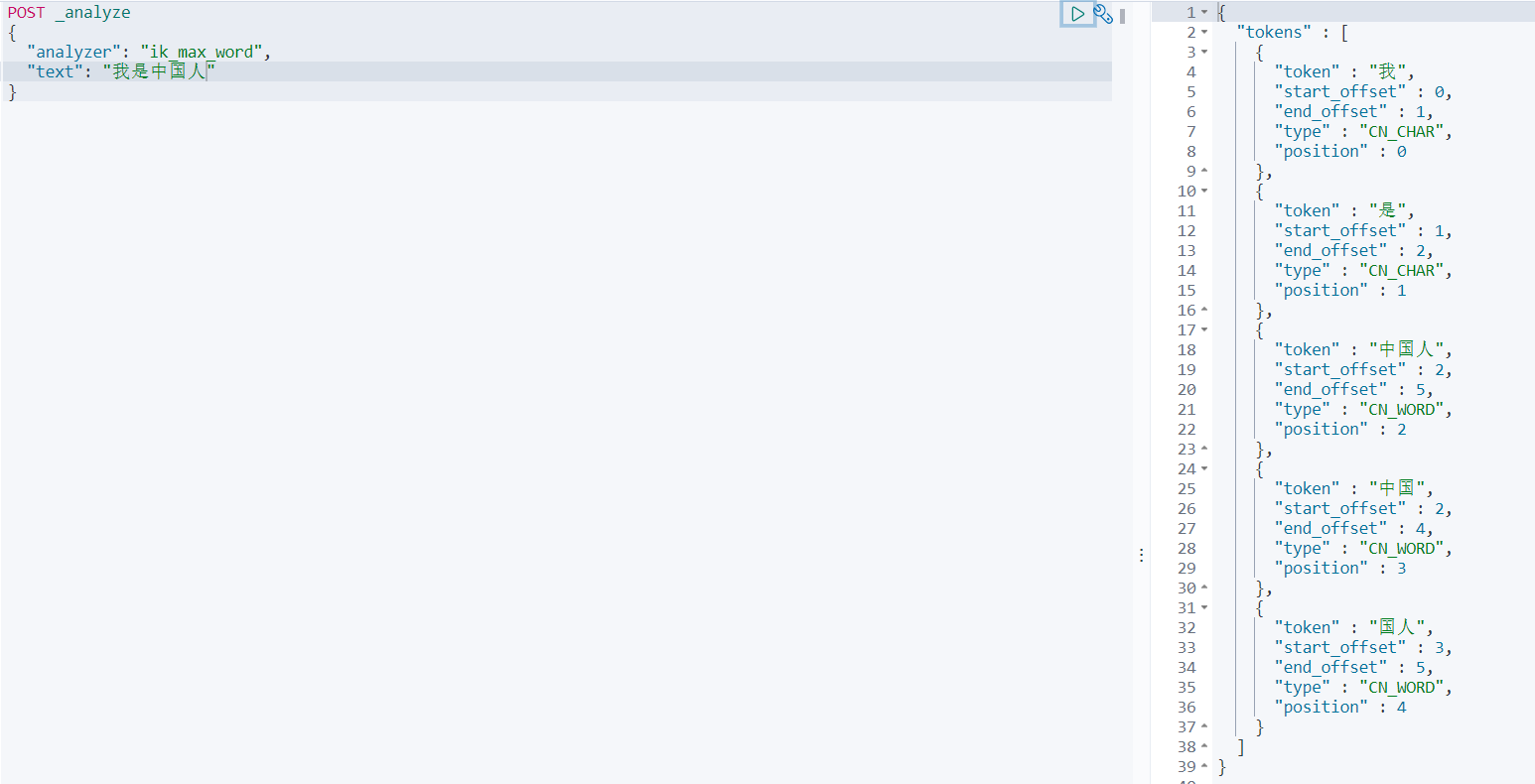
-
安裝Nginx
-
拉取鏡像
docker pull nginx -
先隨便啟動一個nginx實體,只是為了復制配置,方便掛載
#啟動 docker run -p 80:80 --name nginx -d nginx #將容器內的組態檔拷貝到當前目錄 我這里是在 /var/touchAirMallVolume 目錄下執行的 docker container cp nginx:/etc/nginx .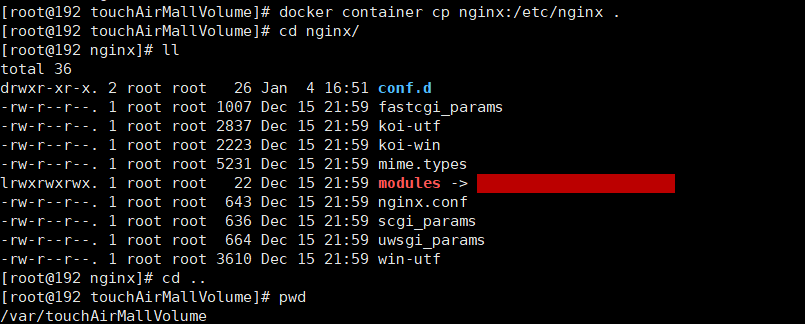
-
修改目錄
mv nginx conf mkdir nginx mv conf nginx/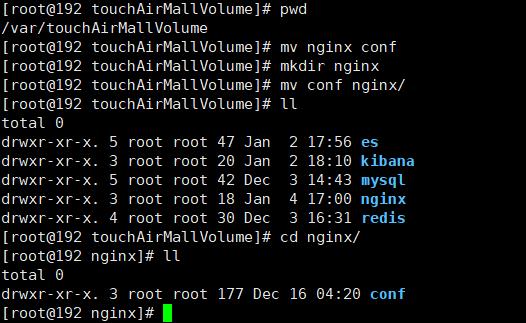
-
洗掉舊的容器,重新掛載啟動
#洗掉舊容器 docker rm -f nginx #掛載啟動 docker run -d --name nginx \ -p 80:80 --restart=always \ -v /var/touchAirMallVolume/nginx/html:/usr/share/nginx/html \ -v /var/touchAirMallVolume/nginx/logs:/var/log/nginx \ -v /var/touchAirMallVolume/nginx/conf:/etc/nginx \ nginx -
驗證nginx
-
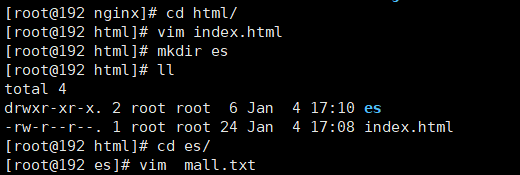
進入宿主機nginx下的html目錄,創建一個簡單的html

-
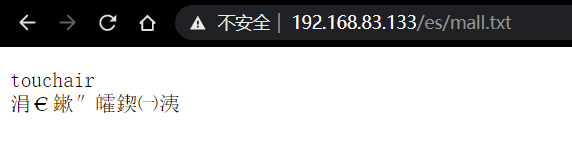
在 nginx/html/ 新增es目錄,創建遠程詞庫
-
自定義擴展詞庫
-
前提:安裝好nginx
-
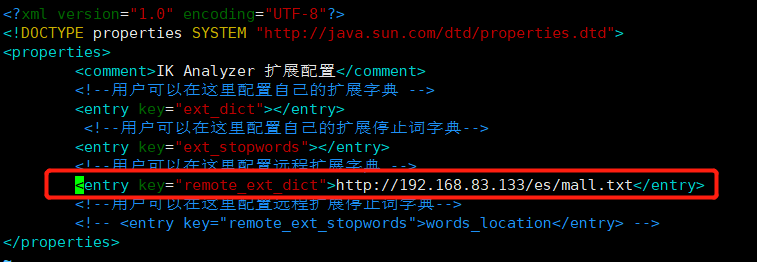
修改ik分詞器的 IKAnalyzer.cfg.xml
cd /var/touchAirMallVolume/es/plugins/ik/config vim IKAnalyzer.cfg.xml
-
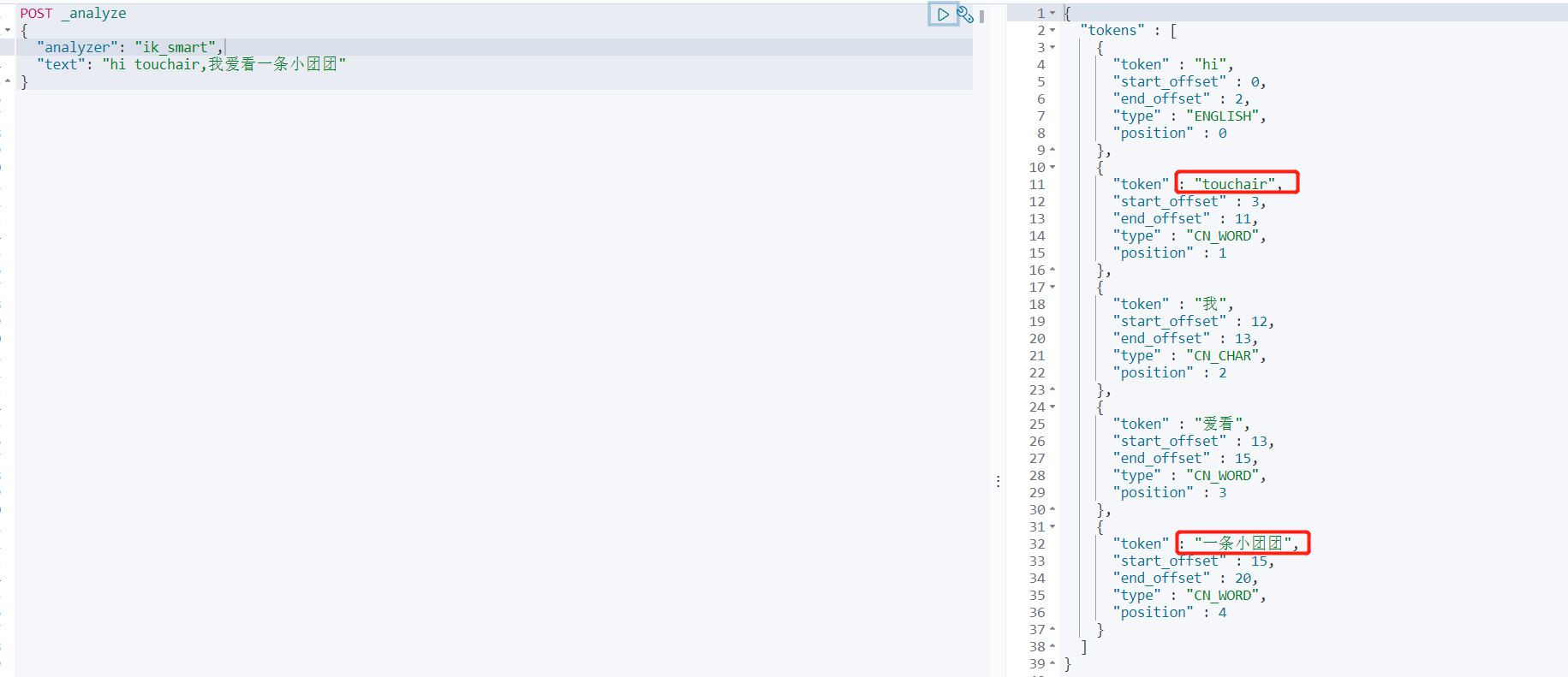
重啟es容器,并測驗自定義分詞效果
Elasticsearch-Rest_Client
-
官方RestClient,封裝了ES操作,API層次分明,上手簡單
最終選擇Elasticsearch-Rest_Client(elasticsearch-rest-high-level-client)
官方地址
-
如果你使用的es版本有對應的spring-data-elasticsearch,建議參照官網使用,封裝了更簡易的API
spring-data
springboot整合
-
導包(對應版本)
<dependency> <groupId>org.elasticsearch.client</groupId> <artifactId>elasticsearch-rest-high-level-client</artifactId> <version>7.6.2</version> </dependency>
配置
-
配置類 (全部參照官方檔案)
elasticsearch-rest-high-level-client配置類
-
MallElasticSearchConfig
@Configuration public class MallElasticSearchConfig { public static final RequestOptions COMMON_OPTIONS; static { RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder(); // builder.addHeader("Authorization", "Bearer " + TOKEN); // builder.setHttpAsyncResponseConsumerFactory( // new HttpAsyncResponseConsumerFactory // .HeapBufferedResponseConsumerFactory(30 * 1024 * 1024 * 1024)); COMMON_OPTIONS = builder.build(); } @Bean public RestHighLevelClient esRestClient() { RestHighLevelClient client = new RestHighLevelClient( RestClient.builder( new HttpHost("192.168.83.133", 9200, "http"))); return client; } }
使用
-
mall-search單元測驗-
測驗是否注入成功
@Resource private RestHighLevelClient restHighLevelClient; @Test public void test() { System.out.println(restHighLevelClient); } -
測驗存盤(更新)資料到es
/** * 測驗存盤資料到es * 更新也可以 */ @Test public void testSave() throws IOException { IndexRequest indexRequest = new IndexRequest("users"); indexRequest.id("1"); // indexRequest.source("username", "ZhSan", "age", 18, "gender","男"); User user = new User(); user.setUserName("ZhSan"); user.setGender("男"); user.setAge(18); String jsonStr = JSONUtil.toJsonStr(user); indexRequest.source(jsonStr, XContentType.JSON);//要保存的內容 //執行操作 IndexResponse index = restHighLevelClient.index(indexRequest, MallElasticSearchConfig.COMMON_OPTIONS); System.out.println(index); } @Data class User{ private String userName; private Integer age; private String gender; } -
測驗復雜檢索
/** * 復雜檢索 */ @Test public void searchData() throws IOException { //1、創建檢索請求 SearchRequest searchRequest = new SearchRequest(); //2、指定索引 searchRequest.indices("bank"); //3、指定DSL,檢索條件 SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(); //3.1、構造檢索條件 //searchSourceBuilder.query(); //searchSourceBuilder.from(); //searchSourceBuilder.size(); //searchSourceBuilder.aggregation(); searchSourceBuilder.query(QueryBuilders.matchQuery("address", "mill")); //聚合操作 //按照年齡的值分布進行聚合 TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg").field("age").size(10); searchSourceBuilder.aggregation(ageAgg); //計算平均薪資 AvgAggregationBuilder balanceAvgAgg = AggregationBuilders.avg("balanceAvgAgg").field("balance"); searchSourceBuilder.aggregation(balanceAvgAgg); System.out.println("檢索條件:"+searchSourceBuilder.toString()); searchRequest.source(searchSourceBuilder); //4、執行檢索 SearchResponse searchResponse = restHighLevelClient.search(searchRequest, MallElasticSearchConfig.COMMON_OPTIONS); //5、分析結果 System.out.println(searchResponse.toString()); //5.1 獲取所有查到的資料 SearchHits hits = searchResponse.getHits(); SearchHit[] hitsHits = hits.getHits(); for (SearchHit searchHit : hitsHits) { /** * "_index" : "bank", * "_type" : "accout", * "_id" : "1", * "_score" : 1.0, * "_source" : {} */ String sourceAsString = searchHit.getSourceAsString(); Account account = JSON.parseObject(sourceAsString, Account.class); System.out.println(account); } //5.2 獲取這次檢索到的分析資訊 Aggregations aggregations = searchResponse.getAggregations(); // for (Aggregation aggregation : aggregations.asList()) { // System.out.println("當前聚合:"+aggregation.getName()); // } Terms ageAggRes = aggregations.get("ageAgg"); for (Terms.Bucket bucket : ageAggRes.getBuckets()) { String keyAsString = bucket.getKeyAsString(); System.out.println("年齡:" + keyAsString+"===>"+bucket.getDocCount()); } Avg balanceAvgAggRes = aggregations.get("balanceAvgAgg"); System.out.println("平均薪資:" + balanceAvgAggRes.getValue()); } /** * bank 賬戶資訊 */ @Data @ToString static class Account { private int account_number; private int balance; private String firstname; private String lastname; private int age; private String gender; private String address; private String employer; private String email; private String city; private String state; }
-
商品上架
spu在es中的存盤模型分析
-
如果每個sku都存盤規格引數,會有冗余存盤,因為每個spu對應的sku的規格引數都一樣,但是如果將規格引數單獨建立索引會出現檢索時出現大量資料傳輸的問題,會阻塞網路
因此我們選用第一種存盤模型,以空間換時間
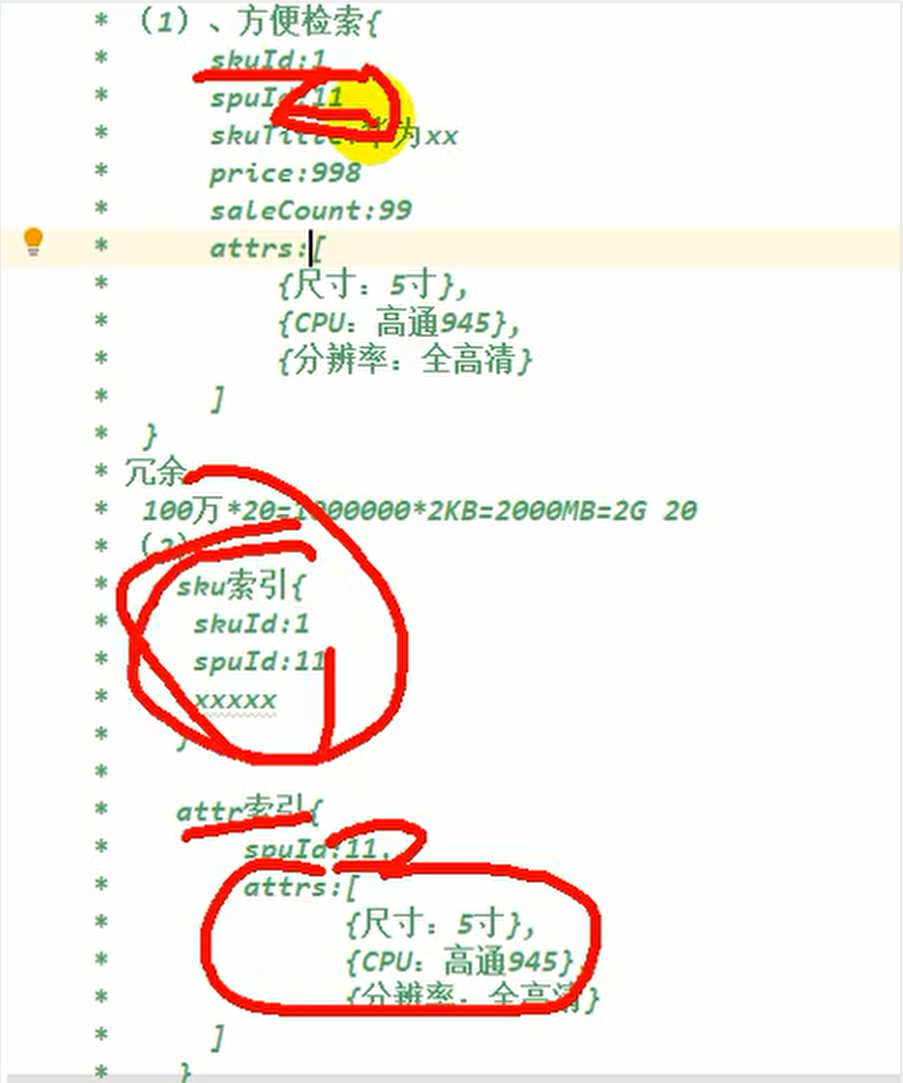
向ES添加商品屬性映射
-
es-product 屬性映射
PUT product { "mappings": { "properties": { "skuId":{ "type":"long" }, "spuId":{ "type":"keyword" }, "skuTitle":{ "type":"text", "analyzer": "ik_smart" }, "skuPrice":{ "type":"keyword" }, "skuImg":{ "type":"keyword", "index": false, "doc_values": false }, "saleCount":{ "type":"long" }, "hasStock":{ "type":"boolean" }, "hotScore":{ "type":"long" }, "brandId":{ "type":"long" }, "catalogId":{ "type":"long" }, "brandName":{ "type":"keyword", "index": false, "doc_values": false }, "brandImg":{ "type":"keyword", "index": false, "doc_values": false }, "catalogName":{ "type":"keyword", "index": false, "doc_values": false }, "attrs":{ "type": "nested", "properties": { "attrId":{ "type":"long" }, "attrName":{ "type":"keyword", "index": false, "doc_values": false }, "attrValue":{ "type":"keyword" } } } } } }
商品上架功能實作
-
實作方法
com.touch.air.mall.product.service.impl.SpuInfoServiceImpl.up()
Feign呼叫流程
- 問題思考:遠程呼叫失敗 是否會重復呼叫?介面冪等性;重試機制?
-
構造請求資料,將物件轉為json
#原始碼 RequestTemplate template=buildTemplateFromArgs.create(argv) -
發送請求進行執行(執行成功會解碼回應資料)
executeAndDecode(template) -
執行請求會有重試機制
while(true) { try{ executeAndDecode(template); }catch(){ try{retryer.continueOrPropagate(e);}catch(){throw ex;} continue; } }
商城首頁
動靜分離
-
整體架構
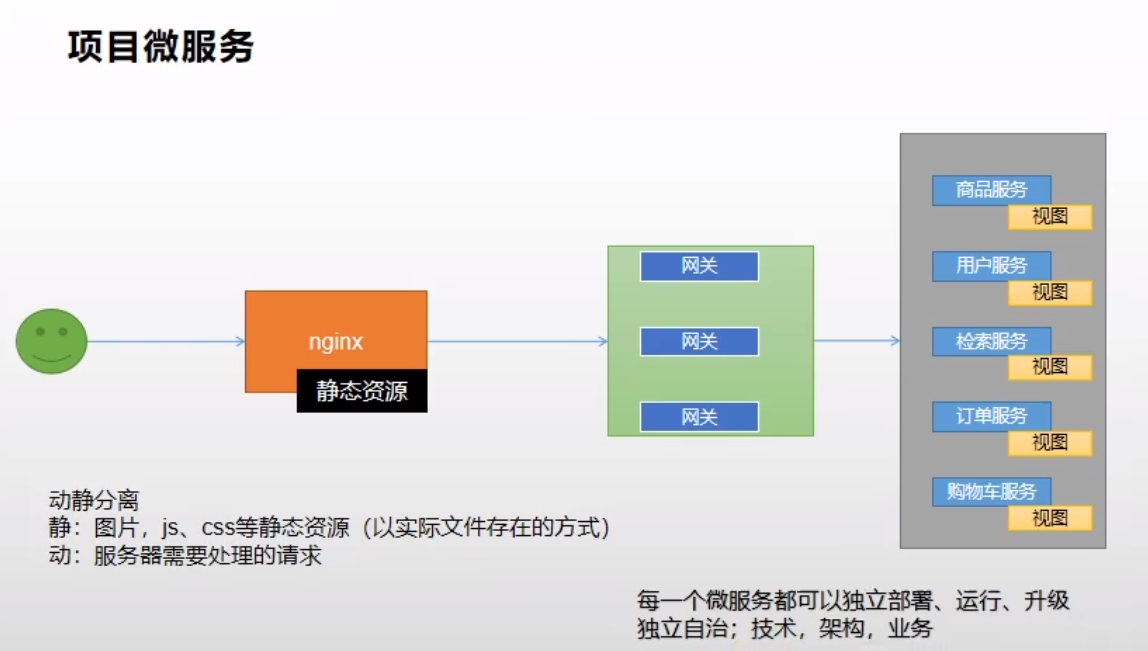
整合thymeleaf渲染首頁
-
添加依賴
<!--模板引擎 thymeleaf--> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-thymeleaf</artifactId> </dependency> -
匯入靜態資源 --首頁資源
-
index檔案夾 添加到商品微服務的
resources/static下 -
index.html檔案添加到商品微服務的resources/templates下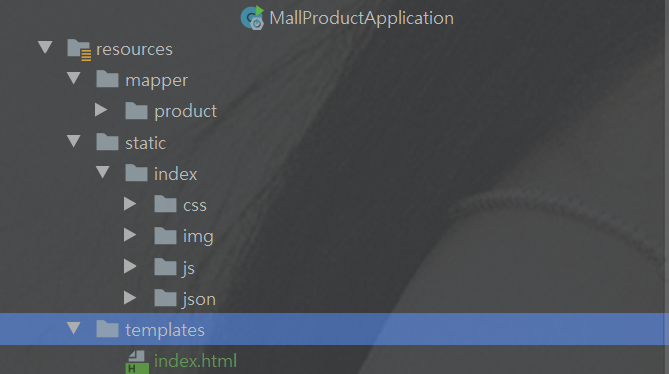
-
-
application.yml添加配置-
靜態資源都放在static檔案夾下就可以按照路徑直接訪問
-
頁面放在templates下,直接訪問 SpringBoot,訪問專案的時候,默認會找index.html
#頁面測驗 #訪問靜態資源 http://localhost:12000/index/css/GL.css #訪問html頁面 http://localhost:12000 -
查看
WebMvcAutoConfiguration原始碼-
OrderedHiddenHttpMethodFilter處理頁面發送的rest請求 -
InternalResourceViewResolver視圖決議器進行拼串(前綴、后綴)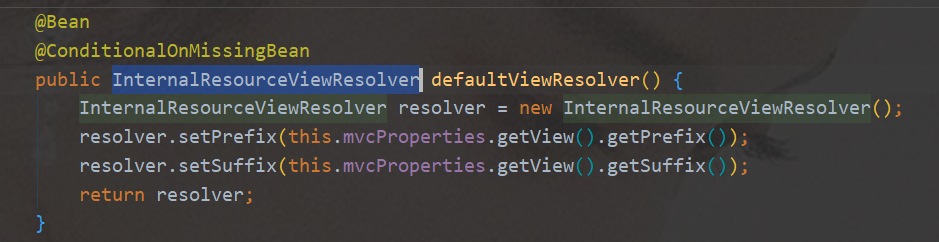
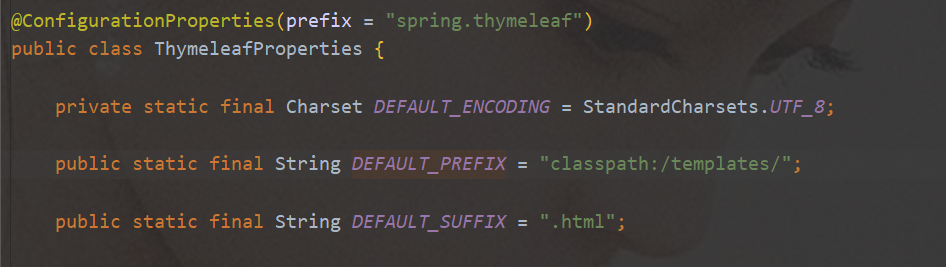
-
addResourceHandlers資源處理器 -
WelcomePageHandlerMapping歡迎頁 默認靜態資源路徑、默認加載index.html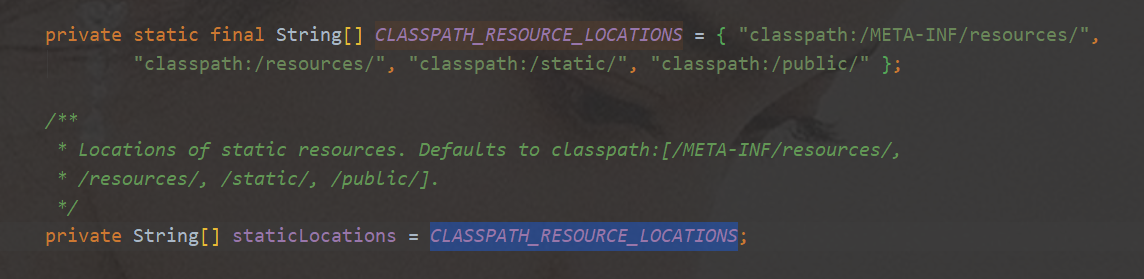
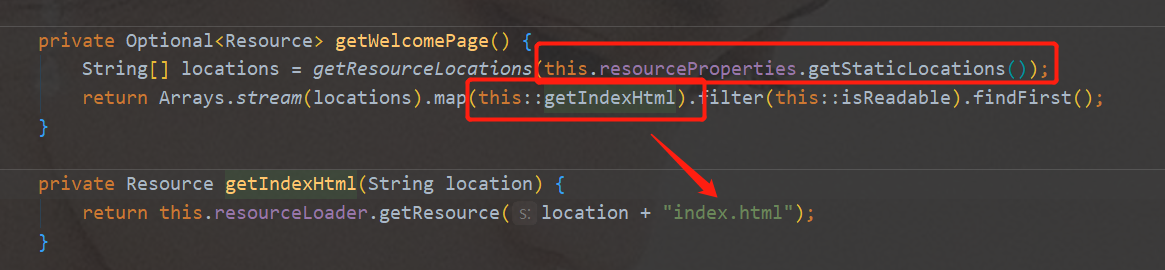
-
-
-
檔案
thymeleaf官方檔案
頁面修改不重啟服務實時更新
-
引入
dev-tools<dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-devtools</artifactId> <optional>true</optional> </dependency> -
修改完頁面 直接
ctrl+shift+F9重新自動編譯,如果修改了代碼配置,推薦重啟 避免bug
渲染一級分類資料
-
介面
com.touch.air.mall.product.web.IndexController.indexPage #請求url http://localhost:12000/ http://localhost:12000/index.html -
頁面
templates/index.html
渲染二級&三級分類資料
-
介面
com.touch.air.mall.product.web.IndexController.getCatalogJson #請求url http://localhost:12000/index/catalog.json -
ajax請求
catalogLoader.js index/catalog.json
nginx搭建域名訪問環境
正向代理與反向代理
-
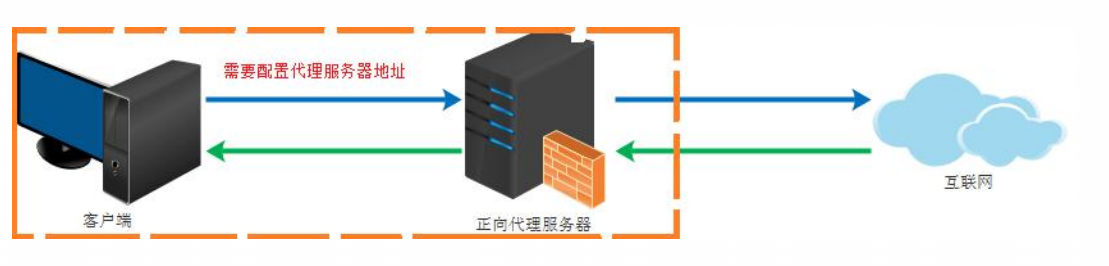
正向代理:如上網,隱藏客戶端資訊(常見VPN)
-
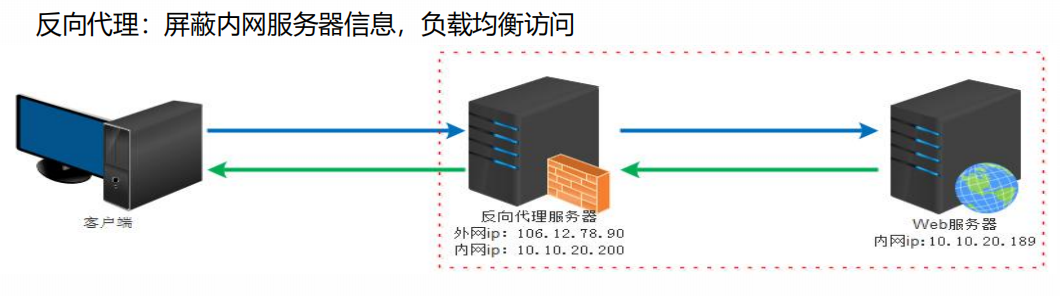
反向代理:屏蔽內網服務器資訊,負載均衡訪問
nginx+Windows搭建域名訪問環境
windows
-
windows hosts檔案
C:\Windows\System32\drivers\etc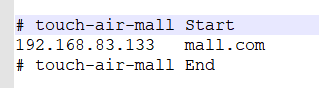
-
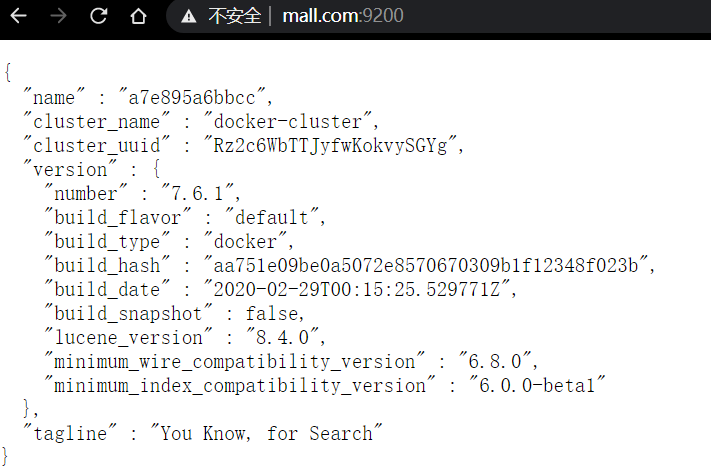
修改完成后,使用域名訪問ES測驗
nginx進行反向代理
-
nginx組態檔
conf/nginx.conf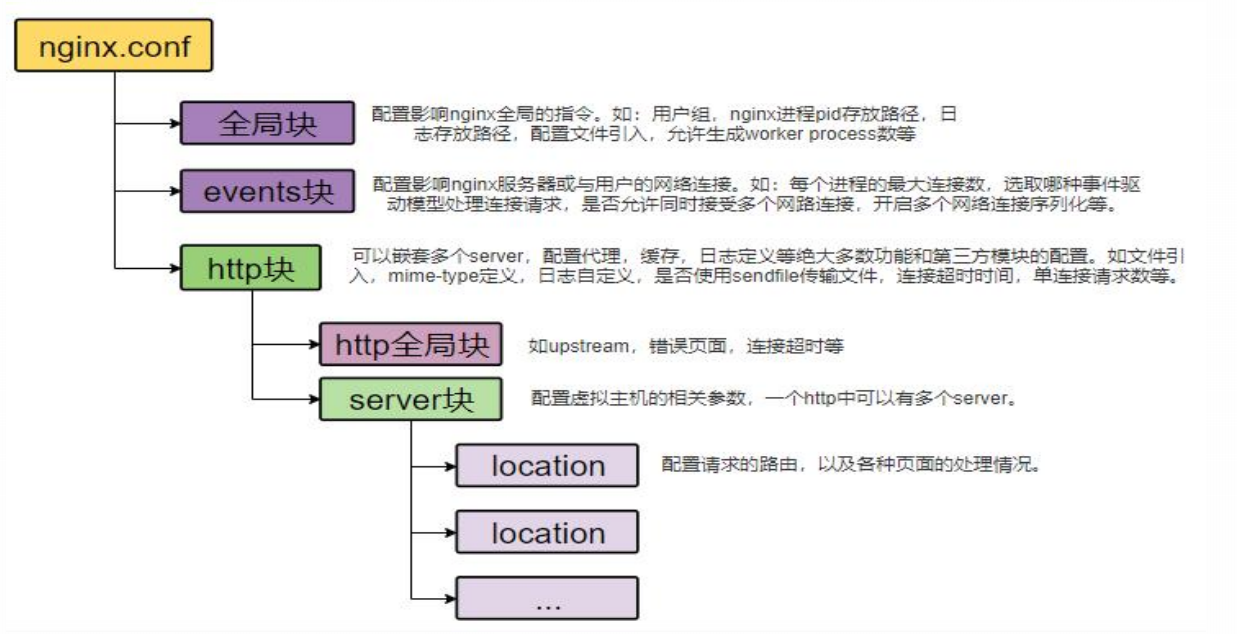
-
nginx.conf 表面所有的server塊所在的位置
nginx/conf.d 目錄下的 default.conf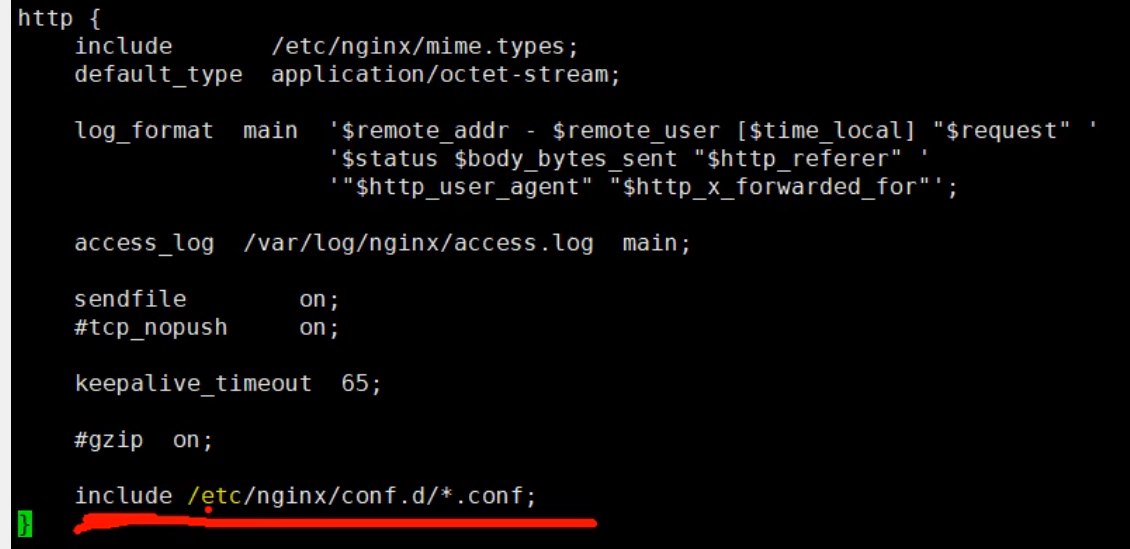
-
-
將所有來自mall.com的請求,都轉到商品服務
cp nginx/conf.d 目錄下的default.conf mall.conf vim mall.conf 指定server_name 為 mall.com (與頁面請求的Host對應) 配置轉發的地址 本地商品服務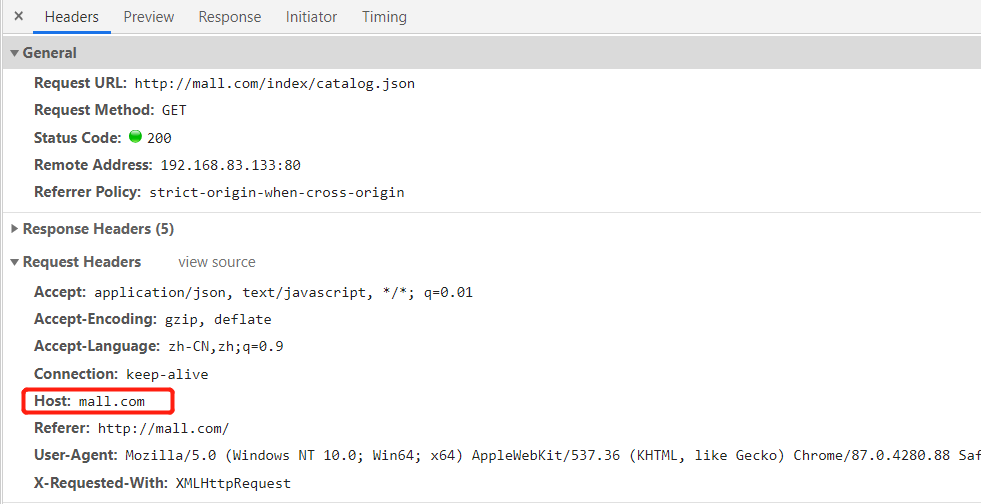
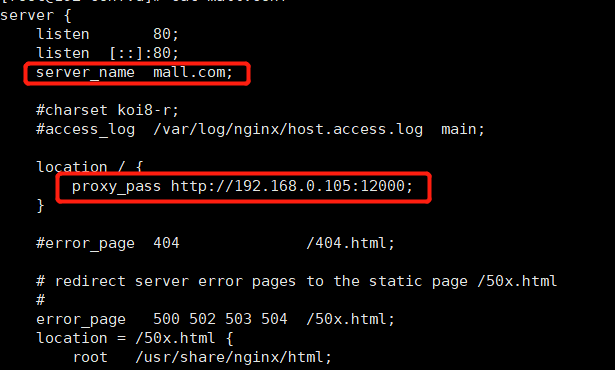
- 重啟nginx容器
- 此時頁面訪問
mall.com,會展示商城首頁
域名訪問,負載均衡到網關
-
nginx官網
使用nginx 在http協議中負載均衡
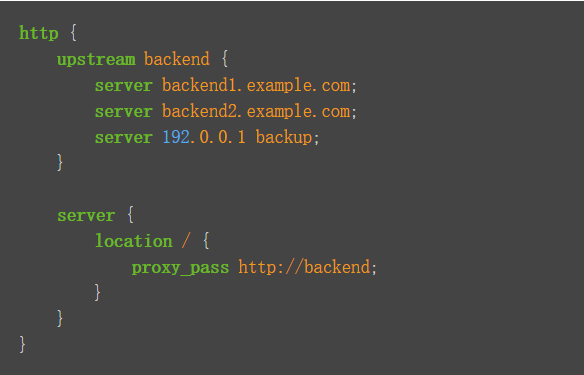
-
修改
nginx.conf#添加上游服務器的服務地址 #轉交給本地網關 upstream mall { server 192.168.0.105:9527; } -
修改
nginx/conf.d目錄下的mall.conf#對應上游服務器的名字 location / { proxy_pass http://mall; }
注意:nginx代理到網關的時候,會默認丟掉很多資訊,包括host資訊等,在這里如果沒有host資訊,網關路由將匹配不到,也就無法轉發到指定的服務
-
修改配置,讓nginx保存host
vim mall.conf #添加以下配置 proxy_set_header Host $host重啟nginx容器
-
添加網關路由處理規則
#配置在vue路由的最下面 - id: mall_host uri: lb://touch-air-mall-product predicates: - Host=**.mall.com重啟網關服務
-
瀏覽器輸入 mall.com 訪問成功
最終域名映射效果
- 請求介面 mall.com
- 請求頁面 mall.com
- nginx 直接代理給網關,網關進行判斷
- 如果/api/**,轉交給對應的服務器
- 如果是滿足域名,轉交給對應的服務
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/247925.html
標籤:Java