前言
本文的文字及圖片來源于網路,僅供學習、交流使用,不具有任何商業用途,如有問題請及時聯系我們以作處理,
Python爬蟲、資料分析、網站開發等案例教程視頻免費在線觀看
https://space.bilibili.com/523606542

基本開發環境
- Python 3.6
- Pycharm
相關模塊的使用
import requests import re
requests 在cmd中 pip install requests 安裝即可
我這是顯示已經安裝過了的,如果你沒有安裝的話,是會有安裝進度條的,
目標網頁分析
就選擇B站排行榜第一的視頻,
如何找到彈幕資料?

如上圖所示:
1、點擊進入網頁之后,F12打開開發者工具,選擇Ntework
2、點擊查看歷史彈幕,選擇日期就有相對應的資料加載出來
3、點擊選擇有日期的url地址,彈幕的資料都包含在內了(如下圖所示)

彈幕資料的url地址既然都知道了,那么就可以直接爬取下來了,
代碼實作部分
1、請求網頁獲取源代碼資料
import requests url = 'https://api.bilibili.com/x/v2/dm/history?type=1&oid=279984604&date=2021-01-10' headers = { 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36' } response = requests.get(url=url, headers=headers) print(response.text)
爬取這些資料是需要加上cookie的,如果沒有加cookie的話會顯示你未登錄賬號

所以需要在headers里面添加cookie
cookie怎么添加呢?
在開發者工具當中,選擇你所需要爬取的url地址,查看headers其中的requests headers 中的cookie就是了,

當給了cookie之后又出現問題了

雖然資料是有了,但是出現亂,其實只需要加一行代碼就可以解決,還是比較萬能的轉碼方式,
response.encoding = response.apparent_encoding
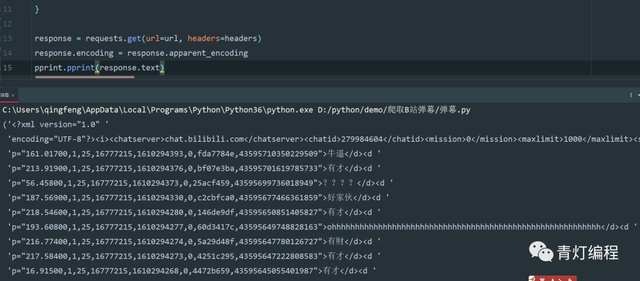
遇到亂碼問題都可以這樣使用,如果使用之后還是出現亂碼問題,就要根據網頁的編碼進行轉碼了,
2、使用正則運算式提取彈幕資料
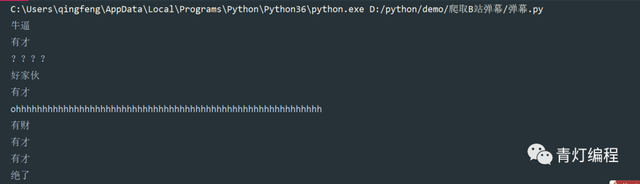
result = re.findall('p=".*?">(.*?)</d><d ', response.text) for i in result: print(i)
正則運算式提取出來的資料,是串列格式,所以需要遍歷提取出每一條彈幕資料,
3、保存資料至本地
with open('彈幕.txt', mode='a', encoding='utf-8') as f: f.write(i) f.write('\n')
mode='a':寫入模式為a,追加寫入
encoding='utf-8':指定寫入編碼,文字內容均為 'utf-8'
寫入一個換行符,每寫入一條資料,就重新換一個行寫入
4、批量爬取彈幕資料
之前只是爬取一天的彈幕資料,如果想要爬取一段時間內容的彈幕資料的話,只需要改變url地址中的日期就可以了
for date in range(9, 12): url = f'https://api.bilibili.com/x/v2/dm/history?type=1&oid=279984604&date=2021-01-{date}'
就是從9號爬取到11號的資料,這個視頻也剛出來三天,
爬蟲完整代碼
import requests import re for date in range(9, 12): url = f'https://api.bilibili.com/x/v2/dm/history?type=1&oid=279984604&date=2021-01-{date}' headers = { "cookie": "輸入你自己的cookie", 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36' } response = requests.get(url=url, headers=headers) response.encoding = response.apparent_encoding result = re.findall('p=".*?">(.*?)</d><d ', response.text) for i in result: with open('彈幕.txt', mode='a', encoding='utf-8') as f: f.write(i) f.write('\n') print(i)
通過代碼量可以看得出來,B站彈幕的爬取還是比較簡單的,16行就能搞定,說到底還是python代碼簡潔優雅,
彈幕詞云代碼
import jieba import wordcloud import imageio # 匯入imageio庫中的imread函式,并用這個函式讀取本地圖片,作為詞云形狀圖片 # py = imageio.imread('圖片路徑') 如何你想要改變詞云圖的形狀,可以添加 # 讀取檔案內容 f = open('彈幕.txt', encoding='utf-8') txt = f.read() # jiabe 分詞 分割詞匯 txt_list = jieba.lcut(txt) string = ' '.join(txt_list) # 詞云圖設定 wc = wordcloud.WordCloud( width=1000, # 圖片的寬 height=700, # 圖片的高 background_color='white', # 圖片背景顏色 font_path='msyh.ttc', # 詞云字體 # mask=py, # 所使用的詞云圖片 scale=15, # stopwords={''}, # 停用詞 # contour_width=5, # contour_color='red' # 輪廓顏色 ) # 給詞云輸入文字 wc.generate(string) # 詞云圖保存圖片地址 wc.to_file('out.png')
實作效果

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/247948.html
標籤:Python