我們先拋出一個問題:
LSM樹是HBase里使用的非常有創意的一種資料結構,在有代表性的關系型資料庫如MySQL、SQL Server、Oracle中,資料存盤與索引的基本結構就是我們耳熟能詳的B樹和B+樹,而在一些主流的NoSQL資料庫如HBase、Cassandra、LevelDB、RocksDB中,則是使用日志結構合并樹(Log-structured Merge Tree,LSM Tree)來組織資料,
首先,我們從B+樹講起
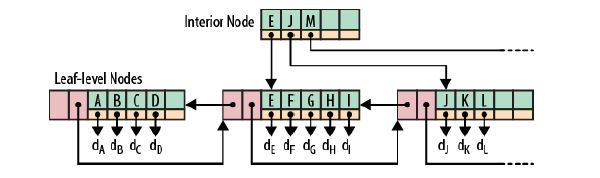
為什么在RDBMS中我們需要B+樹(或者廣義地說,索引)?一句話:減少尋道時間,在存盤系統中廣泛使用的HDD是磁性介質+機械旋轉的,這就使得其順序訪問較快而隨機訪問較慢,使用B+樹組織資料可以較好地利用HDD的這種特點,其本質是多路平衡查找樹,一個典型的B+樹如下圖所示:
-
B+樹的磁盤讀寫代價更低:B+樹的內部節點并沒有指向關鍵字具體資訊的指標,因此其內部節點相對B樹更小,如果把所有同一內部節點的關鍵字存放在同一盤塊中,那么盤塊所能容納的關鍵字數量也越多,一次性讀入記憶體的需要查找的關鍵字也就越多,相對IO讀寫次數就降低了,
-
B+樹的查詢效率更加穩定:由于非終結點并不是最終指向檔案內容的結點,而只是葉子結點中關鍵字的索引,所以任何關鍵字的查找必須走一條從根結點到葉子結點的路,所有關鍵字查詢的路徑長度相同,導致每一個資料的查詢效率相當,
-
由于B+樹的資料都存盤在葉子結點中,分支結點均為索引,方便掃庫,只需要掃一遍葉子結點即可,但是B樹因為其分支結點同樣存盤著資料,我們要找到具體的資料,需要進行一次中序遍歷按序來掃,所以B+樹更加適合在區間查詢的情況,所以通常B+樹用于資料庫索引,
如果你對B+樹不夠熟悉,可以參考這里:https://blog.csdn.net/b_x_p/article/details/86434387
那么,B+樹有什么缺點呢?
B+樹最大的性能問題是會產生大量的隨機IO,隨著新資料的插入,葉子節點會慢慢分裂,邏輯上連續的葉子節點在物理上往往不連續,甚至分離的很遠,但做范圍查詢時,會產生大量讀隨機IO,
LSM Tree
為了克服B+樹的弱點,HBase引入了LSM樹的概念,即Log-Structured Merge-Trees,
LSM Tree(Log-structured merge-tree)起源于1996年的一篇論文:The log-structured merge-tree (LSM-tree),當時的背景是:為一張資料增長很快的歷史資料表設計一種存盤結構,使得它能夠解決:在記憶體不足,磁盤隨機IO太慢下的嚴重寫入性能問題,
LSM Tree(Log-structured merge-tree)廣泛應用在HBase,TiDB等諸多資料庫和存盤引擎上:

我們來看看大佬設計這個資料結構:
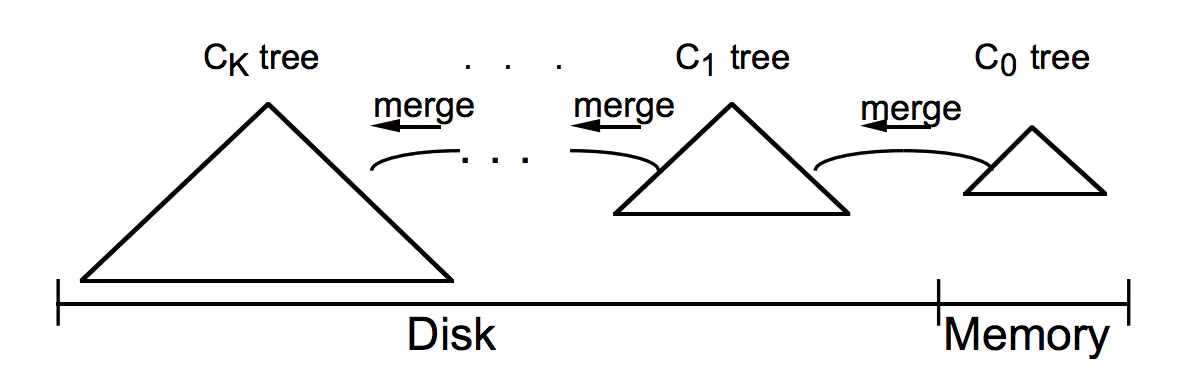
Ck tree是一個有序的樹狀結構,資料的寫入流轉從C0 tree 記憶體開始,不斷被合并到磁盤上的更大容量的Ck tree上,由于記憶體的讀寫速率都比外存要快非常多,因此資料寫入的效率很高,并且資料從記憶體刷入磁盤時是預排序的,也就是說,LSM樹將原本的隨機寫操作轉化成了順序寫操作,寫性能大幅提升,不過它犧牲了一部分讀性能,因為讀取時需要將記憶體中的資料和磁盤中的資料合并,
回到Hbase來,我們在之前的文章中《Hbase性能優化手冊》中提到過Hbase的讀寫流程:
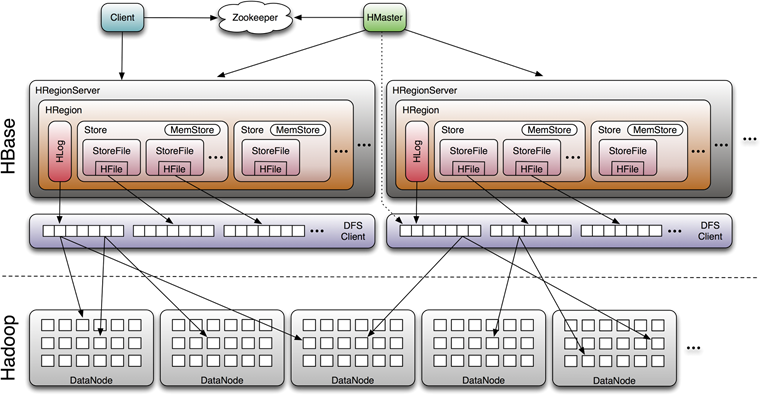
MemStore是HBase中C0的實作,向HBase中寫資料的時候,首先會寫到記憶體中的MemStore,當達到一定閥值之后,flush(順序寫)到磁盤,形成新的StoreFile(HFile),最后多個StoreFile(HFile)又會進行Compact,
memstore內部維護了一個資料結構:ConcurrentSkipListMap,資料存盤是按照RowKey排好序的跳躍串列,跳躍串列的演算法有同平衡樹一樣的漸進的預期時間邊界,并且更簡單、更快速和使用更少的空間,
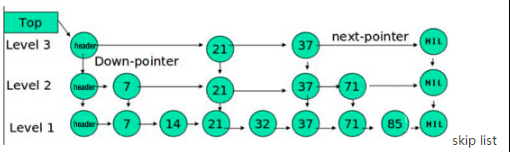
HBase為了提升LSM結構下的隨機讀性能,還引入了布隆過濾器(建表陳述句中可以指定),對應HFile中的Bloom index block,其結構圖如下所示,
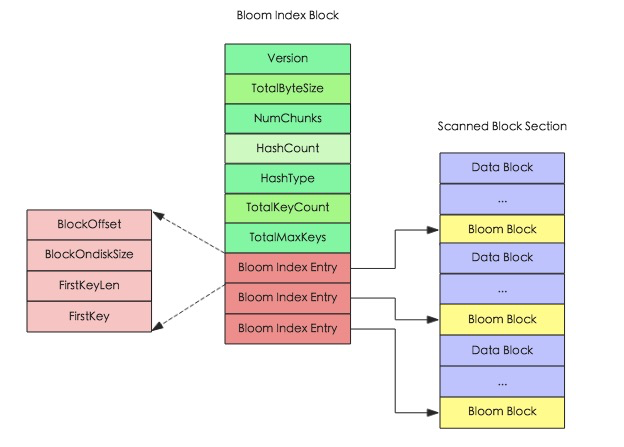
通過布隆過濾器,HBase就能以少量的空間代價,換來在讀取資料時非常快速地確定是否存在某條資料,效率進一步提升,
歡迎關注,《大資料成神之路》系列文章
歡迎關注,《大資料成神之路》系列文章
歡迎關注,《大資料成神之路》系列文章
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/247973.html
標籤:其他