目錄
- 工具
- 前言
- 生成標注集的json檔案
- 資料集準備
- 將voc注解格式資料集的注解轉換成txt注解格式
- 自定義資料集的注解轉換成coco的注解格式
- 生成結果集的json檔案
- 安裝darknet
- 獲取自己模型的.weight檔案(將.h5檔案轉換成.weight檔案)
- 將影像以coco格式重命名
- 修改coco.data中的路徑
- 修改yolov3.cfg檔案
- 進行檢測并生成json檔案
- 測驗mAP步驟
- 錯誤問題解決
- 參考博文及Github專案(十分感謝!)
工具
1.git:去git官網下載:https://git-scm.com/downloads/,下載自己需要的版本,下載完成后按照默認步驟安裝即可
2.pycocotools:測驗mAP時需要用到,參照https://blog.csdn.net/SyliaJason/article/details/103066638 進行安裝(Win10系統)
3.Advanced Renamer:批量重命名工具——https://www.advancedrenamer.com/ ,批量更改資料集名稱時可能會用到,
前言
對于不同資料集mAP值的計算方法不同,VOC2007提出了利用11個recall值來計算AP,而在2010之后使用了所有資料點來計算AP,COCO資料集采用的計算方式更加嚴格,它計算了不同IOU閾值和物體大小下的AP值,再取平均值,
本文參考了利用COCO API評估YOLOv3模型mAP的相關文章,這里總結了如何評估自己訓練出的yolov3模型的mAP,其中自制資料集參考了VOC資料集的格式存放,
測驗mAP需要兩個json檔案:cocoGt_file 和 cocoDt_file,一個是經過正確標注的標注集的json檔案,一個是通過自己訓練的YOLOv3模型進行檢測而生成的結果集的json檔案,這可以通過mAP的定義來理解,
下面我將分別介紹如何生成所需要的這兩個json檔案,進行mAP測驗,
【文章默認已經準備好了帶有xml標注的資料集,并且訓練好了自己的yolo.h5模型】
生成標注集的json檔案
資料集準備
我使用的是VOC格式的自制資料集,要生成COCO資料集需要的json檔案,需要對資料集進行處理,
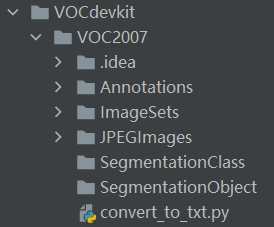
我這里需要使用的僅僅是測驗集,所以只需要用到test.txt,該檔案保存的是
測驗集的影像名稱,
將voc注解格式資料集的注解轉換成txt注解格式
在自己的專案檔案夾下新建1_voc2txt.py檔案,輸入如下代碼,注意根據自己的實際情況更改資料集的路徑,并且在VOCdevkit/VOC2007/Annotations檔案夾下需要存放標注的.xml檔案,
import os
import shutil
'''
將 dataset_dir 改為你的資料集的路徑,
生成的txt注解檔案格式為:
圖片名 物體1左上角x坐標,物體1左上角y坐標,物體1右下角x坐標,物體1右下角y坐標,物體1類別id 物體2左上角x坐標,物體2左上角y坐標,物體2右下角x坐標,物體2右下角y坐標,物體2類別id ...
train_difficult控制是否訓練難例,use_default_label控制是否使用默認的類別檔案,
'''
# 是否訓練難例,
train_difficult = True
# train_difficult = False
# 是否使用默認的類別檔案,
use_default_label = True
# use_default_label = False
dataset_dir = 'VOCdevkit/VOC2007/'
train_path = dataset_dir + 'ImageSets/Main/train.txt'
val_path = dataset_dir + 'ImageSets/Main/val.txt'
test_path = dataset_dir + 'ImageSets/Main/test.txt'
#test_path = None
annos_dir = dataset_dir + 'Annotations/'
# 保存的txt注解檔案的檔案名
train_txt_name = 'voc2007_train.txt'
val_txt_name = 'voc2007_val.txt'
test_txt_name = 'voc2007_test.txt'
class_names = []
class_names_ids = {}
cid_index = 0
if use_default_label:
# class_txt_name指向已有的類別檔案,一行一個類別名,類別id根據這個類別檔案中類別名在第幾行確定,
# 如果只訓練該資料集的部分類別,那么編輯該類別檔案,只留下所需類別的類別名即可,
class_txt_name = 'model_data/voc_classes.txt'
if not os.path.exists(class_txt_name):
raise FileNotFoundError("%s does not exist!" % class_txt_name)
with open(class_txt_name, 'r', encoding='utf-8') as f:
for line in f:
cname = line.strip()
class_names.append(cname)
class_names_ids[cname] = cid_index
cid_index += 1
else: # 如果不使用默認的類別檔案,則會分析出有幾個類別,生成一個類別檔案,
# 保存的類別檔案名
class_txt_name = 'data/class_names.txt'
train_names = []
val_names = []
test_names = []
with open(train_path, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
train_names.append(line)
with open(val_path, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
val_names.append(line)
if test_path is not None:
with open(test_path, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
test_names.append(line)
# 創建txt注解目錄
if os.path.exists('annotation/'): shutil.rmtree('annotation/')
os.mkdir('annotation/')
def write_txt(xml_names, annos_dir, txt_name, use_default_label, train_difficult, class_names, class_names_ids, cid_index):
content = ''
for xml_name in xml_names:
xml_file = '%s%s.xml'%(annos_dir, xml_name)
enter_gt = False
enter_part = False
x0, y0, x1, y1, cid = '', '', '', '', -10
difficult = 0
img_name = ''
bboxes = ''
with open(xml_file, 'r', encoding='utf-8') as f:
for line in f:
line = line.strip()
if '<filename>' in line:
if '</filename>' in line:
ss = line.split('name>')
sss = ss[1].split('</file')
img_name = sss[0]
else:
print('Error 1.')
if '<object>' in line:
if '</object>' in line:
print('Error 2.')
else:
enter_gt = True
if '</object>' in line:
if cid > -5:
if train_difficult:
bboxes += ' %s,%s,%s,%s,%d'%(x0, y0, x1, y1, cid)
else:
if difficult == 0:
bboxes += ' %s,%s,%s,%s,%d'%(x0, y0, x1, y1, cid)
x0, y0, x1, y1, cid = '', '', '', '', -10
difficult = 0
enter_gt = False
enter_part = False
if enter_gt:
if '<part>' in line: # <object>里會有<part>節點,我們要忽略<part>節點,
if '</part>' in line:
print('Error part.')
else:
enter_part = True
if '</part>' in line:
enter_part = False
if not enter_part:
if '<name>' in line:
if '</name>' in line:
ss = line.split('name>')
sss = ss[1].split('</')
cname = sss[0]
if use_default_label:
if cname not in class_names:
cid = -10
else:
cid = class_names_ids[cname]
else:
if cname not in class_names:
class_names.append(cname)
class_names_ids[cname] = cid_index
cid_index += 1
cid = class_names_ids[cname]
else:
print('Error 3.')
if '<xmin>' in line:
if '</xmin>' in line:
ss = line.split('xmin>')
sss = ss[1].split('</')
x0 = sss[0]
else:
print('Error 4.')
if '<ymin>' in line:
if '</ymin>' in line:
ss = line.split('ymin>')
sss = ss[1].split('</')
y0 = sss[0]
else:
print('Error 5.')
if '<xmax>' in line:
if '</xmax>' in line:
ss = line.split('xmax>')
sss = ss[1].split('</')
x1 = sss[0]
else:
print('Error 6.')
if '<ymax>' in line:
if '</ymax>' in line:
ss = line.split('ymax>')
sss = ss[1].split('</')
y1 = sss[0]
else:
print('Error 7.')
if '<difficult>' in line:
if '</difficult>' in line:
ss = line.split('difficult>')
sss = ss[1].split('</')
difficult = int(sss[0])
else:
print('Error 8.')
content += img_name + bboxes + '\n'
with open('annotation/%s' % txt_name, 'w', encoding='utf-8') as f:
f.write(content)
f.close()
return class_names, class_names_ids, cid_index
# train set
class_names, class_names_ids, cid_index = write_txt(train_names, annos_dir, train_txt_name,
use_default_label, train_difficult, class_names, class_names_ids, cid_index)
# val set
class_names, class_names_ids, cid_index = write_txt(val_names, annos_dir, val_txt_name,
use_default_label, train_difficult, class_names, class_names_ids, cid_index)
# test set
if test_path is not None:
class_names, class_names_ids, cid_index = write_txt(test_names, annos_dir, test_txt_name,
use_default_label, train_difficult, class_names, class_names_ids, cid_index)
if not use_default_label:
num_classes = len(class_names)
content = ''
for cid in range(num_classes):
for cname in class_names_ids.keys():
if cid == class_names_ids[cname]:
content += cname + '\n'
break
if not os.path.exists('data/'): os.mkdir('data/')
with open(class_txt_name, 'w', encoding='utf-8') as f:
f.write(content)
f.close()
print('Done.')
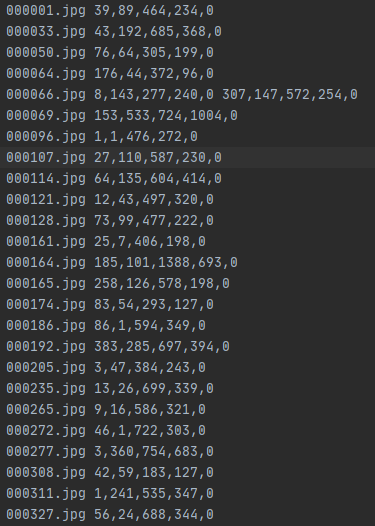
運行后生成一個annotation檔案夾,保存txt注解格式,如下圖,
自定義資料集的注解轉換成coco的注解格式
同樣新建一個1_txt2json.py檔案,輸入如下代碼,這段代碼參考了Github上的專案:https://github.com/miemie2013/Keras-YOLOv4,我在im_id處做了修改,以便于匹配訓練生成的image_id的格式,
#! /usr/bin/env python
# coding=utf-8
# ================================================================
#
# Author : miemie2013
# Created date: 2020-05-20 15:35:27
# Description : Convert annotation files (txt format) into coco json format.
# 自定義資料集的注解轉換成coco的注解格式,生成的json注解檔案在annotation_json目錄下,
#
# ================================================================
import os
import cv2
import json
import copy
import shutil
def get_classes(classes_path):
with open(classes_path) as f:
class_names = f.readlines()
class_names = [c.strip() for c in class_names]
return class_names
def write_json(txt_path, img_path, base_json, anno_name, im_id, anno_id):
target_json = copy.deepcopy(base_json)
with open(txt_path) as f:
txt_lines = f.readlines()
images = []
annos = []
for line in txt_lines:
anno_list = line.split()
ndarr = cv2.imread(img_path + anno_list[0])
img_h, img_w, _ = ndarr.shape
im_id=int((((line.split())[0]).split("."))[0])
image = {
'license': 1,
'file_name': anno_list[0],
'coco_url': 'a',
'height': img_h,
'width': img_w,
'date_captured': 'a',
'flickr_url': 'a',
'id': im_id,
}
images.append(image)
for p in range(1, len(anno_list), 1):
bbox = anno_list[p].split(',')
x1 = float(bbox[0])
y1 = float(bbox[1])
x2 = float(bbox[2])
y2 = float(bbox[3])
cid = int(bbox[4])
w = x2 - x1
h = y2 - y1
anno = {
'segmentation': [[x2, y2, x2, y1, x1, y1, x1, y2, x2, y2]],
'area': w*h,
'iscrowd': 0,
'image_id': im_id,
'bbox': [x1, y1, w, h],
'category_id': cid,
'id': anno_id,
}
annos.append(anno)
anno_id += 1
#im_id += 1
target_json['annotations'] = annos
target_json['images'] = images
filename = anno_name[0] #這里我根據自己存放測驗集的txt格式做了修改
if '/' in anno_name[0]:
filename = anno_name[0].split('/')[-1]
with open('annotation_json/%s.json' % filename, 'w') as f2:
json.dump(target_json, f2)
return im_id, anno_id
if __name__ == '__main__':
# 自定義資料集的注解轉換成coco的注解格式,只需改下面7個即可,檔案夾下的子目錄(子檔案)用/隔開,而不能用\或\\,
train_path = 'annotation/voc2007_train.txt'
val_path = 'annotation/voc2007_val.txt'
test_path = 'annotation/voc2007_test.txt' # 如果沒有測驗集,填None;如果有測驗集,填txt注解檔案的路徑,
classes_path = 'model_data/voc_classes.txt'
train_pre_path = 'VOCdevkit/VOC2007/JPEGImages/' # 訓練集圖片相對路徑
val_pre_path = 'VOCdevkit/VOC2007/JPEGImages/' # 驗證集圖片相對路徑
test_pre_path = 'VOCdevkit/VOC2007/JPEGImages/' # 測驗集圖片相對路徑
# 創建json注解目錄
if os.path.exists('annotation_json/'): shutil.rmtree('annotation_json/')
os.mkdir('annotation_json/')
train_anno_name = train_path.split('.')
val_anno_name = val_path.split('.')
print('Convert annotation files (txt format) into coco json format...')
info = {
'description': 'My dataset',
'url': 'https://github.com/miemie2013',
'version': '1.0',
'year': '2020',
'contributor': 'miemie2013',
'date_created': '2020/06/01',
}
licenses_0 = {
'url': 'https://github.com/miemie2013',
'id': 1,
'name': 'miemie2013 license',
}
licenses = [licenses_0]
categories = []
class_names = get_classes(classes_path)
num_classes = len(class_names)
for cid in range(num_classes):
cate = {
'supercategory': 'object',
'id': cid,
'name': class_names[cid],
}
categories.append(cate)
base_json = {
'info': info,
'licenses': licenses,
'categories': categories,
}
im_id = 0
anno_id = 0
# train set
im_id, anno_id = write_json(train_path, train_pre_path, base_json, train_anno_name, im_id, anno_id)
# val set
im_id, anno_id = write_json(val_path, val_pre_path, base_json, val_anno_name, im_id, anno_id)
# test set
if test_path is not None:
test_anno_name = test_path.split('.')
im_id, anno_id = write_json(test_path, test_pre_path, base_json, test_anno_name, im_id, anno_id)
print('Done.')
運行后生成的json注解檔案在專案檔案夾的annotation_json目錄下,格式如下,該檔案就是標注集的json檔案,記住它的路徑,

生成結果集的json檔案
安裝darknet
在終端輸入命令從github上clone原始碼,或者從該鏈接直接下載.zip檔案,
git clone https://github.com/pjreddie/darknet.git
darknet檔案格式如下:
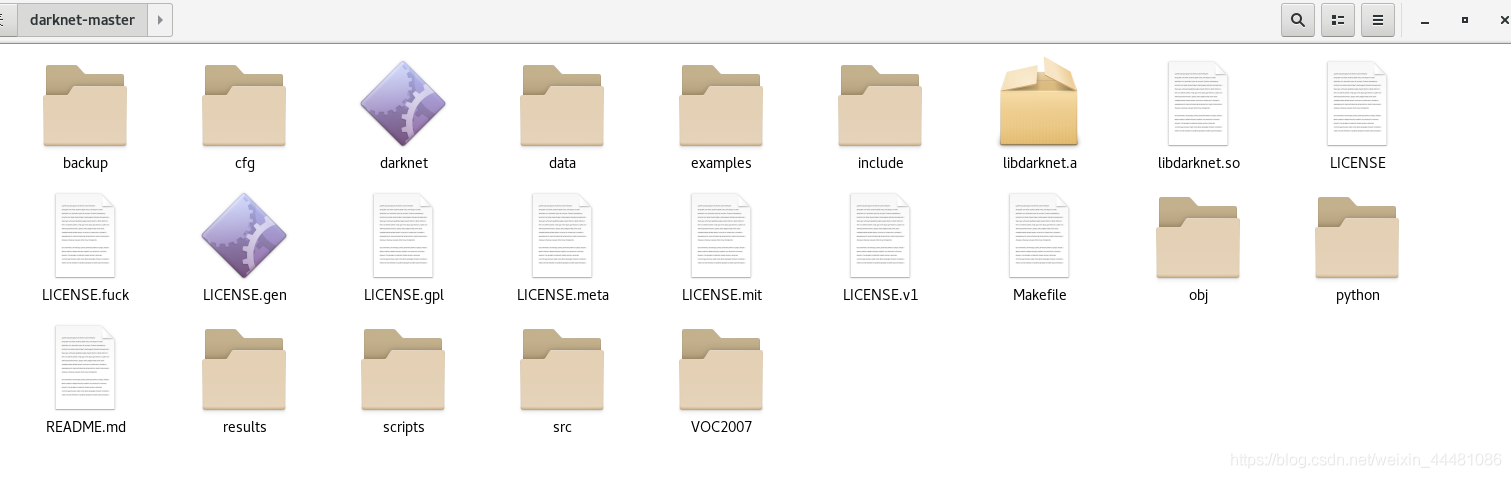
想要用GPU進行檢測的可以將darknet-master/Makefile檔案中第一行的GPU=0改為GPU=1,我這里沒有進行修改,進入到darknet檔案中
cd darknet
編譯(windows系統需要自行下載Cygwin,參考https://blog.csdn.net/chunleixiahe/article/details/55666792來安裝,使得darknet可以編譯)
make
編譯結束后,會產生darknet.exe、libdarknet.a、libdarknet.so檔案,將darknet.exe所在檔案夾添加到環境變數當中去,即可使用darknet命令,
獲取自己模型的.weight檔案(將.h5檔案轉換成.weight檔案)
通常情況下,我們訓練好的YOLOv3模型都是.h5檔案,而后續生成COCO資料集需要的json檔案則需要用到.weight檔案,所以需要進行轉換,
這里參考文章https://blog.csdn.net/qinchang1/article/details/105776132,將自己訓練好的.h5檔案轉換成.weight檔案,(注意修改model_path為自己的.h5檔案名稱)
轉換完會生成自己的.weight檔案,復制到darknet-master/backup當中去,

將影像以coco格式重命名
作者在檢測時發現按照原來的000001.jpg格式命名,在識別image_id時會出錯,所以要更改命名方式,將自己需要測驗的資料集批量重命名為COCO_VOC2007_000001.jpg這種格式,
創建一個convert.py將上面的VOC2007/ImageSets/Main/test.txt轉換成保存影像路徑的txt,注意根據自己的實際情況修改路徑,運行該腳本會生成ntest.txt檔案,
ftest = open('VOC2007/test.txt', 'r')
lines = ftest.readlines()
ftest.close()
ftest = open('VOC2007/test.txt', 'w')
for line in lines:
line_new="VOC2007/JPEGImages/COCO_VOC2007_"+line
ftest.write(line_new)
ff = open('VOC2007/ntest.txt','w') #打開一個檔案,可寫模式
with open('VOC2007/test.txt','r') as f: #打開一個檔案只讀模式
line = f.readlines()
for line_list in line:
line_new =line_list.replace('\n','')
line_new=line_new+r'.jpg'+'\n'
ff.write(line_new)
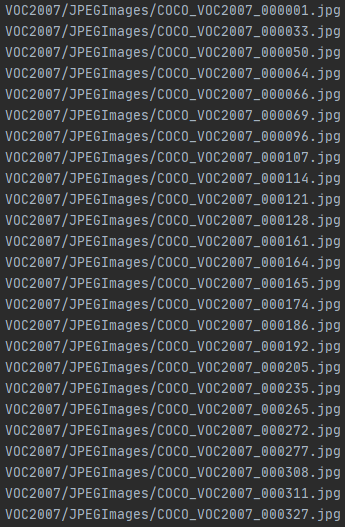
ntest.txt檔案格式如下:
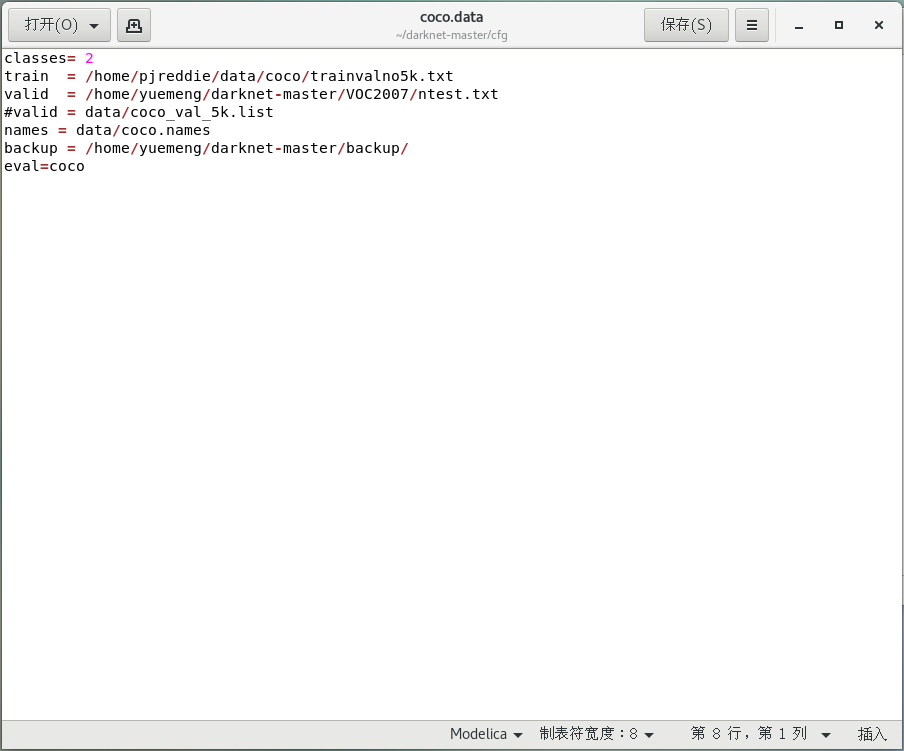
修改coco.data中的路徑
打開darknet/cfg/coco.data,這里只需要用到valid,所以把valid的值改為保存影像路徑的txt的路徑,把classes改為你的資料集包含的物體類別數,
打開data/coco.names檔案,將內容修改為自己模型的物體類別名稱,
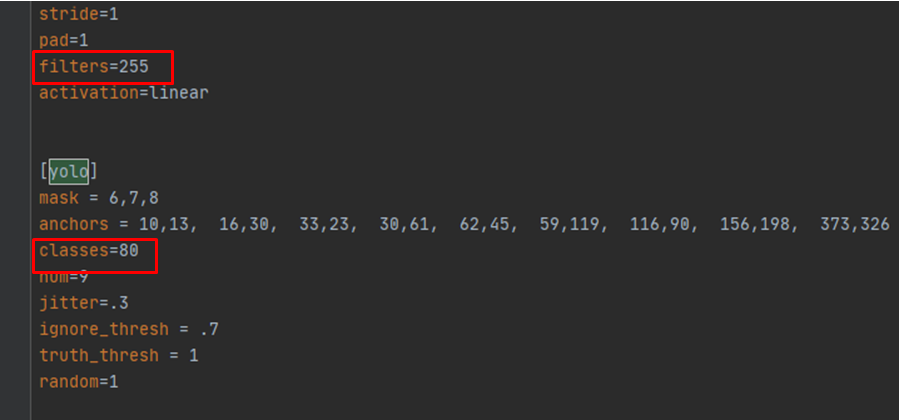
修改yolov3.cfg檔案
打開darknet/cfg/yolov3.cfg檔案,搜索yolo,一共搜索到三處,每一處都做如下修改:
1.filters =3*(5+classes) (注意這里要寫計算出來的具體數字,例如classes是2,這里就改為21,否則后面會報錯)
2.classes=2(你訓練的模型的類別個數)
進行檢測并生成json檔案
在終端運行(作者嘗試了在Win10系統運行,但記憶體始終報錯,于是轉到Linux系統):
./darknet detector valid cfg/coco.data cfg/yolov3.cfg backup/yolov3.weights
運行完成后結果保存在results/coco_results.json檔案中,即結果集的json檔案,將該檔案復制到自己的專案檔案夾下,并記住該路徑,
測驗mAP步驟
得到兩個json檔案后,在自己的專案檔案夾下創建一個coco_compute_mAP.py檔案,根據自己存放的路徑對cocoGt_file和cocoDt_file進行修改,
#-*- coding:utf-8 -*-
import matplotlib.pyplot as plt
from pycocotools.coco import COCO
from pycocotools.cocoeval import COCOeval
import numpy as np
import skimage.io as io
import pylab,json
pylab.rcParams['figure.figsize'] = (10.0, 8.0)
def get_img_id(file_name):
ls = []
myset = []
annos = json.load(open(file_name, 'r'))
for anno in annos:
ls.append(anno['image_id'])
myset = {}.fromkeys(ls).keys()
return myset
if __name__ == '__main__':
annType = ['segm', 'bbox', 'keypoints']#set iouType to 'segm', 'bbox' or 'keypoints'
annType = annType[1] # specify type here
cocoGt_file = 'annotation_json/voc2007_test.json' #需要根據自己的實際情況配置該路徑
cocoGt = COCO(cocoGt_file)#取得標注集中coco json物件
cocoDt_file = 'results/coco_results.json' #需要根據自己的實際情況配置該路徑
imgIds = get_img_id(cocoDt_file)
print(len(imgIds))
cocoDt = cocoGt.loadRes(cocoDt_file)#取得結果集中image json物件
imgIds = sorted(imgIds)#按順序排列coco標注集image_id
imgIds = imgIds[0:5000]#標注集中的image資料
cocoEval = COCOeval(cocoGt, cocoDt, annType)
cocoEval.params.imgIds = imgIds#引數設定
cocoEval.evaluate()#評價
cocoEval.accumulate()#積累
cocoEval.summarize()#總結
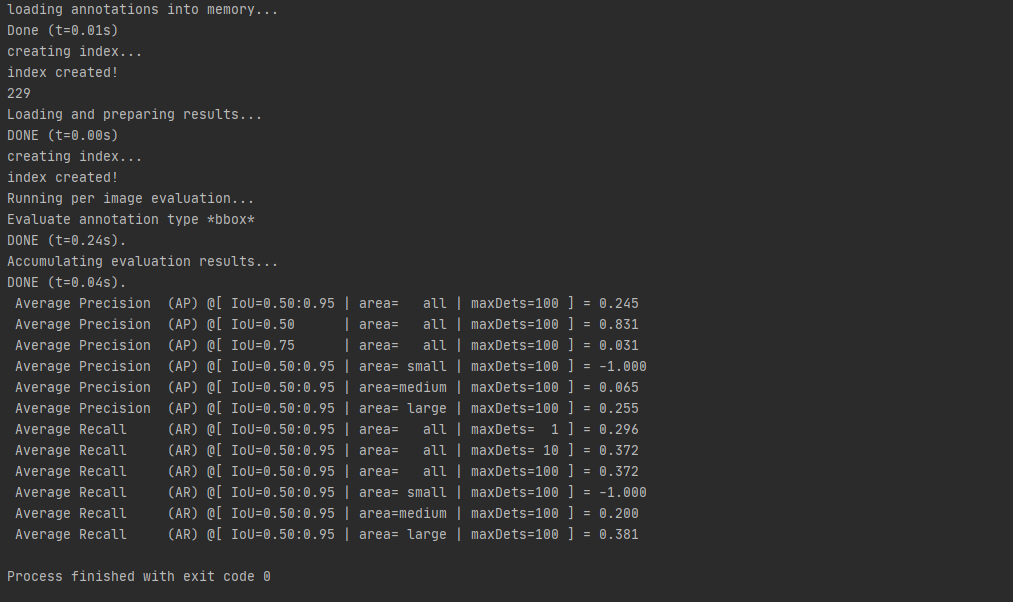
運行該腳本得到mAP的計算結果:
錯誤問題解決
1.【pycocotools報TypeError: object of type class numpy.float64 cannot be safely interpreted as an int】
https://blog.csdn.net/sinat_29957455/article/details/106481297
將507行和508行都做上述修改
2.【檢測時報"cannot load image "./JPEGImages/000001.jpg
STB Reason: unknown image type images】
https://blog.csdn.net/weixin_30840573/article/details/94896855
圖片打開出現錯誤,視情況將后綴改為.png / 將webp格式轉換為.jpg格式
3.【檢測時報:STB Reason: can‘t fopen】
https://blog.csdn.net/pursuit_zhangyu/article/details/107604731
【如有其他錯誤歡迎留言討論,但是我也不一定會…?▽?】
參考博文及Github專案(十分感謝!)
1.COCOAPI評估Yolov3,計算mAP
https://blog.csdn.net/SongJ12345666/article/details/108452730
2.計算YOLOv3在COCO資料集上的mAP值
https://blog.csdn.net/huangxiang360729/article/details/105853200/
3.利用COCOAPI計算Yolov3訓練出的模型的MAP值,復現ap
https://blog.csdn.net/xidaoliang/article/details/88397280
4.【YOLO】如何將Keras訓練的模型用于OpenCV中(.h5檔案轉換成.weights檔案)
https://blog.csdn.net/qinchang1/article/details/105776132
5.Github:Keras-YOLOv4
https://github.com/miemie2013/Keras-YOLOv4
6.目標檢測模型的評估指標mAP詳解(附代碼)
https://zhuanlan.zhihu.com/p/37910324
作者第一次發布文章,在這個方面還屬于小白,以上內容難免會有錯誤,歡迎在評論區指正(??????)??
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/248101.html
標籤:python
上一篇:Python 環境安裝