引言
說到 C++ 的記憶體管理,我們可能會想到堆疊空間的本地變數、堆上通過 new 動態分配的變數以及全域命名空間的變數等,這些變數的分配位置都是由系統來控制管理的,而呼叫者只需要考慮變數的生命周期相關內容即可,而無需關心變數的具體布局,這對于普通軟體的開發已經足夠,但對于引擎開發而言,我們必須對記憶體有著更為精細的管理,
基礎概念
在文章的開篇,先對一些基礎概念進行簡單的介紹,以便能夠更好地理解后續的內容,
記憶體布局
C/C++的學習裙【七一二 二八四 七零五 】,無論你是小白還是進階者,是想轉行還是想入行都可以來了解一起進步一起學習!裙內有開發工具,很多干貨和技術資料分享!
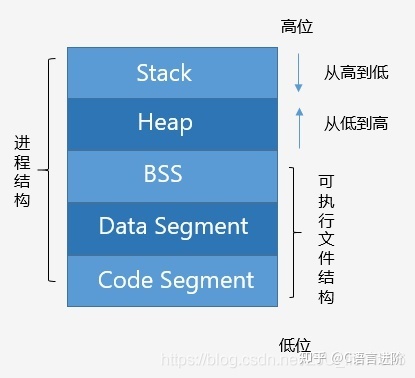
記憶體分布(可執行映像)
如圖,描述了C++程式的記憶體分布,
Code Segment(代碼區)
也稱Text Segment,存放可執行程式的機器碼,
Data Segment (資料區)
存放已初始化的全域和靜態變數, 常量資料(如字串常量),
BSS(Block started by symbol)
存放未初始化的全域和靜態變數,(默認設為0)
Heap(堆)
從低地址向高地址增長,容量大于堆疊,程式中動態分配的記憶體在此區域,
Stack(堆疊)
從高地址向低地址增長,由編譯器自動管理分配,程式中的區域變數、函式引數值、回傳變數等存在此區域,
函式堆疊
如上圖所示,可執行程式的檔案包含BSS,Data Segment和Code Segment,當可執行程式載入記憶體后,系統會保留一些空間,即堆區和堆疊區,堆區主要是動態分配的記憶體(默認情況下),而堆疊區主要是函式以及區域變數等(包括main函式),一般而言,堆疊的空間小于堆的空間,
當呼叫函式時,一塊連續記憶體(堆疊幀)壓入堆疊;函式回傳時,堆疊幀彈出,
堆疊幀包含如下資料:
① 函式回傳地址
② 區域變數/CPU暫存器資料備份
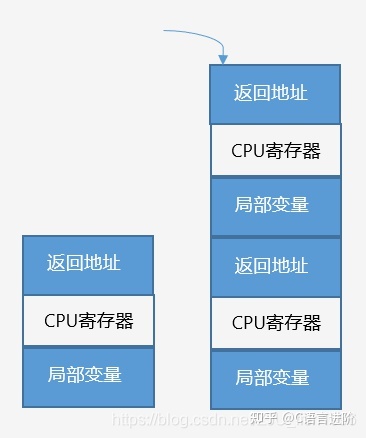
函式壓堆疊
全域變數
當全域/靜態變數(如下代碼中的x和y變數)未初始化的時候,它們記錄在BSS段,
int x;
int z = 5;
void func()
{
static int y;
}
int main()
{
return 0;
}處于BSS段的變數的值默認為0,考慮到這一點,BSS段內部無需存盤大量的零值,而只需記錄位元組個數即可,
系統載入可執行程式后,將BSS段的資料載入資料段(Data Segment) ,并將記憶體初始化為0,再呼叫程式入口(main函式),
而對于已經初始化了的全域/靜態變數而言,如以上代碼中的z變數,則一直存盤于資料段(Data Segment),
記憶體對齊
對于基礎型別,如float, double, int, char等,它們的大小和記憶體占用是一致的,而對于結構體而言,如果我們取得其sizeof的結果,會發現這個值有可能會大于結構體內所有成員大小的總和,這是由于結構體內部成員進行了記憶體對齊,
為什么要進行記憶體對齊
① 記憶體對齊使資料讀取更高效
在硬體設計上,資料讀取的處理器只能從地址為k的倍數的記憶體處開始讀取資料,這種讀取方式相當于將記憶體分為了多個"塊“,假設記憶體可以從任意位置開始存放的話,資料很可能會被分散到多個“塊”中,處理分散在多個塊中的資料需要移除首尾不需要的位元組,再進行合并,非常耗時,
為了提高資料讀取的效率,程式分配的記憶體并不是連續存盤的,而是按首地址為k的倍數的方式存盤;這樣就可以一次性讀取資料,而不需要額外的操作,

讀取非對齊記憶體的程序示例
② 在某些平臺下,不進行記憶體對齊會崩潰
記憶體對齊的規則
定義有效對齊值(alignment)為結構體中 最寬成員 和 編譯器/用戶指定對齊值 中較小的那個,
(1) 結構體起始地址為有效對齊值的整數倍
(2) 結構體總大小為有效對齊值的整數倍
(3) 結構體第一個成員偏移值為0,之后成員的偏移值為 min(有效對齊值, 自身大小) 的整數倍
相當于每個成員要進行對齊,并且整個結構體也需要進行對齊,
示例
struct A
{
int i;
char c1;
char c2;
};
int main()
{
cout << sizeof(A) << endl; // 有效對齊值為4, output : 8
return 0;
}
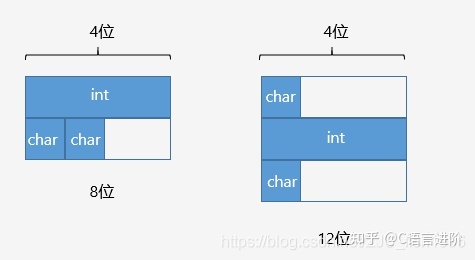
記憶體排布示例
C/C++的學習裙【七一二 二八四 七零五 】,無論你是小白還是進階者,是想轉行還是想入行都可以來了解一起進步一起學習!裙內有開發工具,很多干貨和技術資料分享!
記憶體碎片
程式的記憶體往往不是緊湊連續排布的,而是存在著許多碎片,我們根據碎片產生的原因把碎片分為內部碎片和外部碎片兩種型別:
(1) 內部碎片:系統分配的記憶體大于實際所需的記憶體(由于對齊機制);
(2) 外部碎片:不斷分配回收不同大小的記憶體,由于記憶體分布散亂,較大記憶體無法分配;
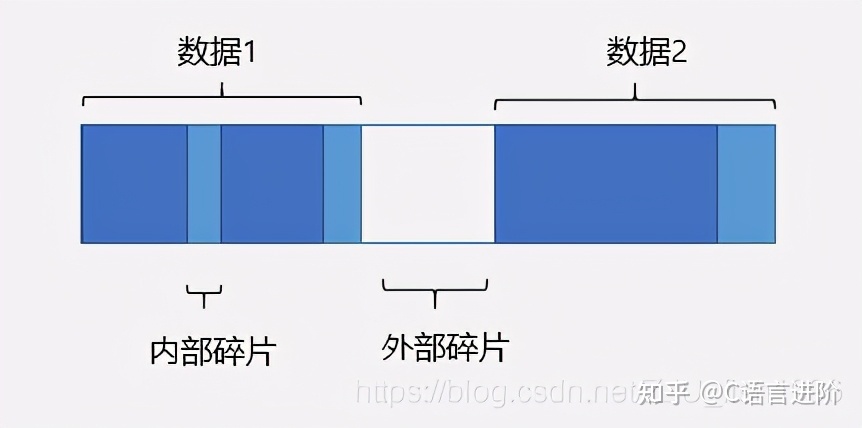
內部碎片和外部碎片
為了提高記憶體的利用率,我們有必要減少記憶體碎片,具體的方案將在后文重點介紹,
繼承類布局
繼承
如果一個類繼承自另一個類,那么它自身的資料位于父類之后,
含虛函式的類
如果當前類包含虛函式,則會在類的最前端占用4個位元組,用于存盤虛表指標(vpointer),它指向一個虛函式表(vtable),
vtable中包含當前類的所有虛函式指標,
位元組序(endianness)
大于一個位元組的值被稱為多位元組量,多位元組量存在高位有效位元組和低位有效位元組 (關于高位和低位,我們以十進制的數字來舉例,對于數字482來說,4是高位,2是低位),微處理器有兩種不同的順序處理高位和低位位元組的順序:
● 小端(little_endian):低位有效位元組存盤于較低的記憶體位置
● 大端(big_endian):高位有效位元組存盤于較低的記憶體位置
我們使用的PC開發機默認是小端存盤,
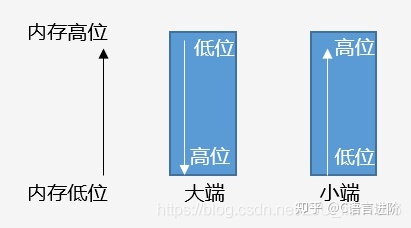
大小端排布
一般情況下,多位元組量的排列順序對編碼沒有影響,但如果要考慮跨平臺的一些操作,就有必要考慮到大小端的問題,如下圖,ue4引擎使用了PLATFORM_LITTLE_ENDIAN這一宏,在不同平臺下對資料做特殊處理(記憶體排布交換,確保存盤時的結果一致),
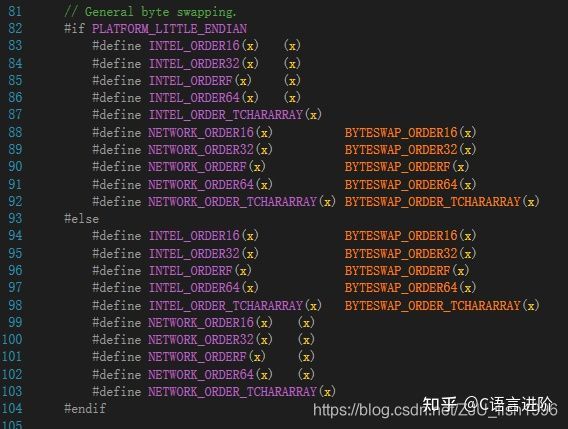
ue4針對大小端對資料做特殊處理(ByteSwap.h)
C/C++的學習裙【七一二 二八四 七零五 】,無論你是小白還是進階者,是想轉行還是想入行都可以來了解一起進步一起學習!裙內有開發工具,很多干貨和技術資料分享!
作業系統
對一些基礎概念有所了解后,我們可以來關注作業系統底層的一些設計,在掌握了這些特性后,我們才能更好地針對性地撰寫高性能代碼,
SIMD
SIMD,即Single Instruction Multiple Data,用一個指令并行地對多個資料進行運算,是CPU基本指令集的擴展,
例一
處理器的暫存器通常是32位或者64位的,而影像的一個像素點可能只有8bit,如果一次只能處理一個資料比較浪費空間;此時可以將64位暫存器拆成8個8位暫存器,就可以并行完成8個操作,提升效率,
例二
SSE指令采用128位暫存器,我們通常將4個32位浮點值打包到128位暫存器中,單個指令可完成4對浮點數的計算,這對于矩陣/向量操作非常友好(除此之外,還有Neon/FPU等暫存器)
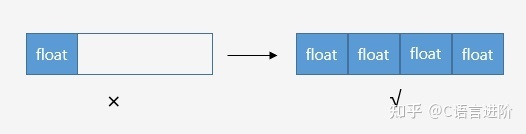
SIMD并行計算
高速快取
一般來說CPU以超高速運行,而記憶體速度慢于CPU,硬碟速度慢于記憶體,
當我們把資料加載記憶體后,要對資料進行一定操作時,會將資料從記憶體載入CPU暫存器,考慮到CPU讀/寫主記憶體速度較慢,處理器使用了高速的快取(Cache),作為記憶體到CPU中間的媒介,
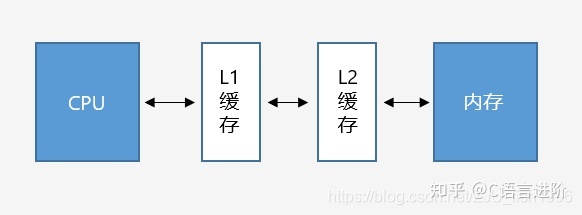
L1快取和L2快取
引入L1和L2快取后,CPU和記憶體之間的將無法進行直接的資料互動,而是需要經過兩級快取(目前也已出現L3快取),
① CPU請求資料:如果資料已經在快取中,則直接從快取載入暫存器;如果資料不在快取中(快取命中失敗),則需要從記憶體讀取,并將記憶體載入快取中,
② CPU寫入資料:有兩種方案,(1) 寫入到快取時同步寫入記憶體(write through cache) (2) 僅寫入到快取中,有必要時再寫入記憶體(write-back)
為了提高程式性能,則需要盡可能避免快取命中失敗,一般而言,遵循盡可能地集中連續訪問記憶體,減少”跳變“訪問的原則(locality of reference),這里其實隱含了兩個意思,一個是記憶體空間上要盡可能連續,另外一個是訪問時序上要盡可能連續,像節點式的資料結構的遍歷就會差于記憶體連續性的容器,
虛擬記憶體
虛擬記憶體,也就是把不連續的物理記憶體塊映射到虛擬地址空間(virtual address space),使記憶體頁對于應用程式來說看起來是連續的,一般而言,出于程式安全性和物理記憶體可能不足的考慮,我們的程式都會運行在虛擬記憶體上,
這意味著,每個程式都有自己的地址空間,我們使用的記憶體存在一個虛擬地址和一個物理地址,兩者之間需要進行地址翻譯,
缺頁
在虛擬記憶體中,每個程式的地址空間被劃分為多個塊,每個記憶體塊被稱作頁,每個頁的包含了連續的地址,并且被映射到物理記憶體,并非所有頁都在物理記憶體中,當我們訪問了不在物理記憶體中的頁時,這一現象稱為缺頁,作業系統會從磁盤將對應內容裝載到物理記憶體;當記憶體不足,部分頁也會寫回磁盤,
在這里,我們將CPU,高速快取和主存視為一個整體,統稱為DRAM,由于DRAM與磁盤之間的讀寫也比較耗時,為了提高程式性能,我們依然需要確保自己的程式具有良好的“區域性”——在任意時刻都在一個較小的活動頁面上作業,
分頁
當使用虛擬記憶體時,會通過MMU將虛擬地址映射到物理記憶體,虛擬記憶體的記憶體塊稱為頁,而物理記憶體中的記憶體塊稱為頁框,兩者大小一致,DRAM和磁盤之間以頁為單位進行交換,
簡單來說,如果想要從虛擬記憶體翻譯到物理地址,首先會從一個TLB(Translation Lookaside Buffer)的設備中查找,如果找不到,在虛擬地址中也記錄了虛擬頁號和偏移量,可以先通過虛擬頁號找到頁框號,再通過偏移量在對應頁框進行偏移,得到物理地址,為了加速這個翻譯程序,有時候還會使用多級頁表,倒排頁表等結構,
置換演算法
到目前為止,我們已經接觸了不少和“置換”有關的內容:例如暫存器和高速快取之間,DRAM和磁盤之間,以及TLB的快取等,這個問題的本質是,我們在有限的空間記憶體儲了一些快速查詢的結構,但是我們無法存盤所有的資料,所以當查詢未命中時,就需要花更大的代價,而所謂置換,也就是我們的快速查詢結構是在不斷更新的,會隨著我們的操作,使得一部分資料被裝在到快速查詢結構中,又有另一部分資料被卸載,相當于完成了資料的置換,
常見的置換有如下幾種:
● 最近未使用置換(NRU)
出現未命中現象時,置換最近一個周期未使用的資料,
● 先入先出置換(FIFO)
出現未命中現象時,置換最早進入的資料,
● 最近最少使用置換(LRU)
出現未命中現象時,置換未使用時間最長的資料,
C++語法
位域(Bit Fields)
表示結構體位域的定義,指定變數所占位數,它通常位于成員變數后,用 宣告符:常量運算式 表示,(參考資料)
宣告符是可選的,匿名欄位可用于填充,
以下是ue4中Float16的定義:
struct
{
#if PLATFORM_LITTLE_ENDIAN
uint16 Mantissa : 10;
uint16 Exponent : 5;
uint16 Sign : 1;
#else
uint16 Sign : 1;
uint16 Exponent : 5;
uint16 Mantissa : 10;
#endif
} Components;new和placement new
new是C++中用于動態記憶體分配的運算子,它主要完成了以下兩個操作:
① 呼叫operator new()函式,動態分配記憶體,
② 在分配的動態記憶體塊上呼叫建構式,以初始化相應型別的物件,并回傳首地址,
當我們呼叫new時,會在堆中查找一個足夠大的剩余空間,分配并回傳;當我們呼叫delete時,則會將該記憶體標記為不再使用,而指標仍然執行原來的記憶體,
new的語法
::(optional) new (placement_params)(optional) ( type ) initializer(optional) ● 一般運算式
p_var = new type(initializer); // p_var = new type{initializer};● 物件陣列運算式
p_var = new type[size]; // 分配
delete[] p_var; // 釋放● 二維陣列運算式
auto p = new double[2][2];
auto p = new double[2][2]{ {1.0,2.0},{3.0,4.0} };● 不拋出例外的運算式
new (nothrow) Type (optional-initializer-expression-list)默認情況下,如果記憶體分配失敗,new運算子會選擇拋出std::bad_alloc例外,如果加入nothrow,則不拋出例外,而是回傳nullptr,
● 占位符型別
我們可以使用placeholder type(如auto/decltype)指定型別:
auto p = new auto('c');● 帶位置的運算式(placement new)
可以指定在哪塊記憶體上構造型別,
它的意義在于我們可以利用placement new將記憶體分配和構造這兩個模塊分離(后續的allocator更好地踐行了這一概念),這對于撰寫記憶體管理的代碼非常重要,比如當我們想要撰寫記憶體池的代碼時,可以預申請一塊記憶體,然后通過placement new申請物件,一方面可以避免頻繁呼叫系統new/delete帶來的開銷,另一方面可以自己控制記憶體的分配和釋放,
預先分配的緩沖區可以是堆或者堆疊上的,一般按位元組(char)型別來分配,這主要考慮了以下兩個原因:
① 方便控制分配的記憶體大小(通過sizeof計算即可)
② 如果使用自定義型別,則會呼叫對應的建構式,但是既然要做分配和構造的分離,我們實際上是不期望它做任何構造操作的,而且對于沒有默認建構式的自定義型別,我們是無法預分配緩沖區的,
以下是一個使用的例子:
class A
{
private:
int data;
public:
A(int indata)
: data(indata) { }
void print()
{
cout << data << endl;
}
};
int main()
{
const int size = 10;
char buf[size * sizeof(A)]; // 記憶體分配
for (size_t i = 0; i < size; i++)
{
new (buf + i * sizeof(A)) A(i); // 物件構造
}
A* arr = (A*)buf;
for (size_t i = 0; i < size; i++)
{
arr[i].print();
arr[i].~A(); // 物件析構
}
// 堆疊上預分配的記憶體自動釋放
return 0;
}和陣列越界訪問不一定崩潰類似,這里如果在未分配的記憶體上執行placement new,可能也不會崩潰,
● 自定義引數的運算式
當我們呼叫new時,實際上執行了operator new運算子運算式,和其它函式一樣,operator new有多種多載,如上文中的placement new,就是operator new以下形式的一個多載:

placement new的定義
新語法(C++17)還支持帶對齊的operator new:
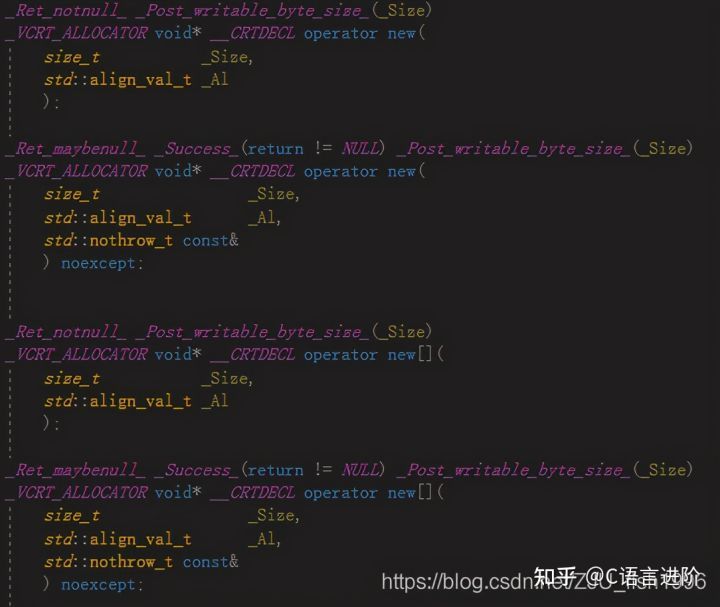
aligned new的宣告
呼叫示例:
auto p = new(std::align_val_t{ 32 }) A;new的多載
在C++中,我們一般說new和delete動態分配和釋放的物件位于自由存盤區(free store),這是一個抽象概念,默認情況下,C++編譯器會使用堆實作自由存盤,
前文已經提及了new的幾種多載,包括陣列,placement,align等,
如果我們想要實作自己的記憶體分配自定義操作,我們可以有如下兩個方式:
① 撰寫多載的operator new,這意味著我們的引數需要和全域operator new有差異,
② 重定義operator new,根據名字查找規則,會優先在申請記憶體的資料內部/資料定義處查找new運算子,未找到才會呼叫全域::operator new(),
需要注意的是,如果該全域operator new已經實作為inline函式,則我們不能重定義相關函式,否則無法通過編譯,如下:
// Default placement versions of operator new.
inline void* operator new(std::size_t, void* __p) throw() { return __p; }
inline void* operator new[](std::size_t, void* __p) throw() { return __p; }
// Default placement versions of operator delete.
inline void operator delete (void*, void*) throw() { }
inline void operator delete[](void*, void*) throw() { }但是,我們可以重寫如下nothrow的operator new:
void* operator new(std::size_t, const std::nothrow_t&) throw();
void* operator new[](std::size_t, const std::nothrow_t&) throw();
void operator delete(void*, const std::nothrow_t&) throw();
void operator delete[](void*, const std::nothrow_t&) throw();為什么說new是低效的
① 一般來說,操作越簡單,意味著封裝了更多的實作細節,new作為一個通用介面,需要處理任意時間、任意位置申請任意大小記憶體的請求,它在設計上就無法兼顧一些特殊場景的優化,在管理上也會帶來一定開銷,
② 系統呼叫帶來的開銷,多數作業系統上,申請記憶體會從用戶模式切換到內核模式,當前執行緒會block住,背景關系切換將會消耗一定時間,
③ 分配可能是帶鎖的,這意味著分配難以并行化,
alignas和alignof
不同的編譯器一般都會有默認的對齊量,一般都為2的冪次,
在C中,我們可以通過預編譯命令修改對齊量:
#pragma pack(n)在記憶體對齊篇已經提及,我們最終的有效對齊量會取結構體最寬成員 和 編譯器默認對齊量(或我們自己定義的對齊量)中較小的那個,
C++中也提供了類似的操作:
alignas
用于指定對齊量,
可以應用于類/結構體/union/列舉的宣告/定義;非位域的成員變數的定義;變數的定義(除了函式引數或例外捕獲的引數);
alignas會對對齊量做檢查,對齊量不能小于默認對齊,如下面的代碼,struct U的對齊設定是錯誤的:
struct alignas(8) S
{
// ...
};
struct alignas(1) U
{
S s;
};以下對齊設定也是錯誤的:
struct alignas(2) S {
int n;
};此外,一些錯誤的格式也無法通過編譯,如:
struct alignas(3) S { };例子:
// every object of type sse_t will be aligned to 16-byte boundary
struct alignas(16) sse_t
{
float sse_data[4];
};
// the array "cacheline" will be aligned to 128-byte boundary
alignas(128)
char cacheline[128];alignof operator
回傳型別的std::size_t,如果是參考,則回傳參考型別的對齊方式,如果是陣列,則回傳元素型別的對齊方式,
例子:
struct Foo {
int i;
float f;
char c;
};
struct Empty { };
struct alignas(64) Empty64 { };
int main()
{
std::cout << "Alignment of" "\n"
"- char :" << alignof(char) << "\n" // 1
"- pointer :" << alignof(int*) << "\n" // 8
"- class Foo :" << alignof(Foo) << "\n" // 4
"- empty class :" << alignof(Empty) << "\n" // 1
"- alignas(64) Empty:" << alignof(Empty64) << "\n"; // 64
}std::max_align_t
一般為16bytes,malloc回傳的記憶體地址,對齊大小不能小于max_align_t,
allocator
當我們使用C++的容器時,我們往往需要提供兩個引數,一個是容器的型別,另一個是容器的分配器,其中第二個引數有默認引數,即C++自帶的分配器(allocator):
template < class T, class Alloc = allocator<T> > class vector; // generic template我們可以實作自己的allocator,只需實作分配、構造等相關的操作,在此之前,我們需要先對allocator的使用做一定的了解,
new操作將記憶體分配和物件構造組合在一起,而allocator的意義在于將記憶體分配和構造分離,這樣就可以分配大塊記憶體,而只在真正需要時才執行物件創建操作,
假設我們先申請n個物件,再根據情況逐一給物件賦值,如果記憶體分配和物件構造不分離可能帶來的弊端如下:
① 我們可能會創建一些用不到的物件;
② 物件被賦值兩次,一次是默認初始化時,一次是賦值時;
③ 沒有默認建構式的類甚至不能動態分配陣列;
使用allocator之后,我們便可以解決上述問題,
分配
為n個string分配記憶體:
allocator<string> alloc; // 構造allocator物件
auto const p = alloc.allocate(n); // 分配n個未初始化的string構造
在剛才分配的記憶體上構造兩個string:
auto q = p;
alloc.construct(q++, "hello"); // 在分配的記憶體處創建物件
alloc.construct(q++, 10, 'c');銷毀
將已構造的string銷毀:
while(q != p)
alloc.destroy(--q);釋放
將分配的n個string記憶體空間釋放:
alloc.deallocate(p, n);注意:傳遞給deallocate的指標不能為空,且必須指向由allocate分配的記憶體,并保證大小引數一致,
拷貝和填充
uninitialized_copy(b, e, b2)
// 從迭代器b, e 中的元素拷貝到b2指定的未構造的原始記憶體中;
uninitialized_copy(b, n, b2)
// 從迭代器b指向的元素開始,拷貝n個元素到b2開始的記憶體中;
uninitialized_fill(b, e, t)
// 從迭代器b和e指定的原始記憶體范圍中創建物件,物件的值均為t的拷貝;
uninitialized_fill_n(b, n, t)
// 從迭代器b指向的記憶體地址開始創建n個物件;為什么stl的allocator并不好用
如果仔細觀察,我們會發現很多商業引擎都沒有使用stl中的容器和分配器,而是自己實作了相應的功能,這意味著allocator無法滿足某些引擎開發一些定制化的需求:
① allocator記憶體對齊無法控制
② allocator難以應用記憶體池之類的優化機制
③ 系結模板簽名
shared_ptr, unique_ptr和weak_ptr
智能指標是針對裸指標可能出現的問題封裝的指標類,它能夠更安全、更方便地使用動態記憶體,
shared_ptr
shared_ptr的主要應用場景是當我們需要在多個類中共享指標時,
多個類共享指標存在這么一個問題:每個類都存盤了指標地址的一個拷貝,如果其中一個類洗掉了這個指標,其它類并不知道這個指標已經失效,此時就會出現野指標的現象,為了解決這一問題,我們可以使用參考指標來計數,僅當檢測到參考計數為0時,才主動洗掉這個資料,以上就是shared_ptr的作業原理,
shared_ptr的基本語法如下:
初始化
shared_ptr<int> p = make_shared<int>(42);拷貝和賦值
auto p = make_shared<int>(42);
auto r = make_shared<int>(42);
r = q; // 遞增q指向的物件,遞減r指向的物件只支持直接初始化
由于接受指標引數的建構式是explicit的,因此不能將指標隱式轉換為shared_ptr:
shared_ptr<int> p1 = new int(1024); // err
shared_ptr<int> p2(new int(1024)); // ok不與普通指標混用
(1) 通過get()函式,我們可以獲取原始指標,但我們不應該delete這一指標,也不應該用它賦值/初始化另一個智能指標;
(2) 當我們將原生指標傳給shared_ptr后,就應該讓shared_ptr接管這一指標,而不再直接操作原生指標,
重新賦值
p.reset(new int(1024));unique_ptr
有時候我們會在函式域內臨時申請指標,或者在類中宣告非共享的指標,但我們很有可能忘記洗掉這個指標,造成記憶體泄漏,此時我們可以考慮使用unique_ptr,由名字可見,某一時刻只有一個unique_ptr指向給定的物件,且它會在析構的時候自動釋放對應指標的記憶體,
unique_ptr的基本語法如下:
初始化
unique_ptr<string> p = make_unique<string>("test");不支持直接拷貝/賦值
為了確保某一時刻只有一個unique_ptr指向給定物件,unique_ptr不支持普通的拷貝或賦值,
unique_ptr<string> p1(new string("test"));
unique_ptr<string> p2(p1); // err
unique_ptr<string> p3;
p3 = p2; // err所有權轉移
可以通過呼叫release或reset將指標的所有權在unique_ptr之間轉移:
unique_ptr<string> p2(p1.release());
unique_ptr<string> p3(new string("test"));
p2.reset(p3.release());不能忽視release回傳的結果
release回傳的指標通常用來初始化/賦值另一個智能指標,如果我們只呼叫release,而沒有洗掉其回傳值,會造成記憶體泄漏:
p2.release(); // err
auto p = p2.release(); // ok, but remember to delete(p)支持移動
unique_ptr<int> clone(int p) {
return unique_ptr<int>(new int(p));
}weak_ptr
weak_ptr不控制所指向物件的生存期,即不會影響參考計數,它指向一個shared_ptr管理的物件,通常而言,它的存在有如下兩個作用:
(1) 解決回圈參考的問題
(2) 作為一個“觀察者”:
詳細來說,和之前提到的多個類共享記憶體的例子一樣,使用普通指標可能會導致一個類洗掉了資料后其它類無法同步這一資訊,導致野指標;之前我們提出了shared_ptr,也就是每個類記錄一個參考,釋放時參考數減一,直到減為0才釋放,
但在有些情況下,我們并不希望當前類影響到參考計數,而是希望實作這樣的邏輯:假設有兩個類參考一個資料,其中有一個類將主動控制類的釋放,而無需等待另外一個類也釋放才真正銷毀指標所指物件,對于另一個類而言,它只需要知道這個指標已經失效即可,此時我們就可以使用weak_ptr,
我們可以像如下這樣檢測weak_ptr所有物件是否有效,并在有效的情況下做相關操作:
auto p = make_shared<int>(42);
weak_ptr<int> wp(p);
if(shared_ptr<int> np = wp.lock())
{
// ...
}分配與管理機制
到目前為止,我們對記憶體的概念有了初步的了解,也掌握了一些基本的語法,接下來我們要討論如何進行有效的記憶體管理,
設計高效的記憶體分配器通常會考慮到以下幾點:
① 盡可能減少記憶體碎片,提高記憶體利用率
② 盡可能提高記憶體的訪問區域性
③ 設計在不同場合上適用的記憶體分配器
④ 考慮到記憶體對齊
含freelist的分配器
我們首先來考慮一種能夠處理任何請求的通用分配器,
一個非常樸素的想法是,對于釋放的記憶體,通過鏈表將空閑記憶體鏈接起來,稱為freelist,
分配記憶體時,先從freelist中查找是否存在滿足要求的記憶體塊,如果不存在,再從未分配記憶體中獲取;當我們找到合適的記憶體塊后,分配合適的記憶體,并將多余的部分放回freelist,
釋放記憶體時,將記憶體插入到空閑鏈表,可能的話,合并前后記憶體塊,
其中,有一些細節問題值得考慮:
① 空閑空間應該如何進行管理?
我們知道freelist是用于管理空閑記憶體的,但是freelist本身的存盤也需要占用記憶體,我們可以按如下兩種方式存盤freelist:
● 隱式空閑鏈表
將空閑鏈表資訊與記憶體塊存盤在一起,主要記錄大小,已分配位等資訊,
● 顯式空閑鏈表
單獨維護一塊空間來記錄所有空閑塊資訊,
● 分離適配(segregated-freelist)
將不同大小的記憶體塊放在一起容易造成外部碎片,可以設定多個freelist,并讓每個freelist存盤不同大小的記憶體塊,申請記憶體時選擇滿足條件的最小記憶體塊,
● 位圖
除了freelist之外,還可以考慮用0,1表示對應記憶體區域是否已分配,稱為位圖,
② 分配記憶體優先分配哪塊記憶體?
一般而言,從策略不同來分,有以下幾種常見的分配方式:
● 首次適應(first-fit):找到的第一個滿足大小要求的空閑區
● 最佳適應(best-fit) : 滿足大小要求的最小空閑區
● 回圈首次適應(next-fit) :在先前停止搜索的地方開始搜索找到的第一個滿足大小要求的空閑區
③ 釋放記憶體后如何放置到空閑鏈表中?
● 直接放回鏈表頭部/尾部
● 按照地址順序放回
這幾種策略本質上都是取舍問題:分配/放回時間復雜度如果低,記憶體碎片就有可能更多,反之亦然,
buddy分配器
按照一分為二,二分為四的原則,直到分裂出一個滿足大小的記憶體塊;合并的時候看buddy是否空閑,如果是就合并,
可以通過位運算直接算出buddy,buddy的buddy,速度較快,但記憶體碎片較多,
含對齊的分配器
一般而言,對于通用分配器來說,都應當傳回對齊的記憶體塊,即根據對齊量,分配比請求多的對齊的記憶體,
如下,是ue4中計算對齊的方式,它回傳和對齊量向上對齊后的值,其中Alignment應為2的冪次,
template <typename T>
FORCEINLINE constexpr T Align(T Val, uint64 Alignment)
{
static_assert(TIsIntegral<T>::Value || TIsPointer<T>::Value, "Align expects an integer or pointer type");
return (T)(((uint64)Val + Alignment - 1) & ~(Alignment - 1));
}其中~(Alignment - 1) 代表的是高位掩碼,類似于11110000的格式,它將剔除低位,在對Val進行掩碼計算時,加上Alignment - 1的做法類似于(x + a) % a,避免Val值過小得到0的結果,
單幀分配器模型
用于分配一些臨時的每幀生成的資料,分配的記憶體僅在當前幀適用,每幀開始時會將上一幀的緩沖資料清除,無需手動釋放,
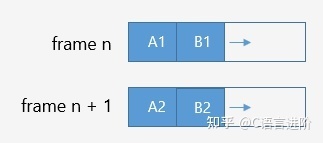
雙幀分配器模型
它的基本特點和單幀分配器相近,區別在于第i+1幀適用第i幀分配的記憶體,它適用于處理非同步的一些資料,避免當前緩沖區被重寫(同時讀寫)
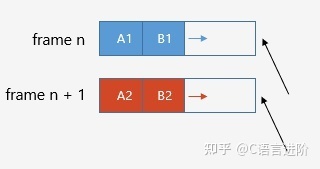
堆疊分配器模型
堆疊分配器,它的優點是實作簡單,并且完全避免了記憶體碎片,如前文所述,函式堆疊的設計也使用了堆疊分配器的模型,
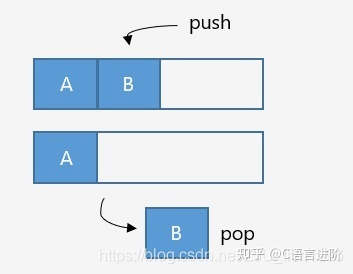
堆疊分配器
雙端堆疊分配器模型
可以從兩端開始分配記憶體,分別用于處理不同的事務,能夠更充分地利用記憶體,
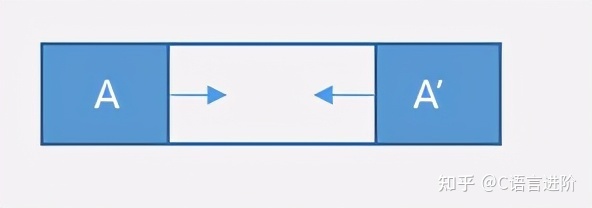
雙端堆疊分配器
池分配器模型
池分配器可以分配大量同尺寸的小塊記憶體,它的空閑塊也是由freelist管理的,但由于每個塊的尺寸一致,它的操作復雜度更低,且也不存在記憶體碎片的問題,
tcmalloc的記憶體分配
tcmalloc是一個應用比較廣泛的記憶體分配第三方庫,
對于大于頁結構和小于頁結構的記憶體塊申請,tcmalloc分別做不同的處理,
小于頁的記憶體塊分配
使用多個記憶體塊定長的freelist進行記憶體分配,如:8,16,32……,對實際申請的記憶體向上“取整”,
freelist采用隱式存盤的方式,
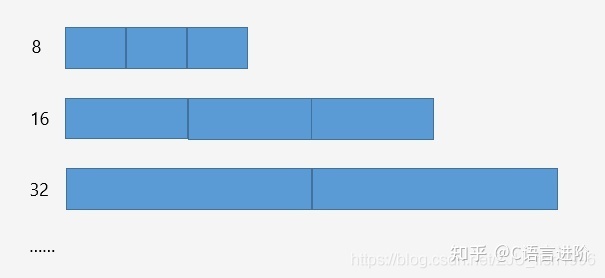
多個定長的freelist
大于頁的記憶體塊分配
可以一次申請多個page,多個page構成一個span,同樣的,我們使用多個定長的span鏈表來管理不同大小的span,

多個定長的spanlist
對于不同大小的物件,都有一個對應的記憶體分配器,稱為CentralCache,具體的資料都存盤在span內,每個CentralCache維護了對應的spanlist,如果一個span可以存盤多個物件,spanlist內部還會維護對應的freelist,
容器的訪問區域性
由于作業系統內部存在快取命中的問題,所以我們需要考慮程式的訪問區域性,這個訪問區域性實際上有兩層意思:
(1) 時間區域性:如果當前資料被訪問,那么它將在不久后很可能在此被訪問;
(2) 空間區域性:如果當前資料被訪問,那么它相鄰位置的資料很可能也被訪問;
我們來認識一下常用的幾種容器的記憶體布局:
陣列/順序容器:記憶體連續,訪問區域性良好;
map:內部是樹狀結構,為節點存盤,無法保證記憶體連續性,訪問區域性較差(flat_map支持順序存盤);
鏈表:初始狀態下,如果我們連續順序插入節點,此時我們認為記憶體連續,訪問較快;但通過多次插入、洗掉、交換等操作,鏈表結構變得散亂,訪問區域性較差;
碎片整理機制
記憶體碎片幾乎是不可完全避免的,當一個程式運行一定時間后,將會出現越來越多的記憶體碎片,一個優化的思路就是在引擎底層支持定期地整理記憶體碎片,
簡單來說,碎片整理通過不斷的移動操作,使所有的記憶體塊“貼合”在一起,為了處理指標可能失效的問題,可以考慮使用智能指標,
由于記憶體碎片整理會造成卡頓,我們可以考慮將整理操作分攤到多幀完成,
ue4記憶體管理
自定義記憶體管理

ue4的記憶體管理主要是通過FMalloc型別的GMalloc這一結構來完成特定的需求,這是一個虛基類,它定義了malloc,realloc,free等一系列常用的記憶體管理操作,其中,Malloc的兩個引數分別是分配記憶體的大小和對應的對齊量,默認對齊量為0,
/** The global memory allocator's interface. */
class CORE_API FMalloc :
public FUseSystemMallocForNew,
public FExec
{
public:
virtual void* Malloc( SIZE_T Count, uint32 Alignment=DEFAULT_ALIGNMENT ) = 0;
virtual void* TryMalloc( SIZE_T Count, uint32 Alignment=DEFAULT_ALIGNMENT );
virtual void* Realloc( void* Original, SIZE_T Count, uint32 Alignment=DEFAULT_ALIGNMENT ) = 0;
virtual void* TryRealloc(void* Original, SIZE_T Count, uint32 Alignment=DEFAULT_ALIGNMENT);
virtual void Free( void* Original ) = 0;
// ...
};FMalloc有許多不同的實作,如FMallocBinned,FMallocBinned2等,可以在HAL檔案夾下找到相關的頭檔案和定義,如下:
內部通過列舉量來確定對應使用的Allocator:
/** Which allocator is being used */
enum EMemoryAllocatorToUse
{
Ansi, // Default C allocator
Stomp, // Allocator to check for memory stomping
TBB, // Thread Building Blocks malloc
Jemalloc, // Linux/FreeBSD malloc
Binned, // Older binned malloc
Binned2, // Newer binned malloc
Binned3, // Newer VM-based binned malloc, 64 bit only
Platform, // Custom platform specific allocator
Mimalloc, // mimalloc
};對于不同平臺而言,都有自己對應的平臺記憶體管理類,它們繼承自FGenericPlatformMemory,封裝了平臺相關的記憶體操作,具體而言,包含FAndroidPlatformMemory,FApplePlatformMemory,FIOSPlatformMemory,FWindowsPlatformMemory等,
通過呼叫PlatformMemory的BaseAllocator函式,我們取得平臺對應的FMalloc型別,基類默認回傳默認的C allocator,而不同平臺會有自己特殊的實作,
在PlatformMemory的基礎上,為了方便呼叫,ue4又封裝了FMemory類,定義通用記憶體操作,如在申請記憶體時,會呼叫FMemory::Malloc,FMemory內部又會繼續呼叫GMalloc->Malloc,如下為節選代碼:
struct CORE_API FMemory
{
/** @name Memory functions (wrapper for FPlatformMemory) */
static FORCEINLINE void* Memmove( void* Dest, const void* Src, SIZE_T Count )
{
return FPlatformMemory::Memmove( Dest, Src, Count );
}
static FORCEINLINE int32 Memcmp( const void* Buf1, const void* Buf2, SIZE_T Count )
{
return FPlatformMemory::Memcmp( Buf1, Buf2, Count );
}
// ...
static void* Malloc(SIZE_T Count, uint32 Alignment = DEFAULT_ALIGNMENT);
static void* Realloc(void* Original, SIZE_T Count, uint32 Alignment = DEFAULT_ALIGNMENT);
static void Free(void* Original);
static SIZE_T GetAllocSize(void* Original);
// ...
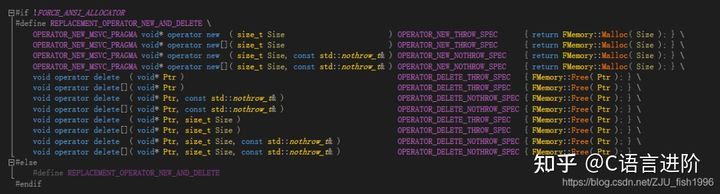
};為了在呼叫new/delete能夠呼叫ue4的自定義函式,ue4內部替換了operator new,這一替換是通過IMPLEMENT_MODULE宏引入的:

IMPLEMENT_MODULE通過定義REPLACEMENT_OPERATOR_NEW_AND_DELETE宏實作替換,如下圖所示,operator new/delete內實際呼叫被替換為FMemory的相關函式,
FMallocBinned
我們以FMallocBinned為例介紹ue4中通用記憶體的分配,
基本介紹
(1) 空閑記憶體如何管理?
FMallocBinned使用freelist機制管理空閑記憶體,每個空閑塊的資訊記錄在FFreeMem結構中,顯式存盤,
(2)不同大小記憶體如何分配?
FMallocBinned使用記憶體池機制,內部包含POOL_COUNT(42)個記憶體池和2個擴展的頁記憶體池;其中每個記憶體池的資訊由FPoolInfo結構體維護,記錄了當前FreeMem記憶體塊指標等,而特定大小的所有記憶體池由FPoolTable維護;記憶體池內包含了記憶體塊的雙向鏈表,
(3)如何快速根據分配元素大小找到對應的記憶體池?
為了快速查詢當前分配記憶體大小應該對應使用哪個記憶體池,有兩種辦法,一種是二分搜索O(logN),另一種是打表(O1),考慮到可分配記憶體數量并不大,MallocBinned選擇了打表的方式,將資訊記錄在MemSizeToPoolTable,
(4)如何快速洗掉已分配記憶體?
為了能夠在釋放的時候以O(1)時間找到對應記憶體池,FMallocBinned維護了PoolHashBucket結構用于跟蹤記憶體分配的記錄,它組織為雙向鏈表形式,存盤了對應記憶體塊和鍵值,
記憶體池
● 多個小物件記憶體池(記憶體池大小均為PageSize,但存盤的資料量不一樣),資料塊大小設定如下:
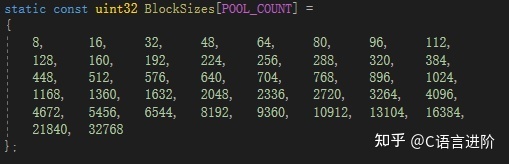
● 兩個額外的頁記憶體池,管理大于一個頁的記憶體池,大小為3*PageSize和6*PageSize
● 作業系統的記憶體池
分配策略
分配記憶體的函式為void* FMallocBinned::Malloc(SIZE_T Size, uint32 Alignment),
其中第一個引數為需要分配的記憶體的大小,第二個引數為對齊的記憶體數,
如果用戶未指定對齊的記憶體大小,MallocBinned內部會默認對齊于16位元組,如果指定了大于16位元組的對齊記憶體大小,則對齊于用戶指定的對齊大小,根據對齊量,計算出最終實際分配的記憶體大小,
MallocBinned內部對于不同的記憶體大小有三種不同的處理:
(1) 分配小塊記憶體(0,PAGE_SIZE_LIMIT/2)
根據分配大小從MemSizeToPoolTable中獲取對應記憶體池,并從記憶體池的當前空閑位置讀取一塊記憶體,并移動當前記憶體指標,如果移動后的記憶體指標指向的記憶體塊已經使用,則將指標移動到FreeMem鏈表的下一個元素;如果當前記憶體池已滿,將該記憶體池移除,并鏈接到耗盡的記憶體池,
如果當前記憶體池已經用盡,下次記憶體分配時,檢測到記憶體池用盡,會從系統重新申請一塊對應大小的記憶體池,
(2) 分配大塊記憶體 [PAGE_SIZE_LIMIT/2, PAGE_SIZE_LIMIT*3/4]∪(PageSize,PageSize + PAGE_SIZE_LIMIT/2)
需要從額外的頁記憶體池分配,分配方式和(1)一樣,
(3) 分配超大記憶體
從系統記憶體池中分配,
Allocator
對于ue4中的容器而言,它的模板有兩個引數,第一個是元素型別,第二個就是對應的分配器(Allocator):
template<typename InElementType, typename InAllocator>
class TArray
{
// ...
};如下圖,容器一般都指定了自己默認的分配器:
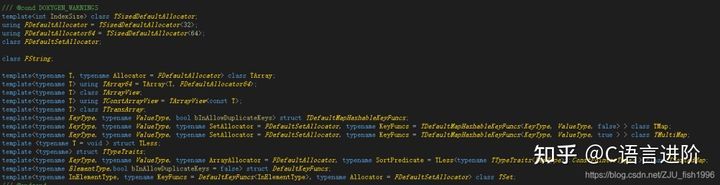
默認的堆分配器
template <int IndexSize>
class TSizedHeapAllocator { ... };
// Default Allocator
using FHeapAllocator = TSizedHeapAllocator<32>;默認情況下,如果我們不指定特定的Allocator,容器會使用大小型別為int32堆分配器,默認由FMemory控制分配(和new一致)
含對齊的分配器
template<uint32 Alignment = DEFAULT_ALIGNMENT>
class TAlignedHeapAllocator
{
// ...
};由FMemory控制分配,含對齊,
可擴展大小的分配器
template <uint32 NumInlineElements, typename SecondaryAllocator = FDefaultAllocator>
class TInlineAllocator
{
//...
};可擴展大小的分配器存盤大小為NumInlineElements的定長陣列,當實際存盤的元素數量高于NumInlineElements時,會從SecondaryAllocator申請分配記憶體,默認情況下為堆分配器,
對齊量總為DEFAULT_ALIGNMENT,
不可重定位的可擴展大小的分配器
template <uint32 NumInlineElements>
class TNonRelocatableInlineAllocator
{
// ...
};在支持第二分配器的基礎上,允許第二分配器存盤指向行內元素的指標,這意味著Allocator不應做指標重定向的操作,但ue4的Allocator通常依賴于指標重定向,因此該分配器不應用于其它Allocator容器,
固定大小的分配器
template <uint32 NumInlineElements>
class TFixedAllocator
{
// ...
};類似于InlineAllocator,會分配固定大小記憶體,區別在于當行內存盤耗盡后,不會提供額外的分配器,
稀疏陣列分配器
template<typename InElementAllocator = FDefaultAllocator,typename InBitArrayAllocator = FDefaultBitArrayAllocator>
class TSparseArrayAllocator
{
public:
typedef InElementAllocator ElementAllocator;
typedef InBitArrayAllocator BitArrayAllocator;
};稀疏陣列本身的定義比較簡單,它主要用于稀疏陣列(Sparse Array),相關的操作也在對應陣列類中完成,稀疏陣列支持不連續的下標索引,通過BitArrayAllocator來控制分配哪個位是可用的,能夠以O(1)的時間洗掉元素,
默認使用堆分配,
哈希分配器
template<
typename InSparseArrayAllocator = TSparseArrayAllocator<>,
typename InHashAllocator = TInlineAllocator<1,FDefaultAllocator>,
uint32 AverageNumberOfElementsPerHashBucket = DEFAULT_NUMBER_OF_ELEMENTS_PER_HASH_BUCKET,
uint32 BaseNumberOfHashBuckets = DEFAULT_BASE_NUMBER_OF_HASH_BUCKETS,
uint32 MinNumberOfHashedElements = DEFAULT_MIN_NUMBER_OF_HASHED_ELEMENTS
>
class TSetAllocator
{
public:
static FORCEINLINE uint32 GetNumberOfHashBuckets(uint32 NumHashedElements) { //... }
typedef InSparseArrayAllocator SparseArrayAllocator;
typedef InHashAllocator HashAllocator;
};用于TSet/TMap等結構的哈希分配器,同樣的實作比較簡單,具體的分配策略在TSet等結構中實作,其中SparseArrayAllocator用于管理Value,HashAllocator用于管理Key,Hash空間不足時,按照2的冪次進行擴展,
默認使用堆分配,
除了使用默認的堆分配器,稀疏陣列分配器和哈希分配器都有對應的可擴展大小(InlineAllocator)/固定大小(FixedAllocator)分配版本,
C/C++的學習裙【七一二 二八四 七零五 】,無論你是小白還是進階者,是想轉行還是想入行都可以來了解一起進步一起學習!裙內有開發工具,很多干貨和技術資料分享!
動態記憶體管理
TSharedPtr
template< class ObjectType, ESPMode Mode >
class TSharedPtr
{
// ...
private:
ObjectType* Object;
SharedPointerInternals::FSharedReferencer< Mode > SharedReferenceCount;
};TSharedPtr是ue4提供的類似stl sharedptr的解決方案,但相比起stl,它可由第二個模板引數控制是否執行緒安全,
如上所示,它基于類內的參考計數實作(SharedReferenceCount),為了確保多個TSharedPtr能夠同步當前參考計數的資訊,參考計數被設計為指標型別,在拷貝/構造/賦值等操作時,會增加或減少參考計數的值,當參考計數為0時將銷毀指標所指物件,
TSharedRef
template< class ObjectType, ESPMode Mode >
class TSharedRef
{
// ...
private:
ObjectType* Object;
SharedPointerInternals::FSharedReferencer< Mode > SharedReferenceCount;
};和TSharedPtr類似,但存盤的指標不可為空,創建時需同時初始化指標,類似于C++中的參考,
TRefCountPtr
template<typename ReferencedType>
class TRefCountPtr
{
// ...
private:
ReferencedType* Reference;
};TRefCountPtr是基于參考計數的共享指標的另一種實作,和TSharedPtr的差異在于它的參考計數并非智能指標類內維護的,而是基于物件的,相當于TRefCountPtr內部只存盤了對應的指標資訊(ReferencedType* Reference),
基于物件的參考計數,即參考計數存盤在物件內部,這是通過從FRefCountBase繼承引入的,這也就意味著TRefCountPtr參考的物件必須從FRefCountBase繼承,它的使用是有局限性的,
但是在如統計資源參考而判斷資源是否需要卸載的應用場景中,TRefCountPtr可手動添加/釋放參考,使用上更友好,
class FRefCountBase
{
public:
// ...
private:
mutable int32 NumRefs = 0;
};TWeakPtr
template< class ObjectType, ESPMode Mode >
class TWeakPtr
{
};類似的,TWeakObjectPtr是ue4提供的類似stl weakptr的解決方案,它將不影響參考計數,
TWeakObjectPtr
template<class T, class TWeakObjectPtrBase>
struct TWeakObjectPtr : private TWeakObjectPtrBase
{
// ...
};
struct FWeakObjectPtr
{
// ...
private:
int32 ObjectIndex;
int32 ObjectSerialNumber;
};特別的,由于UObject有對應的gc機制,TWeakObjectPtr為指向UObject的弱指標,用于查詢物件是否有效(是否被回收)
垃圾回收
C++語言本身并沒有垃圾回識訓制,ue4基于內部的UObject,單獨實作了一套GC機制,此處僅做簡單介紹,
首先,對于UObject相關物件,為了維持參考(防止被回收),通常使用UProperty()宏,使用容器(如TArray存盤),或呼叫AddToRoot的方法,
ue4的垃圾回收代碼實作位于GarbageCollection.cpp中的CollectGarbage函式中,這一函式會在游戲執行緒中被反復呼叫,要么在一些情況下手動呼叫,要么在游戲回圈Tick()中滿足條件時自動呼叫,
GC程序中,首先會收集所有不可到達的物件(無參考),
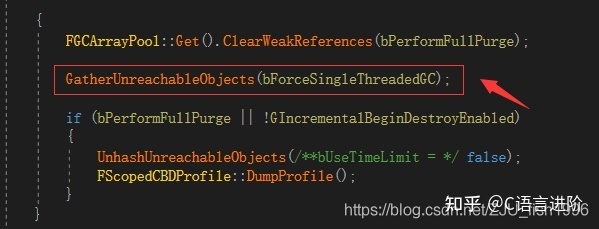
之后,根據當前情況,會在單幀(無時間限制)或多幀(有時間限制)的時間內,清理相關物件(IncrementalPurgeGarbage)
SIMD
合理的記憶體布局/對齊有利于SIMD的廣泛應用,在撰寫定義基礎型別/底層數學演算法庫時,我們通常有必要考慮到這一點,
我們可以參考ue4中封裝的sse初始化、加法、減法、乘法等操作,其中,__m128型別的變數需程式確保為16位元組對齊,它適用于浮點數存盤,大部分情況下存盤于記憶體中,計算時會在SSE暫存器中運用,
typedef __m128 VectorRegister;
FORCEINLINE VectorRegister VectorLoad( const void* Ptr )
{
return _mm_loadu_ps((float*)(Ptr));
}
FORCEINLINE VectorRegister VectorAdd( const VectorRegister& Vec1, const VectorRegister& Vec2 )
{
return _mm_add_ps(Vec1, Vec2);
}
FORCEINLINE VectorRegister VectorSubtract( const VectorRegister& Vec1, const VectorRegister& Vec2 )
{
return _mm_sub_ps(Vec1, Vec2);
}
FORCEINLINE VectorRegister VectorMultiply( const VectorRegister& Vec1, const VectorRegister& Vec2 )
{
return _mm_mul_ps(Vec1, Vec2);
}除了SSE外,ue4還針對Neon/FPU等暫存器封裝了統一的介面,這意味呼叫者可以無需考慮過多硬體的細節,
我們可以在多個數學運算庫中看到相關的呼叫,如球諧向量的相加:
/** Addition operator. */
friend FORCEINLINE TSHVector operator+(const TSHVector& A,const TSHVector& B)
{
TSHVector Result;
for(int32 BasisIndex = 0;BasisIndex < NumSIMDVectors;BasisIndex++)
{
VectorRegister AddResult = VectorAdd(
VectorLoadAligned(&A.V[BasisIndex * NumComponentsPerSIMDVector]),
VectorLoadAligned(&B.V[BasisIndex * NumComponentsPerSIMDVector])
);
VectorStoreAligned(AddResult, &Result.V[BasisIndex * NumComponentsPerSIMDVector]);
}
return Result;
原文鏈接:https://blog.csdn.net/zju_fish1996/article/details/108858577
如果大家如果在自學遇到困難,想找一個C++的學習環境,可以加入我們的C/C++技術交流群,點擊我加入吧~會節約很多時間,能夠在專業牛人大牛的幫助下,攻克很多在學習中遇到的難題,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/248835.html
標籤:C++
下一篇:C語言基礎知識:exit()函式