redis作為目前最流行的nosql快取資料庫,憑借其優異的性能、豐富的資料結構已成為大部分場景下首選的快取工具,
由于redis是一個純記憶體的資料庫,在存放大量資料時,記憶體的占用將會非常可觀,那么在一些場景下,通過選用合適的資料結構來存盤,可以大幅減少記憶體的占用,甚至于可以減少80%-99%的記憶體占用,
利用zipList來替代大量的Key-Value
先來看一下場景,在Dsp廣告系統、海量用戶系統經常會碰到這樣的需求,要求根據用戶的某個唯一標識迅速查到該用戶的id,譬如根據mac地址或uuid或手機號的md5,去查詢到該用戶的id,
特點是資料量很大、千萬或億級別,key是比較長的字串,如32位的md5或者uuid這種,
如果不加以處理,直接以key-value形式進行存盤,我們可以簡單測驗一下,往redis里插入1千萬條資料,1550000000 - 1559999999,形式就是key(md5(1550000000))→ value(1550000000)這種,
然后用info memory看一下記憶體占用,
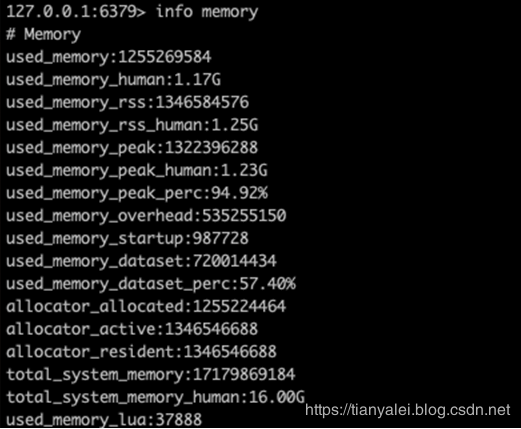
可以看到,這1千萬條資料,占用了redis共計1.17G的記憶體,當資料量變成1個億時,實測大約占用8個G,
同樣的一批資料,我們換一種存盤方式,先來看結果:
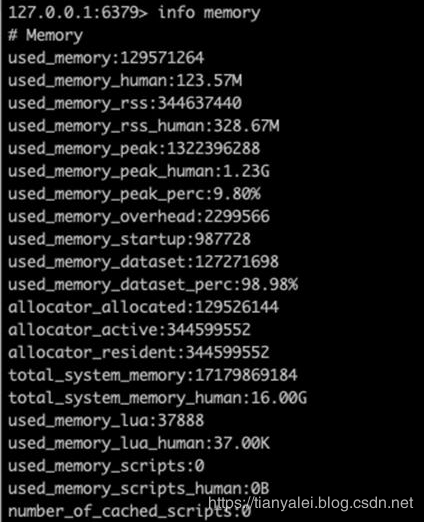
在我們利用zipList后,記憶體占用為123M,大約減少了85%的空間占用,這是怎么做到的呢?我們來從redis的底層存盤來剖析一下,
1 redis資料結構和編碼方式
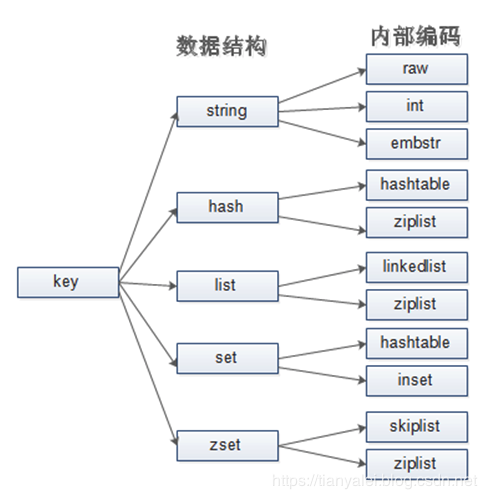
2 redis如何存盤字串
string是redis里最常用的資料結構,redis的默認字串和C語言的字串不同,它是自己構建了一種名為“簡單動態字串SDS”的抽象型別,

具體到string的底層存盤,redis共用了三種方式,分別是int、embstr和raw,
譬如set k1 abc和set k2 123就會分別用embstr、int,當value的長度大于44(或39,不同版本不一樣)個位元組時,會采用raw,
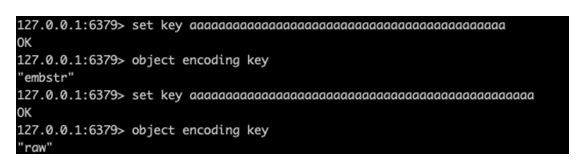
int是一種定長的結構,占8個位元組(注意,相當于java里的long),只能用來存盤長整形,
embstr是動態擴容的,每次擴容1倍,超過1M時,每次只擴容1M,
raw用來存盤大于44個位元組的字串,
具體到我們的案例中,key是32個位元組的字串(embstr),value是一個長整形(int),所以如果能將32位的md5變成int,那么在key的存盤上就可以直接減少3/4的記憶體占用,
這是第一個優化點,
3 redis如何存盤Hash
從1.1的圖上我們可以看到Hash資料結構,在編碼方式上有兩種,1是hashTable,2是zipList,
hashTable大家很熟悉,和java里的hashMap很像,都是陣列+鏈表的方式,java里hashmap為了減少hash沖突,設定了負載因子為0.75,同樣,redis的hash也有類似的擴容負載因子,細節不提,只需要留個印象,用hashTable編碼的話,則會花費至少大于存盤的資料25%的空間才能存下這些資料,它大概長這樣:
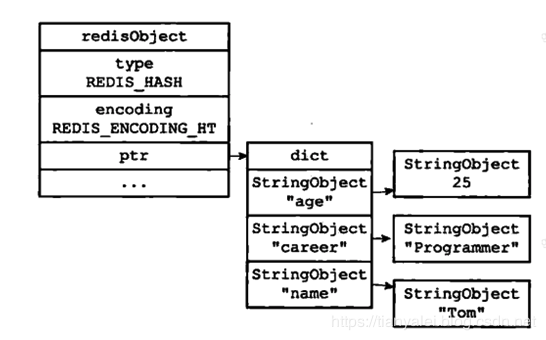
zipList,壓縮鏈表,它大概長這樣:

可以看到,zipList最大的特點就是,它根本不是hash結構,而是一個比較長的字串,將key-value都按順序依次擺放到一個長長的字串里來存盤,如果要找某個key的話,就直接遍歷整個長字串就好了,
所以很明顯,zipList要比hashTable占用少的多的空間,但是會耗費更多的cpu來進行查詢,
那么何時用hashTable、zipList呢?在redis.conf檔案中可以找到:
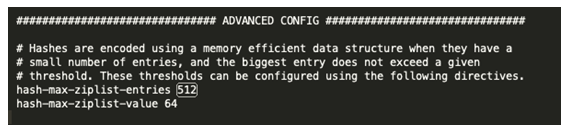
就是當這個hash結構的內層field-value數量不超過512,并且value的位元組數不超過64時,就使用zipList,
通過實測,value數量在512時,性能和單純的hashTable幾乎無差別,在value數量不超過1024時,性能僅有極小的降低,很多時候可以忽略掉,
而記憶體占用,zipList可比hashTable降低了極多,
這是第二個優化點,
4 用zipList來代替key-value
通過上面的知識,我們得出了兩個結論,用int作為key,會比string省很多空間,用hash中的zipList,會比key-value省巨大的空間,
那么我們就來改造一下當初的1千萬個key-value,
第一步:
我們要將1千萬個鍵值對,放到N個bucket中,每個bucket是一個redis的hash資料結構,并且要讓每個bucket內不超過默認的512個元素(如果改了組態檔,如1024,則不能超過修改后的值),以避免hash將編碼方式從zipList變成hashTable,
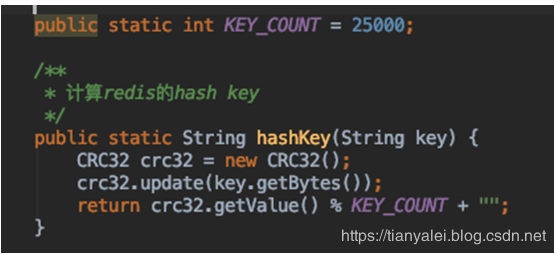
1千萬 / 512 = 19531,由于將來要將所有的key進行哈希演算法,來盡量均攤到所有bucket里,但由于哈希函式的不確定性,未必能完全平均分配,所以我們要預留一些空間,譬如我分配25000個bucket,或30000個bucket,
第二步:
選用哈希演算法,決定將key放到哪個bucket,這里我們采用高效而且均衡的知名演算法crc32,該哈希演算法可以將一個字串變成一個long型的數字,通過獲取這個md5型的key的crc32后,再對bucket的數量進行取余,就可以確定該key要被放到哪個bucket中,
第三步:
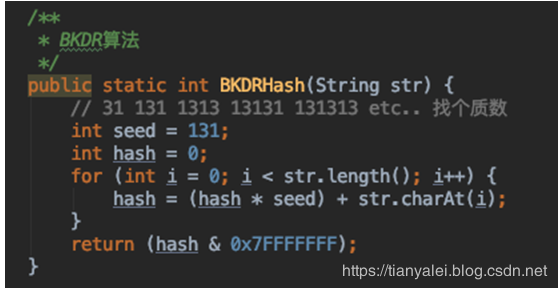
通過第二步,我們確定了key即將存放在的redis里hash結構的外層key,對于內層field,我們就選用另一個hash演算法,以避免兩個完全不同的值,通過crc32(key) % COUNT后,發生field再次相同,產生hash沖突導致值被覆寫的情況,內層field我們選用bkdr哈希演算法(或直接選用Java的hashCode),該演算法也會得到一個long整形的數字,value的存盤保持不變,
第四步:
裝入資料,原來的資料結構是key-value,0eac261f1c2d21e0bfdbd567bb270a68 → 1550000000,
現在的資料結構是hash,key為14523,field是1927144074,value是1550000000,
通過實測,將1千萬資料存入25000個bucket后,整體hash比較均衡,每個bucket下大概有300多個field-value鍵值對,理論上只要不發生兩次hash演算法后,均產生相同的值,那么就可以完全依靠key-field來找到原始的value,這一點可以通過計算總量進行確認,實際上,在bucket數量較多時,且每個bucket下,value數量不是很多,發生連續碰撞概率極低,實測在存盤50億個手機號情況下,未發生明顯碰撞,
測驗查詢速度:
在存盤完這1千萬個資料后,我們進行了查詢測驗,采用key-value型和hash型,分別查詢100萬條資料,看一下對查詢速度的影響,
key-value耗時:10653、10790、11318、9900、11270、11029毫秒
hash-field耗時:12042、11349、11126、11355、11168毫秒,
可以看到,整體上采用hash存盤后,查詢100萬條耗時,也僅僅增加了500毫秒不到,對性能的影響極其微小,但記憶體占用從1.1G變成了120M,帶來了接近90%的記憶體節省,
總結
大量的key-value,占用過多的key,redis里為了處理hash碰撞,需要占用更多的空間來存盤這些key-value資料,
如果key的長短不一,譬如有些40位,有些10位,因為對齊問題,那么將產生巨大的記憶體碎片,占用空間情況更為嚴重,所以,保持key的長度統一(譬如統一采用int型,定長8個位元組),也會對記憶體占用有幫助,
string型的md5,占用了32個位元組,而通過hash演算法后,將32降到了8個位元組的長整形,這顯著降低了key的空間占用,
zipList比hashTable明顯減少了記憶體占用,它的存盤非常緊湊,對查詢效率影響也很小,所以應善于利用zipList,避免在hash結構里,存放超過512個field-value元素,
如果value是字串、物件等,應盡量采用byte[]來存盤,同樣可以大幅降低記憶體占用,譬如可以選用google的Snappy壓縮演算法,將字串轉為byte[],非常高效,壓縮率也很高,
為減少redis對字串的預分配和擴容(每次翻倍),造成記憶體碎片,不應該使用append,setrange等,而是直接用set,替換原來的,
方案缺點:
hash結構不支持對單個field的超時設定,但可以通過代碼來控制洗掉,對于那些不需要超時的長期存放的資料,則沒有這種顧慮,
存在較小的hash沖突概率,對于對資料要求極其精確的場合,不適合用這種壓縮方式,
基于上述方案,我改寫了springboot原始碼的redisTemplate,提供了一個CompressRedisTemplate類,可以直接當成redisTemplate使用,它會自動將key-value轉為hash進行存盤,以達到上述目的,
后續,我們會基于更極端一些的場景,如統計獨立訪客等,來看一下redis的不常見的資料結構,是如何將記憶體占用由20G降低到5M,
歡迎關注公眾號 【碼農開花】一起學習成長
我會一直分享Java干貨,也會分享免費的學習資料課程和面試寶典
回復:【計算機】【設計模式】【面試】有驚喜哦
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/248855.html
標籤:Java
上一篇:快取,確實很香,卻也很受傷!