爬取嗶哩嗶哩每周必看欄目影片
前言
本次內容為爬取嗶哩嗶哩每周必看欄目影片,靈感來自于一位博主的評論,問能否爬取B站歷史排行榜資訊,便決定一試,不過B站上的排行耪都是動態更新的,因此沒有頭緒,自我感覺不能爬取歷史排行榜資訊!不過看到了一個欄目倒是有歷史的資訊,即圖中每周必看欄目,每周五定期更新,目前已更到94期,瞬間覺著是個不錯的較有挑戰的例子,便打算試上一試!于是乎~便有了本篇文章,詳情如下
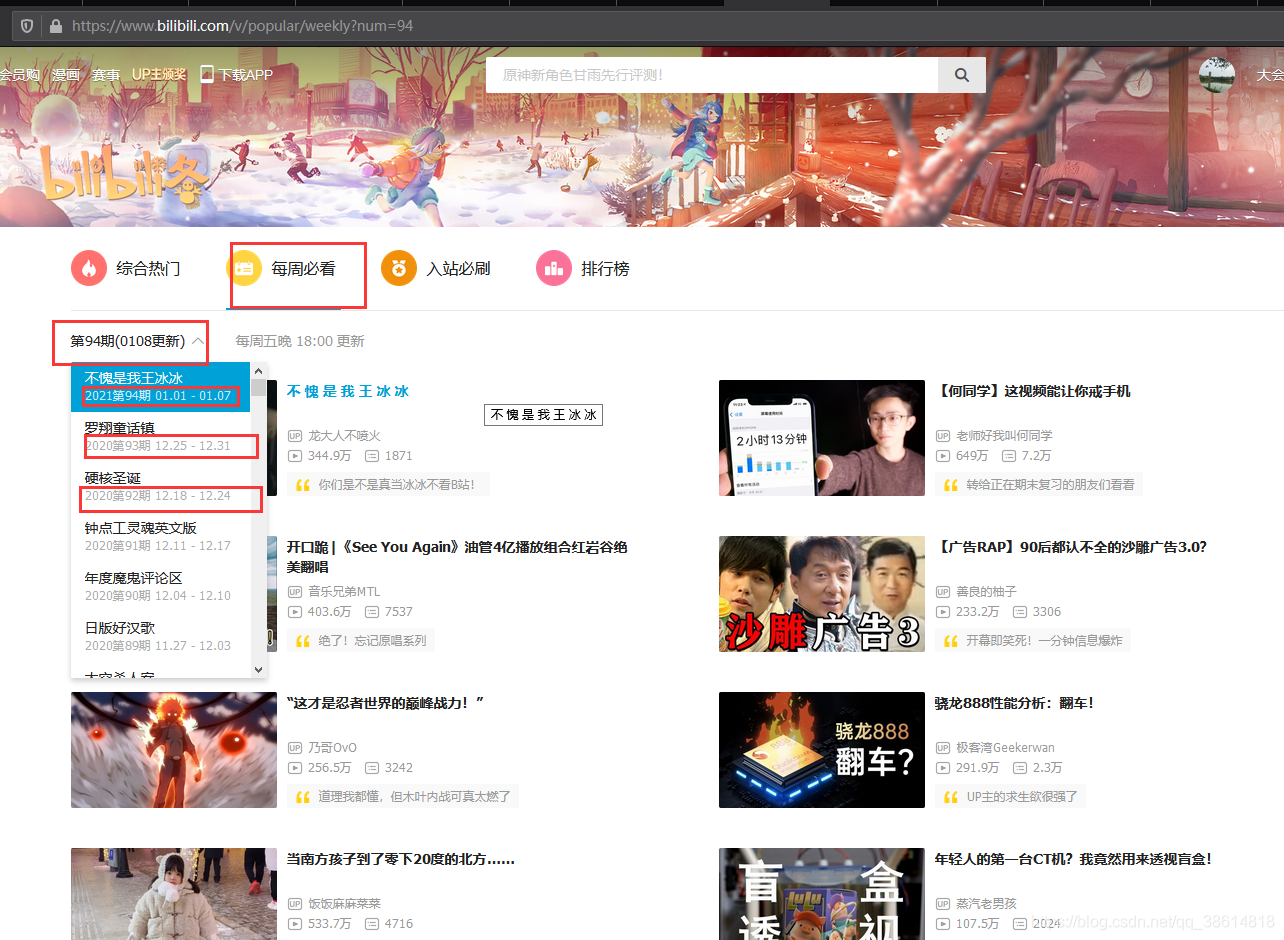
一、爬取程序
在爬取程序中,小編開始采用之前慣用的爬取方式,發現爬取的內容不是需要的資料,每次回傳的資料是各個排行榜的資料,整的挺郁悶,,,最后便采取了另外一種方式:1. 先獲取頁面的json資料;2. 然后對json資料進行處理;3. 最后存盤到excel表中,看似沒什么區別,哈哈哈,容我一一道來:
-
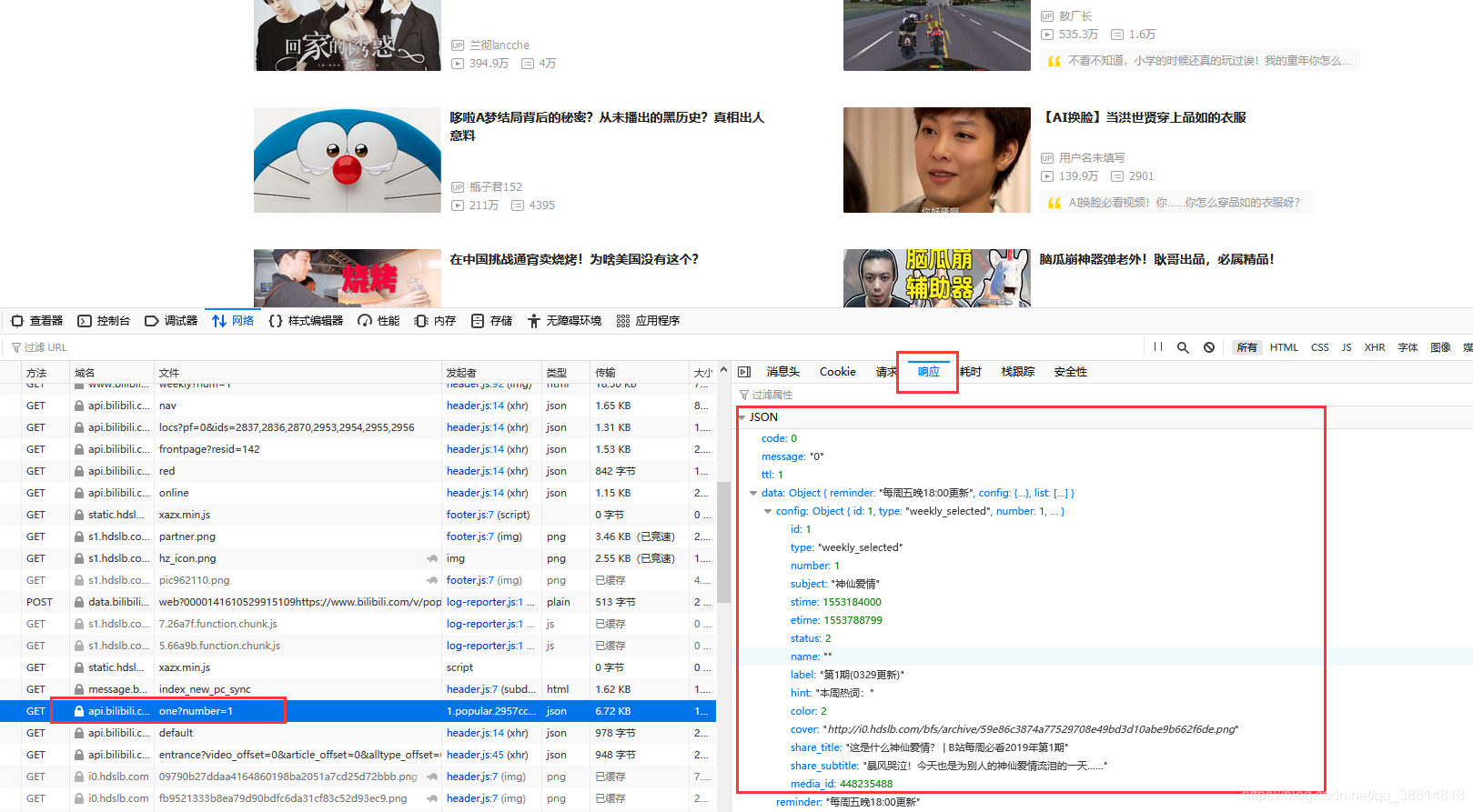
先獲取頁面的json資料:打開頁面,點擊F12—網路(network)----找到對應json資料
-
點擊訊息頭,復制請求的鏈接,復制完可以在瀏覽器中看一下是否是需要的資料,確定無誤,爬就完了
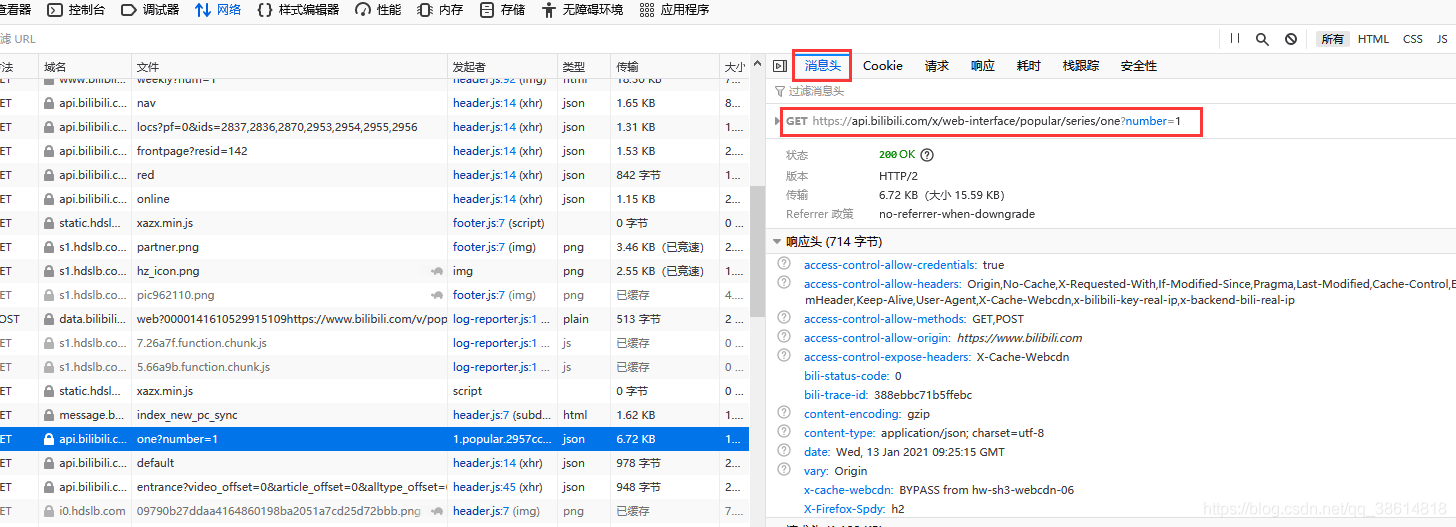
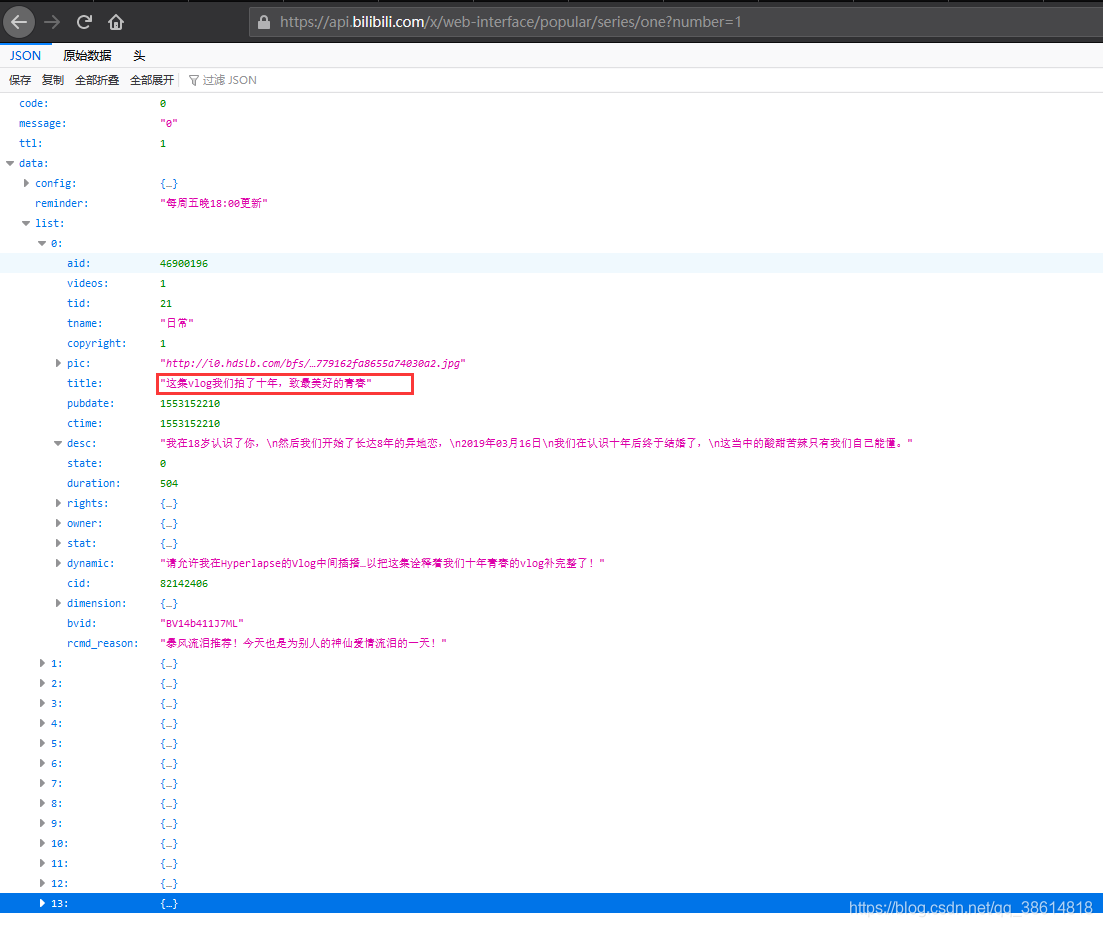
-
通過requests請求獲取到json資料后,根據對應的標簽,取自己想到的資料就行,小編獲取的是如下幾個資訊:
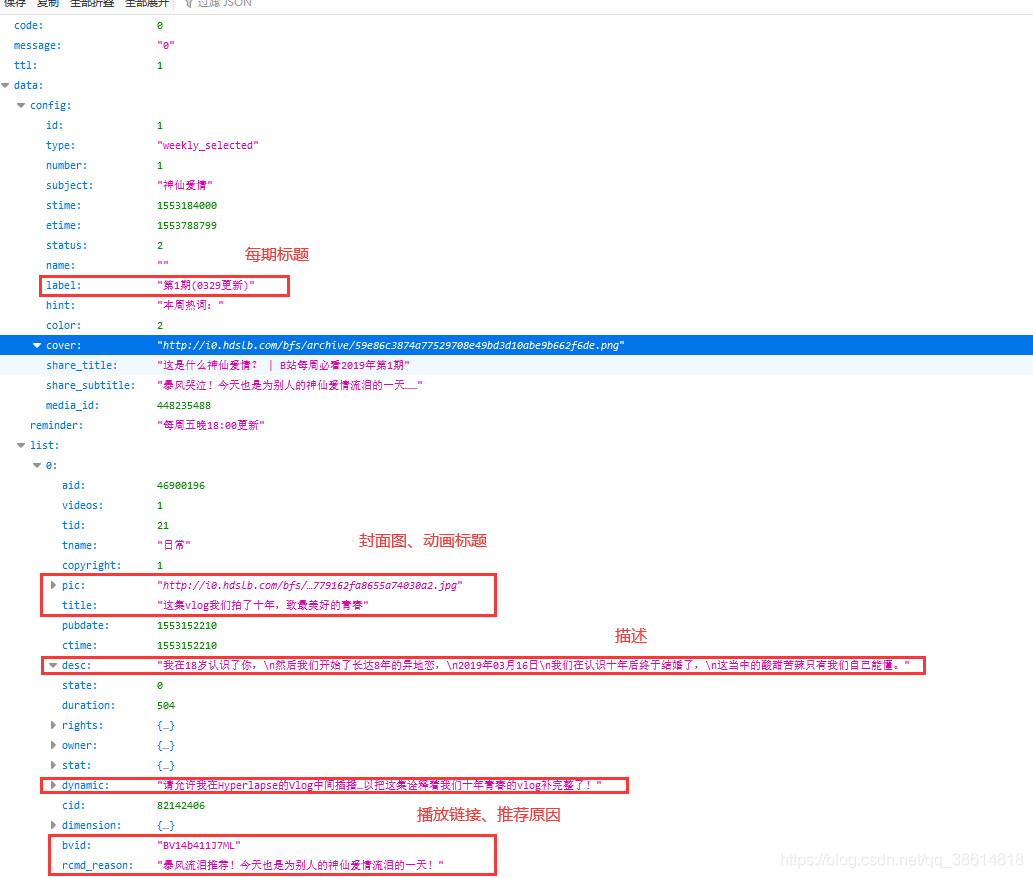
-
重點說一下播放鏈接,開始在回傳的資料中沒找到影片鏈接,想著絕對不可能,這么多資訊,怎么能少得了播放鏈接!!!于是觀察了下每個影片的鏈接規律:

前面都是一樣的,只有后面的碼不同,然后在爬取的資料中找了找,果然有,然后就拼接了下,完美! -
詳細完整爬取代碼如下:
import requests
import pandas as pd
def getUrl(url):
#請求頭
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0',
}
#決議url
html = requests.get(url, headers=header).json()
#回傳json資料
return html
def getData(html):
#從json中取出需要的資料
data = html['data']['list']
# 轉成DataFrame格式
datadf = pd.DataFrame(data)
# 獲取標題
title=html['data']['config']['label']
#從data取出想要的欄位以及對應資料
weeklydf = datadf[['title', 'pic', "bvid", 'desc', 'dynamic', 'rcmd_reason']]
# 拼接影片鏈接
weeklydf['bvid'] = 'https://www.bilibili.com/video/' + weeklydf['bvid']
return weeklydf,title
if __name__ == '__main__':
for i in range(1,95):
url='https://api.bilibili.com/x/web-interface/popular/series/one?number={}'.format(i)
html=getUrl(url)
weeklydf,title=getData(html)
# 索引從1開始
weeklydf.index=weeklydf.index+1
weeklydf.to_excel('E:/output/bilibili/'+title+'.xlsx')
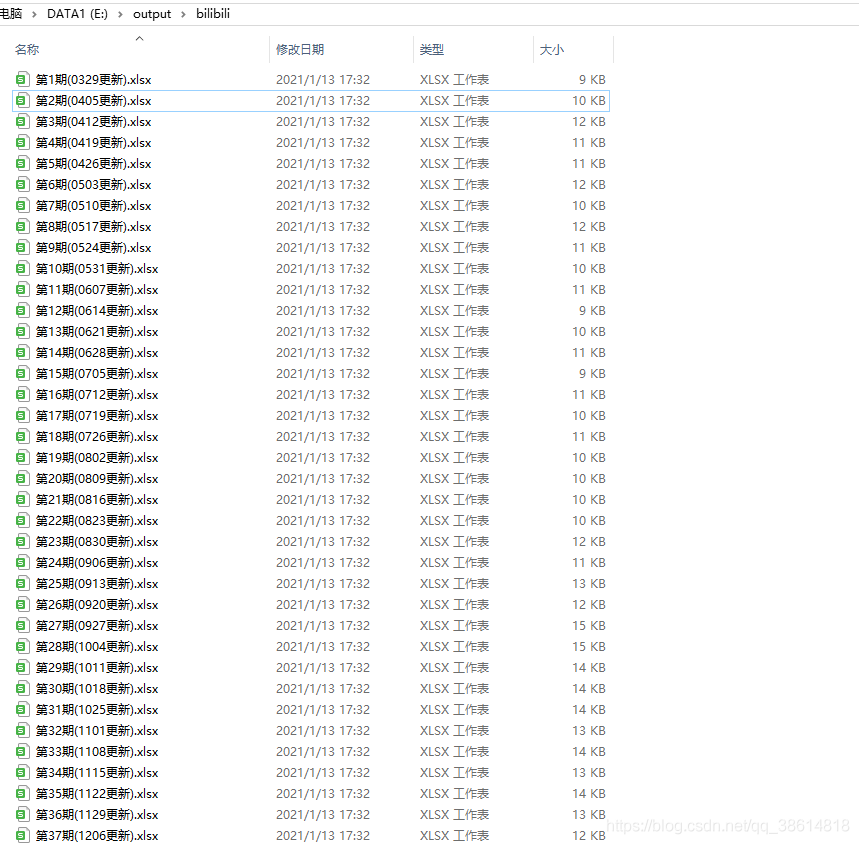
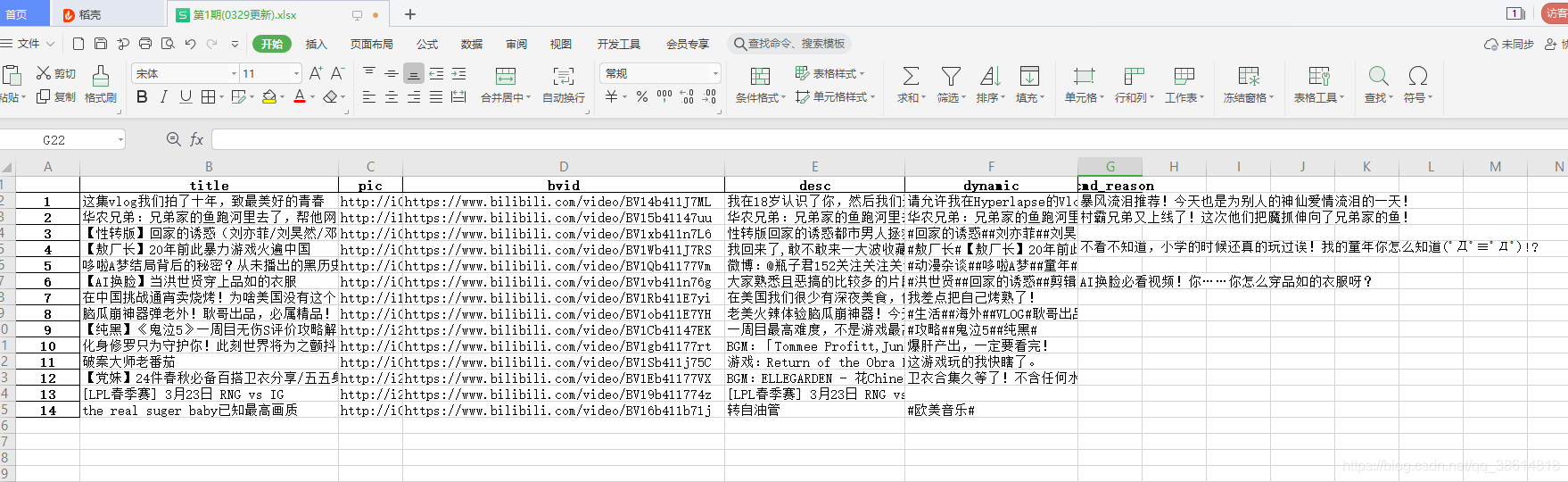
二、爬取結果
總結

轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/249070.html
標籤:python