前言
Mission04 顯卡日志
下面給出了3090顯卡的性能測評日志結果,每一條日志有如下結構:
Benchmarking #2# #4# precision type #1#
#1# model average #2# time : #3# ms
其中#1#代表的是模型名稱,#2#的值為train(ing)或inference,表示訓練狀態或推斷狀態,#3#表示耗時,#4#表示精度,其中包含了float, half, double三種型別,下面是一個具體的例子:
Benchmarking Inference float precision type resnet50 resnet50 model
average inference time : 13.426570892333984 ms
請把日志結果進行整理,變換成如下狀態,model_i用相應模型名稱填充,按照字母順序排序,數值保留三位小數:
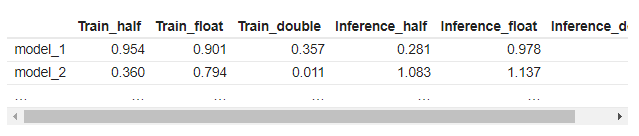
資料查看
#略去前10行和后2行 不設定第一行資料為col值 引擎使用python
df = pd.read_table('./data/mission04/benchmark.txt',skiprows=10,skipfooter=2,header=None,engine='python')
df
完整解題代碼
def my_func(x):
list1 = x.iloc[1].split(' ')
list2 = x.iloc[-1].split(' ')
return pd.Series([list2[0],list1[1],float(list2[-2]),list1[2]],index=['model_name','data_type','time','state'])
#把df的每兩行合并到一起,并用my_func方法提取4個引數并將time小數點后保留三位
df_demo = pd.concat([df[0::2].reset_index(),df[1::2].reset_index()],axis=1).apply(my_func,axis=1).round({'time': 3})
#進行長寬表轉換
res = df_demo.pivot(index='model_name',columns=['data_type','state'],values='time')
#進行多級列索引合并
res.columns = res.columns.map(lambda x:(x[0]+'_'+x[1]))
#按要求排列列索引順序
res = res[['Training_half','Training_float','Training_double','Inference_half','Inference_float','Inference_double']]
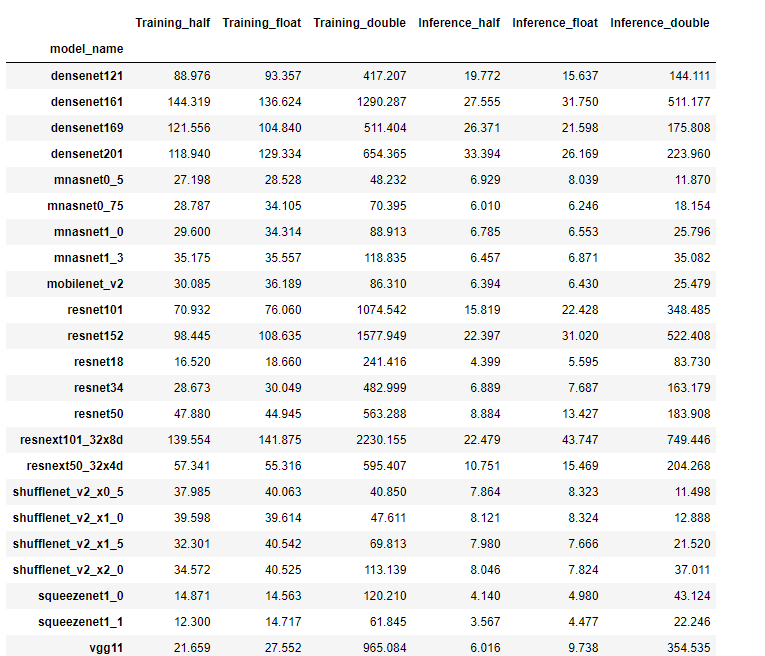
res.shape
(32, 6)
res
Mission05 水壓站點的特征工程
-
df1和df2中分別給出了18年和19年各個站點的資料,其中列中的H0至H23分別代表當天0點至23點
-
df3中記錄了18-19年的每日該地區的天氣情況
請完成如下的任務:
1.通過df1和df2構造df,把時間設為索引,第一列為站點編號,第二列為對應時刻的壓力大小,排列方式如下(壓力數值請用正確的值替換):
def process_df(my_df):
df_demo = my_df.melt(id_vars=['Time','MeasName'],value_vars=df1.columns[2:],var_name='小時',value_name='壓力')
df_demo.Time = pd.to_datetime(df_demo.Time) + pd.to_timedelta(df_demo['小時'].apply(lambda x:x[1:]+'H'))
df_demo.MeasName = df_demo.MeasName.apply(lambda x:int(x[2:]))
df_demo.drop('小時',axis=1,inplace=True)
return df_demo.sort_values(['Time','MeasName'])
df1 = pd.read_csv('./data/mission05/yali18.csv')
df2 = pd.read_csv('./data/mission05/yali19.csv')
df = pd.concat([process_df(df1),process_df(df2)])
df.reset_index(drop=True,inplace=True)
df.rename(columns = {'MeasName':'站點'},inplace=True)
df.set_index('Time',inplace=True)
df
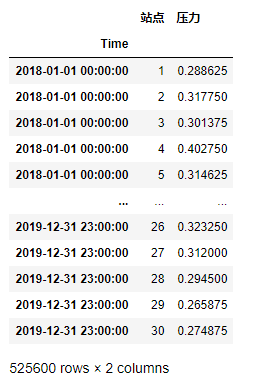
2.在上一問構造的df基礎上,構造下面的特征序列或DataFrame,并把它們逐個拼接到df的右側
df3 = pd.read_csv('./data/mission05/qx1819.csv')
df3
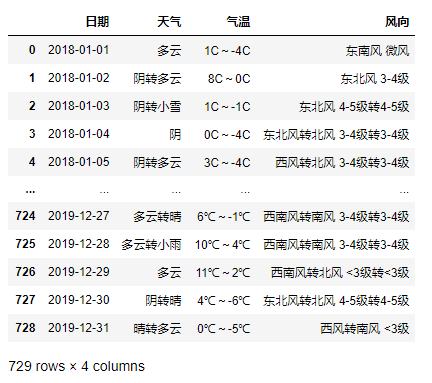
1)當天最高溫、最低溫和它們的溫差
def my_func(x):
list2 = x[2].replace(' ','').split('~')
a1 = int(list2[0][:-1]) if list2[0] not in '℃C' else 0
a2 = int(list2[1][:-1]) if list2[1] not in '℃C' else 0
a1 = a2 if a1 < a2 else a1
return pd.Series([x[0],a1,a2,a1-a2],index=['日期','最高溫','最低溫','溫差'])
df3.apply(my_func,axis=1)
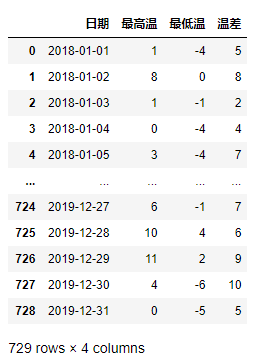
2)當天是否有沙暴、是否有霧、是否有雨、是否有雪、是否為晴天
def my_func(x):
return pd.Series(['沙' in x[1],'霧' in x[1],'雨' in x[1],'雪' in x[1],'晴天' in x[1]],index=['是否有沙暴','是否有霧','是否有雨','是否有雪','是否為晴天'])
df3.apply(my_func,axis=1)
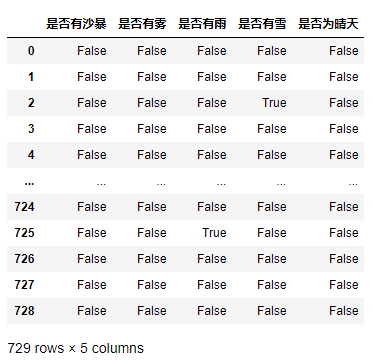
3) 選擇一種合適的方法度量雨量/下雪量的大小(構造兩個序列分別表示二者大小)
對不同的雨雪情況進行觀察:
def my_func(x):
if '雪' in x:
return x
snow_list = list(df_weather.apply(my_func).drop_duplicates())[1:]
snow_list
['陰轉小雪',
'多云轉小到中雪',
'雨夾雪轉陰',
'多云轉小雪',
'陰轉雨夾雪',
'雨夾雪轉多云',
'大雪轉多云',
'陰轉中到大雪',
'小雪轉晴',
'揚沙轉雨夾雪',
'雨夾雪轉大雪',
'霧轉雨夾雪']
def my_func(x):
if '雨' in x:
return x
rain_list = list(df_weather.apply(my_func).drop_duplicates())[1:]
rain_list
['雨夾雪轉陰',
'陰轉雨夾雪',
'小雨轉陰',
'多云轉小雨',
'陰轉小雨',
'中雨轉小雨',
'多云轉雷陣雨',
'雨夾雪轉多云',
'小雨',
'多云轉中到大雨',
'陰轉陣雨',
'小雨轉中雨',
'陰轉雷陣雨',
'多云轉小到中雨',
'陰轉小到中雨',
'大雨轉小雨',
'陰轉中雨',
'雷陣雨',
'小雨轉雷陣雨',
'雷陣雨轉陰',
'雷陣雨轉多云',
'陰轉中到大雨',
'中雨轉暴雨',
'小雨轉多云',
'陰轉大雨',
'中雨轉多云',
'多云轉陣雨',
'揚沙轉雨夾雪',
'雨夾雪轉大雪',
'多云轉中雨',
'雨轉陰',
'小雨轉陣雨',
'大雨轉多云',
'暴雨轉雷陣雨',
'晴轉陣雨',
'中雨轉陰',
'中雨轉雷陣雨',
'暴雨',
'中雨轉小到中雨',
'雨轉多云',
'晴轉小雨',
'霧轉小雨',
'霧轉雨夾雪']
觀察后,將雨雪按照不同類別進行離散分類:
| 雨的種類 | 等級 |
|---|---|
| 小雨 | 1 |
| 中雨 | 2 |
| 大雨 | 3 |
| 陣雨 | 4 |
| 暴雨 | 5 |
| 雨夾雪 | 6 |
| 雪的種類 | 等級 |
|---|---|
| 小雪 | 1 |
| 中雪 | 2 |
| 大雪 | 3 |
| 雨夾雪 | 4 |
做一個說明,這里考慮到有不同的“轉”的情況,比如“小雨轉陣雨”,“陰轉大雨”等,這里統一以強度最高的類別為主體:
def my_func(x):
def judge(s,type):
dict = snow_dict if type else rain_dict
for x in dict:
if x in s:
return dict[x]
return 0
snow_dict = dict(zip(['小雪','中雪','大雪','雨夾雪'],range(1,5)))
rain_dict = dict(zip(['小雨','中雨','大雨','陣雨','暴雨','雨夾雪'],range(1,7)))
return pd.Series([judge(x[1],1),judge(x[1],0)],index=['雨量等級','雪量等級'])
df_weather_descibe = df3.apply(my_func,axis=1)
df_weather_descibe
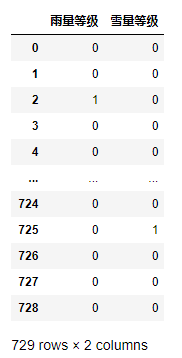
4)限制只用4列,對風向進行0-1編碼(只考慮風向,不考慮大小)
def my_func(x):
def returnWindCode(s):
res = [pd.NA,pd.NA]
if '東' in s:
res[0] = 1
if '西' in s:
res[0] = 0
if '南' in s:
res[1] = 1
if '北' in s:
res[1] = 0
return res
#list代表風向
list = x[-1].split(' ')
#提前補全
if '轉' not in list[0]:
list[0] += '轉'
#list1為風向串列,可能為空
list1 = list[0].split('轉')
res = []
for x in list1:
res += returnWindCode(x)
return pd.Series(res,index=['前風 東1西0','前風 南1北0','后風 東1西0','后風 南1北0'])
df3.apply(my_func,axis=1).head(10)
驗證:
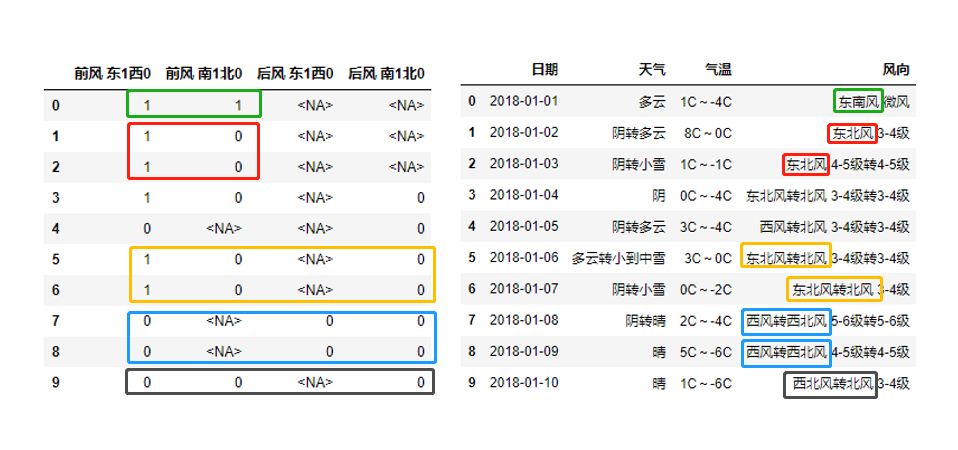
5)統一連接表操作:
由于df與df3合并相當于是多對一合并,所以這里首選merge方法將上面4類額外資料進行統一合并操作:
先進行匯總:
def my_func(x):
def getWeather():
typeList = ['沙','霧','雨','雪','晴天']
return [1 if item in x[1] else 0 for item in typeList]
def getTemp():
list2 = x[2].replace(' ','').split('~')
a1 = int(list2[0][:-1]) if list2[0] not in '℃C' else 0
a2 = int(list2[1][:-1]) if list2[1] not in '℃C' else 0
a1 = a2 if a1 < a2 else a1
return [a1,a2,a1-a2]
def getWeatherDes():
def judge(s,type):
dict = snow_dict if type else rain_dict
for x in dict:
if x in s:
return dict[x]
return 0
snow_dict = dict(zip(['小雪','中雪','大雪','雨夾雪'],range(1,5)))
rain_dict = dict(zip(['小雨','中雨','大雨','陣雨','暴雨','雨夾雪'],range(1,7)))
return [judge(x[1],1),judge(x[1],0)]
def getWindType():
def returnWindCode(s):
res = [pd.NA,pd.NA]
if '東' in s:
res[0] = 1
elif '西' in s:
res[0] = 0
if '南' in s:
res[1] = 1
elif '北' in s:
res[1] = 0
return res
#list代表風向
list = x[-1].split(' ')
#提前補全
if '轉' not in list[0]:
list[0] += '轉'
#list1為風向串列,可能為空
list1 = list[0].split('轉')
res = []
for item in list1:
res += returnWindCode(item)
return res
index = ['日期','最高溫','最低溫','溫差','是否有沙暴','是否有霧','是否有雨','是否有雪','是否為晴天','雪量等級','雨量等級','前 東1西0','前 南1北0','后 東1西0','后 南1北0']
return pd.Series([pd.to_datetime(x[0])]+getTemp()+getWeather()+getWeatherDes()+getWindType(),index=index)
df_total = df3.apply(my_func,axis=1)
df_total
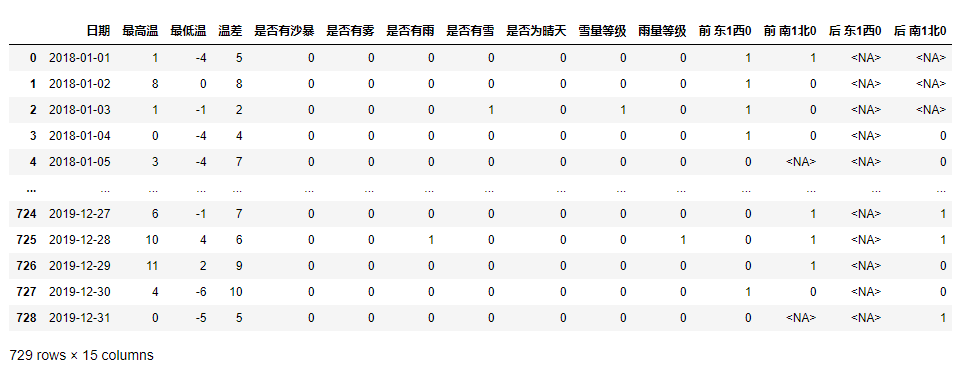
然后進行merge:
df_demo = df
df_demo['日期'] = pd.to_datetime(df.index.date)
df_demo = df_demo.reset_index().merge(df_total,on='日期',how='left',validate='m:1').set_index('Time').drop('日期',axis=1)
df_demo
注意這里需要對日期列轉成時序型別,并且要將merge方法中的validate引數設定為‘m:1’,否則右邊會產生很多空值,而且因為合并后不保留行索引,所以在合并之前要把df_demo的行索引重置,在合并后刪掉‘日期’列,效果如下:
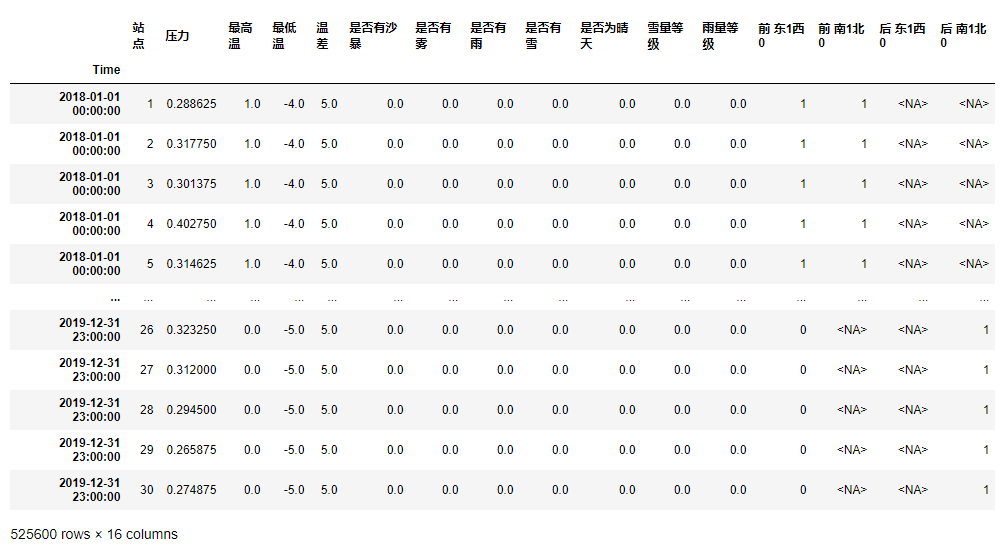
3.對df的水壓一列構造如下時序特征:
1)當前時刻該站點水壓與本月的相同整點時間該站點水壓均值的差,例如當前時刻為2018-05-20 17:00:00,那么對應需要減去的值為當前月所有17:00:00時間點水壓值的均值
首先建立一個根據年、月、小時、站點分組的分組物件,然后求得壓力均值,最后將行索引進行合并,存入df_table中:
def concatFourNum(a,b,c,d):
return str(a)+'-'+str(b)+'-'+str(c)+'-'+str(d)
df_table = df.groupby([df.index.year,df.index.month,df.index.hour,'站點'])['壓力'].mean()
df_table.index = df_table.index.map(lambda x:concatFourNum(x[0],x[1],x[2],x[3]))
df_table = df_table.to_frame().reset_index()
df_table
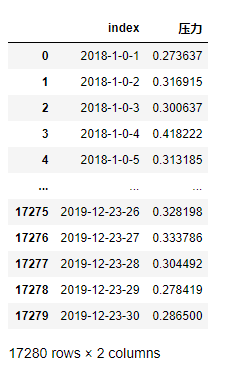
然后新建一個df的copy:df_demo,遍歷每行建立與df_table的index列保持一致的列:
df_demo = df.copy()
df_demo['index'] = pd.to_datetime(df_demo.index)
df_demo['index'] = df_demo.apply(lambda x:concatFourNum(x[-1].year,x[-1].month,x[-1].hour,x[0]),axis=1)
df_demo
最后將兩張表進行合并,合并后的效果為:
df_res = df_demo.merge(df_table,on='index',validate='m:1',how='left')
df_res
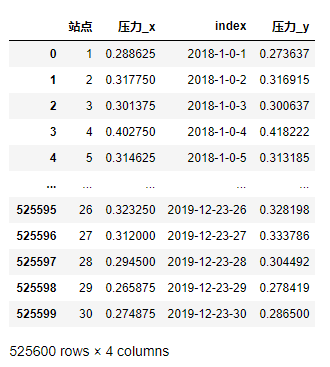
此時壓力_x代表當前的壓力,壓力_y代表題目要求的當月相同整點的壓力均值,相減即可得到結果:
res = df_res['壓力_x'] - df_res['壓力_y']
res
0 0.014988
1 0.000835
2 0.000738
3 -0.015472
4 0.001440
...
525595 -0.004948
525596 -0.021786
525597 -0.009992
525598 -0.012544
525599 -0.011625
Length: 525600, dtype: float64
2)當前時刻所在周的周末該站點水壓均值與作業日水壓均值之差
首先增加額外資訊列輔助判斷,分別為站點+當前年份+周數,以及是否為周內:
df_demo = df.copy().reset_index()
# df_demo['weekInfo'] =
df_demo['weekInfo'] = df_demo.apply(lambda x:str(x[1])+'-'+str(x[0].year)+'-'+str(x[0].weekofyear),axis=1)
df_demo['isWeekdays'] = df_demo.apply(lambda x:x[0].dayofweek < 5,axis=1)
df_demo
然后按weekInfo進行分組,利用isWeekdays列分別求均值:
s_wdays = df_demo[df_demo.isWeekdays].groupby('weekInfo')['壓力'].mean()
s_wdays
weekInfo
1-2018-1 0.247120
1-2018-10 0.250056
1-2018-11 0.246278
1-2018-12 0.240869
1-2018-13 0.243756
...
9-2019-52 0.210806
9-2019-6 0.265816
9-2019-7 0.239919
9-2019-8 0.250313
9-2019-9 0.254747
Name: 壓力, Length: 3120, dtype: float64
s_wends = df_demo[~df_demo.isWeekdays].groupby('weekInfo')['壓力'].mean()
s_wends
weekInfo
1-2018-1 0.251711
1-2018-10 0.251602
1-2018-11 0.237789
1-2018-12 0.242266
1-2018-13 0.241422
...
9-2019-52 0.204203
9-2019-6 0.245734
9-2019-7 0.237219
9-2019-8 0.243523
9-2019-9 0.245055
Name: 壓力, Length: 3120, dtype: float64
然后相減后轉換成df型別準備拼接:
res = (s_wdays - s_wends).to_frame().reset_index()
res
最后利用df_demo進行拼接:
df_demo.merge(res,on='weekInfo',validate='m:1',how='left').set_index('Time')
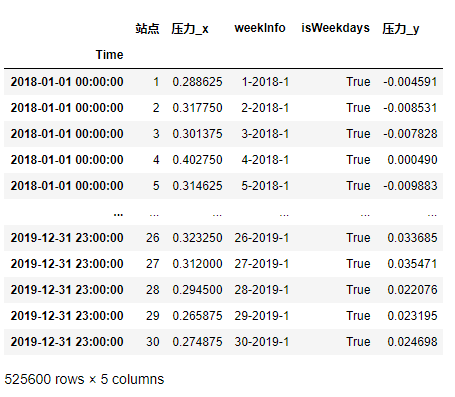
壓力_y即為所求,
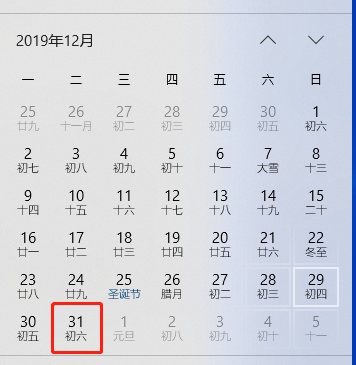
這塊也有一點點小問題,不是所有的日期所屬的周都是按所在年計算:
pd.Timestamp('2021-01-01').weekofyear
53
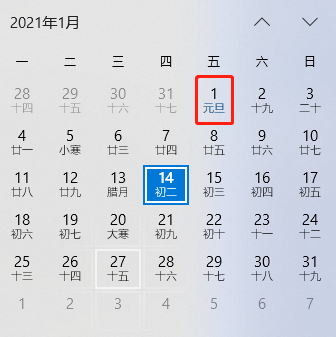
pd.Timestamp('2019-12-31').weekofyear
1
解決思路:研究一下日歷中不同日子所屬周相對于年的關系,然后在上面生成weekIndex的代碼中進行額外的邏輯判斷,
3)當前時刻向前7日內,該站點水壓的均值、標準差、0.95分位數、下雨天數與下雪天數的總和
df_demoda代表2問中求得的df
gb = df_demo.groupby('站點')
gb.rolling('7D')['壓力'].mean()
站點 Time
1 2018-01-01 00:00:00 0.288625
2018-01-01 01:00:00 0.290313
2018-01-01 02:00:00 0.290375
2018-01-01 03:00:00 0.292656
2018-01-01 04:00:00 0.294175
...
30 2019-12-31 19:00:00 0.276701
2019-12-31 20:00:00 0.276730
2019-12-31 21:00:00 0.276777
2019-12-31 22:00:00 0.276824
2019-12-31 23:00:00 0.276750
Name: 壓力, Length: 525600, dtype: float64
gb.rolling('7D')['壓力'].std()
站點 Time
1 2018-01-01 00:00:00 NaN
2018-01-01 01:00:00 0.002386
2018-01-01 02:00:00 0.001691
2018-01-01 03:00:00 0.004767
2018-01-01 04:00:00 0.005346
...
30 2019-12-31 19:00:00 0.027159
2019-12-31 20:00:00 0.027153
2019-12-31 21:00:00 0.027120
2019-12-31 22:00:00 0.027075
2019-12-31 23:00:00 0.027063
Name: 壓力, Length: 525600, dtype: float64
gb.rolling('7D')['壓力'].quantile(0.95)
站點 Time
1 2018-01-01 00:00:00 0.288625
2018-01-01 01:00:00 0.291831
2018-01-01 02:00:00 0.291850
2018-01-01 03:00:00 0.298375
2018-01-01 04:00:00 0.300100
...
30 2019-12-31 19:00:00 0.319988
2019-12-31 20:00:00 0.319988
2019-12-31 21:00:00 0.319988
2019-12-31 22:00:00 0.319988
2019-12-31 23:00:00 0.319988
Name: 壓力, Length: 525600, dtype: float64
求7天內下雨,下雪天數:
df_res = df_demo.copy()
df_res['Date'] = pd.to_datetime(pd.to_datetime(df_res.index).date)
df_res = df_res[['站點','是否有雨','是否有雪','Date']]
df_res = df_res.groupby(['站點','Date']).agg(lambda x:1 if sum(x) > 0 else 0)
df_res.reset_index('站點').groupby('站點')[['是否有雨','是否有雪']].rolling('7D').sum().rename(columns={'是否有雨':'7天內有雨天數','是否有雪':'7天內有雪天數'})
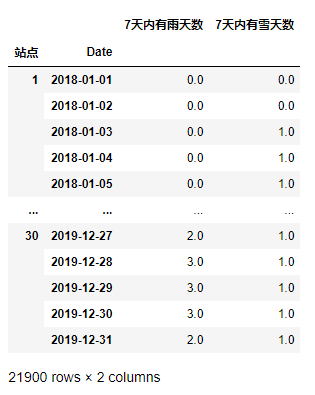
這塊已經求出了結果,但是有個細節要修改一下:
用主資料表進行merge合并,
4)當前時刻向前7日內,該站點同一整點時間水壓的均值、標準差、0.95分位數
先求同一整點的水壓的三個系數,然后再進行滑動視窗,
gb = df.groupby([df.index.year,df.index.month,df.index.hour,'站點']).rolling('7D')['壓力']
gb.mean()
Time Time Time 站點
2018 1 0 1 0.288625
1 0.287688
1 0.289125
1 0.289563
1 0.288550
...
2019 12 23 30 0.286714
30 0.283821
30 0.284839
30 0.284679
30 0.282911
Name: 壓力, Length: 525600, dtype: float64
gb.std()
Time Time Time 站點
2018 1 0 1 NaN
1 0.001326
1 0.002660
1 0.002342
1 0.003040
...
2019 12 23 30 0.006524
30 0.007718
30 0.007381
30 0.007127
30 0.007878
Name: 壓力, Length: 525600, dtype: float64
gb.quantile(0.95)
Time Time Time 站點
2018 1 0 1 0.288625
1 0.288531
1 0.291663
1 0.291831
1 0.291775
...
2019 12 23 30 0.294450
30 0.293550
30 0.293550
30 0.292763
30 0.292763
Name: 壓力, Length: 525600, dtype: float64
待修改的地方,雖然長度保持一致,但是行索引已經不同,需要修改,
5)當前時刻所在日的該站點水壓最高值與最低值出現時刻的時間差
新增主鍵列index:
def concatFourNum(a,b,c,d):
return str(a)+'-'+str(b)+'-'+str(c)+'-'+str(d)
df_demo = df.copy()
df_demo['index'] = pd.to_datetime(df_demo.index)
df_demo['index'] = df_demo.apply(lambda x:concatFourNum(x[-1].year,x[-1].month,x[-1].day,x[0]),axis=1)
df_demo = df_demo.reset_index()
df_demo
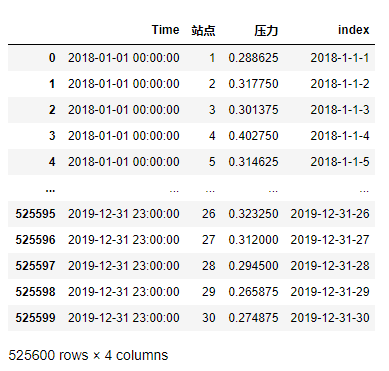
計算每個站點每日的最大壓力和最小壓力之間的時間差:
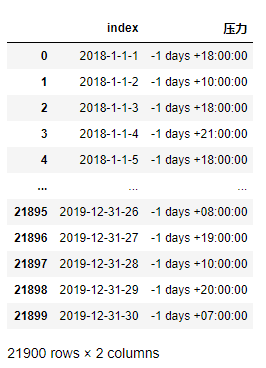
res = df.groupby([pd.to_datetime(df.index.date),'站點']).idxmax() - df.groupby([pd.to_datetime(df.index.date),'站點']).idxmin()
res.index = res.index.map(lambda x:concatFourNum(x[0].year,x[0].month,x[0].day,x[1]))
res = res.reset_index()
res
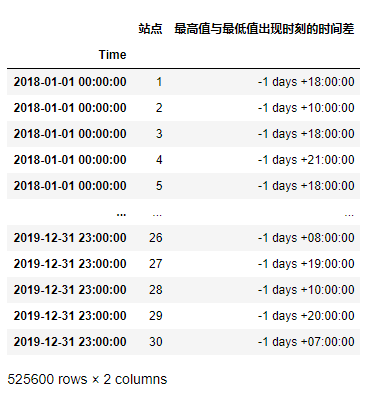
左連接兩張表,并且更改列名:
res = df_demo.merge(res,how='left',on='index',validate='m:1')
res = res.set_index('Time')[['站點','壓力_y']].rename(columns={'壓力_y':'最高值與最低值出現時刻的時間差'})
res
參考文獻
1.風向都有哪幾種啊
https://zhidao.baidu.com/question/1732599155287606027.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/249072.html
標籤:python