????在 Mask R-CNN 中 DrugDataset 類有一個函式 draw_mask(),利用三個 for 回圈重寫mask,造成訓練及資料加載的瓶頸,GPU不會滿載訓練,大量CPU資源用于三個 for 回圈計算,當一張圖片目標較多以及資料量大時,速度更會減慢,
def draw_mask(self, num_obj, mask, image,image_id):
#print("draw_mask-->",image_id)
#print("self.image_info",self.image_info)
info = self.image_info[image_id]
#print("info-->",info)
#print("info[width]----->",info['width'],"-info[height]--->",info['height'])
for index in range(num_obj):
for i in range(info['width']):
for j in range(info['height']):
#print("image_id-->",image_id,"-i--->",i,"-j--->",j)
#print("info[width]----->",info['width'],"-info[height]--->",info['height'])
at_pixel = image.getpixel((i, j))
if at_pixel == index + 1:
mask[j, i, index] = 1
return mask
解決辦法
????將每個重寫后的 mask 陣列保存下來,訓練時直接加載,
具體實作
第一步:
????首先將 draw_mask 中回傳的 mask 利用 numpy.savez_compressed()保存下來,我簡單寫了個代碼,利用行程池加快轉換,直接貼代碼,
def draw_mask(self, num_obj, mask, image, image_id):
info = self.image_info[image_id]
for index in range(num_obj):
for i in range(info['width']):
for j in range(info['height']):
at_pixel = image.getpixel((i, j))
if at_pixel == index + 1:
mask[j, i, index] = 1
np.savez_compressed(os.path.join(ROOT_DIR, 'resources', 'yn', 'rwmask', info["path"].split("/")[-1].split(".")[0]), mask)
return mask
data_res_dir = os.path.join(ROOT_DIR, 'resources', 'yn')
data_set_root_path = os.path.join(ROOT_DIR, 'data', 'yn')
# data_set_path = os.path.join(data_set_root_path, data_set)
train_file = os.path.join(data_set_root_path, '1.txt')
train_name = open(train_file, 'r').read().splitlines()
count_tra = len(train_name)
# train and val data set preparation
data_set_train = DrugDataset()
data_set_train.load_shapes(count_tra, data_res_dir, train_name)
data_set_train.prepare()
queue = Queue()
thread_num = 30
[queue.put(id) for id in data_set_train.image_ids]
print("kaishi ")
pthread = Pool(thread_num)
while True:
image_id = queue.get()
pthread.apply_async(data_set_train.load_mask, args=(image_id,))
if queue.empty():
break
pthread.close()
pthread.join()
這樣每個圖片的mask就會保存下來,如下所示,
第二步:
????修改訓練代碼,主要是修改 mask 加載的部分,如下所示:
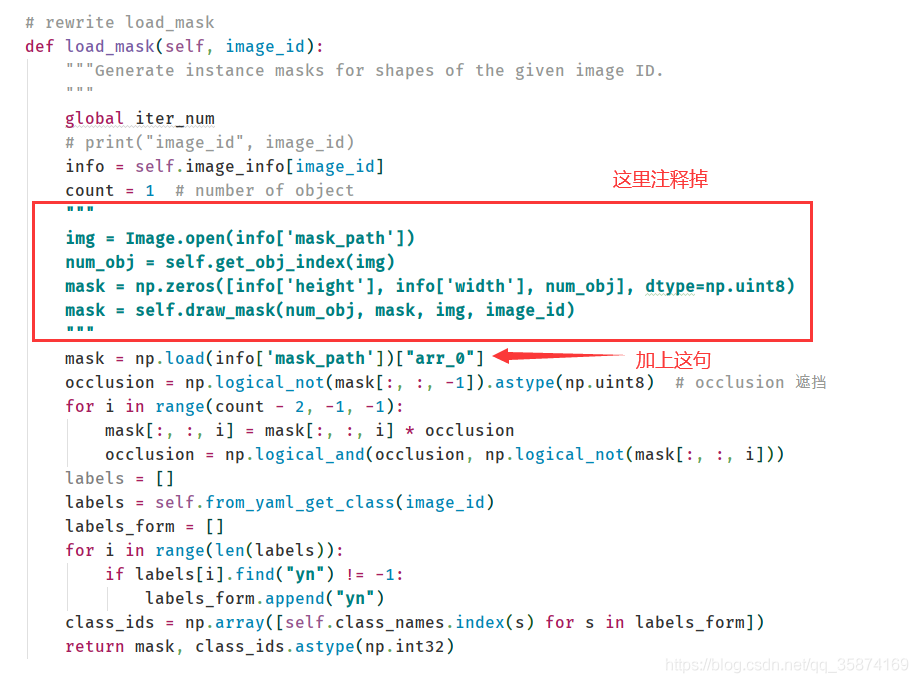
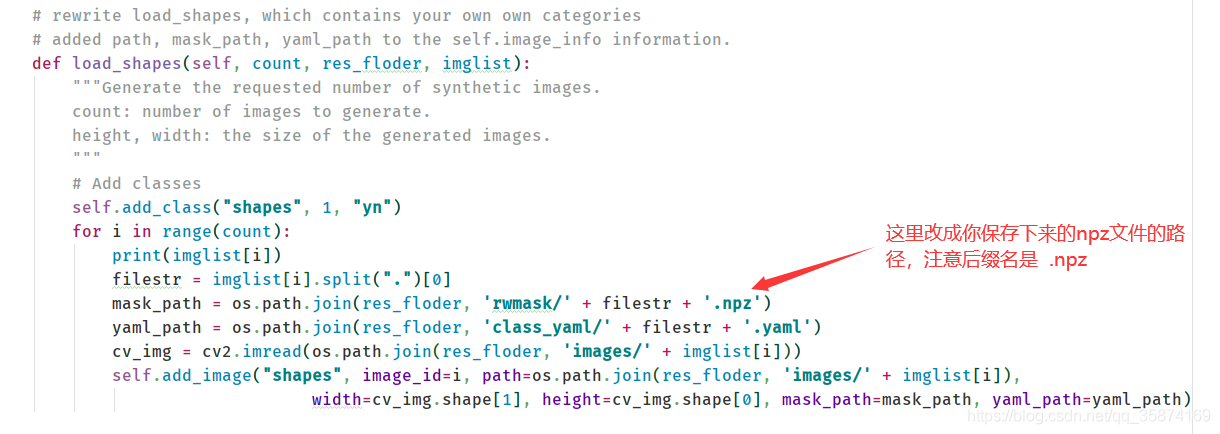
貼個轉換的全部代碼
# encoding: utf-8
"""
@author: Libing Wang
@time: 2021/1/12 9:19
@file: rewrite_save_mask.py
@desc:
"""
import os
import sys
import cv2
import yaml
import numpy as np
from PIL import Image
# import threading
from queue import Queue
from multiprocessing import Pool
ROOT_DIR = os.path.abspath("../")
sys.path.append(ROOT_DIR)
from mrcnn import utils
from mrcnn.config import Config
class ShapesConfig(Config):
"""Configuration for training on the toy shapes dataset.
Derives from the base Config class and overrides values specific
to the toy shapes dataset.
"""
# Give the configuration a recognizable name
NAME = "yn"
# Train on 1 GPU and 8 images per GPU. We can put multiple images on each
# GPU because the images are small. Batch size is 8 (GPUs * images/GPU).
GPU_COUNT = 1
IMAGES_PER_GPU = 1
# Number of classes (including background)
NUM_CLASSES = 1 + 1 # background + 3 shapes
# Use small images for faster training. Set the limits of the small side
# the large side, and that determines the image shape.
IMAGE_MIN_DIM = 128
IMAGE_MAX_DIM = 1024
# Use smaller anchors because our image and objects are small
RPN_ANCHOR_SCALES = (32, 64, 128, 256, 512) # anchor side in pixels
# Reduce training ROIs per image because the images are small and have
# few objects. Aim to allow ROI sampling to pick 33% positive ROIs.
TRAIN_ROIS_PER_IMAGE = 70
# Use a small epoch since the data is simple
STEPS_PER_EPOCH = 10
# use small validation steps since the epoch is small
VALIDATION_STEPS = 10
class InferenceConfig(ShapesConfig):
# Set batch size to 1 since we'll be running inference on
# one image at a time. Batch size = GPU_COUNT * IMAGES_PER_GPU
GPU_COUNT = 1
IMAGES_PER_GPU = 1
IoU_THRESHOLD = 0.7
class DrugDataset(utils.Dataset):
# the count of instances (objects) in the graph
def get_obj_index(self, image):
n = np.max(image)
return n
# Parse the yaml file obtained in the labelme to get the instance tag
# corresponding to each layer of the mask.
def from_yaml_get_class(self, image_id):
info = self.image_info[image_id]
with open(info['yaml_path']) as f:
temp = yaml.load(f.read(), Loader=yaml.FullLoader)
labels = temp['label_names']
del labels[0]
return labels
# rewrite draw_mask
def draw_mask(self, num_obj, mask, image, image_id):
info = self.image_info[image_id]
for index in range(num_obj):
for i in range(info['width']):
for j in range(info['height']):
at_pixel = image.getpixel((i, j))
if at_pixel == index + 1:
mask[j, i, index] = 1
np.savez_compressed(os.path.join(ROOT_DIR, 'resources', 'yn', 'rwmask', info["path"].split("/")[-1].split(".")[0]), mask)
return mask
# rewrite load_shapes, which contains your own own categories
# added path, mask_path, yaml_path to the self.image_info information.
def load_shapes(self, count, res_floder, imglist):
"""Generate the requested number of synthetic images.
count: number of images to generate.
height, width: the size of the generated images.
"""
# Add classes
self.add_class("shapes", 1, "yn")
for i in range(count):
print(imglist[i])
filestr = imglist[i].split(".")[0]
mask_path = os.path.join(res_floder, 'mask/' + filestr + '.png')
yaml_path = os.path.join(
res_floder, 'class_yaml/' + filestr + '.yaml')
cv_img = cv2.imread(os.path.join(res_floder, 'images/' + imglist[i]))
self.add_image("shapes", image_id=i, path=os.path.join(res_floder, 'images/' + imglist[i]),
width=cv_img.shape[1],
height=cv_img.shape[0],
mask_path=mask_path,
yaml_path=yaml_path)
# rewrite load_mask
def load_mask(self, image_id):
"""Generate instance masks for shapes of the given image ID.
"""
print("image_id", image_id)
info = self.image_info[image_id]
count = 1 # number of object
img = Image.open(info['mask_path'])
num_obj = self.get_obj_index(img)
mask = np.zeros(
[info['height'], info['width'], num_obj], dtype=np.uint8)
mask = self.draw_mask(num_obj, mask, img, image_id)
def train_model(): # dataset 代表本次訓練樣本的檔案夾名稱
# 訓練模型的配置
train_config = ShapesConfig()
data_res_dir = os.path.join(ROOT_DIR, 'resources', 'yn')
data_set_root_path = os.path.join(ROOT_DIR, 'data', 'yn')
# data_set_path = os.path.join(data_set_root_path, data_set)
train_file = os.path.join(data_set_root_path, '1.txt')
train_name = open(train_file, 'r').read().splitlines()
count_tra = len(train_name)
# train and val data set preparation
data_set_train = DrugDataset()
data_set_train.load_shapes(count_tra, data_res_dir, train_name)
data_set_train.prepare()
queue = Queue()
thread_num = 30
[queue.put(id) for id in data_set_train.image_ids]
print("start! ")
pthread = Pool(thread_num)
while not queue.empty():
image_id = queue.get()
pthread.apply_async(data_set_train.load_mask, args=(image_id,))
pthread.close()
pthread.join()
print("queue is empty!")
if __name__ == '__main__':
train_model()
????這樣就修改完畢了,本人實測會提速很多,而且CPU占用也會減小,本人使用 DGX-Station,cpu占用如下所示,
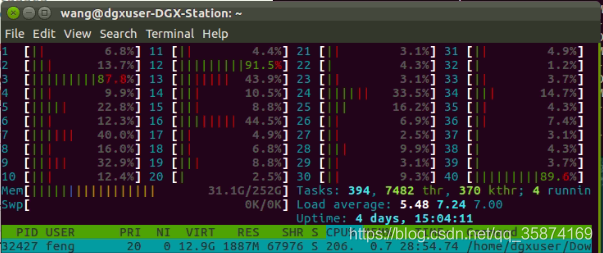
????如果覺得這篇文章幫助到你,請點個贊,評論一下,謝謝!大家還有什么好方法也可以交流一下,學習學習,最后轉載,請注明該博客連接以及作者名字!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/249078.html
標籤:python
上一篇:Python學習(5)(while回圈陳述句、回圈嵌套、break/continue、賦值運算子、轉義字符等 )