1. 背景
1.1. 話題來源
最近很多從事移動互聯網和物聯網開發的同學給我發郵件或者微博私信我,咨詢推送服務相關的問題,問題五花八門,在幫助大家答疑解惑的程序中,我也對問題進行了總結,大概可以歸納為如下幾類:
- Netty 是否可以做推送服務器?
- 如果使用 Netty 開發推送服務,一個服務器最多可以支撐多少個客戶端?
- 使用 Netty 開發推送服務遇到的各種技術問題,
由于咨詢者眾多,關注點也比較集中,我希望通過本文的案例分析和對推送服務設計要點的總結,幫助大家在實際作業中少走彎路,
1.2. 推送服務
移動互聯網時代,推送 (Push) 服務成為 App 應用不可或缺的重要組成部分,推送服務可以提升用戶的活躍度和留存率,我們的手機每天接收到各種各樣的廣告和提示訊息等大多數都是通過推送服務實作的,
隨著物聯網的發展,大多數的智能家居都支持移動推送服務,未來所有接入物聯網的智能設備都將是推送服務的客戶端,這就意味著推送服務未來會面臨海量的設備和終端接入,
1.3. 推送服務的特點
移動推送服務的主要特點如下:
- 使用的網路主要是運營商的無線移動網路,網路質量不穩定,例如在地鐵上信號就很差,容易發生網路閃斷;
- 海量的客戶端接入,而且通常使用長連接,無論是客戶端還是服務端,資源消耗都非常大;
- 由于谷歌的推送框架無法在國內使用,Android 的長連接是由每個應用各自維護的,這就意味著每臺安卓設備上會存在多個長連接,即便沒有訊息需要推送,長連接本身的心跳訊息量也是非常巨大的,這就會導致流量和耗電量的增加;
- 不穩定:訊息丟失、重復推送、延遲送達、過期推送時有發生;
- 垃圾訊息滿天飛,缺乏統一的服務治理能力,
為了解決上述弊端,一些企業也給出了自己的解決方案,例如京東云推出的推送服務,可以實作多應用單服務單連接模式,使用 AlarmManager 定時心跳節省電量和流量,
2. 智能家居領域的一個真實案例
2.1. 問題描述
智能家居 MQTT 訊息服務中間件,保持 10 萬用戶在線長連接,2 萬用戶并發做訊息請求,程式運行一段時間之后,發現記憶體泄露,懷疑是 Netty 的 Bug,其它相關資訊如下:
- MQTT 訊息服務中間件服務器記憶體 16G,8 個核心 CPU;
- Netty 中 boss 執行緒池大小為 1,worker 執行緒池大小為 6,其余執行緒分配給業務使用,該分配方式后來調整為 worker 執行緒池大小為 11,問題依舊;
- Netty 版本為 4.0.8.Final,
2.2. 問題定位
首先需要 dump 記憶體堆疊,對疑似記憶體泄露的物件和參考關系進行分析,如下所示:
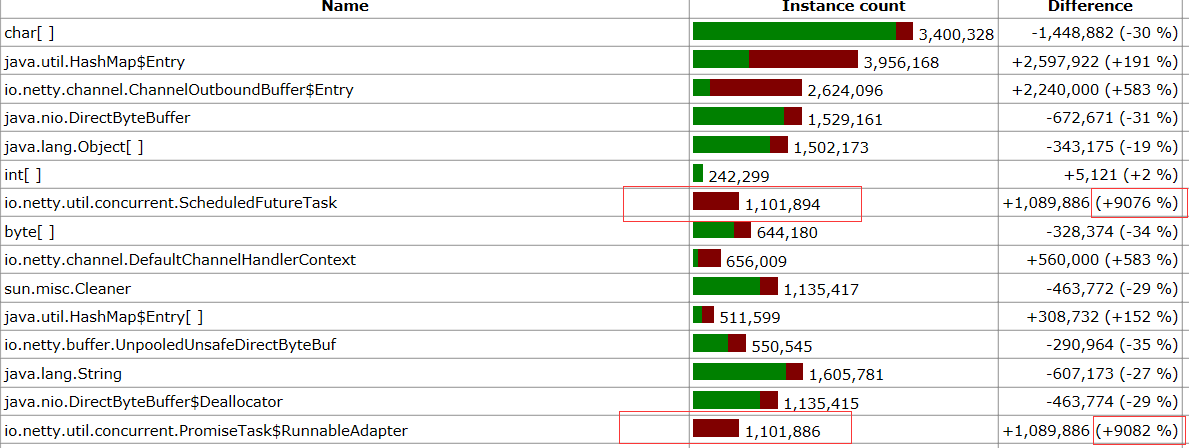
我們發現 Netty 的 ScheduledFutureTask 增加了 9076%,達到 110W 個左右的實體,通過對業務代碼的分析發現用戶使用 IdleStateHandler 用于在鏈路空閑時進行業務邏輯處理,但是空閑時間設定的比較大,為 15 分鐘,
Netty 的 IdleStateHandler 會根據用戶的使用場景,啟動三類定時任務,分別是:ReaderIdleTimeoutTask、WriterIdleTimeoutTask 和 AllIdleTimeoutTask,它們都會被加入到 NioEventLoop 的 Task 佇列中被調度和執行,
由于超時時間過長,10W 個長鏈接鏈路會創建 10W 個 ScheduledFutureTask 物件,每個物件還保存有業務的成員變數,非常消耗記憶體,用戶的持久代設定的比較大,一些定時任務被老化到持久代中,沒有被 JVM 垃圾回收掉,記憶體一直在增長,用戶誤認為存在記憶體泄露,
事實上,我們進一步分析發現,用戶的超時時間設定的非常不合理,15 分鐘的超時達不到設計目標,重新設計之后將超時時間設定為 45 秒,記憶體可以正常回收,問題解決,
2.3. 問題總結
如果是 100 個長連接,即便是長周期的定時任務,也不存在記憶體泄露問題,在新生代通過 minor GC 就可以實作記憶體回收,正是因為十萬級的長連接,導致小問題被放大,引出了后續的各種問題,
事實上,如果用戶確實有長周期運行的定時任務,該如何處理?對于海量長連接的推送服務,代碼處理稍有不慎,就滿盤皆輸,下面我們針對 Netty 的架構特點,介紹下如何使用 Netty 實作百萬級客戶端的推送服務,
3. Netty 海量推送服務設計要點
作為高性能的 NIO 框架,利用 Netty 開發高效的推送服務技術上是可行的,但是由于推送服務自身的復雜性,想要開發出穩定、高性能的推送服務并非易事,需要在設計階段針對推送服務的特點進行合理設計,
3.1. 最大句柄數修改
百萬長連接接入,首先需要優化的就是 Linux 內核引數,其中 Linux 最大檔案句柄數是最重要的調優引數之一,默認單行程打開的最大句柄數是 1024,通過 ulimit -a 可以查看相關引數,示例如下:
[root@lilinfeng ~]# ulimit -a
core file size (blocks, -c) 0
data seg size (kbytes, -d) unlimited
scheduling priority (-e) 0
file size (blocks, -f) unlimited
pending signals (-i) 256324
max locked memory (kbytes, -l) 64
max memory size (kbytes, -m) unlimited
open files (-n) 1024
...... 后續輸出省略
當單個推送服務接收到的鏈接超過上限后,就會報“too many open files”,所有新的客戶端接入將失敗,
通過 vi /etc/security/limits.conf 添加如下配置引數:修改之后保存,注銷當前用戶,重新登錄,通過 ulimit -a 查看修改的狀態是否生效,
* soft nofile 1000000
* hard nofile 1000000
需要指出的是,盡管我們可以將單個行程打開的最大句柄數修改的非常大,但是當句柄數達到一定數量級之后,處理效率將出現明顯下降,因此,需要根據服務器的硬體配置和處理能力進行合理設定,如果單個服務器性能不行也可以通過集群的方式實作,
3.2. 當心 CLOSE_WAIT
從事移動推送服務開發的同學可能都有體會,移動無線網路可靠性非常差,經常存在客戶端重置連接,網路閃斷等,
在百萬長連接的推送系統中,服務端需要能夠正確處理這些網路例外,設計要點如下:
- 客戶端的重連間隔需要合理設定,防止連接過于頻繁導致的連接失敗(例如埠還沒有被釋放);
- 客戶端重復登陸拒絕機制;
- 服務端正確處理 I/O 例外和解碼例外等,防止句柄泄露,
最后特別需要注意的一點就是 close_wait 過多問題,由于網路不穩定經常會導致客戶端斷連,如果服務端沒有能夠及時關閉 socket,就會導致處于 close_wait 狀態的鏈路過多,close_wait 狀態的鏈路并不釋放句柄和記憶體等資源,如果積壓過多可能會導致系統句柄耗盡,發生“Too many open files”例外,新的客戶端無法接入,涉及創建或者打開句柄的操作都將失敗,
下面對 close_wait 狀態進行下簡單介紹,被動關閉 TCP 連接狀態遷移圖如下所示:
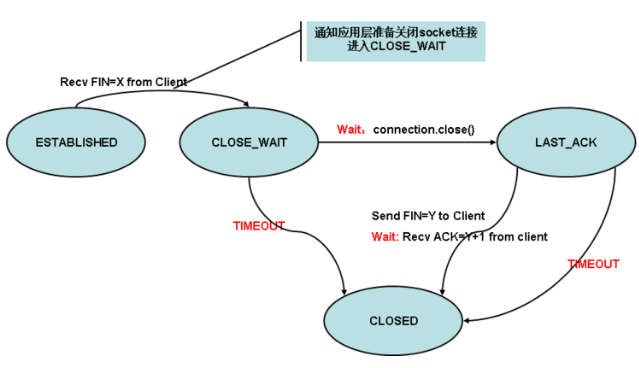
圖 3-1 被動關閉 TCP 連接狀態遷移圖
close_wait 是被動關閉連接是形成的,根據 TCP 狀態機,服務器端收到客戶端發送的 FIN,TCP 協議堆疊會自動發送 ACK,鏈接進入 close_wait 狀態,但如果服務器端不執行 socket 的 close() 操作,狀態就不能由 close_wait 遷移到 last_ack,則系統中會存在很多 close_wait 狀態的連接,通常來說,一個 close_wait 會維持至少 2 個小時的時間(系統默認超時時間的是 7200 秒,也就是 2 小時),如果服務端程式因某個原因導致系統造成一堆 close_wait 消耗資源,那么通常是等不到釋放那一刻,系統就已崩潰,
導致 close_wait 過多的可能原因如下:
- 程式處理 Bug,導致接收到對方的 fin 之后沒有及時關閉 socket,這可能是 Netty 的 Bug,也可能是業務層 Bug,需要具體問題具體分析;
- 關閉 socket 不及時:例如 I/O 執行緒被意外阻塞,或者 I/O 執行緒執行的用戶自定義 Task 比例過高,導致 I/O 操作處理不及時,鏈路不能被及時釋放,
下面我們結合 Netty 的原理,對潛在的故障點進行分析,
設計要點 1:不要在 Netty 的 I/O 執行緒上處理業務(心跳發送和檢測除外),Why? 對于 Java 行程,執行緒不能無限增長,這就意味著 Netty 的 Reactor 執行緒數必須收斂,Netty 的默認值是 CPU 核數 * 2,通常情況下,I/O 密集型應用建議執行緒數盡量設定大些,但這主要是針對傳統同步 I/O 而言,對于非阻塞 I/O,執行緒數并不建議設定太大,盡管沒有最優值,但是 I/O 執行緒數經驗值是 [CPU 核數 + 1,CPU 核數 *2 ] 之間,
假如單個服務器支撐 100 萬個長連接,服務器內核數為 32,則單個 I/O 執行緒處理的鏈接數 L = 100/(32 * 2) = 15625, 假如每 5S 有一次訊息互動(新訊息推送、心跳訊息和其它管理訊息),則平均 CAPS = 15625 / 5 = 3125 條 / 秒,這個數值相比于 Netty 的處理性能而言壓力并不大,但是在實際業務處理中,經常會有一些額外的復雜邏輯處理,例如性能統計、記錄介面日志等,這些業務操作性能開銷也比較大,如果在 I/O 執行緒上直接做業務邏輯處理,可能會阻塞 I/O 執行緒,影響對其它鏈路的讀寫操作,這就會導致被動關閉的鏈路不能及時關閉,造成 close_wait 堆積,
設計要點 2:在 I/O 執行緒上執行自定義 Task 要當心,Netty 的 I/O 處理執行緒 NioEventLoop 支持兩種自定義 Task 的執行:
- 普通的 Runnable: 通過呼叫 NioEventLoop 的 execute(Runnable task) 方法執行;
- 定時任務 ScheduledFutureTask: 通過呼叫 NioEventLoop 的 schedule(Runnable command, long delay, TimeUnit unit) 系列介面執行,
為什么 NioEventLoop 要支持用戶自定義 Runnable 和 ScheduledFutureTask 的執行,并不是本文要討論的重點,后續會有專題文章進行介紹,本文重點對它們的影響進行分析,
在 NioEventLoop 中執行 Runnable 和 ScheduledFutureTask,意味著允許用戶在 NioEventLoop 中執行非 I/O 操作類的業務邏輯,這些業務邏輯通常用訊息報文的處理和協議管理相關,它們的執行會搶占 NioEventLoop I/O 讀寫的 CPU 時間,如果用戶自定義 Task 過多,或者單個 Task 執行周期過長,會導致 I/O 讀寫操作被阻塞,這樣也間接導致 close_wait 堆積,
所以,如果用戶在代碼中使用到了 Runnable 和 ScheduledFutureTask,請合理設定 ioRatio 的比例,通過 NioEventLoop 的 setIoRatio(int ioRatio) 方法可以設定該值,默認值為 50,即 I/O 操作和用戶自定義任務的執行時間比為 1:1,
我的建議是當服務端處理海量客戶端長連接的時候,不要在 NioEventLoop 中執行自定義 Task,或者非心跳類的定時任務,
設計要點 3:IdleStateHandler 使用要當心,很多用戶會使用 IdleStateHandler 做心跳發送和檢測,這種用法值得提倡,相比于自己啟定時任務發送心跳,這種方式更高效,但是在實際開發中需要注意的是,在心跳的業務邏輯處理中,無論是正常還是例外場景,處理時延要可控,防止時延不可控導致的 NioEventLoop 被意外阻塞,例如,心跳超時或者發生 I/O 例外時,業務呼叫 Email 發送介面告警,由于 Email 服務端處理超時,導致郵件發送客戶端被阻塞,級聯引起 IdleStateHandler 的 AllIdleTimeoutTask 任務被阻塞,最終 NioEventLoop 多路復用器上其它的鏈路讀寫被阻塞,
對于 ReadTimeoutHandler 和 WriteTimeoutHandler,約束同樣存在,
3.3. 合理的心跳周期
百萬級的推送服務,意味著會存在百萬個長連接,每個長連接都需要靠和 App 之間的心跳來維持鏈路,合理設定心跳周期是非常重要的作業,推送服務的心跳周期設定需要考慮移動無線網路的特點,
當一臺智能手機連上移動網路時,其實并沒有真正連接上 Internet,運營商分配給手機的 IP 其實是運營商的內網 IP,手機終端要連接上 Internet 還必須通過運營商的網關進行 IP 地址的轉換,這個網關簡稱為 NAT(NetWork Address Translation),簡單來說就是手機終端連接 Internet 其實就是移動內網 IP,埠,外網 IP 之間相互映射,
GGSN(GateWay GPRS Support Note) 模塊就實作了 NAT 功能,由于大部分的移動無線網路運營商為了減少網關 NAT 映射表的負荷,如果一個鏈路有一段時間沒有通信時就會洗掉其對應表,造成鏈路中斷,正是這種刻意縮短空閑連接的釋放超時,原本是想節省信道資源的作用,沒想到讓互聯網的應用不得以遠高于正常頻率發送心跳來維護推送的長連接,以中移動的 2.5G 網路為例,大約 5 分鐘左右的基帶空閑,連接就會被釋放,
由于移動無線網路的特點,推送服務的心跳周期并不能設定的太長,否則長連接會被釋放,造成頻繁的客戶端重連,但是也不能設定太短,否則在當前缺乏統一心跳框架的機制下很容易導致信令風暴(例如微信心跳信令風暴問題),具體的心跳周期并沒有統一的標準,180S 也許是個不錯的選擇,微信為 300S,
在 Netty 中,可以通過在 ChannelPipeline 中增加 IdleStateHandler 的方式實作心跳檢測,在建構式中指定鏈路空閑時間,然后實作空閑回呼介面,實作心跳的發送和檢測,代碼如下:
public void initChannel({@link Channel} channel) {
channel.pipeline().addLast("idleStateHandler", new {@link IdleStateHandler}(0, 0, 180));
channel.pipeline().addLast("myHandler", new MyHandler());
}
攔截鏈路空閑事件并處理心跳:
public class MyHandler extends {@link ChannelHandlerAdapter} {
{@code @Override}
public void userEventTriggered({@link ChannelHandlerContext} ctx, {@link Object} evt) throws {@link Exception} {
if (evt instanceof {@link IdleStateEvent}} {
// 心跳處理
}
}
}
3.4. 合理設定接收和發送緩沖區容量
對于長鏈接,每個鏈路都需要維護自己的訊息接收和發送緩沖區,JDK 原生的 NIO 類別庫使用的是 java.nio.ByteBuffer, 它實際是一個長度固定的 Byte 陣列,我們都知道陣列無法動態擴容,ByteBuffer 也有這個限制,相關代碼如下:
public abstract class ByteBuffer
extends Buffer
implements Comparable
{
final byte[] hb; // Non-null only for heap buffers
final int offset;
boolean isReadOnly;
容量無法動態擴展會給用戶帶來一些麻煩,例如由于無法預測每條訊息報文的長度,可能需要預分配一個比較大的 ByteBuffer,這通常也沒有問題,但是在海量推送服務系統中,這會給服務端帶來沉重的記憶體負擔,假設單條推送訊息最大上限為 10K,訊息平均大小為 5K,為了滿足 10K 訊息的處理,ByteBuffer 的容量被設定為 10K,這樣每條鏈路實際上多消耗了 5K 記憶體,如果長鏈接鏈路數為 100 萬,每個鏈路都獨立持有 ByteBuffer 接識訓沖區,則額外損耗的總記憶體 Total(M) = 1000000 * 5K = 4882M,記憶體消耗過大,不僅僅增加了硬體成本,而且大記憶體容易導致長時間的 Full GC,對系統穩定性會造成比較大的沖擊,
實際上,最靈活的處理方式就是能夠動態調整記憶體,即接識訓沖區可以根據以往接收的訊息進行計算,動態調整記憶體,利用 CPU 資源來換記憶體資源,具體的策略如下:
- ByteBuffer 支持容量的擴展和收縮,可以按需靈活調整,以節約記憶體;
- 接收訊息的時候,可以按照指定的演算法對之前接收的訊息大小進行分析,并預測未來的訊息大小,按照預測值靈活調整緩沖區容量,以做到最小的資源損耗滿足程式正常功能,
幸運的是,Netty 提供的 ByteBuf 支持容量動態調整,對于接識訓沖區的記憶體分配器,Netty 提供了兩種:
- FixedRecvByteBufAllocator:固定長度的接識訓沖區分配器,由它分配的 ByteBuf 長度都是固定大小的,并不會根據實際資料報的大小動態收縮,但是,如果容量不足,支持動態擴展,動態擴展是 Netty ByteBuf 的一項基本功能,與 ByteBuf 分配器的實作沒有關系;
- AdaptiveRecvByteBufAllocator:容量動態調整的接識訓沖區分配器,它會根據之前 Channel 接收到的資料報大小進行計算,如果連續填充滿接識訓沖區的可寫空間,則動態擴展容量,如果連續 2 次接收到的資料報都小于指定值,則收縮當前的容量,以節約記憶體,
相對于 FixedRecvByteBufAllocator,使用 AdaptiveRecvByteBufAllocator 更為合理,可以在創建客戶端或者服務端的時候指定 RecvByteBufAllocator,代碼如下:
Bootstrap b = new Bootstrap();
b.group(group)
.channel(NioSocketChannel.class)
.option(ChannelOption.TCP_NODELAY, true)
.option(ChannelOption.RCVBUF_ALLOCATOR, AdaptiveRecvByteBufAllocator.DEFAULT)
如果默認沒有設定,則使用 AdaptiveRecvByteBufAllocator,
另外值得注意的是,無論是接識訓沖區還是發送緩沖區,緩沖區的大小建議設定為訊息的平均大小,不要設定成最大訊息的上限,這會導致額外的記憶體浪費,通過如下方式可以設定接識訓沖區的初始大小:
/**
* Creates a new predictor with the specified parameters.
*
* @param minimum
* the inclusive lower bound of the expected buffer size
* @param initial
* the initial buffer size when no feed back was received
* @param maximum
* the inclusive upper bound of the expected buffer size
*/
public AdaptiveRecvByteBufAllocator(int minimum, int initial, int maximum)
對于訊息發送,通常需要用戶自己構造 ByteBuf 并編碼,例如通過如下工具類創建訊息發送緩沖區:
圖 3-2 構造指定容量的緩沖區
3.5. 記憶體池
推送服務器承載了海量的長鏈接,每個長鏈接實際就是一個會話,如果每個會話都持有心跳資料、接識訓沖區、指令集等資料結構,而且這些實體隨著訊息的處理朝生夕滅,這就會給服務器帶來沉重的 GC 壓力,同時消耗大量的記憶體,
最有效的解決策略就是使用記憶體池,每個 NioEventLoop 執行緒處理 N 個鏈路,在執行緒內部,鏈路的處理時串行的,假如 A 鏈路首先被處理,它會創建接識訓沖區等物件,待解碼完成之后,構造的 POJO 物件被封裝成 Task 后投遞到后臺的執行緒池中執行,然后接識訓沖區會被釋放,每條訊息的接收和處理都會重復接識訓沖區的創建和釋放,如果使用記憶體池,則當 A 鏈路接收到新的資料報之后,從 NioEventLoop 的記憶體池中申請空閑的 ByteBuf,解碼完成之后,呼叫 release 將 ByteBuf 釋放到記憶體池中,供后續 B 鏈路繼續使用,
使用記憶體池優化之后,單個 NioEventLoop 的 ByteBuf 申請和 GC 次數從原來的 N = 1000000/64 = 15625 次減少為最少 0 次(假設每次申請都有可用的記憶體),
下面我們以推特使用 Netty4 的 PooledByteBufAllocator 進行 GC 優化作為案例,對記憶體池的效果進行評估,結果如下:
垃圾生成速度是原來的 1/5,而垃圾清理速度快了 5 倍,使用新的記憶體池機制,幾乎可以把網路帶寬壓滿,
Netty4 之前的版本問題如下:每當收到新資訊或者用戶發送資訊到遠程端,Netty 3 均會創建一個新的堆緩沖區,這意味著,對應每一個新的緩沖區,都會有一個 new byte[capacity],這些緩沖區會導致 GC 壓力,并消耗記憶體帶寬,為了安全起見,新的位元組陣列分配時會用零填充,這會消耗記憶體帶寬,然而,用零填充的陣列很可能會再次用實際的資料填充,這又會消耗同樣的記憶體帶寬,如果 Java 虛擬機(JVM)提供了創建新位元組陣列而又無需用零填充的方式,那么我們本來就可以將記憶體帶寬消耗減少 50%,但是目前沒有那樣一種方式,
在 Netty 4 中實作了一個新的 ByteBuf 記憶體池,它是一個純 Java 版本的 jemalloc (Facebook 也在用),現在,Netty 不會再因為用零填充緩沖區而浪費記憶體帶寬了,不過,由于它不依賴于 GC,開發人員需要小心記憶體泄漏,如果忘記在處理程式中釋放緩沖區,那么記憶體使用率會無限地增長,
Netty 默認不使用記憶體池,需要在創建客戶端或者服務端的時候進行指定,代碼如下:
Bootstrap b = new Bootstrap();
b.group(group)
.channel(NioSocketChannel.class)
.option(ChannelOption.TCP_NODELAY, true)
.option(ChannelOption.ALLOCATOR, PooledByteBufAllocator.DEFAULT)
使用記憶體池之后,記憶體的申請和釋放必須成對出現,即 retain() 和 release() 要成對出現,否則會導致記憶體泄露,
值得注意的是,如果使用記憶體池,完成 ByteBuf 的解碼作業之后必須顯式的呼叫 ReferenceCountUtil.release(msg) 對接識訓沖區 ByteBuf 進行記憶體釋放,否則它會被認為仍然在使用中,這樣會導致記憶體泄露,
3.6. 當心“日志隱形殺手”
通常情況下,大家都知道不能在 Netty 的 I/O 執行緒上做執行時間不可控的操作,例如訪問資料庫、發送 Email 等,但是有個常用但是非常危險的操作卻容易被忽略,那便是記錄日志,
通常,在生產環境中,需要實時列印介面日志,其它日志處于 ERROR 級別,當推送服務發生 I/O 例外之后,會記錄例外日志,如果當前磁盤的 WIO 比較高,可能會發生寫日志檔案操作被同步阻塞,阻塞時間無法預測,這就會導致 Netty 的 NioEventLoop 執行緒被阻塞,Socket 鏈路無法被及時關閉、其它的鏈路也無法進行讀寫操作等,
以最常用的 log4j 為例,盡管它支持異步寫日志(AsyncAppender),但是當日志佇列滿之后,它會同步阻塞業務執行緒,直到日志佇列有空閑位置可用,相關代碼如下:
synchronized (this.buffer) {
while (true) {
int previousSize = this.buffer.size();
if (previousSize < this.bufferSize) {
this.buffer.add(event);
if (previousSize != 0) break;
this.buffer.notifyAll(); break;
}
boolean discard = true;
if ((this.blocking) && (!Thread.interrupted()) && (Thread.currentThread() != this.dispatcher)) // 判斷是業務執行緒
{
try
{
this.buffer.wait();// 阻塞業務執行緒
discard = false;
}
catch (InterruptedException e)
{
Thread.currentThread().interrupt();
}
}
類似這類 BUG 具有極強的隱蔽性,往往 WIO 高的時間持續非常短,或者是偶現的,在測驗環境中很難模擬此類故障,問題定位難度非常大,這就要求讀者在平時寫代碼的時候一定要當心,注意那些隱性地雷,
3.7. TCP 引數優化
常用的 TCP 引數,例如 TCP 層面的接收和發送緩沖區大小設定,在 Netty 中分別對應 ChannelOption 的 SO_SNDBUF 和 SO_RCVBUF,需要根據推送訊息的大小,合理設定,對于海量長連接,通常 32K 是個不錯的選擇,
另外一個比較常用的優化手段就是軟中斷,如圖所示:如果所有的軟中斷都運行在 CPU0 相應網卡的硬體中斷上,那么始終都是 cpu0 在處理軟中斷,而此時其它 CPU 資源就被浪費了,因為無法并行的執行多個軟中斷,
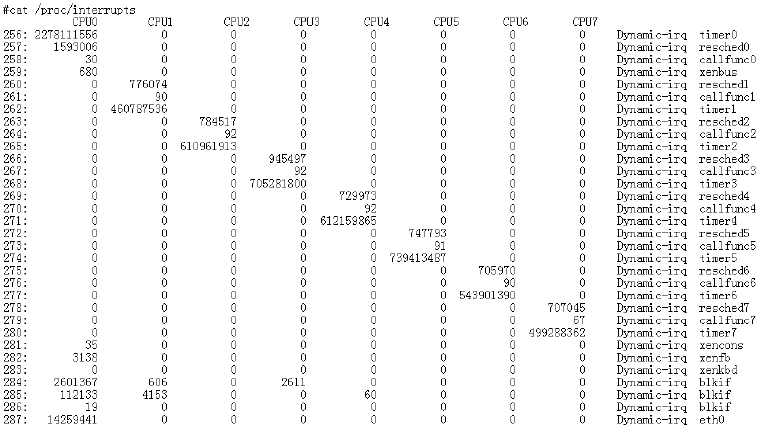
圖 3-3 中斷資訊
大于等于 2.6.35 版本的 Linux kernel 內核,開啟 RPS,網路通信性能提升 20% 之上,RPS 的基本原理:根據資料包的源地址,目的地址以及目的和源埠,計算出一個 hash 值,然后根據這個 hash 值來選擇軟中斷運行的 cpu,從上層來看,也就是說將每個連接和 cpu 系結,并通過這個 hash 值,來均衡軟中斷運行在多個 cpu 上,從而提升通信性能,
3.8. JVM 引數
最重要的引數調整有兩個:
- -Xmx:JVM 最大記憶體需要根據記憶體模型進行計算并得出相對合理的值;
- GC 相關的引數: 例如新生代和老生代、永久代的比例,GC 的策略,新生代各區的比例等,需要根據具體的場景進行設定和測驗,并不斷的優化,盡量將 Full GC 的頻率降到最低,
來源:https://www.infoq.cn/article/netty-million-level-push-service-design-points/
歡迎關注公眾號 【碼農開花】一起學習成長
我會一直分享Java干貨,也會分享免費的學習資料課程和面試寶典
回復:【計算機】【設計模式】【面試】有驚喜哦
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/249320.html
標籤:Java
下一篇:PMP知識領域