專案前言
自學python差不多有一年半載了,這兩天利用在甲方公司搬磚空閑之余寫了個小專案——【12306-tiebanggg-master】剛好在昨天幫朋友搶了一張票(祝他一路平安)hhhhh,注:本專案僅供學習研究,如若侵犯到貴公司權益請聯系我第一時間進行洗掉;請勿用于一切非法行為,否則后果自行承擔!
專案描述
通過分析123O6,車次串列資訊無需登錄即可獲取,但是如果我們想要使用代碼代替手動為自己進行購票時,則需要進行登錄網站;為了不給對方服務器造成壓力,本專案并未開啟多執行緒,專案為全自動進行車票的購買,包括(登錄、驗證碼識別、刷票、判斷是否有票、預購、下單、郵箱通知)本專案思路——使用selenium登錄網站獲取到cookie(供后續購票使用),定時檢查cookie是否有效,獲取列車串列資訊及購票流程均使用requests的方式進行,流程如下:
1. 獲取車次串列資訊并對獲取到的資訊進行清洗處理;
2. selenium登錄;
3. 超級鷹驗證碼處理(圖片點選/滑塊);
4. 獲取cookie并保存至本地;
5. 判斷是否有所選擇的車次車票;
6. requests購票;
7. 完成搶票;
8. 將購票信心發送至郵箱;
9. 付款,
專案結構如圖:
專案效果:
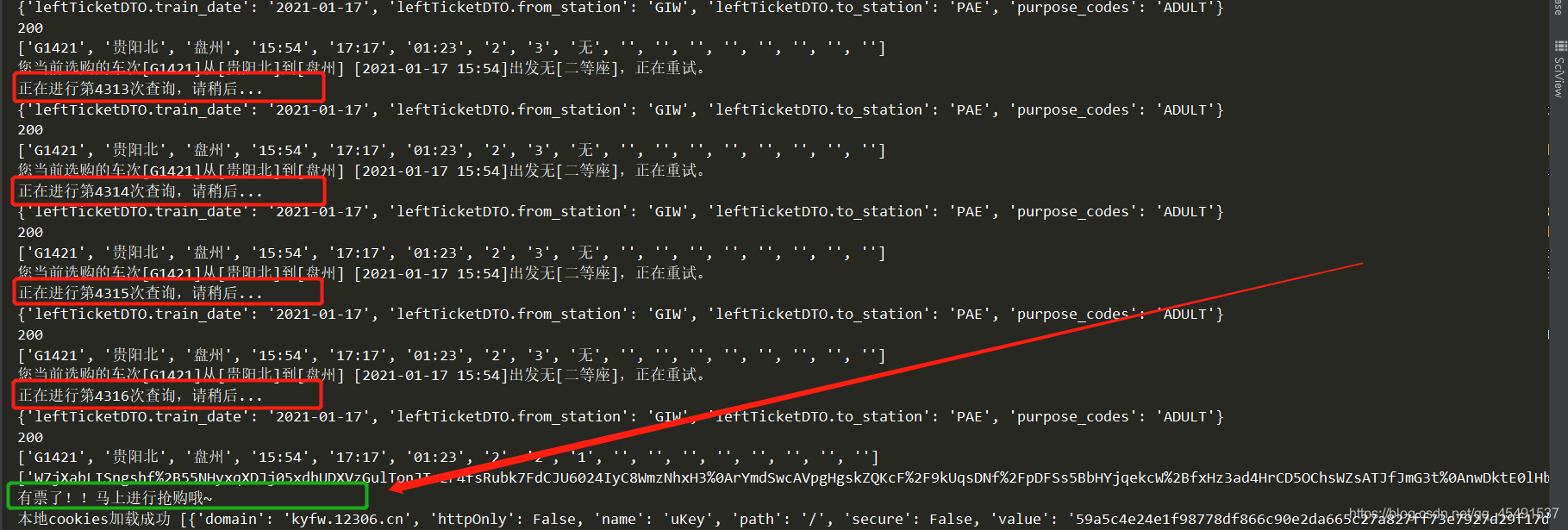
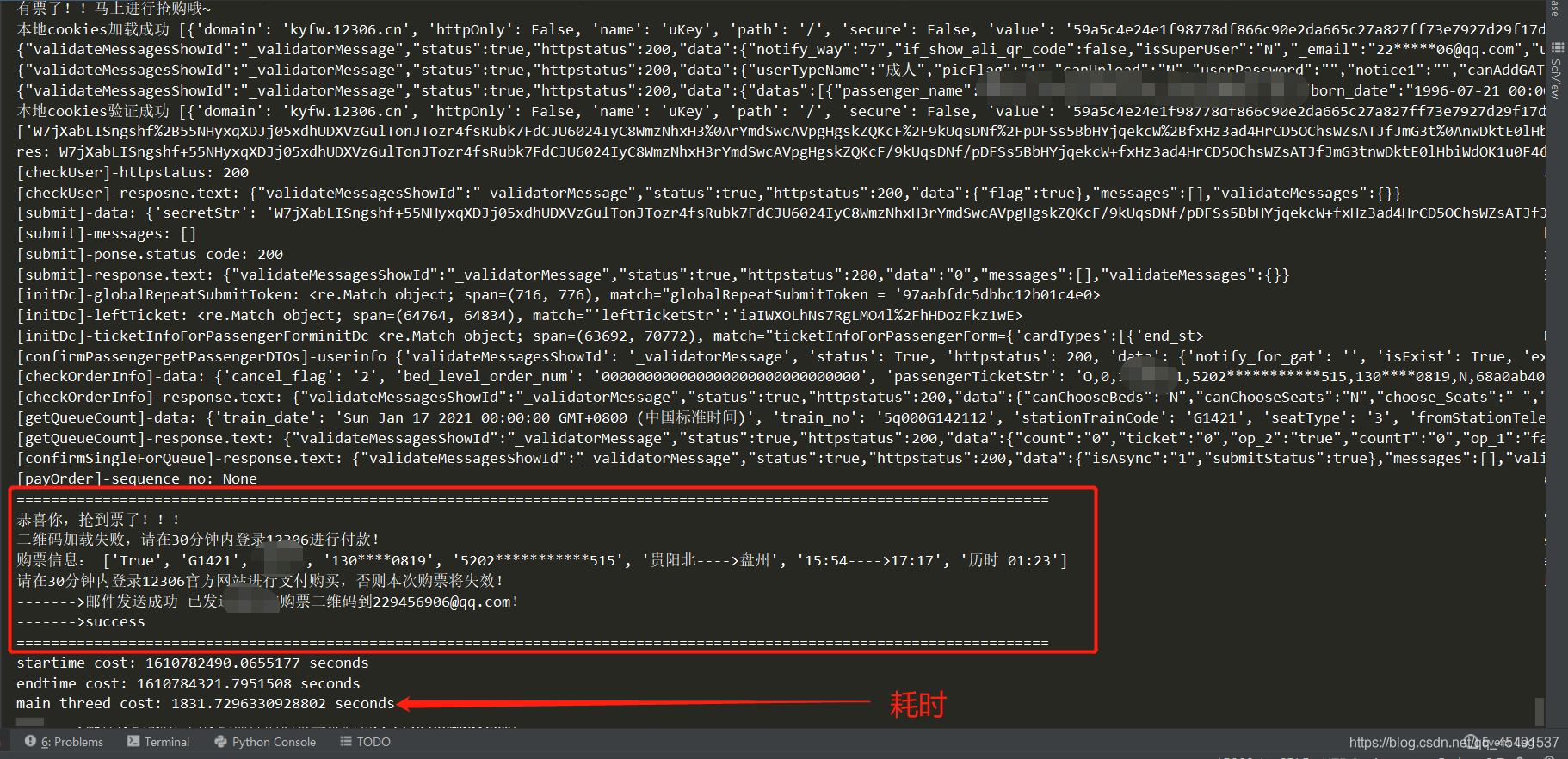
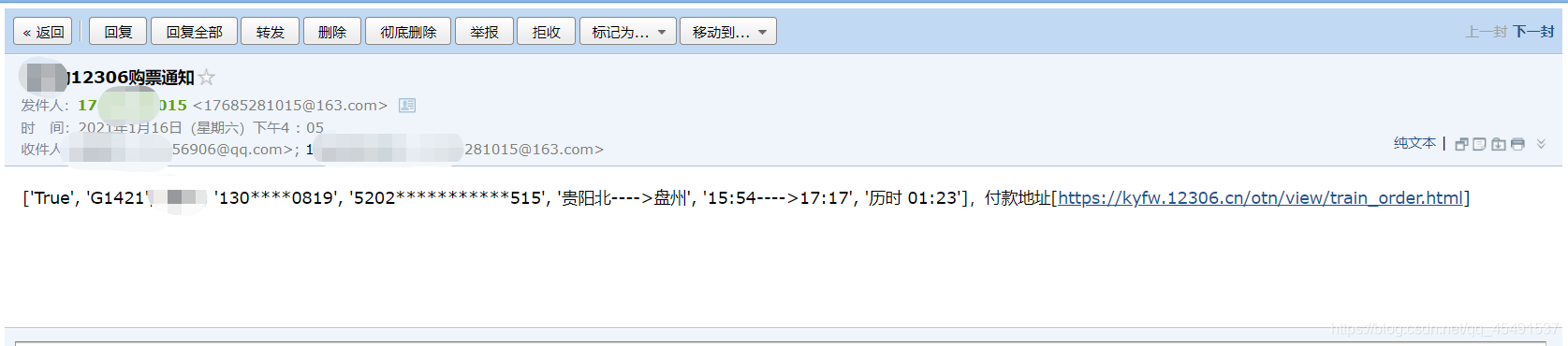
最后搶到票的時候耗時總共用了1800秒并且郵件發送到了我的郵箱中(也可以通過微信進行通知,由于忙著寫博客暫時不加入微信通知), 差不多半個小時,,,也就是說我在沒有開多執行緒的情況下每秒的并發量可以達到2.3次,
技術手段及第三方打碼平臺的使用
本專案思路、程序過于復雜,共分為【列車資料獲取篇】【selenium登錄驗證篇】【購票篇】【專案結束】,本篇文章只講第一點【列車資料獲取篇】
涉及到的第三方包:
① selenium
② requests
③ lxml
④ PIL
⑤ smtplib
⑥ email
打碼平臺:超級鷹
為什么使用第三方打碼:
① 可以采用tensorflow等訓練模型的方式進行驗證碼識別,但由于需要時間成本太大,果斷放棄(其實是學藝不精,菜鳥,搞不定此處省略一萬個#¥#¥%@#@¥),
②由于12303采用圖片點選和滑塊的登陸驗證方式,超級鷹可以識別并回傳正確圖片的坐標(供我們使用selenium進行點選操作)很方便,且10塊大洋10000積分很實惠(宣告:沒有被超級鷹充值),至于滑塊驗證的話本專案使用純手工打造的代碼進行實作驗證通過率為99+%,
郵件發送:
當我們購票成功后,程式會自動將資訊發送至設定郵箱通知付款,
好了,正片開始~
一. 獲取列車串列資訊并處理資料
本次“幸運”物件地址:aHR0cHM6Ly93d3cuMTIzMDYuY24vaW5kZXgvaW5kZXguaHRtbA==
1. 抓包
①搜先進入車票搜索頁面進行車票檢索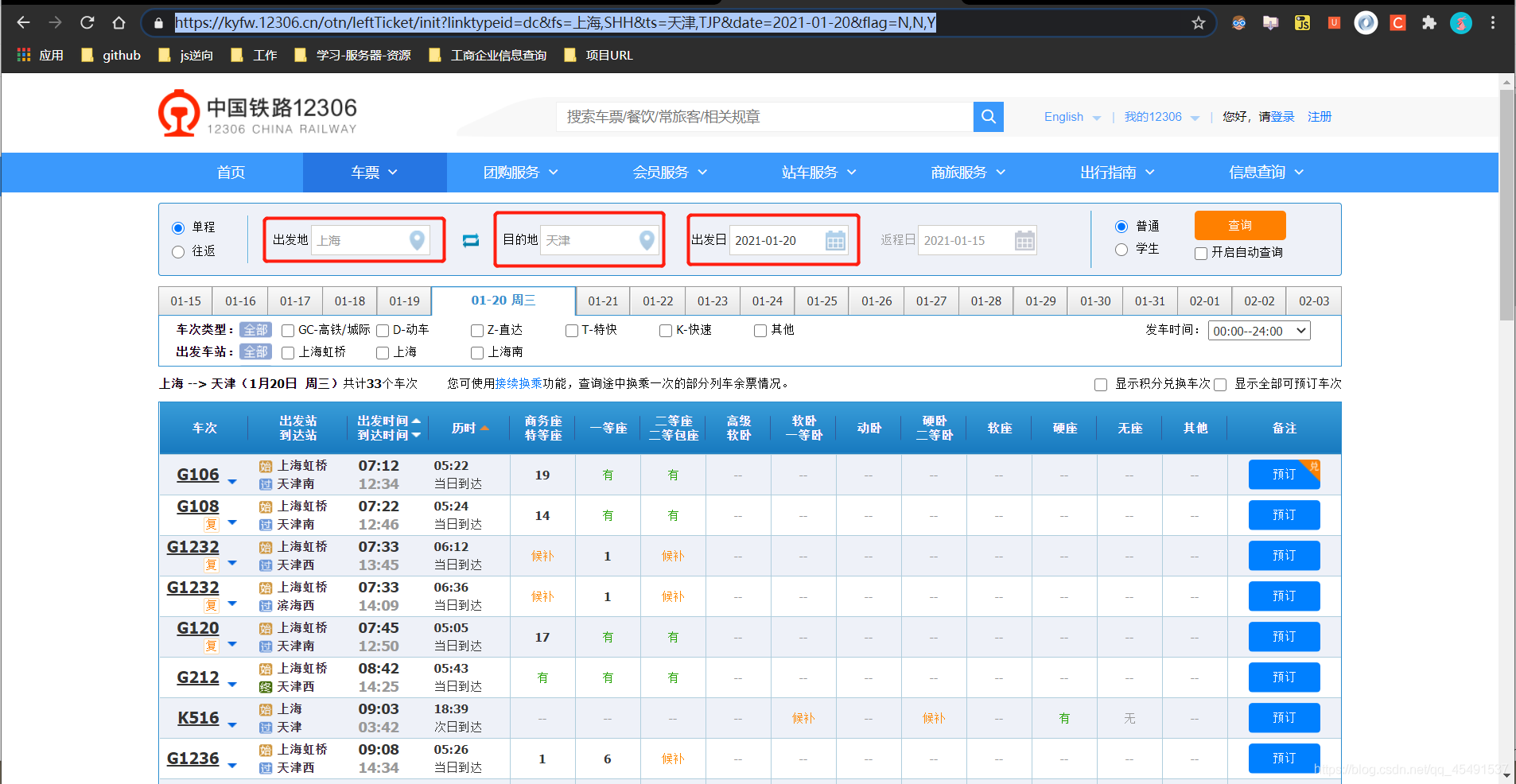
可以看到我們輸入【上海—天津】時間為【2021-01-20】點擊查詢后便可以看到所有的車次串列資訊地址欄URL變化為https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc&fs=上海,SHH&ts=天津,TJP&date=2021-01-20&flag=N,N,Y
URL中帶上了我們在輸入框中輸入的資訊并回傳資料,接下來通過代碼請求網頁:
import requests
fs = '上海'
ts = '天津'
date = '2021-01-20'
url = "https://kyfw.12306.cn/otn/leftTicket/init?linktypeid=dc&fs={},SHH&ts={},TJP&date={}&flag=N,N,Y"
headers = {
'Host': 'kyfw.12306.cn',
'Origin': 'https://kyfw.12306.cn',
'Referer': 'https://kyfw.12306.cn/otn/confirmPassenger/initDc',
'sec-ch-ua': '"Google Chrome";v="87", " Not;A Brand";v="99", "Chromium";v="87"',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36',
}
response = requests.get(url=url, headers=headers)
# 列印網頁文本
print(response.text)
請求到網頁文本資料之后通過run視窗進行查詢資料是否存在: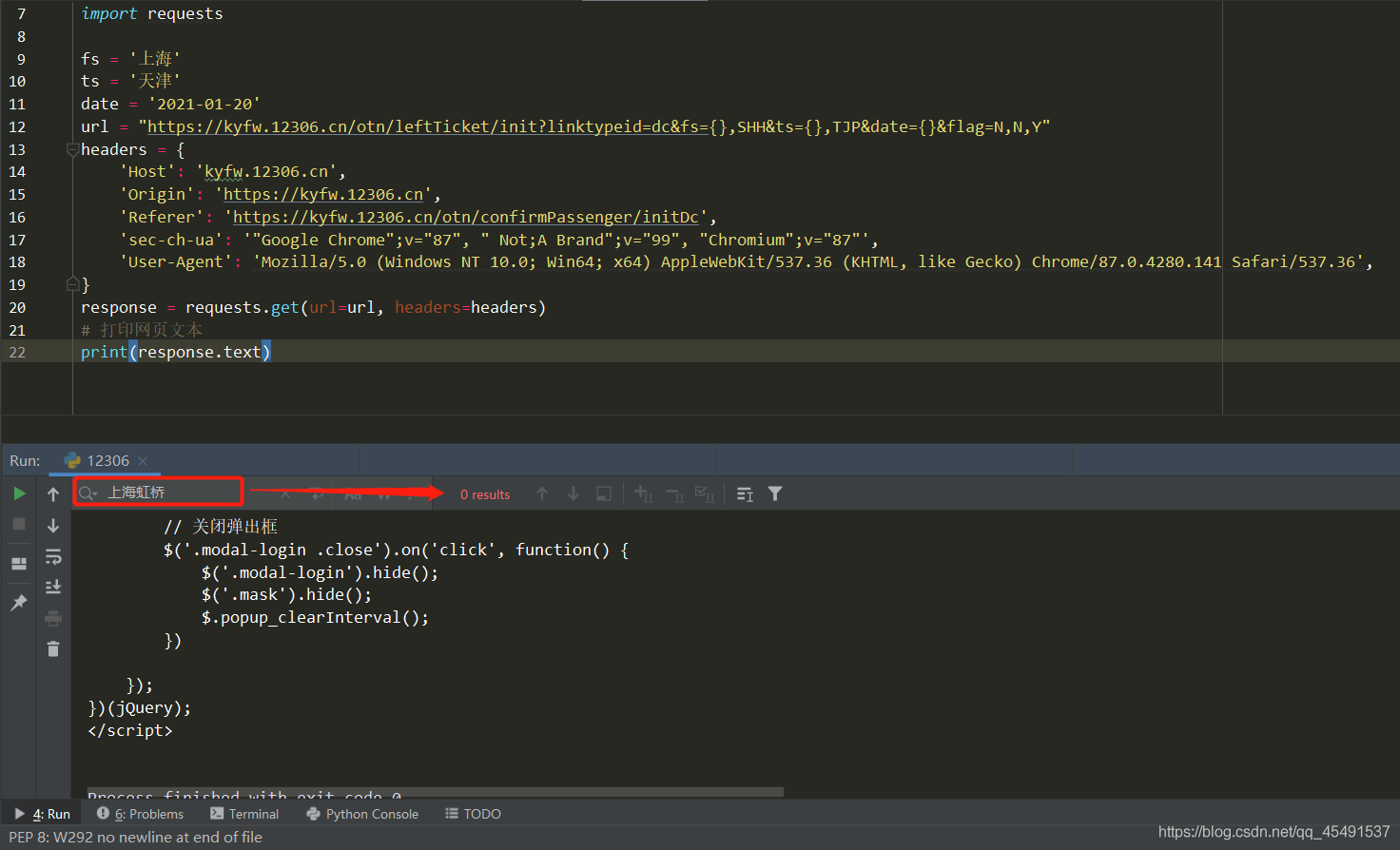
瓦特???沒資料,于是我將headers中資訊全部添加完整、帶上cookie之后再進行請求,然鵝并沒有什么暖用,資料依然不見蹤影…
接下來我心存幻想:網頁是不是異步加載?
于是乎:
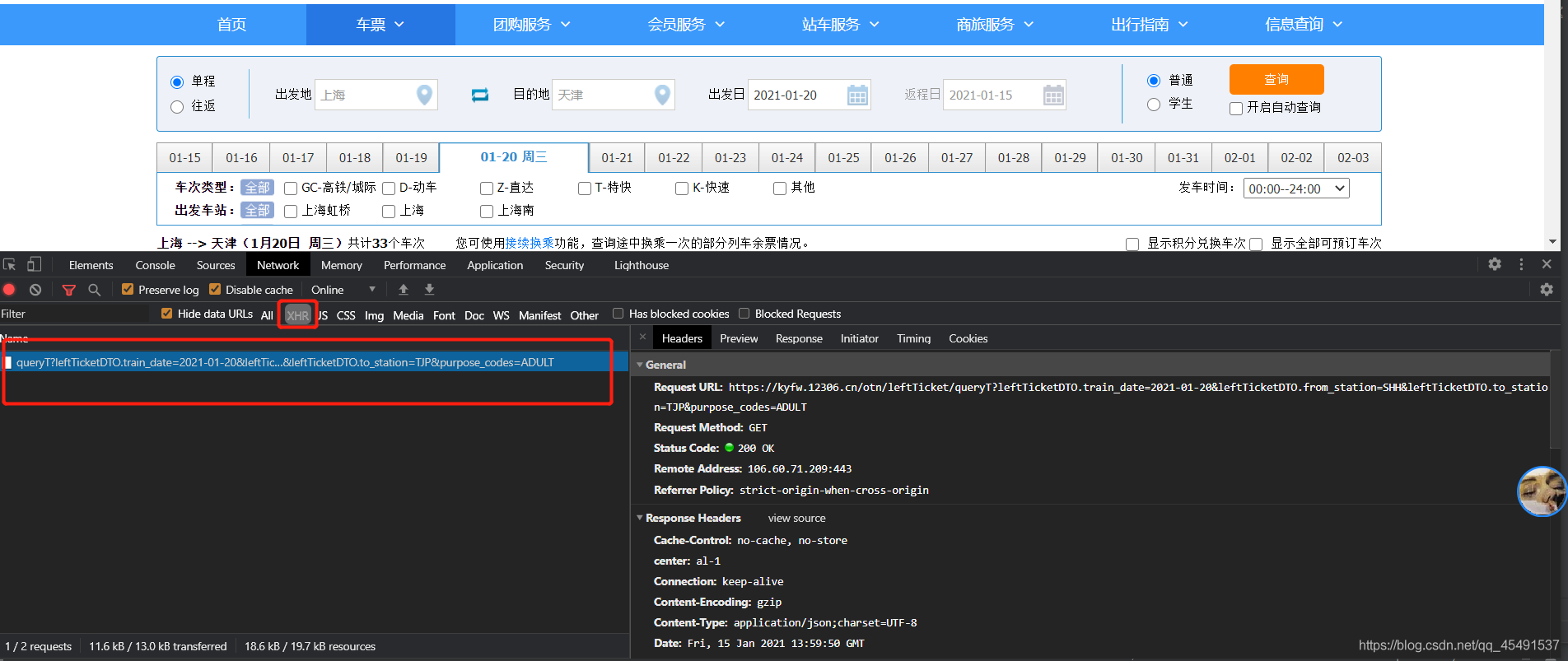
當按下F12,并選擇XHR(異步加載請求抓包)重新點擊查詢后出來了這么個玩意,接下來點擊Preview看看回傳值:
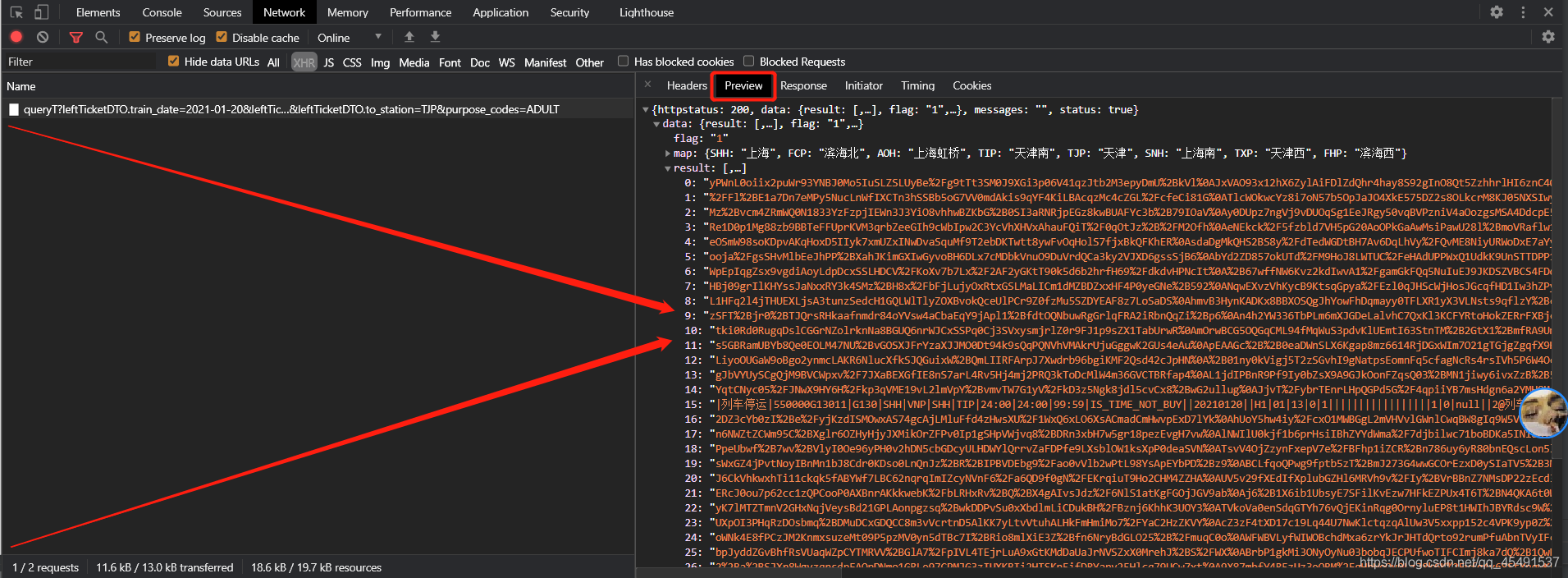
這是個啥玩意?這時候不慌,先點擊Response查詢資料看看,以 G106這列車來進行搜索:
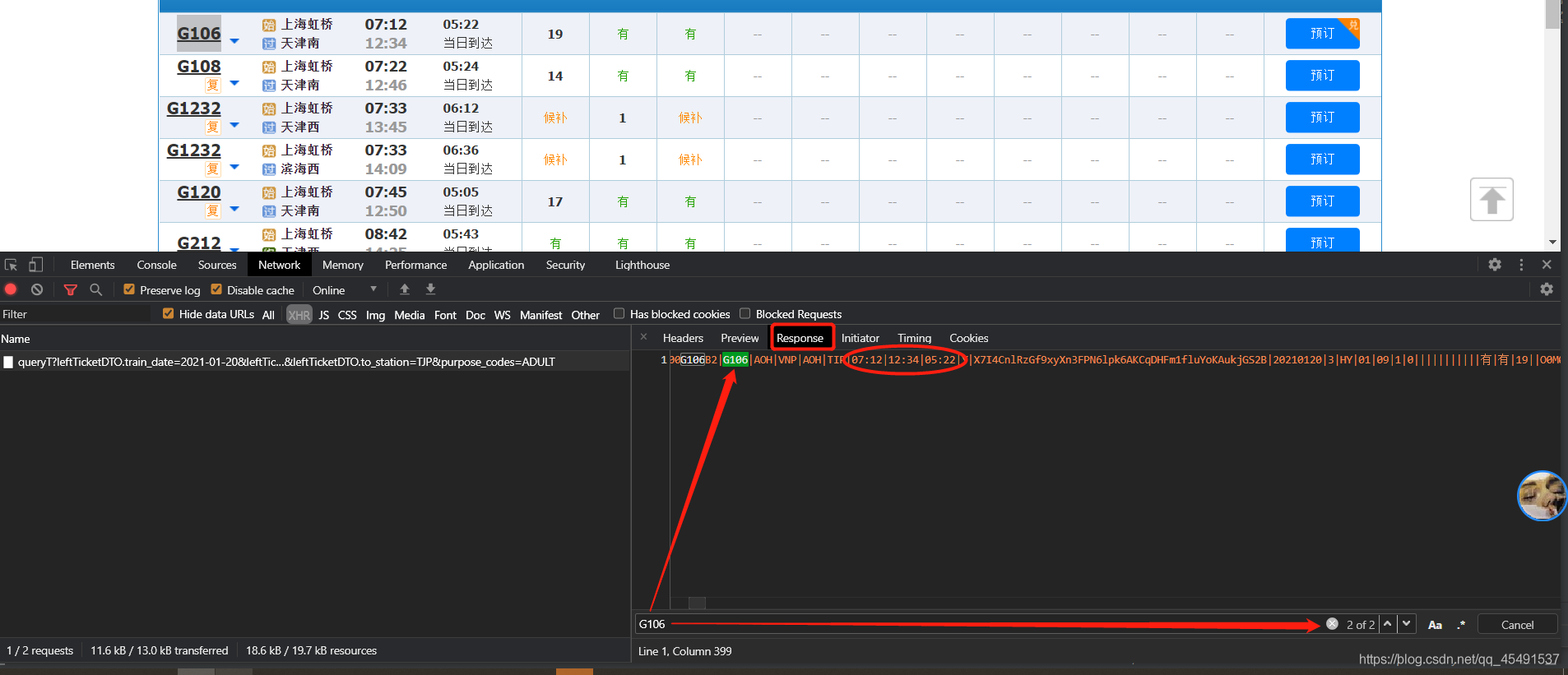
真香大白了hhh~列車資料是通過異步加載地址:https://kyfw.12306.cn/otn/leftTicket/queryT?leftTicketDTO.train_date=2021-01-20&leftTicketDTO.from_station=SHH&leftTicketDTO.to_station=TJP&purpose_codes=ADULT請求而得到,看看請求方式及提交的表單資訊:
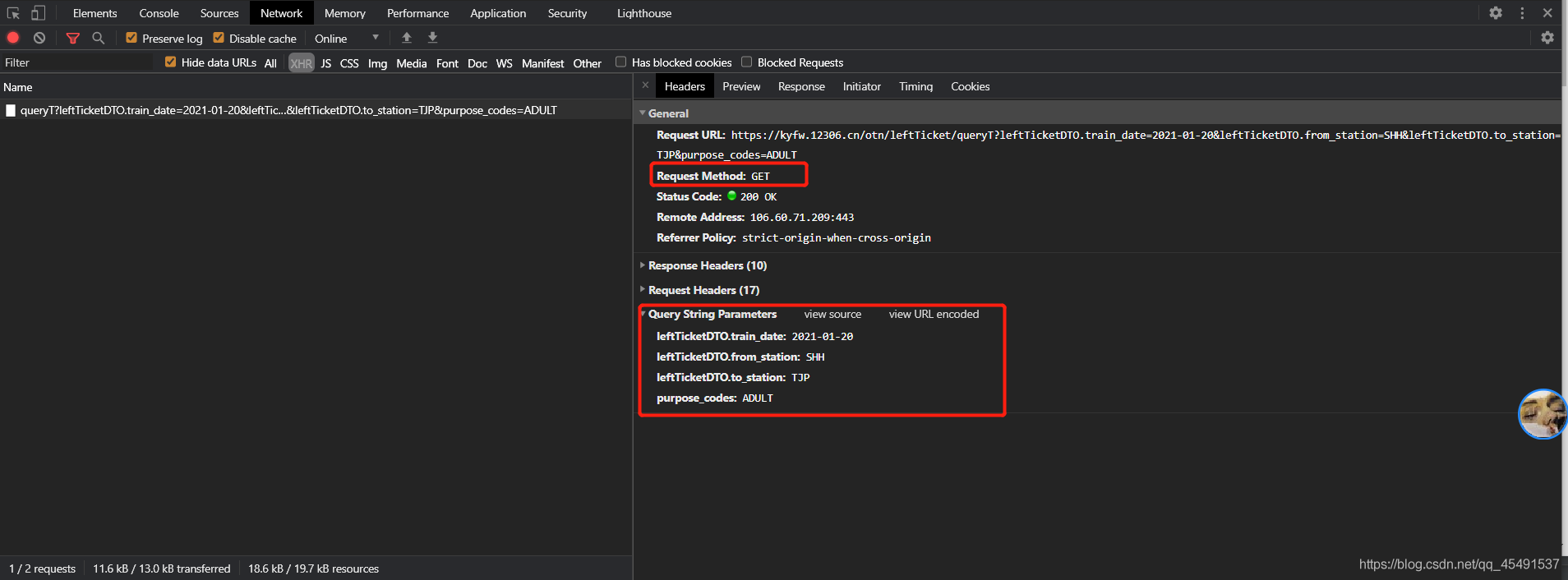
可以看到請求方式為get,提交的表單有leftTicketDTO.train_date、leftTicketDTO.from_station、leftTicketDTO.to_station、purpose_codes 經過多次抓包purpose_codes引數為固定值,leftTicketDTO.train_date為我們填入的購票日期,另外兩個跟著我們填入的出發點和目的地一直在改變,我猜想這應該是出發地和目的地的對應代碼,接下來我們清空之前的抓包資料再進行一次抓包,并以我們輸入的出發地【上海】進行全域搜索:
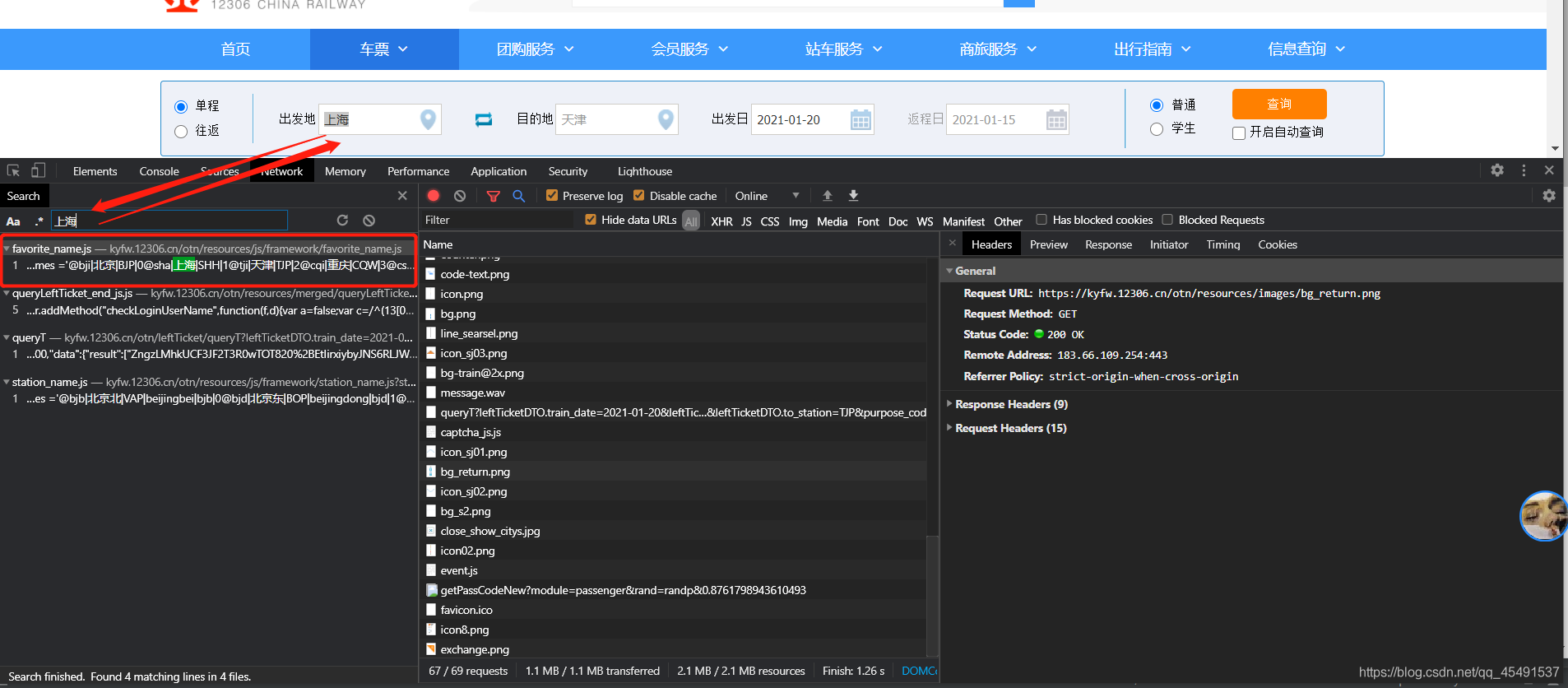
發現了什么~[/手動滑稽],接著點擊這條連接看看回傳資料:
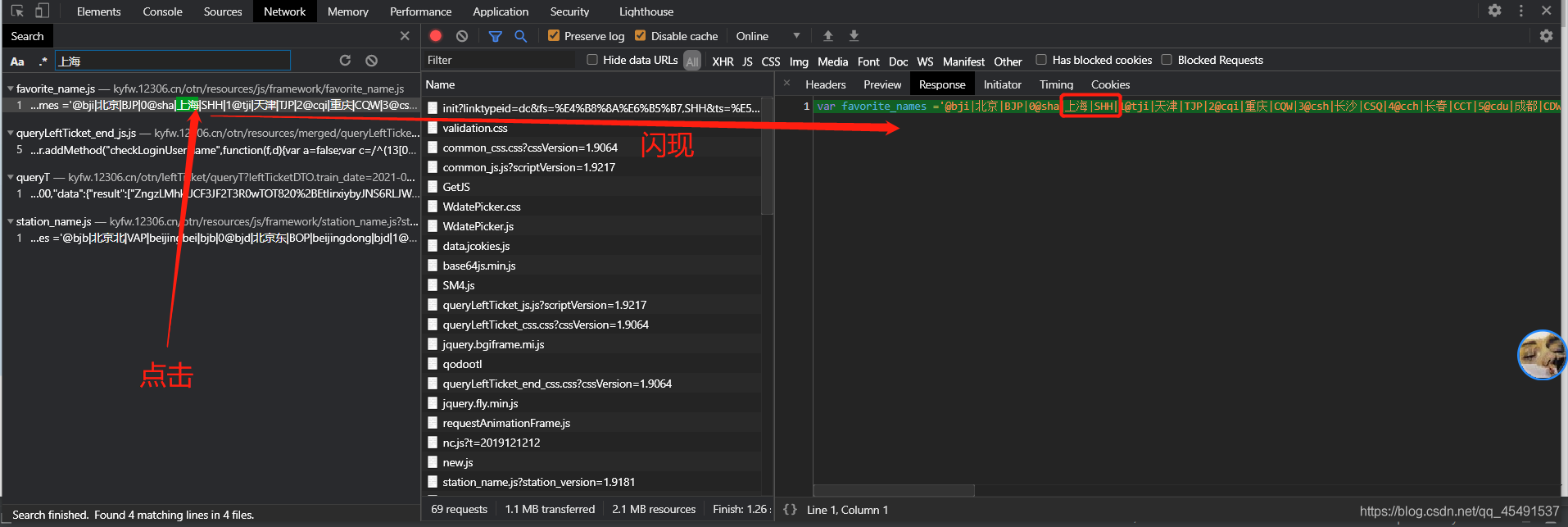
通過回傳資料可以看到【上海】后面跟的是一個【SHH】,沒錯,到這里我們找到了之前我們的leftTicketDTO.from_station=SHH變數,再進一步搜索【天津】:
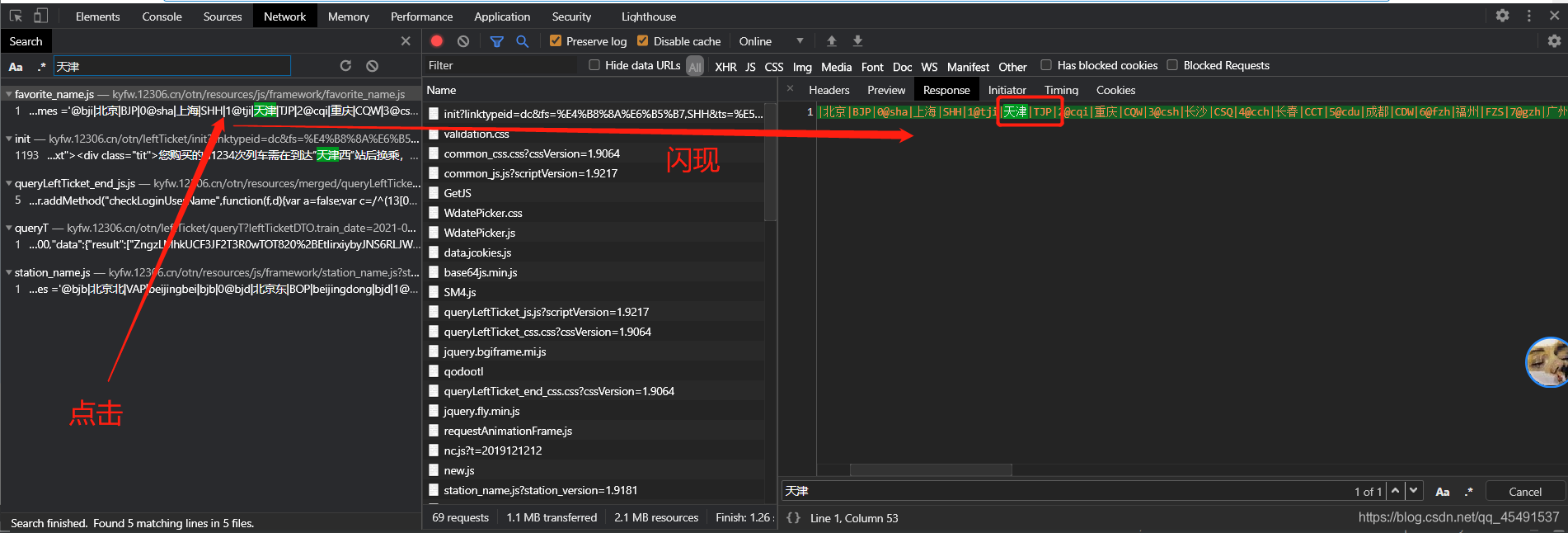
沒錯,leftTicketDTO.to_station=TJP, 也就是說這里找到了出發地和目的地對應的代碼,接下來可以請求這個地址進行出發地和目的地代碼提取了,但是這里有細節需要注意一下:
當我搜索出發地或者目的地關鍵字時可以看到回傳的地址并不是唯一一個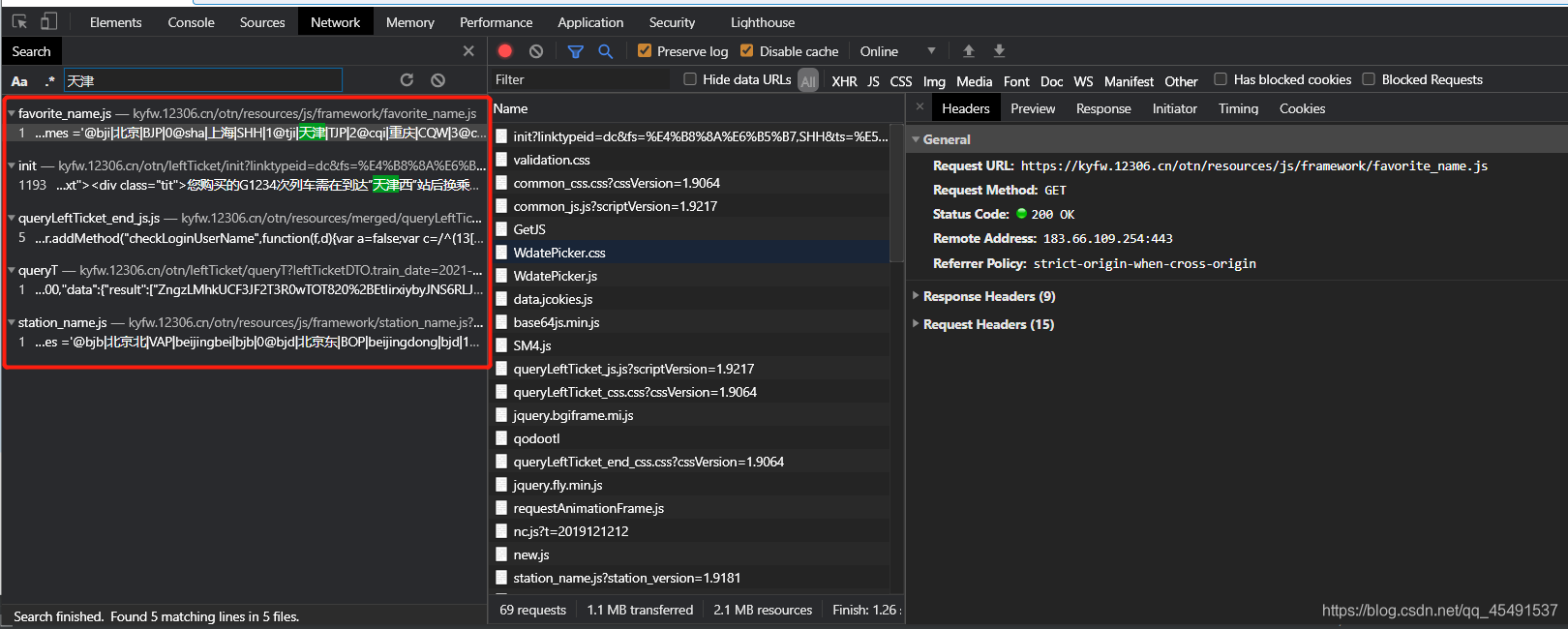
樓主之前使用第一條地址進行請求時,雖然能夠回傳出發地和目的地對應的代碼,但是資料并不全,so,經過我多次觀察,出發點和目的地回傳最全的地址為截圖中第五條地址, 如何操作:
左邊點擊地址,右邊再點擊Headers即可查看到對應的URL并且請求方式為get
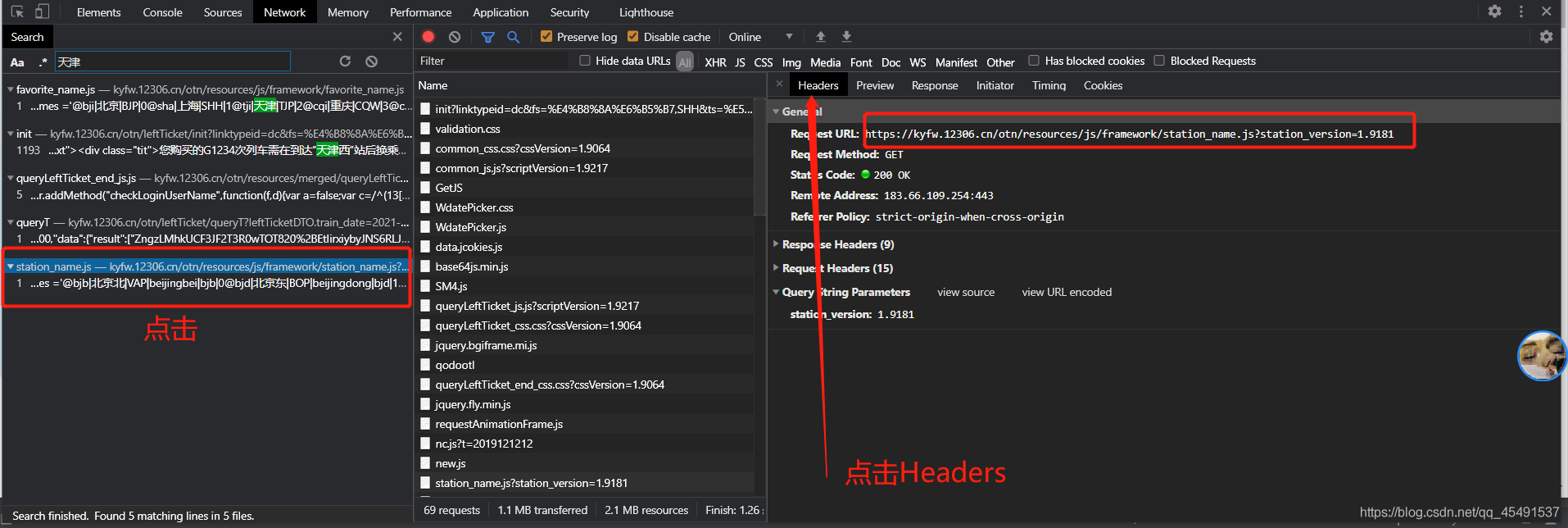
接下來寫代碼獲取全國出發站臺的對應id,代碼實作:
"""
獲取城市站臺對應代號并保存到本地
:return: dict
"""
# 通過抓包可知城市代碼資訊為請求如下地址
url = "https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9181"
response = requests.get(url=url).text
# print(response)
# 通過正則運算式獲取需要資料
find_city = re.findall(r'@.*?\|(.*?)\|', response)
find_city_id = re.findall(r'@.*?\|.*?\|(.*?)\|', response)
city_id_dict = {}
for c, i in zip(find_city, find_city_id):
city_id_dict[c] = i
print(city_id_dict)
# 保存資料至本地
with open('_utils/citytilss/city.txt', 'w', encoding='utf-8') as f:
f.write(str(city_id_dict))
列印日志:
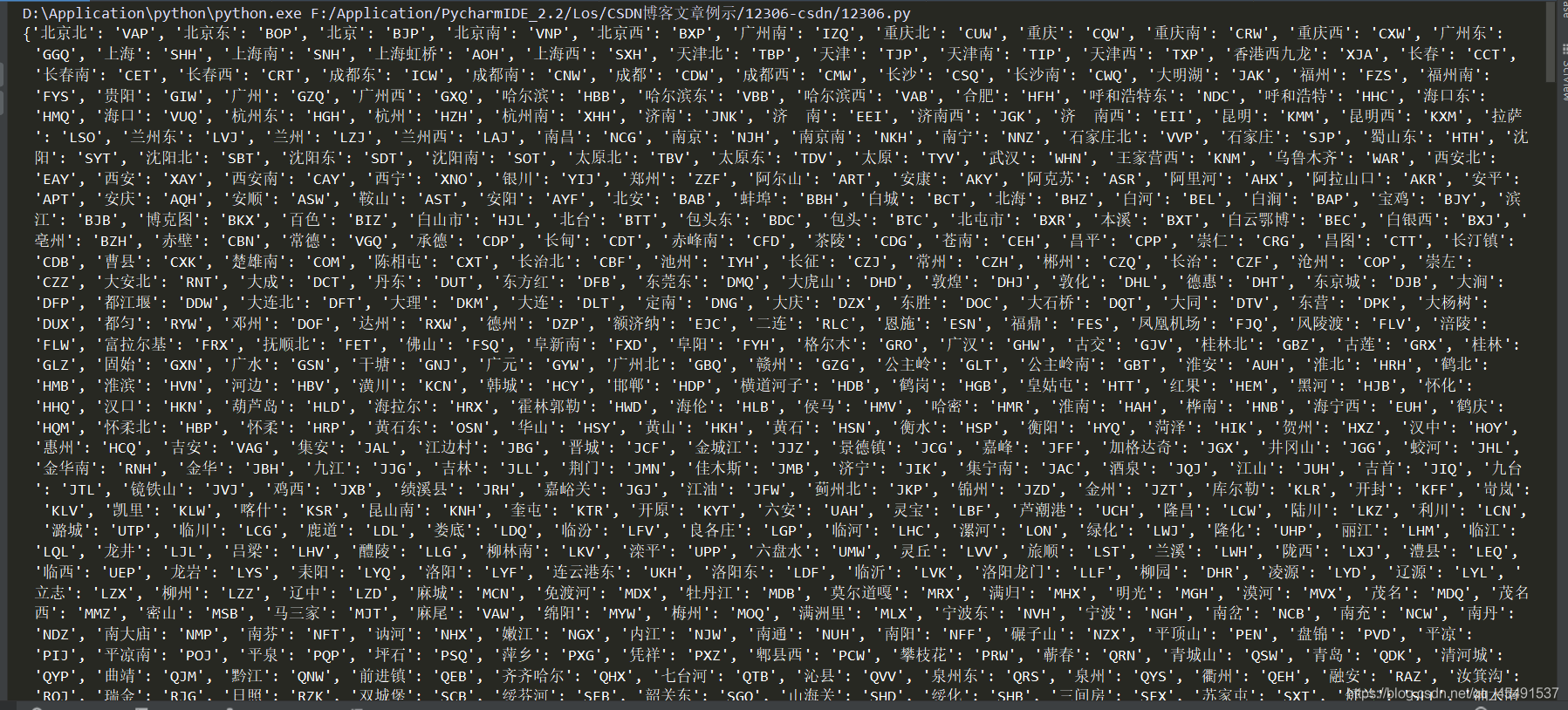
將保存為字典格式,以便后續獲取列車資訊使用,代碼實作獲取列車資訊:
# -- coding: utf-8 --
# @Time : 2021/1/15 21:45
# @Author : Los Angeles Clippers
import requests
import json
import re
def city_id():
"""
獲取城市站臺對應代號并保存到本地
:return: dict
"""
# 通過抓包可知城市代碼資訊為請求如下地址
url = "https://kyfw.12306.cn/otn/resources/js/framework/station_name.js?station_version=1.9181"
response = requests.get(url=url).text
# print(response)
# 通過正則運算式獲取需要資料
find_city = re.findall(r'@.*?\|(.*?)\|', response)
find_city_id = re.findall(r'@.*?\|.*?\|(.*?)\|', response)
city_id_dict = {}
for c, i in zip(find_city, find_city_id):
city_id_dict[c] = i
print(city_id_dict)
# 保存資料至本地
with open('_utils/citytilss/city.txt', 'w', encoding='utf-8') as f:
f.write(str(city_id_dict))
return city_id_dict
def decrypt(string):
"""
處理字串
:param string:
:return:
"""
# 定義正則運算式提取規則
reg1 = re.compile('.*?\|預訂\|.*?\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|.*?\|.*')
reg2 = re.compile('.*?\|.*?起售\|.*?\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|.*?\|.*')
reg3 = re.compile('.*?\|.*?停運\|.*?\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|.*?\|.*')
reg4 = re.compile('.*?\|.*?暫停發售\|.*?\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|.*?\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|(.*?)\|.*?\|.*?\|.*?\|.*')
# 因網站存在三種狀態的列車資訊,所以使用try陳述句進行處理,
try:
result = re.findall(reg1,string)[0]
except IndexError as e:
try:
result = re.findall(reg2, string)[0]
except:
try:
result = re.findall(reg3, string)[0]
except:
result = re.findall(reg4, string)[0]
return result
def getchepiaoinfo(city_id_dict):
"""
獲取列車資訊并保存至本地,
:param city_id_dict:
:return:
"""
# 通過抓包可知車次資訊為請求如下地址得到
fs = '上海'
ts = '天津'
date = '2021-01-20'
url = "https://kyfw.12306.cn/otn/leftTicket/queryT?"
# 構造form表單
params = {
'leftTicketDTO.train_date': date,
'leftTicketDTO.from_station': city_id_dict[fs],
'leftTicketDTO.to_station': city_id_dict[ts],
'purpose_codes': 'ADULT',
}
headers = {
'Accept': '*/*',
'Accept-Encoding': 'gzip, deflate, br',
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Host': 'kyfw.12306.cn',
'If-Modified-Since': '0',
'Pragma': 'no-cache',
'sec-ch-ua': '"Google Chrome";v="87", " Not;A Brand";v="99", "Chromium";v="87"',
'sec-ch-ua-mobile': '?0',
'Sec-Fetch-Dest': 'empty',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Site': 'same-origin',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36',
'X-Requested-With': 'XMLHttpRequest',
'Cookie': '', # 自行添加
}
response = requests.get(url=url, params=params, headers=headers)
print(response.status_code)
# 請求到的資料使用json來進行處理
jsdata = json.loads(response.text)['data']['result']
read_id = {}
for k, v in city_id_dict.items():
read_id[v] = k
# 獲取車次詳情資訊,并保存至本地
for item in jsdata:
# break
result = list(decrypt(item))
result[1] = fs
result[2] = ts
# 構建content串列,用于存放列車資訊
content = [result[0], read_id[item.split('|')[6]], read_id[item.split('|')[7]], result[3], result[4], result[5], result[-1], result[-2], result[-3],
result[6], result[-10], result[8], result[-5], result[9], result[-4], result[-7], result[-6]]
print(content)
def spider_main():
# 主函式,程式運行入口
city_id_dict = city_id()
secretStr = getchepiaoinfo(city_id_dict=city_id_dict)
return secretStr
if __name__ == '__main__':
spider_main()
運行結果:
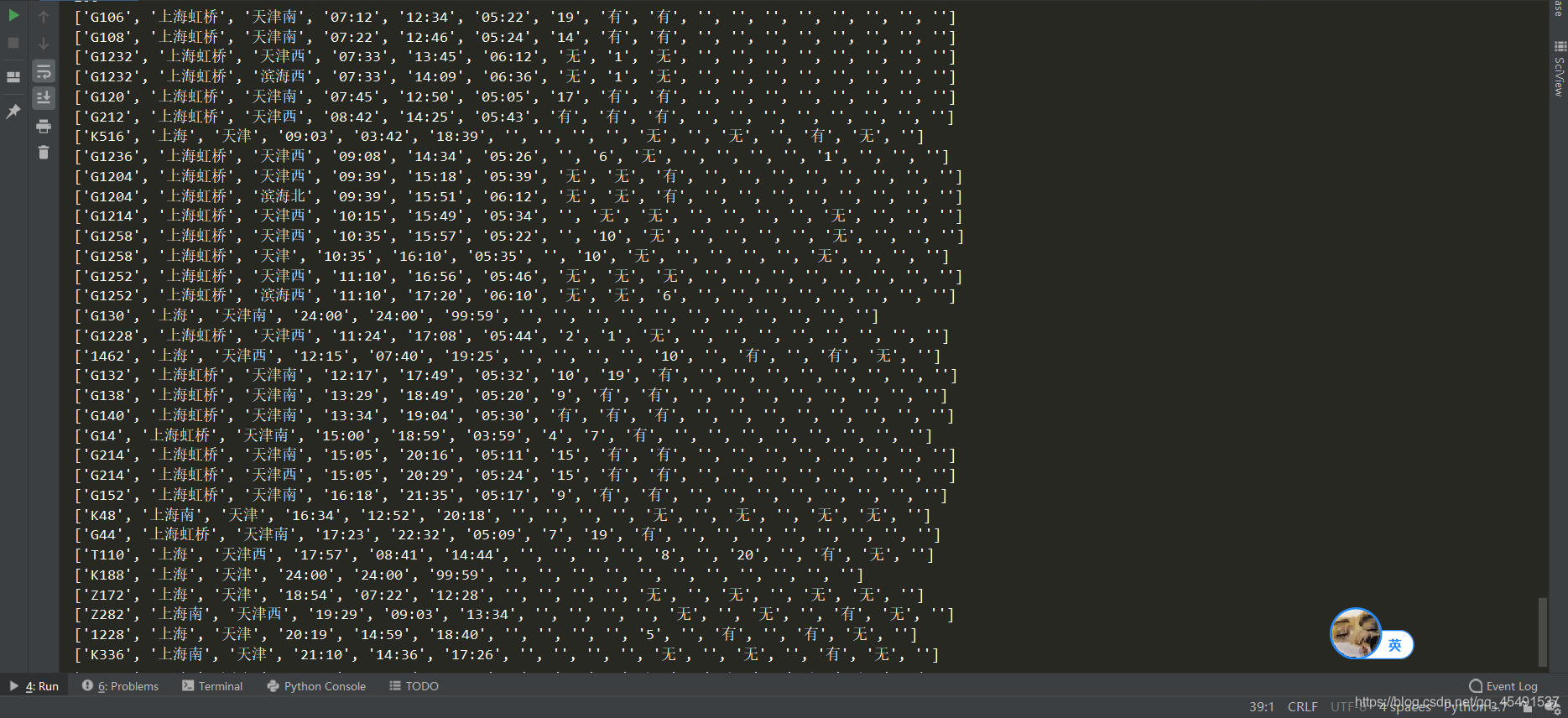
可以看到,我們到此為止獲取到了上海到天津的所有車次串列資訊,本篇文章只對程序進行敘述,具體代碼實作如有不明白的請v我解答,
接下來購票需要登錄,所以下一章節我們將會講解如何進行12306登錄并處理驗證碼,
下一章節【python爬取12306列車資訊自動搶票并自動識別驗證碼(二)selenium登錄驗證篇】 敬請期待
碼字不容易,如果不能篇文章對你有幫助請點贊,謝謝~
告辭,還有單子要寫~,明天更新登錄篇
需專案【12306-tiebanggg-master】原始碼請加v:tiebanggg 【注明來意】
*注:本文為原創文章,轉載文章請附上本文鏈接,謝謝!
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/249912.html
標籤:python
上一篇:使用邊緣計算網關分析CAN報文