前言
這個是用來講述go調度器機制和特性的第三部分. 這個主要關注并發.
博客三部分的順序:
1) go調度: 第一部分-作業系統調度
2) go調度: 第二部分-go調度器
3) go調度: 第三部分-并發
介紹
當我在解決一個問題, 尤其是一個新問題的時候, 開始階段, 我不會考慮并發是不是有用. 我尋找一個順序化解決方案, 并且確保這個方案有效. 然后, 我進行評估, 來看看并發是否合適. 有些情況下, 并發是很合適的, 而有些情況下則未必.
在第一部分,我講了作業系統的調度器的特性, 如果你想寫多執行緒應用, 這個是很有必要的. 在第二部分, 我講了go的調度器特性, 我認為, 這個對使用go語言寫多執行緒是很有意義的. 在這篇中, 我將結合作業系統調度和go程調度, 來提供一個對于使用go語言寫多執行緒的更加深入的理解.
這篇博客的目的是:
(1) 辨別你代碼應用的場景是否適合使用并發.
(2) 展示如何根據應用場景改變并發的使用.
什么是并發
并發意味著亂序執行. 一系列指令, 可以被順序執行, 也可以在滿足限制的情況下亂序執行, 但是還是可以產生相同的結果. 對于你眼前的這個問題, 亂序執行必須可以展示出明顯的價值, 也就是說, 并發可以明顯的提高性能, 同時, 沒有代碼復雜度的增加可以容忍. 根據你的問題, 亂序執行有時候是不可行的.
有一個重要的點需要注意, 并發不等于并行. 并行意味著同一時間執行多條指令. 這個與并發的概念并不相同. 只有在有至少2個作業系統執行緒(運行在兩個硬體執行緒之上), 并且有至少2個go程的情況下, 每個作業系統/硬體執行緒運行一組指令的情況下, 并行才會發生.
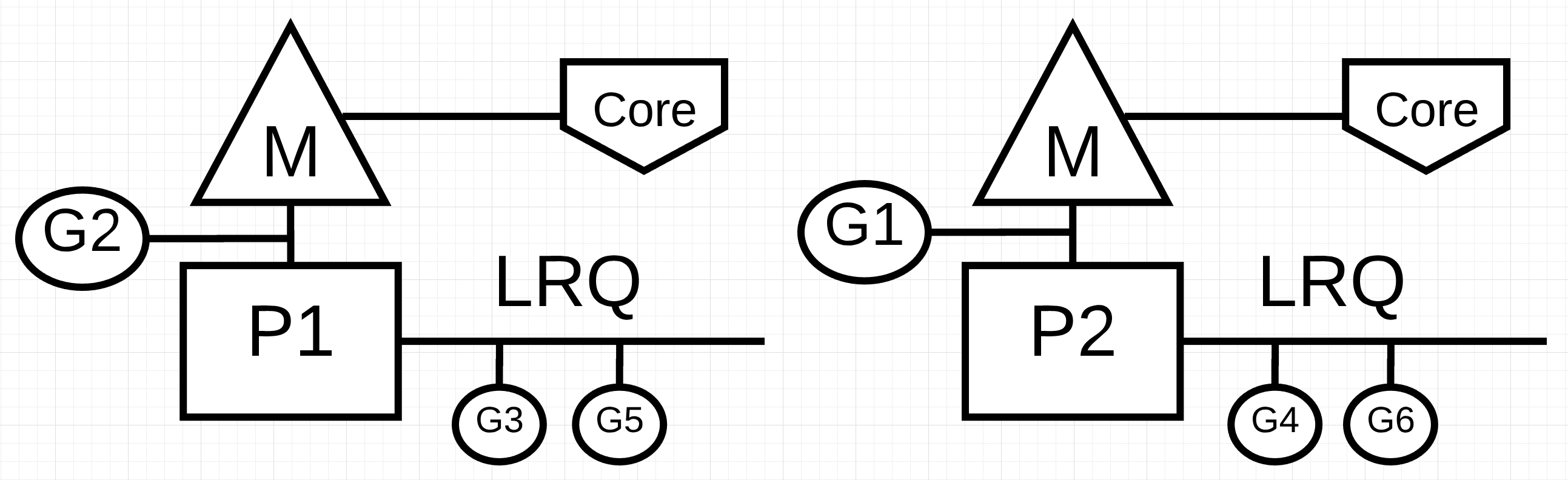
圖1
在圖1中, 你看到兩個邏輯處理器(P)運行在兩個不同的作業系統執行緒(M)上, 這兩個M對應著不同的硬體執行緒. 這種情況下, 兩個go程(G1和G2)處于并行狀態. 在每個邏輯處理器上, go程輪流分享作業系統執行緒. 所有的這些go程都并發地執行, 這些go程分享作業系統的運行時間, 以一種不確定的順序運行.
有一點需要注意的是, 有時候沒有并行執行的并發會降低程式的性能. 另外, 有時候程式并行執行, 但是并不會明顯提升你的程式的性能.
負載
我們如何知道并發是不是有意義呢? 理解你的問題的負載型別, 是一個好的入手點. 在考慮使用并發時, 你需要區分如下兩類負載:
(1) CPU密集型: 這類問題, 主要用來做計算, 不會讓go程經常在等待和運行狀態之間切換. 計算Pi的第Nth小數屬于這類負載.
(2) IO密集型. 這類負載需要go程經常在等待和運行狀態之間切換. 這類作業包括網路請求資源, 作業系統呼叫, 等待事件發生. 讀取檔案, 使用同步事件(mutexes, atomic)屬于這類負載.
對于CPU密集型負載, 你需要使用并行來提高性能. 一個單一的作業系統/硬體執行緒處理多個go程, 比處理單個go程性能更差, 因為要進行等待和運行狀態的切換. 所以, 在這種情況下, go程數超過作業系統/硬體執行緒數, 會降低性能, 而不是提高性能.
對于IO密集型負載, 你可以通過并發(可以不適用并行)來提高性能. 一個作業系統/硬體執行緒可以高效地處理很多個go程, 因為go調度器很擅長處理等待和運行狀態的切換. go程數超過作業系統/硬體執行緒數, 可以加快負載的執行, 因為這種情況下, 可以減少作業系統/硬體執行緒的空載時間.
我們如何知道每個硬體執行緒對應多少個go程比較合適? go程很少意味著更多的空載時間. 執行緒太多, 用于背景關系切換的時間就會花費很多.
下面, 我們看一些代碼, 學習在什么情況下, 可以利用并發, 什么時候可以利用并行.
加法運算(Adding Numbers)
我們不需要復雜的代碼來理解這種語境. 看下面這個將多個數字加在一起的函式.
36 func add(numbers []int) int {
37 var v int
38 for _, n := range numbers {
39 v += n
40 }
41 return v
42 }
問題: add函式是一個適合并發的負載嗎? 我相信是的. 這些整數可以拆分程更小的幾組整數, 然后每組整數并發計算. 當這些組整數都相加完成后, 然后將這些整數相加的結果進行相加, 就可以得到最終的結果.
然而, 現在有另外一個問題, 我們需要拆成多少個小的組, 然后讓他們并發執行, 從而提供最好的性能? 為了回答這個問題, 我們需要知道add的負載型別. add函式是CPU密集型的負載, 因為這個函式只進行數學運算, 而不會使go程進入等待狀態. 這種情況下, 每個go程對應一個作業系統/硬體執行緒是合理的.
Listing 2是我的add函式的并發版本.
Listing 2
44 func addConcurrent(goroutines int, numbers []int) int {
45 var v int64
46 totalNumbers := len(numbers)
47 lastGoroutine := goroutines - 1
48 stride := totalNumbers / goroutines
49
50 var wg sync.WaitGroup
51 wg.Add(goroutines)
52
53 for g := 0; g < goroutines; g++ {
54 go func(g int) {
55 start := g * stride
56 end := start + stride
57 if g == lastGoroutine {
58 end = totalNumbers
59 }
60
61 var lv int
62 for _, n := range numbers[start:end] {
63 lv += n
64 }
65
66 atomic.AddInt64(&v, int64(lv))
67 wg.Done()
68 }(g)
69 }
70
71 wg.Wait()
72
73 return int(v)
74 }
并發版本明顯比順序運行版本復雜, 那么增加的這個復雜性值得嗎? 最好地回答這個問題的方法是通過基準測驗(benchmark). 對于這些基準測驗, 我將垃圾收集器關閉, 然后將一千萬個數字相加. 下面測驗分別使用了順序版本的add函式, 和并發版本的addConcurrent函式.
Listing 3
func BenchmarkSequential(b *testing.B) {
for i := 0; i < b.N; i++ {
add(numbers)
}
}
func BenchmarkConcurrent(b *testing.B) {
for i := 0; i < b.N; i++ {
addConcurrent(runtime.NumCPU(), numbers)
}
}
Listing 4
10 Million Numbers using 8 goroutines with 1 core 2.9 GHz Intel 4 Core i7 Concurrency WITHOUT Parallelism ----------------------------------------------------------------------------- $ GOGC=off go test -cpu 1 -run none -bench . -benchtime 3s goos: darwin goarch: amd64 pkg: github.com/ardanlabs/gotraining/topics/go/testing/benchmarks/cpu-bound BenchmarkSequential 1000 5720764 ns/op : ~10% Faster BenchmarkConcurrent 1000 6387344 ns/op BenchmarkSequentialAgain 1000 5614666 ns/op : ~13% Faster BenchmarkConcurrentAgain 1000 6482612 ns/op
注意: 在本機運行基準測驗不是一件簡單的事. 有很多會導致基準測驗不準確的因素, 因此, 你需要確保你的機器盡可能的空閑, 并且多運行幾次測驗.
listing 4的基準測驗顯示, 當只有一個硬體執行緒時, 順序版本比并發版本快大約10%到13%. 因為并發版本有在同一個作業系統執行緒上的go程的背景關系切換, 這種情況是可以預料到的.
Listing 5
10 Million Numbers using 8 goroutines with 8 cores 2.9 GHz Intel 4 Core i7 Concurrency WITH Parallelism ----------------------------------------------------------------------------- $ GOGC=off go test -cpu 8 -run none -bench . -benchtime 3s goos: darwin goarch: amd64 pkg: github.com/ardanlabs/gotraining/topics/go/testing/benchmarks/cpu-bound BenchmarkSequential-8 1000 5910799 ns/op BenchmarkConcurrent-8 2000 3362643 ns/op : ~43% Faster BenchmarkSequentialAgain-8 1000 5933444 ns/op BenchmarkConcurrentAgain-8 2000 3477253 ns/op : ~41% Faster
在上面的基準測驗中, 并發版本快了大約41%到43%, 因為每個go程可以運行在不同的作業系統/硬體執行緒.
排序
理解不是所有的CPU密集型負載都適合并發是很重要的. 尤其是在將任務拆解, 以及任務聚合都很復雜的時候. 排序演算法中的冒泡排序就是其中的一個例子. 我們來看看go語言中實作的冒泡排序.
Listing 6
01 package main
02
03 import "fmt"
04
05 func bubbleSort(numbers []int) {
06 n := len(numbers)
07 for i := 0; i < n; i++ {
08 if !sweep(numbers, i) {
09 return
10 }
11 }
12 }
13
14 func sweep(numbers []int, currentPass int) bool {
15 var idx int
16 idxNext := idx + 1
17 n := len(numbers)
18 var swap bool
19
20 for idxNext < (n - currentPass) {
21 a := numbers[idx]
22 b := numbers[idxNext]
23 if a > b {
24 numbers[idx] = b
25 numbers[idxNext] = a
26 swap = true
27 }
28 idx++
29 idxNext = idx + 1
30 }
31 return swap
32 }
33
34 func main() {
35 org := []int{1, 3, 2, 4, 8, 6, 7, 2, 3, 0}
36 fmt.Println(org)
37
38 bubbleSort(org)
39 fmt.Println(org)
40 }
問題: bubbleSort函式適合改成并發執行嗎? 我相信不合適. 這些整數可以拆分成小的佇列, 然后這些佇列并發排序. 然而, 這些小的已排序的佇列, 沒有好的辦法, 將它們排序在一起. 下面是冒泡排序的并發版本.
Listing 8
01 func bubbleSortConcurrent(goroutines int, numbers []int) {
02 totalNumbers := len(numbers)
03 lastGoroutine := goroutines - 1
04 stride := totalNumbers / goroutines
05
06 var wg sync.WaitGroup
07 wg.Add(goroutines)
08
09 for g := 0; g < goroutines; g++ {
10 go func(g int) {
11 start := g * stride
12 end := start + stride
13 if g == lastGoroutine {
14 end = totalNumbers
15 }
16
17 bubbleSort(numbers[start:end])
18 wg.Done()
19 }(g)
20 }
21
22 wg.Wait()
23
24 // Ugh, we have to sort the entire list again.
25 bubbleSort(numbers)
26 }
在Listing 8中, bubbleSortConcurrent函式作為bubbleSort函式的并發版本.
Listing 9
Before: 25 51 15 57 87 10 10 85 90 32 98 53 91 82 84 97 67 37 71 94 26 2 81 79 66 70 93 86 19 81 52 75 85 10 87 49 After: 10 10 15 25 32 51 53 57 85 87 90 98 2 26 37 67 71 79 81 82 84 91 94 97 10 19 49 52 66 70 75 81 85 86 87 93
bubbleSortConcurrent的25行呼叫了bubbleSort, 這里抵消了并發可能實作的提升. 對于冒泡排序, 并發不能實作性能提升.
讀檔案
舉了兩個CPU密集型負載的例子, 下面, 我們看一下IO密集型負載的例子. 我們看一下讀取檔案, 然后進行文本搜索的例子.
順序操作版本的函式名叫做find.
Listing 10
42 func find(topic string, docs []string) int {
43 var found int
44 for _, doc := range docs {
45 items, err := read(doc)
46 if err != nil {
47 continue
48 }
49 for _, item := range items {
50 if strings.Contains(item.Description, topic) {
51 found++
52 }
53 }
54 }
55 return found
56 }
下面是find函式中呼叫的read函式的實作:
Listing 11
33 func read(doc string) ([]item, error) {
34 time.Sleep(time.Millisecond) // Simulate blocking disk read.
35 var d document
36 if err := xml.Unmarshal([]byte(file), &d); err != nil {
37 return nil, err
38 }
39 return d.Channel.Items, nil
40 }
Listing 11中的read函式, 以一個time.Sleep函式開始, 這個呼叫用來模擬實際系統呼叫從硬碟中讀取檔案的延遲. 相同的延遲對于精確測驗find函式與它的并發版本的性能很重要.
下面我們看看并發版本:
Listing 12
58 func findConcurrent(goroutines int, topic string, docs []string) int {
59 var found int64
60
61 ch := make(chan string, len(docs))
62 for _, doc := range docs {
63 ch <- doc
64 }
65 close(ch)
66
67 var wg sync.WaitGroup
68 wg.Add(goroutines)
69
70 for g := 0; g < goroutines; g++ {
71 go func() {
72 var lFound int64
73 for doc := range ch {
74 items, err := read(doc)
75 if err != nil {
76 continue
77 }
78 for _, item := range items {
79 if strings.Contains(item.Description, topic) {
80 lFound++
81 }
82 }
83 }
84 atomic.AddInt64(&found, lFound)
85 wg.Done()
86 }()
87 }
88
89 wg.Wait()
90
91 return int(found)
92 }
并發版本明顯比順序執行版本復雜, 那么這樣做值得嗎? 最好的方法還是通過基準測驗. 在測驗中, 我們同樣將垃圾回收關閉.
Listing 13
func BenchmarkSequential(b *testing.B) {
for i := 0; i < b.N; i++ {
find("test", docs)
}
}
func BenchmarkConcurrent(b *testing.B) {
for i := 0; i < b.N; i++ {
findConcurrent(runtime.NumCPU(), "test", docs)
}
}
Listing 14
10 Thousand Documents using 8 goroutines with 1 core 2.9 GHz Intel 4 Core i7 Concurrency WITHOUT Parallelism ----------------------------------------------------------------------------- $ GOGC=off go test -cpu 1 -run none -bench . -benchtime 3s goos: darwin goarch: amd64 pkg: github.com/ardanlabs/gotraining/topics/go/testing/benchmarks/io-bound BenchmarkSequential 3 1483458120 ns/op BenchmarkConcurrent 20 188941855 ns/op : ~87% Faster BenchmarkSequentialAgain 2 1502682536 ns/op BenchmarkConcurrentAgain 20 184037843 ns/op : ~88% Faster
listing 14的基準測驗顯示, 當所有go程共用一個作業系統/硬體執行緒時, 并發版本大約快了87%到88%. 這種情況是可以預料到的, 因為所有的go程可以很好的共享一個作業系統/硬體執行緒.
下面測驗使用并行性.
Listing 15
10 Thousand Documents using 8 goroutines with 1 core 2.9 GHz Intel 4 Core i7 Concurrency WITH Parallelism ----------------------------------------------------------------------------- $ GOGC=off go test -run none -bench . -benchtime 3s goos: darwin goarch: amd64 pkg: github.com/ardanlabs/gotraining/topics/go/testing/benchmarks/io-bound BenchmarkSequential-8 3 1490947198 ns/op BenchmarkConcurrent-8 20 187382200 ns/op : ~88% Faster BenchmarkSequentialAgain-8 3 1416126029 ns/op BenchmarkConcurrentAgain-8 20 185965460 ns/op : ~87% Faster
listing 15中的基準測驗顯示, 額外的作業系統/硬體執行緒并不能提升性能.
結論
這篇博客的目的是告訴你如何決定負載是否適合使用并發. 其中IO密集型一般適合使用并發, 而CPU密集型需要使用并行. 有些任務型別(演算法), 可能使用并發和并行都不能提高性能.
原文參考: https://www.ardanlabs.com/blog/2018/12/scheduling-in-go-part3.html
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/250020.html
標籤:Go
上一篇:編程的相關概念
下一篇:Go基礎及語法(一)