資料挖掘常用分析方法:
最近團隊需要招資料挖掘工程師,但公司之前沒有相關的崗位,領導讓我臨時充當面試官對應聘者進行技術考核,為了做好這事情,我花了點時間了解了一下資料挖掘的知識,并整理了這份資料,
資料挖掘的分析方法可以劃分為關聯分析、序列模式分析、分類分析和聚類分析四種,
關聯分析:
關聯分析是一種簡單、實用的分析技術,就是發現存在于大量資料集中的關聯性或相關性,從而描述了一個事物中某些屬性同時出現的規律和模式,
關聯分析是從大量資料中發現項集之間有趣的關聯和相關聯系,
關聯分析的一個典型例子是購物籃分析,該程序通過發現顧客放入其購物籃中的不同商品之間的聯系,分析顧客的購買習慣,通過了解哪些商品頻繁地被顧客同時購買,這種關聯的發現可以幫助零售商制定營銷策略,其他的應用還包括價目表設計、商品促銷、商品的排放和基于購買模式的顧客劃分,
可從資料庫中關聯分析出形如“由于某些事件的發生而引起另外一些事件的發生”之類的規則,如“67%的顧客在購買啤酒的同時也會購買尿布”,因此通過合理的啤酒和尿布的貨架擺放或捆綁銷售可提高超市的服務質量和效益,又如“‘C語言’課程優秀的同學,在學習‘資料結構’時為優秀的可能性達88%”,那么就可以通過強化“C語言”的學習來提高教學效果,
關聯分析->相關性分析->回歸分析
關聯分析常用演算法有:
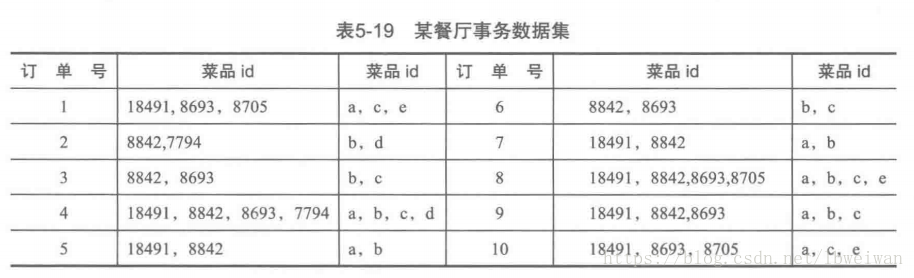
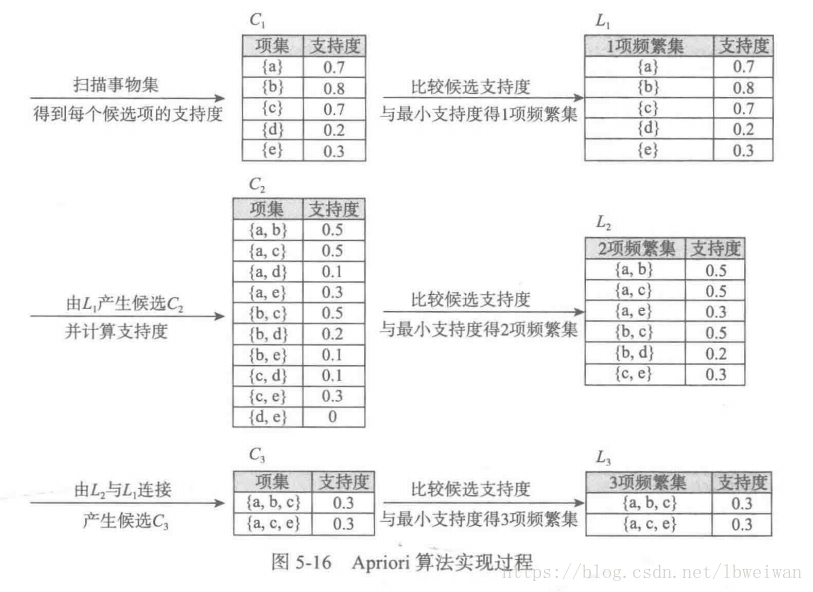
簡單介紹Apriori演算法
Apriori演算法常用的用于挖掘出資料關聯規則的演算法,它用來找出資料值中頻繁出現的資料集合,
通過找出的資料集合,可以對人類商業決策進行指導,典型應用例子:超市購物的啤酒與尿布銷售關系,
Apriori演算法基本思想是對各種數值進行組合,計算其共同出現概率,但其中增加了迭代,截枝思想,大大減少組合計算次數,在海量資料的情況下依然可以保證足夠高的計算效率,
序列模式:
所謂序列模式,我的定義是:在一組有序的資料列組成的資料集中,經常出現的那些序列組合構成的模式,跟我們所熟知的關聯規則挖掘不一樣,序列模式挖掘的物件以及結果都是有序的,即資料集中的每個序列的條目在時間或空間上是有序排列的,輸出的結果也是有序的,
舉個簡單的例子來說明,關聯規則一個經典的應用是計算超市購物中被共同購買的商品,它把每個顧客的一次交易視作一個transaction,計算在不同transaction中不同item組合的規律性,而如果我們考慮一個用戶多次在超市購物的情況,那么這些不同時間點的交易記錄就構成了一個購買序列,N個用戶的購買序列就組成一個規模為N的序列資料集,考慮這些時間上的因素之后,我們就能得到一些比關聯規則更有價值的規律,比如關聯挖掘經常能挖掘出如啤酒和尿布的搭配規律,而序列模式挖掘則能挖掘出諸如《育兒指南》->嬰兒車這樣帶有一定因果性質的規律,所以,序列模式挖掘比關聯挖掘能得到更深刻的知識,
序列模式挖掘常用演算法有:
GSP演算法,SPADE演算法,PrefixSpan演算法,Clospan演算法等
分類分析:
分類是基于包含其類別成員資格已知的觀察(或實體)的訓練資料集來識別新觀察所屬的一組類別(子群體)中的哪一個的問題,例如,將給定的電子郵件分配給“垃圾郵件”或“非垃圾郵件”類,并根據觀察到的患者特征(性別,血壓,某些癥狀的存在或不存在等)為給定患者分配診斷,分類分析,簡單地說就是把資料分成不同類別,
分類分析常用演算法:
決策樹,神經網路,貝葉斯分類,k最近鄰分類(即KNN,見后面例外資料挖掘)
聚類分析:
聚類是將資料分類到不同的類或者簇這樣的一個程序,所以同一個簇中的物件有很大的相似性,而不同簇間的物件有很大的相異性,
聚類分析是一種探索性的分析,在分類的程序中,人們不必事先給出一個分類的標準,聚類分析能夠從樣本資料出發,自動進行分類,聚類分析所使用方法的不同,常常會得到不同的結論,不同研究者對于同一組資料進行聚類分析,所得到的聚類數未必一致,
聚類分析跟分類分析區別是分類分析需要有已有標簽的資料,而聚類分析則不需要,
聚類分析常用演算法:
從統計學的觀點看,聚類分析是通過資料建模簡化資料的一種方法,傳統的統計聚類分析方法包括系統聚類法、分解法、加入法、動態聚類法、有序樣品聚類、有重疊聚類和模糊聚類等,采用隨機林林,k-均值、k-中心點等演算法的聚類分析工具已被加入到許多著名的統計分析軟體包中,如SPSS、SAS等,
簡單介紹k-means(k均值):

例外資料:
例外資料挖掘是資料挖掘中一種常用的場景,例外資料一般是指在總體樣本中占比較小的資料,
根據應用場景不同也稱錯誤資料,特殊資料,重要資料,高價值資料等,
例外資料挖掘常用方法有:
基于規則
規則有特定場景的業務規則:
例如某個欄位取值必須為0
冬天氣溫肯定不能高于40度
也有通用的自然規則:
例如本福德定律(自然生成的數字首位為1的概率為30.10%,2的概率為17.61%,依次遞減,首位為9的概率僅為4.58%,),
基于統計方法
簡單統計規則:觀察其方差、標準差、均值等是否和常規值有所差異
正態分布規則:找出資料集里面不符合正態分布的資料
離群點檢測演算法
1 KNN
人們常說“想知道自己是什么人,看看與自己關系最親密的十個人是什么人就知道”,意思是人總是會跟相似的人交朋友,
那反過來,要將某個人歸類,則看他跟什么人接觸比較多,則將全歸到那一類里面,
knn演算法是基于這個原理的分類演算法,預測一個新的值x的時候,根據它距離最近的K個點是什么類別來判斷x屬于哪個類別,
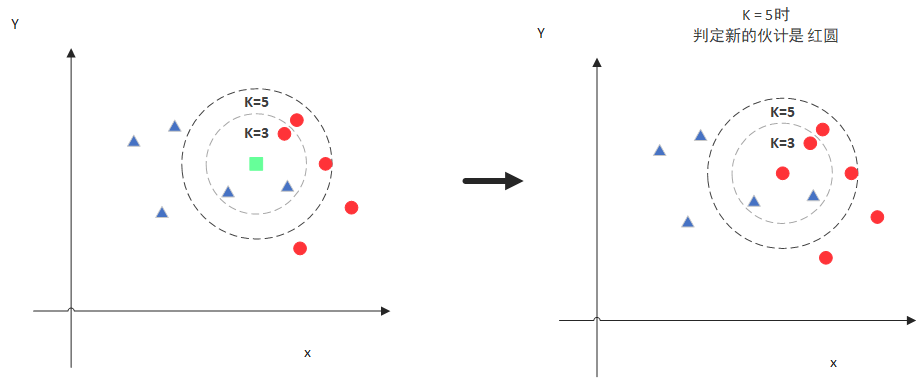
圖中綠色的點就是我們要預測的那個點,假設K=3,那么KNN演算法就會找到與它距離最近的三個點,看看哪種類別多一些,比如這個例子中是藍色三角形多一些,新來的綠色點就歸類到藍三角了,
假設K=5,那么KNN演算法就會找到與它距離最近的五個點(這里用圓圈把它圈起來了),看看哪種類別多一些,比如這個例子中是紅色多一些,新來的綠色點就歸類到紅色球了,
此類演算法需要有現成的例外資料樣本,屬于有監督機器學習,演算法主要難點在于怎么定義資料距離還有k值取值(太小和太大的k值都會造成比較大的誤差)
2 孤立森林
森林里面的樹木一般是連成一片的,如果某一棵樹跟其它樹木不在一塊,那這棵樹一般有問題,
如何找出這樣樹呢?資料量少時可以通過可視化展示, 由人工判斷,但資料量多時就比較麻煩,
孤立森林演算法原理,就是逐次添加隨機線段將森林劃分片,直到每一片里面只有一棵樹,孤立的樹總是會在比較早的時候就分到獨立的區域,
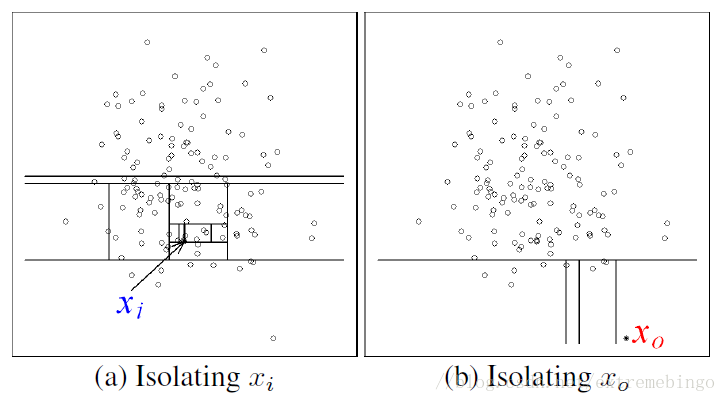
例如x0這個點,只需要四次劃分就被分到獨立區域,xi這個點需要11次劃分才能分到獨立區域,(這張圖只演示了一次劃分程序,如果重復多次劃分,每次劃分的方法都是隨機的,但x0都是比較早被分出來,則可以認為x0肯定是差異點)
孤立森林是比較實用的例外資料挖掘演算法,不需要現成的例外資料樣本,
3 LOF
暫時沒看懂原理
可視化分析
將資料進行建模形成不同維度資料,并對不同維度數值做標準化,降維到一維或者二維資料以方便通過散點圖,折線圖,箱線圖,熱力圖等把資料可視化展示,供分析人員直觀識別,
例如將人群年齡段,體重,性別,體育成績等做加權累計,得出一個單一維度的資料,使用箱線圖進行展示,
人工智能分析
這種相對來說比較適合沒有專家參與的例外資料分析,利用深度學習演算法,只需要前期匯入足夠多的有標記資料,經過多輪訓練,得出一個合適的模型,
但缺點是結果無法預期(目前人類很難搞清楚人工智能的思維),而且需要比較長時間的訓練,
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/250046.html
標籤:R
下一篇:編程的相關概念