Spark3.0已經發布半年之久,這次大版本的升級主要是集中在性能優化和檔案豐富上,其中46%的優化都集中在Spark SQL上,SQL優化里最引人注意的非Adaptive Query Execution莫屬了,
Adaptive Query Execution(AQE)是英特爾大資料技術團隊和百度大資料基礎架構部工程師在Spark 社區版本的基礎上,改進并實作的自適應執行引擎,近些年來,Spark SQL 一直在針對CBO 特性進行優化,而且做得十分成功,
CBO基本原理
首先,我們先來介紹另一個基于規則優化(Rule-Based Optimization,簡稱RBO)的優化器,這是一種經驗式、啟發式的優化思路,優化規則都已經預先定義好,只需要將SQL往這些規則上套就可以,簡單的說,RBO就像是一個經驗豐富的老司機,基本套路全都知道,
然而世界上有一種東西叫做 – 不按套路來,與其說它不按套路來,倒不如說它本身并沒有什么套路,最典型的莫過于復雜Join算子優化,對于這些Join來說,通常有兩個選擇題要做:
-
Join應該選擇哪種演算法策略來執行?BroadcastJoin or ShuffleHashJoin or SortMergeJoin?不同的執行策略對系統的資源要求不同,執行效率也有天壤之別,同一個SQL,選擇到合適的策略執行可能只需要幾秒鐘,而如果沒有選擇到合適的執行策略就可能會導致系統OOM,
-
對于雪花模型或者星型模型來講,多表Join應該選擇什么樣的順序執行?不同的Join順序意味著不同的執行效率,比如A join B join C,A、B表都很大,C表很小,那A join B很顯然需要大量的系統資源來運算,執行時間必然不會短,而如果使用A join C join B的執行順序,因為C表很小,所以A join C會很快得到結果,而且結果集會很小,再使用小的結果集 join B,性能顯而易見會好于前一種方案,
大家想想,這有什么固定的優化規則么?并沒有,說白了,你需要知道更多關于表的基礎資訊(表大小、表記錄總條數等),再通過一定規則代價評估才能從中選擇一條最優的執行計劃,所以,CBO 意為基于代價優化策略,它需要計算所有可能執行計劃的代價,并挑選出代價最小的執行計劃,
AQE對于整體的Spark SQL的執行程序做了相應的調整和優化,它最大的亮點是可以根據已經完成的計劃結點真實且精確的執行統計結果來不停的反饋并重新優化剩下的執行計劃,
CBO這么難實作,Spark怎么解決?
CBO 會計算一些和業務資料相關的統計資料,來優化查詢,例如行數、去重后的行數、空值、最大最小值等,Spark會根據這些資料,自動選擇BHJ或者SMJ,對于多Join場景下的Cost-based Join Reorder,來達到優化執行計劃的目的,
但是,由于這些統計資料是需要預先處理的,會過時,所以我們在用過時的資料進行判斷,在某些情況下反而會變成負面效果,拉低了SQL執行效率,
Spark3.0的AQE框架用了三招解決這個問題:
- 動態合并shuffle磁區(Dynamically coalescing shuffle partitions)
- 動態調整Join策略(Dynamically switching join strategies)
- 動態優化資料傾斜Join(Dynamically optimizing skew joins)
下面我們來詳細介紹這三個特性,
動態合并 shuffle 的磁區
在我們處理的資料量級非常大時,shuffle通常來說是最影響性能的,因為shuffle是一個非常耗時的算子,它需要通過網路移動資料,分發給下游算子,
在shuffle中,partition的數量十分關鍵,partition的最佳數量取決于資料,而資料大小在不同的query不同stage都會有很大的差異,所以很難去確定一個具體的數目:
- 如果partition過少,每個partition資料量就會過多,可能就會導致大量資料要落到磁盤上,從而拖慢了查詢,
- 如果partition過多,每個partition資料量就會很少,就會產生很多額外的網路開銷,并且影響Spark task scheduler,從而拖慢查詢,
為了解決該問題,我們在最開始設定相對較大的shuffle partition個數,通過執行程序中shuffle檔案的資料來合并相鄰的小partitions,
例如,假設我們執行SELECT max(i) FROM tbl GROUP BY j,表tbl只有2個partition并且資料量非常小,我們將初始shuffle partition設為5,因此在分組后會出現5個partitions,若不進行AQE優化,會產生5個tasks來做聚合結果,事實上有3個partitions資料量是非常小的,
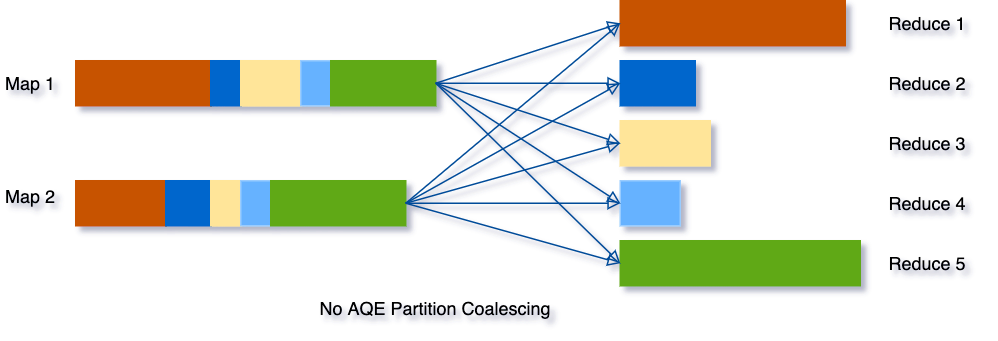
然而在這種情況下,AQE只會生成3個reduce task,

動態切換join策略
Spark 支持許多 Join 策略,其中 broadcast hash join 通常是性能最好的,前提是參加 join 的一張表的資料能夠裝入記憶體,由于這個原因,當 Spark 估計參加 join 的表資料量小于廣播大小的閾值時,其會將 Join 策略調整為 broadcast hash join,但是,很多情況都可能導致這種大小估計出錯——例如存在一個非常有選擇性的過濾器,
由于AQE擁有精確的上游統計資料,因此可以解決該問題,比如下面這個例子,右表的實際大小為15M,而在該場景下,經過filter過濾后,實際參與join的資料大小為8M,小于了默認broadcast閾值10M,應該被廣播,
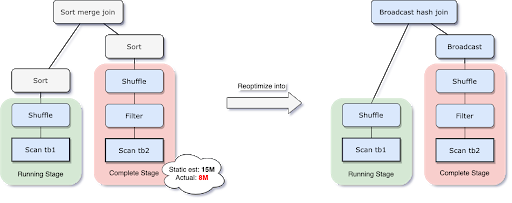
在我們執行程序中轉化為BHJ的同時,我們甚至可以將傳統shuffle優化為本地shuffle(例如shuffle讀在mapper而不是基于reducer)來減小網路開銷,
動態優化資料傾斜
Join里如果出現某個key的資料傾斜問題,那么基本上就是這個任務的性能殺手了,在AQE之前,用戶沒法自動處理Join中遇到的這個棘手問題,需要借助外部手動收集資料統計資訊,并欄位外的加鹽,分批處理資料等相對繁瑣的方法來應對資料傾斜問題,
資料傾斜本質上是由于集群上資料在磁區之間分布不均勻所導致的,它會拉慢join場景下整個查詢,AQE根據shuffle檔案統計資料自動檢測傾斜資料,將那些傾斜的磁區打散成小的子磁區,然后各自進行join,
我們可以看下這個場景,Table A join Table B,其中Table A的partition A0資料遠大于其他磁區,
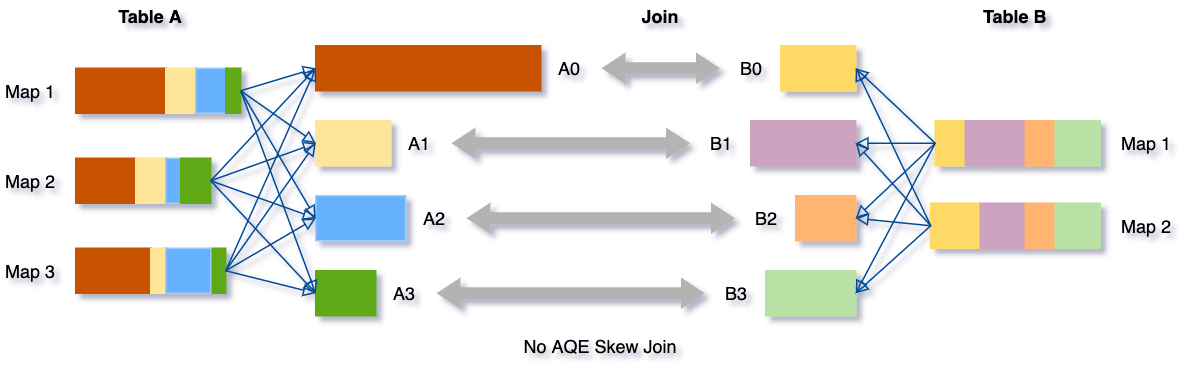
AQE會將partition A0切分成2個子磁區,并且讓他們獨自和Table B的partition B0進行join,
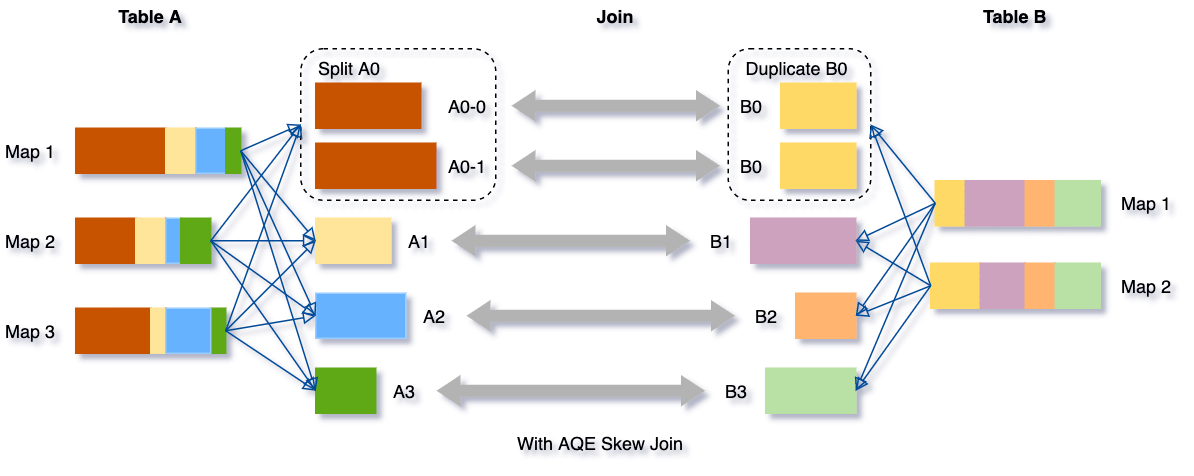
如果不做這個優化,SMJ將會產生4個tasks并且其中一個執行時間遠大于其他,經優化,這個join將會有5個tasks,但每個task執行耗時差不多相同,因此個整個查詢帶來了更好的性能,
如何開啟AQE
我們可以設定引數spark.sql.adaptive.enabled為true來開啟AQE,在Spark 3.0中默認是false,并滿足以下條件:
- 非流式查詢
- 包含至少一個exchange(如join、聚合、視窗算子)或者一個子查詢
AQE通過減少了對靜態統計資料的依賴,成功解決了Spark CBO的一個難以處理的trade off(生成統計資料的開銷和查詢耗時)以及資料精度問題,相比之前具有局限性的CBO,現在就顯得非常靈活,
Spark CBO原始碼實作
Adaptive Execution 模式是在使用Spark物理執行計劃注入生成的,在QueryExecution類中有 preparations 一組優化器來對物理執行計劃進行優化, InsertAdaptiveSparkPlan 就是第一個優化器,
InsertAdaptiveSparkPlan 使用 PlanAdaptiveSubqueries Rule對部分SubQuery處理后,將當前 Plan 包裝成 AdaptiveSparkPlanExec ,
當執行 AdaptiveSparkPlanExec 的 collect() 或 take() 方法時,全部會先執行 getFinalPhysicalPlan() 方法生成新的SparkPlan,再執行對應的SparkPlan對應的方法,
// QueryExecution類
lazy val executedPlan: SparkPlan = {
executePhase(QueryPlanningTracker.PLANNING) {
QueryExecution.prepareForExecution(preparations, sparkPlan.clone())
}
}
protected def preparations: Seq[Rule[SparkPlan]] = {
QueryExecution.preparations(sparkSession,
Option(InsertAdaptiveSparkPlan(AdaptiveExecutionContext(sparkSession, this))))
}
private[execution] def preparations(
sparkSession: SparkSession,
adaptiveExecutionRule: Option[InsertAdaptiveSparkPlan] = None): Seq[Rule[SparkPlan]] = {
// `AdaptiveSparkPlanExec` is a leaf node. If inserted, all the following rules will be no-op
// as the original plan is hidden behind `AdaptiveSparkPlanExec`.
adaptiveExecutionRule.toSeq ++
Seq(
PlanDynamicPruningFilters(sparkSession),
PlanSubqueries(sparkSession),
EnsureRequirements(sparkSession.sessionState.conf),
ApplyColumnarRulesAndInsertTransitions(sparkSession.sessionState.conf,
sparkSession.sessionState.columnarRules),
CollapseCodegenStages(sparkSession.sessionState.conf),
ReuseExchange(sparkSession.sessionState.conf),
ReuseSubquery(sparkSession.sessionState.conf)
)
}
// InsertAdaptiveSparkPlan
override def apply(plan: SparkPlan): SparkPlan = applyInternal(plan, false)
private def applyInternal(plan: SparkPlan, isSubquery: Boolean): SparkPlan = plan match {
// ...some checking
case _ if shouldApplyAQE(plan, isSubquery) =>
if (supportAdaptive(plan)) {
try {
// Plan sub-queries recursively and pass in the shared stage cache for exchange reuse.
// Fall back to non-AQE mode if AQE is not supported in any of the sub-queries.
val subqueryMap = buildSubqueryMap(plan)
val planSubqueriesRule = PlanAdaptiveSubqueries(subqueryMap)
val preprocessingRules = Seq(
planSubqueriesRule)
// Run pre-processing rules.
val newPlan = AdaptiveSparkPlanExec.applyPhysicalRules(plan, preprocessingRules)
logDebug(s"Adaptive execution enabled for plan: $plan")
AdaptiveSparkPlanExec(newPlan, adaptiveExecutionContext, preprocessingRules, isSubquery)
} catch {
case SubqueryAdaptiveNotSupportedException(subquery) =>
logWarning(s"${SQLConf.ADAPTIVE_EXECUTION_ENABLED.key} is enabled " +
s"but is not supported for sub-query: $subquery.")
plan
}
} else {
logWarning(s"${SQLConf.ADAPTIVE_EXECUTION_ENABLED.key} is enabled " +
s"but is not supported for query: $plan.")
plan
}
case _ => plan
}
AQE對Stage 分階段提交執行和優化程序如下:
private def getFinalPhysicalPlan(): SparkPlan = lock.synchronized {
// 第一次呼叫 getFinalPhysicalPlan方法時為false,等待該方法執行完畢,全部Stage不會再改變,直接回傳最終plan
if (isFinalPlan) return currentPhysicalPlan
// In case of this adaptive plan being executed out of `withActive` scoped functions, e.g.,
// `plan.queryExecution.rdd`, we need to set active session here as new plan nodes can be
// created in the middle of the execution.
context.session.withActive {
val executionId = getExecutionId
var currentLogicalPlan = currentPhysicalPlan.logicalLink.get
var result = createQueryStages(currentPhysicalPlan)
val events = new LinkedBlockingQueue[StageMaterializationEvent]()
val errors = new mutable.ArrayBuffer[Throwable]()
var stagesToReplace = Seq.empty[QueryStageExec]
while (!result.allChildStagesMaterialized) {
currentPhysicalPlan = result.newPlan
// 接下來有哪些Stage要執行,參考 createQueryStages(plan: SparkPlan) 方法
if (result.newStages.nonEmpty) {
stagesToReplace = result.newStages ++ stagesToReplace
// onUpdatePlan 通過listener更新UI
executionId.foreach(onUpdatePlan(_, result.newStages.map(_.plan)))
// Start materialization of all new stages and fail fast if any stages failed eagerly
result.newStages.foreach { stage =>
try {
// materialize() 方法對Stage的作為一個單獨的Job提交執行,并回傳 SimpleFutureAction 來接收執行結果
// QueryStageExec: materialize() -> doMaterialize() ->
// ShuffleExchangeExec: -> mapOutputStatisticsFuture -> ShuffleExchangeExec
// SparkContext: -> submitMapStage(shuffleDependency)
stage.materialize().onComplete { res =>
if (res.isSuccess) {
events.offer(StageSuccess(stage, res.get))
} else {
events.offer(StageFailure(stage, res.failed.get))
}
}(AdaptiveSparkPlanExec.executionContext)
} catch {
case e: Throwable =>
cleanUpAndThrowException(Seq(e), Some(stage.id))
}
}
}
// Wait on the next completed stage, which indicates new stats are available and probably
// new stages can be created. There might be other stages that finish at around the same
// time, so we process those stages too in order to reduce re-planning.
// 等待,直到有Stage執行完畢
val nextMsg = events.take()
val rem = new util.ArrayList[StageMaterializationEvent]()
events.drainTo(rem)
(Seq(nextMsg) ++ rem.asScala).foreach {
case StageSuccess(stage, res) =>
stage.resultOption = Some(res)
case StageFailure(stage, ex) =>
errors.append(ex)
}
// In case of errors, we cancel all running stages and throw exception.
if (errors.nonEmpty) {
cleanUpAndThrowException(errors, None)
}
// Try re-optimizing and re-planning. Adopt the new plan if its cost is equal to or less
// than that of the current plan; otherwise keep the current physical plan together with
// the current logical plan since the physical plan's logical links point to the logical
// plan it has originated from.
// Meanwhile, we keep a list of the query stages that have been created since last plan
// update, which stands for the "semantic gap" between the current logical and physical
// plans. And each time before re-planning, we replace the corresponding nodes in the
// current logical plan with logical query stages to make it semantically in sync with
// the current physical plan. Once a new plan is adopted and both logical and physical
// plans are updated, we can clear the query stage list because at this point the two plans
// are semantically and physically in sync again.
// 對前面的Stage替換為 LogicalQueryStage 節點
val logicalPlan = replaceWithQueryStagesInLogicalPlan(currentLogicalPlan, stagesToReplace)
// 再次呼叫optimizer 和planner 進行優化
val (newPhysicalPlan, newLogicalPlan) = reOptimize(logicalPlan)
val origCost = costEvaluator.evaluateCost(currentPhysicalPlan)
val newCost = costEvaluator.evaluateCost(newPhysicalPlan)
if (newCost < origCost ||
(newCost == origCost && currentPhysicalPlan != newPhysicalPlan)) {
logOnLevel(s"Plan changed from $currentPhysicalPlan to $newPhysicalPlan")
cleanUpTempTags(newPhysicalPlan)
currentPhysicalPlan = newPhysicalPlan
currentLogicalPlan = newLogicalPlan
stagesToReplace = Seq.empty[QueryStageExec]
}
// Now that some stages have finished, we can try creating new stages.
// 進入下一輪回圈,如果存在Stage執行完畢, 對應的resultOption 會有值,對應的allChildStagesMaterialized 屬性 = true
result = createQueryStages(currentPhysicalPlan)
}
// Run the final plan when there's no more unfinished stages.
// 所有前置stage全部執行完畢,根據stats資訊優化物理執行計劃,確定最終的 physical plan
currentPhysicalPlan = applyPhysicalRules(result.newPlan, queryStageOptimizerRules)
isFinalPlan = true
executionId.foreach(onUpdatePlan(_, Seq(currentPhysicalPlan)))
currentPhysicalPlan
}
}
// SparkContext
/**
* Submit a map stage for execution. This is currently an internal API only, but might be
* promoted to DeveloperApi in the future.
*/
private[spark] def submitMapStage[K, V, C](dependency: ShuffleDependency[K, V, C])
: SimpleFutureAction[MapOutputStatistics] = {
assertNotStopped()
val callSite = getCallSite()
var result: MapOutputStatistics = null
val waiter = dagScheduler.submitMapStage(
dependency,
(r: MapOutputStatistics) => { result = r },
callSite,
localProperties.get)
new SimpleFutureAction[MapOutputStatistics](waiter, result)
}
// DAGScheduler
def submitMapStage[K, V, C](
dependency: ShuffleDependency[K, V, C],
callback: MapOutputStatistics => Unit,
callSite: CallSite,
properties: Properties): JobWaiter[MapOutputStatistics] = {
val rdd = dependency.rdd
val jobId = nextJobId.getAndIncrement()
if (rdd.partitions.length == 0) {
throw new SparkException("Can't run submitMapStage on RDD with 0 partitions")
}
// We create a JobWaiter with only one "task", which will be marked as complete when the whole
// map stage has completed, and will be passed the MapOutputStatistics for that stage.
// This makes it easier to avoid race conditions between the user code and the map output
// tracker that might result if we told the user the stage had finished, but then they queries
// the map output tracker and some node failures had caused the output statistics to be lost.
val waiter = new JobWaiter[MapOutputStatistics](
this, jobId, 1,
(_: Int, r: MapOutputStatistics) => callback(r))
eventProcessLoop.post(MapStageSubmitted(
jobId, dependency, callSite, waiter, Utils.cloneProperties(properties)))
waiter
}
當前,AdaptiveSparkPlanExec 中對物理執行的優化器串列如下:
// AdaptiveSparkPlanExec
@transient private val queryStageOptimizerRules: Seq[Rule[SparkPlan]] = Seq(
ReuseAdaptiveSubquery(conf, context.subqueryCache),
CoalesceShufflePartitions(context.session),
// The following two rules need to make use of 'CustomShuffleReaderExec.partitionSpecs'
// added by `CoalesceShufflePartitions`. So they must be executed after it.
OptimizeSkewedJoin(conf),
OptimizeLocalShuffleReader(conf),
ApplyColumnarRulesAndInsertTransitions(conf, context.session.sessionState.columnarRules),
CollapseCodegenStages(conf)
)
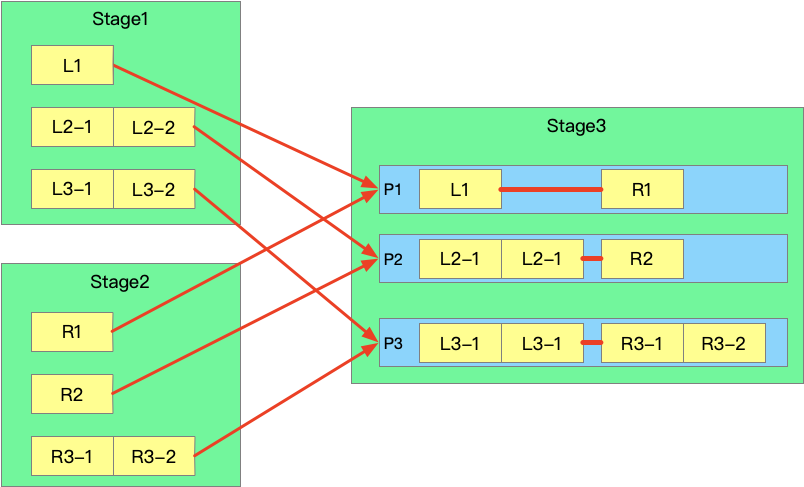
其中 OptimizeSkewedJoin方法就是針對最容易出現資料傾斜的Join進行的優化:
AQE模式下,每個Stage執行之前,前置依賴Stage已經全部執行完畢,那么就可以獲取到每個Stage的stats資訊,
當發現shuffle partition的輸出超過partition size的中位數的5倍,且partition的輸出大于 256M 會被判斷產生資料傾斜, 將partition 資料按照targetSize進行切分為N份,
targetSize = max(64M, 非資料傾斜partition的平均大小),
優化前 shuffle 如下:
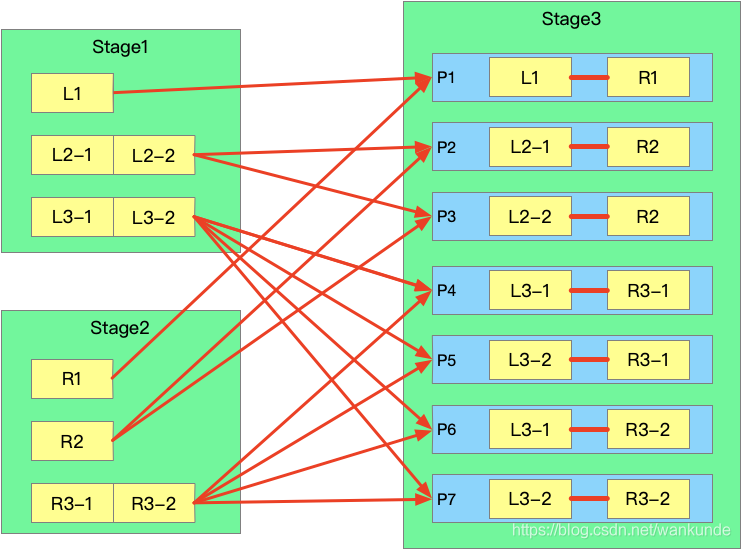
優化后 shuffle:
Spark3.0AQE在FreeWheel的應用與實踐
FreeWheel團隊通過高效的敏捷開發趕在 2020 年圣誕廣告季之前在生產環境順利發布上線,整體性能提升高達 40%(對于大 batch)的資料,AWS Cost 平均節省 25%~30%之間,大約每年至少能為公司節省百萬成本,
主要升級改動
打開 Spark 3.0 AQE 的新特性,主要配置如下:
"spark.sql.adaptive.enabled": true,
"spark.sql.adaptive.coalescePartitions.enabled": true,
"spark.sql.adaptive.coalescePartitions.minPartitionNum": 1,
"spark.sql.adaptive.advisoryPartitionSizeInBytes": "128MB"
需要注意的是,AQE 特性只是在 reducer 階段不用指定 reducer 的個數,但并不代表你不再需要指定任務的并行度了,因為 map 階段仍然需要將資料劃分為合適的磁區進行處理,如果沒有指定并行度會使用默認的 200,當資料量過大時,很容易出現 OOM,建議還是按照任務之前的并行度設定來配置引數spark.sql.shuffle.partitions和spark.default.parallelism,
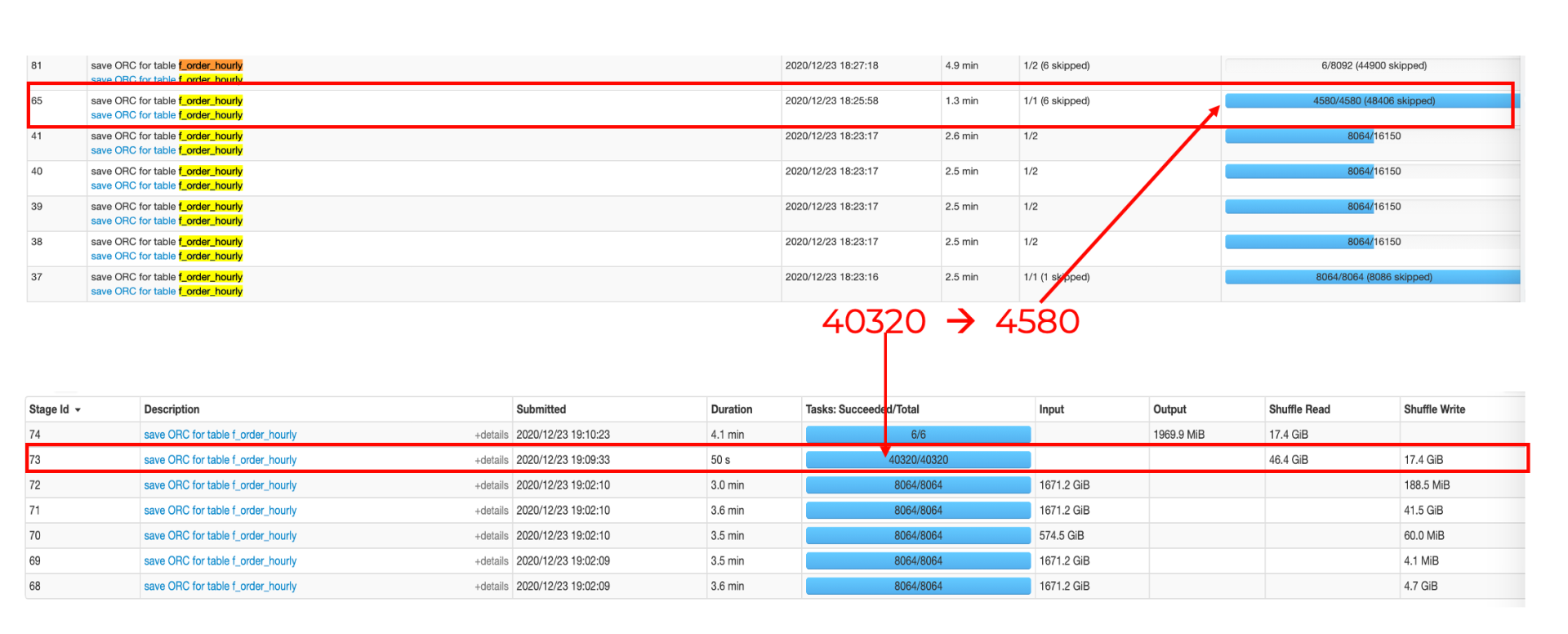
我們來仔細看一下為什么升級到 3.0 以后可以減少運行時間,又能節省集群的成本, 以 Optimus 資料建模里的一張表的運行情況為例:
- 在 reduce 階段從沒有 AQE 的40320個 tasks 銳減到4580個 tasks,減少了一個數量級,
- 下圖里下半部分是沒有 AQE 的 Spark 2.x 的 task 情況,上半部分是打開 AQE 特性后的 Spark 3.x 的情況,
- 從更詳細的運行時間圖來看,shuffler reader后同樣的 aggregate 的操作等時間也從4.44h到2.56h,節省將近一半,
- 左邊是 spark 2.x 的運行指標明細,右邊是打開 AQE 后通過custom shuffler reader后的運行指標情況,
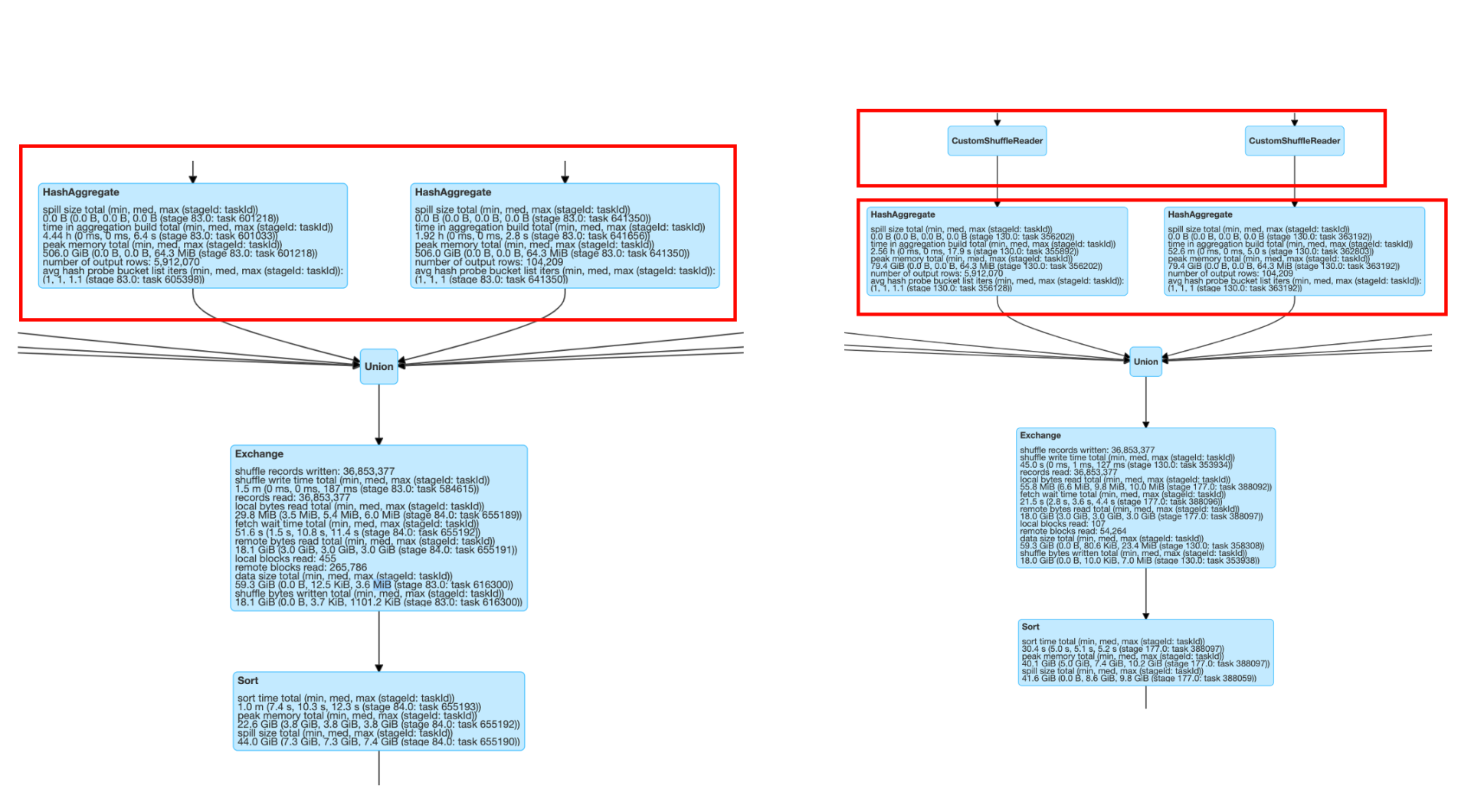
性能提升
AQE性能
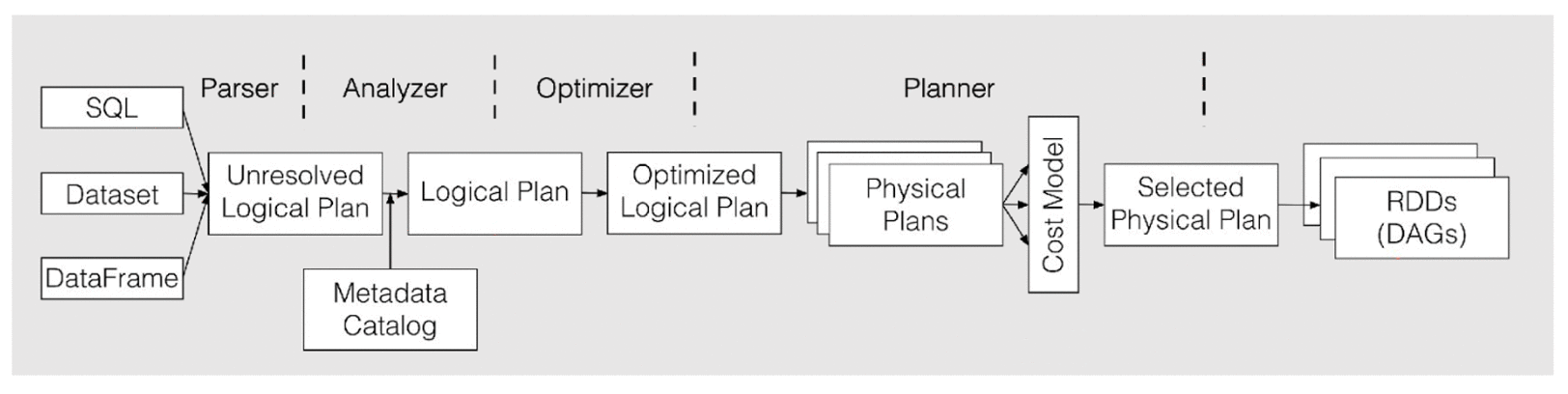
AQE對于整體的 Spark SQL 的執行程序做了相應的調整和優化(如下圖),它最大的亮點是可以根據已經完成的計劃結點真實且精確的執行統計結果來不停的反饋并重新優化剩下的執行計劃,
AQE 自動調整 reducer 的數量,減小 partition 數量,Spark 任務的并行度一直是讓用戶比較困擾的地方,如果并行度太大的話,會導致 task 過多,overhead 比較大,整體拉慢任務的運行,而如果并行度太小的,資料磁區會比較大,容易出現 OOM 的問題,并且資源也得不到合理的利用,并行運行任務優勢得不到最大的發揮,
而且由于 Spark Context 整個任務的并行度,需要一開始設定好且沒法動態修改,這就很容易出現任務剛開始的時候資料量大需要大的并行度,而運行的程序中通過轉化過濾可能最終的資料集已經變得很小,最初設定的磁區數就顯得過大了,AQE 能夠很好的解決這個問題,在 reducer 去讀取資料時,會根據用戶設定的磁區資料的大小(spark.sql.adaptive.advisoryPartitionSizeInBytes)來自動調整和合并(Coalesce)小的 partition,自適應地減小 partition 的數量,以減少資源浪費和 overhead,提升任務的性能,
由上面單張表可以看到,打開 AQE 的時候極大的降低了 task 的數量,除了減輕了 Driver 的負擔,也減少啟動 task 帶來的 schedule,memory,啟動管理等 overhead,減少 cpu 的占用,提升的 I/O 性能,
拿歷史 Data Pipelines 為例,同時會并行有三十多張表在 Spark 里運行,每張表都有極大的性能提升,那么也使得其他的表能夠獲得資源更早更多,互相受益,那么最終整個的資料建模程序會自然而然有一個加速的結果,
大 batch(>200G)相對小 batch(< 100G )有比較大的提升,有高達 40%提升,主要是因為大 batch 本身資料量大,需要機器數多,設定并發度也更大,那么 AQE 展現特性的時刻會更多更明顯,而小 batch 并發度相對較低,那么提升也就相對會少一些,不過也是有 27.5%左右的加速,
記憶體優化
除了因為 AQE 的打開,減少過碎的 task 對于 memory 的占用外,Spark 3.0 也在其他地方做了很多記憶體方面的優化,比如 Aggregate 部分指標瘦身、Netty 的共享記憶體 Pool 功能、Task Manager 死鎖問題、避免某些場景下從網路讀取 shuffle block等等,來減少記憶體的壓力,一系列記憶體的優化加上 AQE 特性疊加從前文記憶體實踐圖中可以看到集群的記憶體使用同時有30%左右的下降,
實踐成果
升級主要的實踐成果如下:
性能提升明顯
-
歷史資料 Pipeline 對于大 batch 的資料(200~400G/每小時)性能提升高達40%, 對于小 batch(小于 100G/每小時)提升效果沒有大 batch 提升的那么明顯,每天所有 batches平均提升水平27.5%左右,
-
預測資料性能平均提升30%,由于資料輸入源不一樣,目前是分別兩個 pipelines 在跑歷史和預測資料,產生的表的數目也不太一樣,因此做了分別的評估,
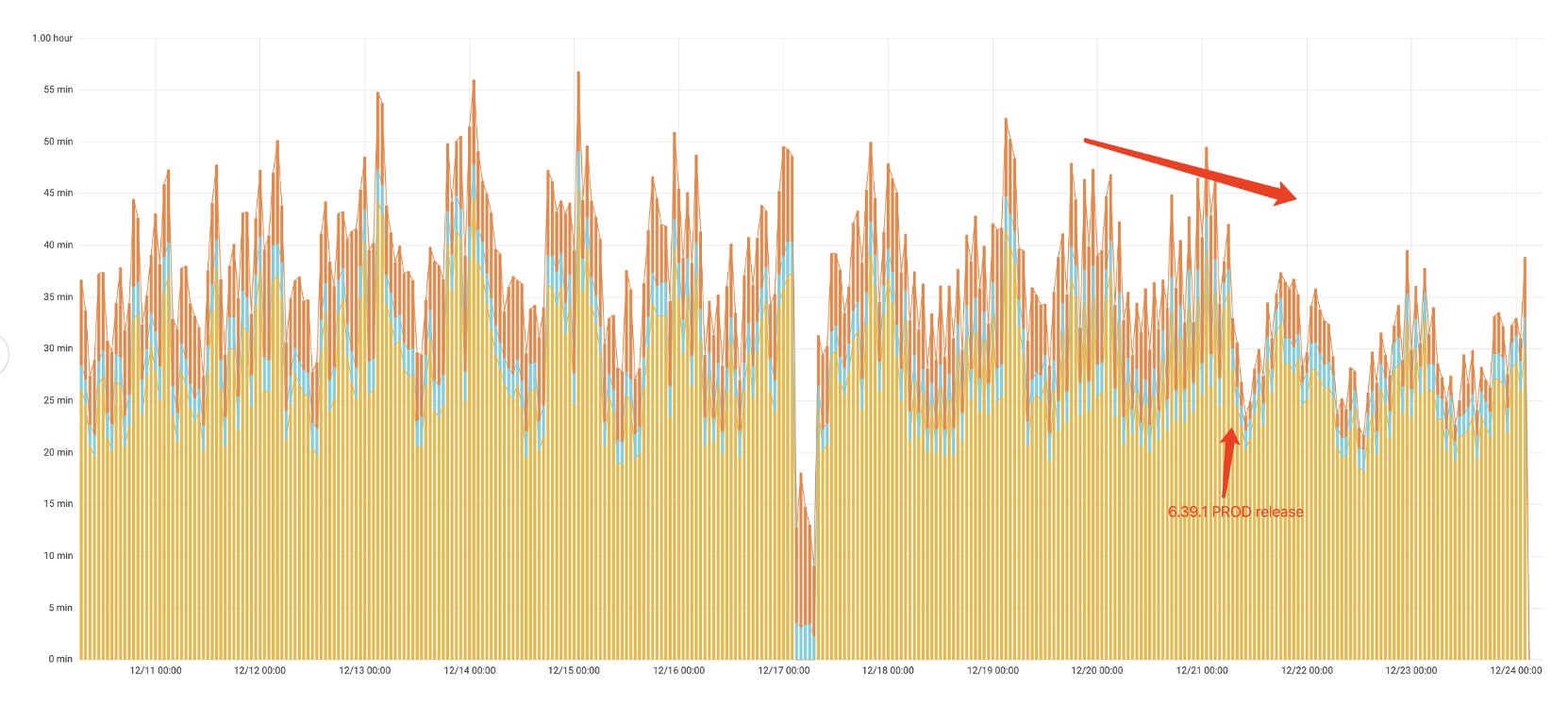
以歷史資料上線后的端到端到運行時間為例(如下圖),肉眼可見上線后整體 pipeline 的運行時間有了明顯的下降,能夠更快的輸出資料供下游使用,
集群記憶體使用降低
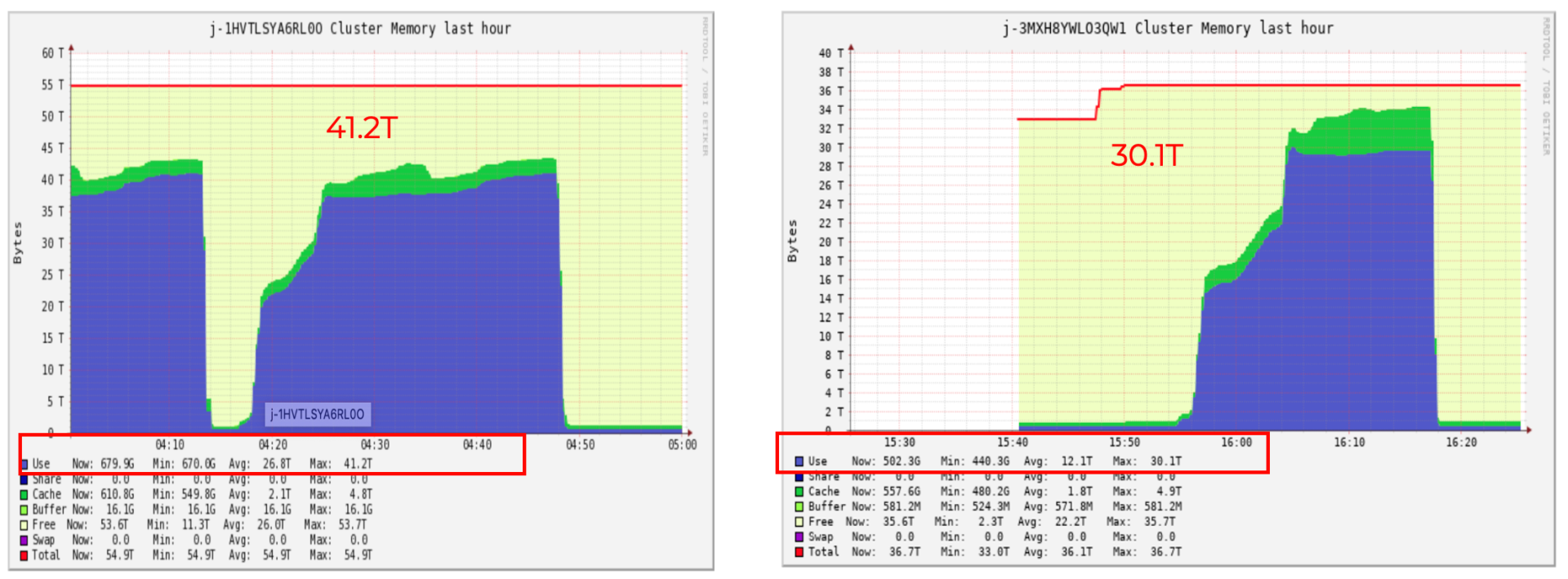
集群記憶體使用對于大 batch 達降低30%左右,每天平均平均節省25%左右,
以歷史資料上線后的運行時集群的 memory 在 ganglia 上的截圖為例(如下圖),整體集群的記憶體使用從 41.2T 降到 30.1T,這意味著我們可以用更少的機器花更少的錢來跑同樣的 Spark 任務,
AWS Cost 降低
Pipelines 做了自動的 Scale In/Scale Out 策略: 在需要資源的時候擴集群的 Task 結點,在任務結束后自動去縮集群的 Task 結點,且會根據每次 batch 資料的大小通過演算法學習得到最佳的機器數,通過升級到 Spark 3.0 后,由于現在任務跑的更快并且需要的機器更少,上線后統計 AWS Cost 每天節省30%左右,大約一年能為公司節省百萬成本,
歡迎關注,《大資料成神之路》系列文章
歡迎關注,《大資料成神之路》系列文章
歡迎關注,《大資料成神之路》系列文章
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/251379.html
標籤:Java
下一篇:陣列