在資料處理時,有時需要對資料的結構進行重排,也稱作是重塑(Reshape)或者軸向旋轉(Pivot),而運用層次化索引可為 DataFrame 的資料重排提供良好的一致性,在 pandas 中提供了實作重塑的兩個函式,即 stack() 函式和 unstack() 函式,
常見的資料層次化結構有兩種,一種是表格,如圖 1 所示;另一種是“花括號”,如圖 2 所示
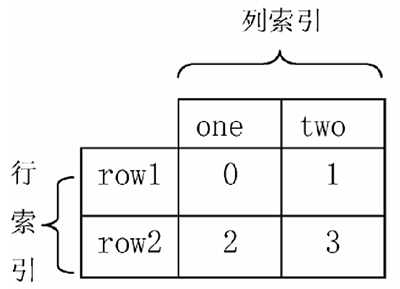
圖 1:表格結構
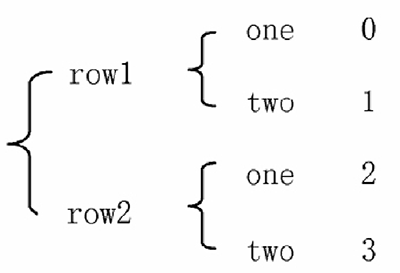
圖 2:花括號結構
表格在行列方向上均有索引(類似于 DataFrame),花括號結構只有“列方向”上的索引(類似于層次化的 Series),結構更加偏向于堆疊(Series-stack),
stack() 函式會將資料從“表格結構”變成“花括號結構”,即將其行索引變成列索引,反之,
unstack() 函式將資料從“花括號結構”變成“表格結構”,即要將其中一層的列索引變成行索引,
stack() 函式
stack() 函式的語法格式如下:
DataFrame.stack(level=-1,dropna=True)
函式中的引數說明如下:
- level:接收 int、str、list,默認為 -1,表示從列軸到索引軸堆疊的級別,定義為一個索引或標簽,或者索引或標簽串列;
- dropna:接收布林值,默認為 True,表示是否在缺失值的結果框架/系列中洗掉行,將列級別堆疊到索引軸上可以創建原始資料幀中缺失的索引值和列值的組合,
函式回傳值為 DataFrame 或 Series,
unstack() 函式
unstack() 函式的語法格式如下:
DataFrame.unstack(level=-1, fill_value=https://www.cnblogs.com/aitree/p/None)
或
Series.unstack(level=-1, fill_value=https://www.cnblogs.com/aitree/p/None)
函式中的引數說明如下:
- level:接收 int、string 或其中的串列,默認為 -1(最后一級),表示 unstack 索引的級別或級別名稱,
- fill_value:如果取消堆疊,則用此值替換 NaN 缺失值,默認為 None,
函式回傳值為 DataFrame 或 Series,
使用 stack()、unstack() 函式的示例代碼 example1.py 如下
import numpy as np import pandas as pd #創建DataFrame data = https://www.cnblogs.com/aitree/p/pd.DataFrame(np.arange(4).reshape((2, 2)), index=pd.Index(['row1', 'row2'], name='rows'), columns=pd.Index(['one', 'two'], name='cols')) print(data) cols one two rows row1 0 1 row2 2 3
#使用stack()函式改變data層次化結構 result = data.stack() print('data改變成"花括號"結構','\n',result) data改變成"花括號"結構 rows cols row1 one 0 two 1 row2 one 2 two 3
print('恢復到原來結構','\n',result.unstack()) 恢復到原來結構 cols one two rows row1 0 1 row2 2 3 print(result.unstack(0)) rows row1 row2 cols one 0 2 two 1 3 print(result.unstack('rows'))
#創建Series s1 = pd.Series([0, 1, 2, 3], index=['a', 'b', 'c', 'd']) s2 = pd.Series([4, 5, 6], index=['c', 'd', 'e']) data2 = pd.concat([s1, s2], keys=['one', 'two']) print(data2) print('將data2改變成表格結構','\n',data2.unstack()) #使用stack()函式改變成"花括號"結構,并洗掉缺失值行 print(data2.unstack().stack()) #使用stack()函式改變成"花括號"結構,不洗掉缺失值行 print(data2.unstack().stack(dropna=False)) #用字典創建DataFrame df = pd.DataFrame({'left': result, 'right': result + 3}, columns=pd.Index(['left', 'right'], name='side')) print(df) #使用unstack()、stack()函式 print(df.unstack('rows')) print(df.unstack('rows').stack('side'))
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/251405.html
標籤:Python
上一篇:Python基礎 - 變數及常量