首先宣告:爬取的內容為公開資訊
我們先看一下頁面:
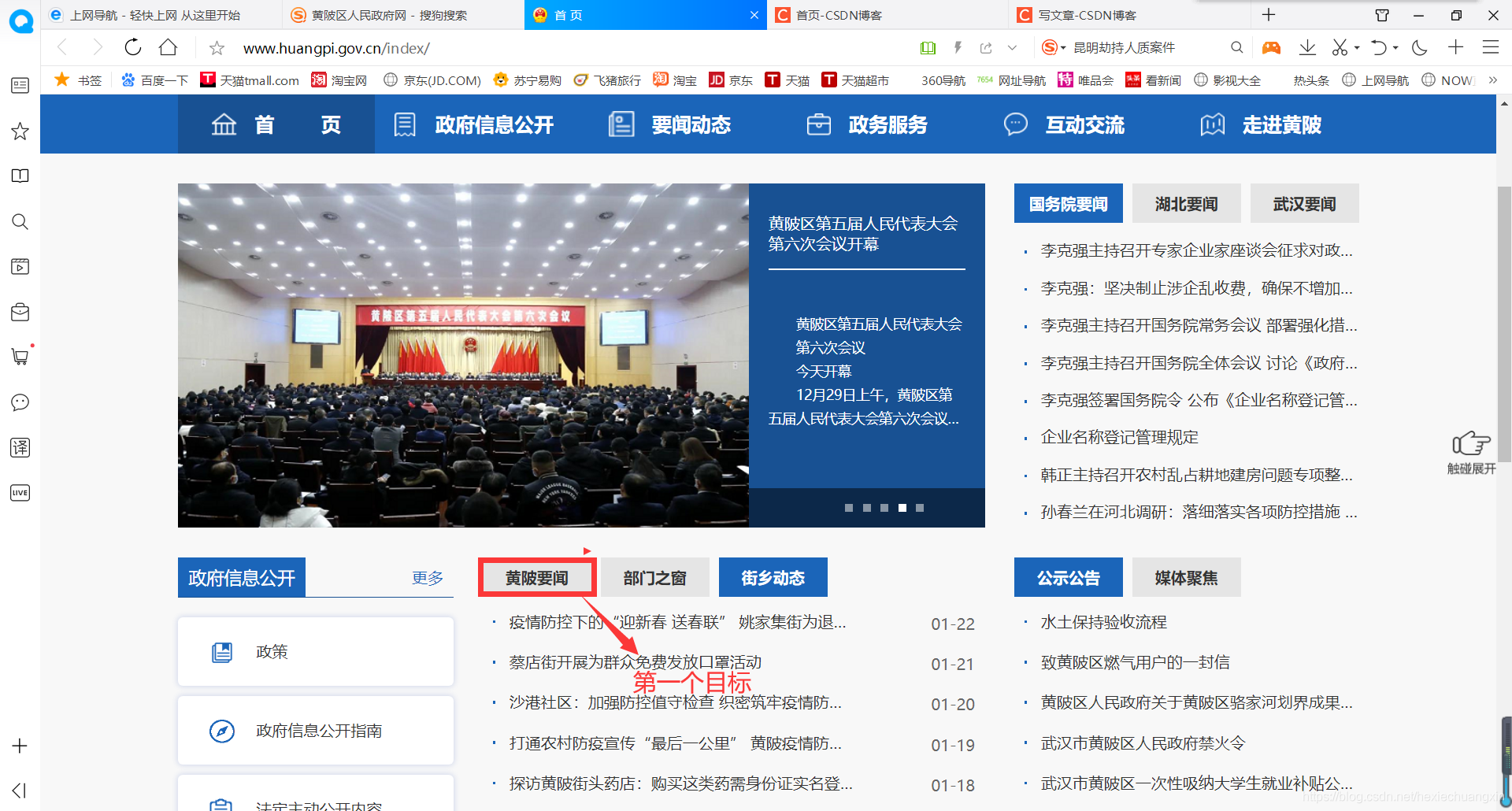
點擊黃陂要聞,進入另一個頁面:
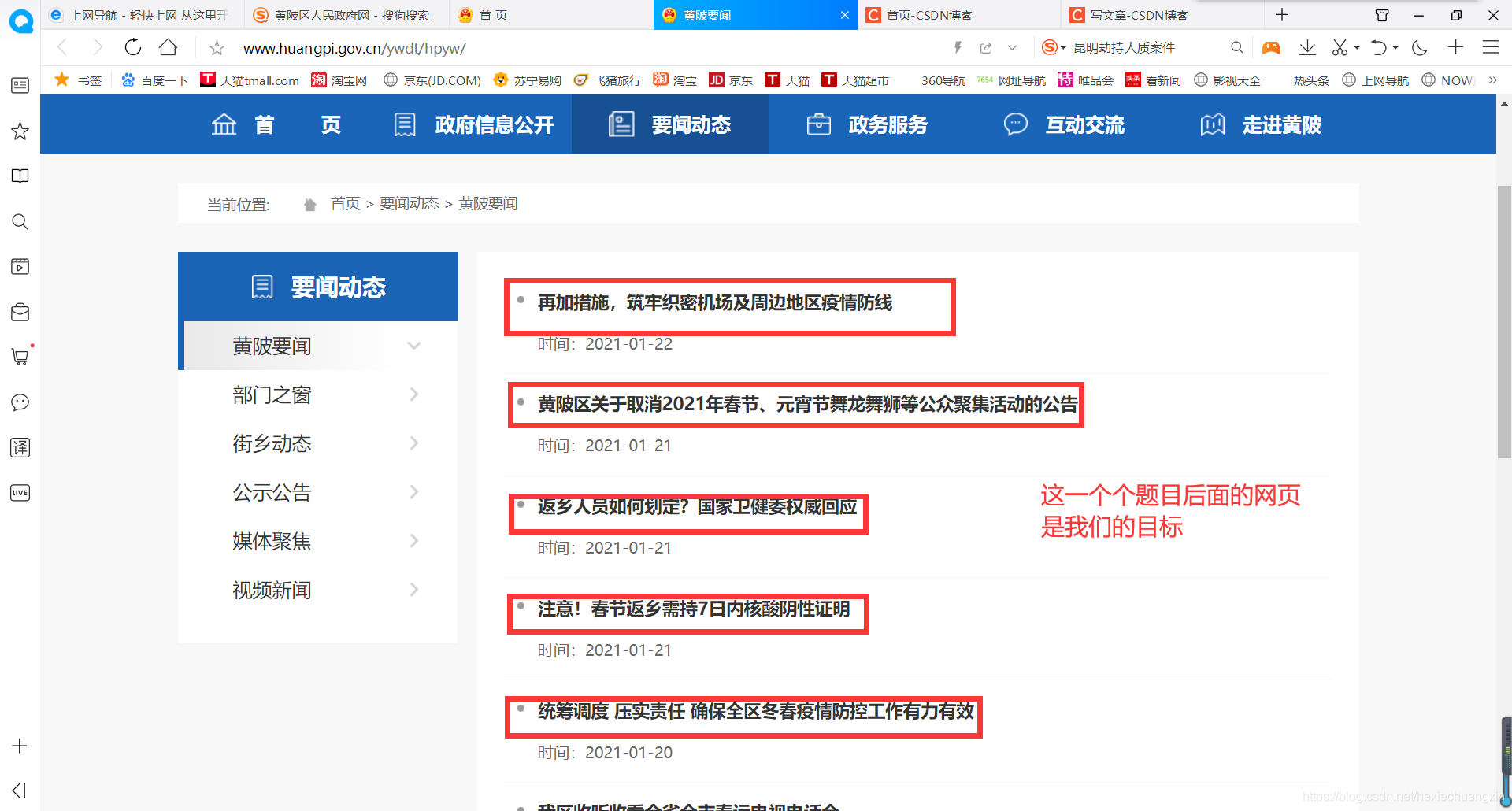
先簡要分析一下:
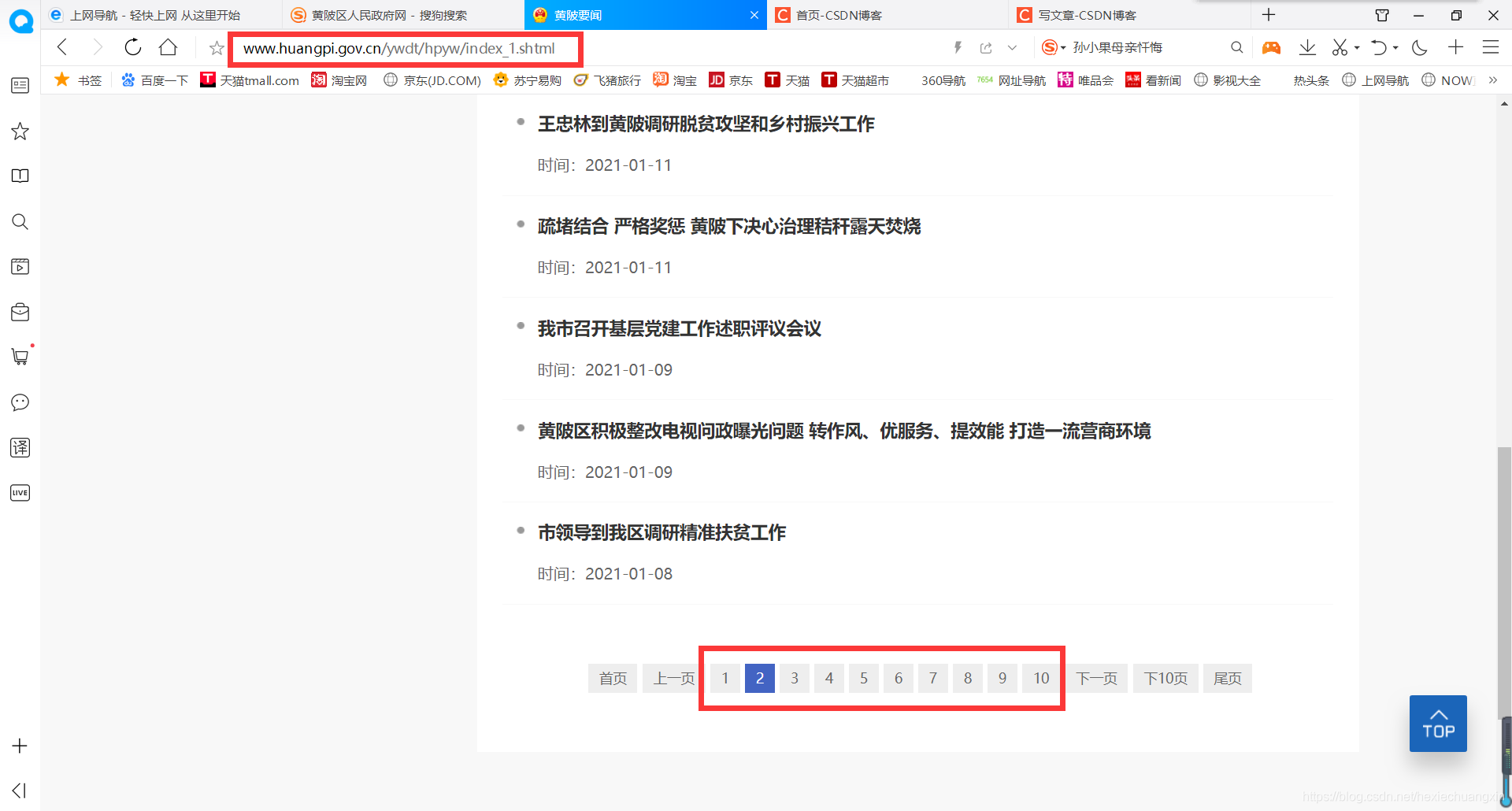
這個新聞頁面有好多頁,實際上不只圖中顯示的10頁,而是有40多頁,每一頁的網址格式相似,每張頁面里面的主要內容在 < a > 標簽里面,如圖:
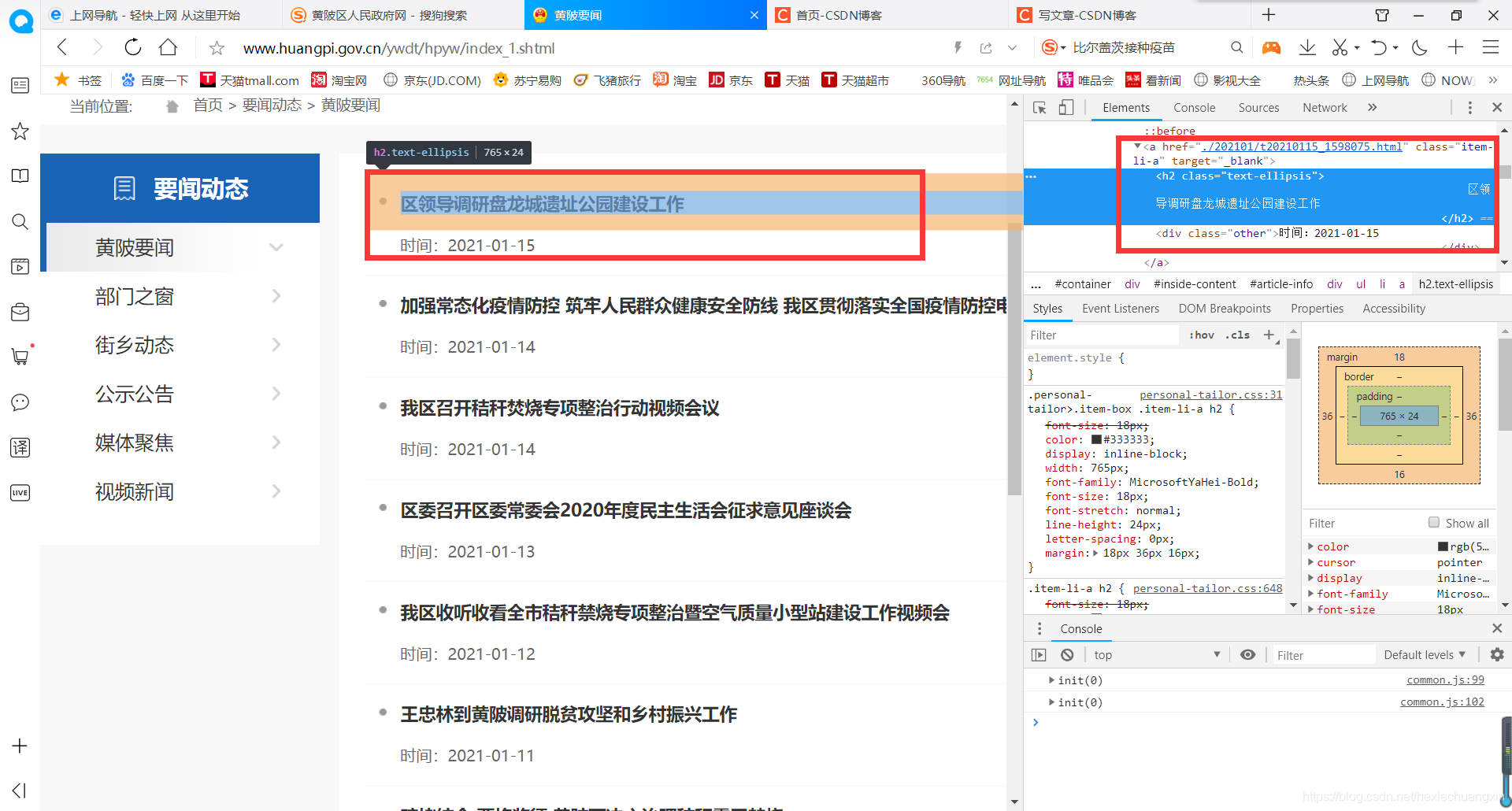
我們使用xpath方法提取出來就行,再對< a >標簽中的地址進行請求資料,
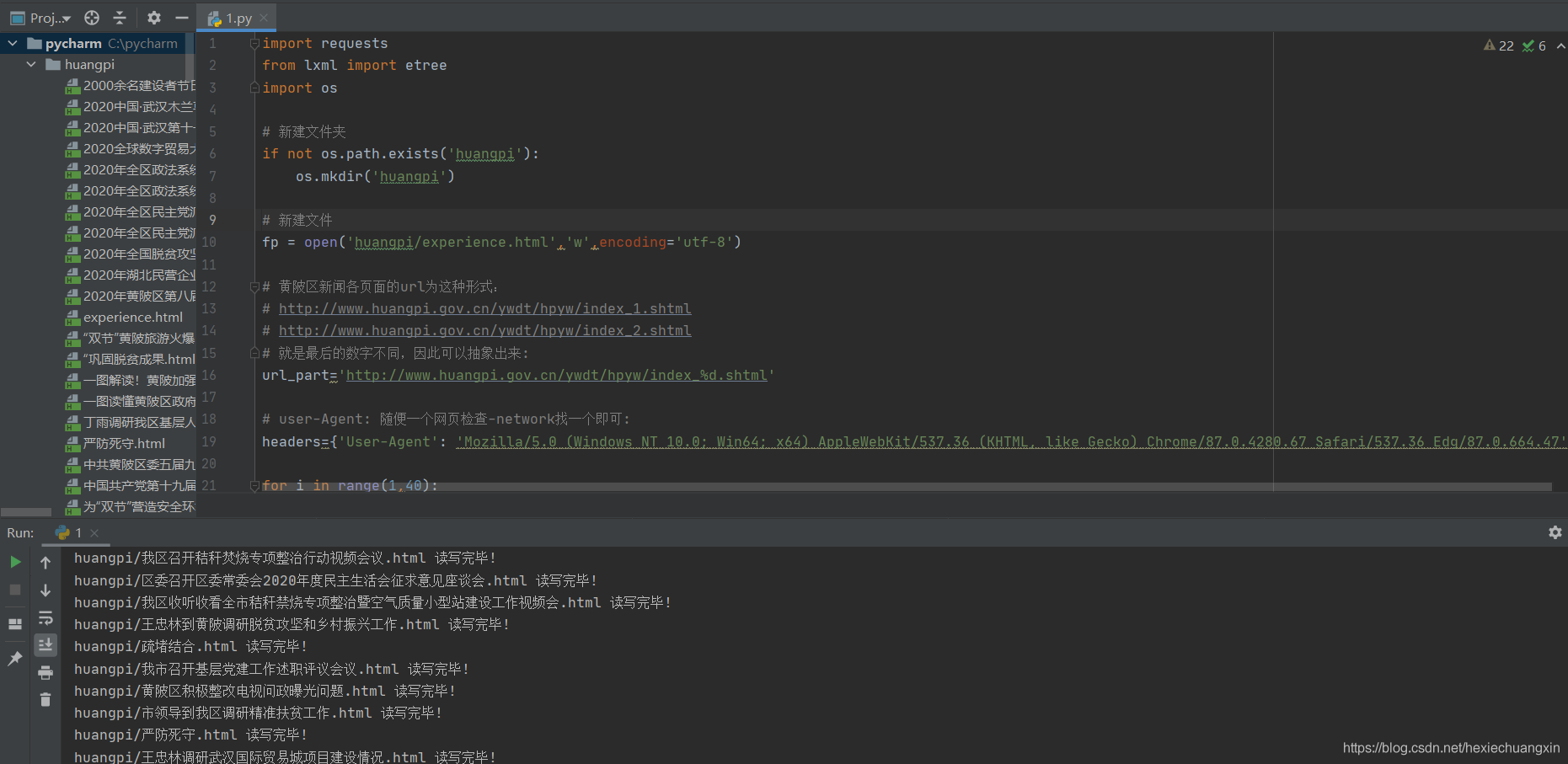
完整代碼如下:
import requests
from lxml import etree
import os
# 新建檔案夾
if not os.path.exists('huangpi'):
os.mkdir('huangpi')
# 黃陂區新聞各頁面的url為這種形式:
# http://www.huangpi.gov.cn/ywdt/hpyw/index_1.shtml
# http://www.huangpi.gov.cn/ywdt/hpyw/index_2.shtml
# 就是最后的數字不同,因此可以抽象出來:
url_part='http://www.huangpi.gov.cn/ywdt/hpyw/index_%d.shtml'
# user-Agent: 隨便一個網頁檢查-network找一個即可:
headers={'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'}
for i in range(1,40):
url=format(url_part%i) # 組合為一個完整的url
response=requests.get(url=url,headers=headers,proxies={"https":"115.207.226.40:9999"}) #添加代理ip
response.encoding='utf-8' # 進行'utf-8'編碼,或者出來是亂碼
html_data=response.text # 回應的文本資料
tree=etree.HTML(html_data) # 用網頁資料實體化etree物件
li_list=tree.xpath('//div[@class="personal-tailor"]/ul/li') # 提取新聞頁中的li標簽
for li in li_list: # 遍歷li標簽
href=li.xpath('./a/@href')[0] # 從li標簽中提取href屬性
title='huangpi/'+li.xpath('./a/h2/text()')[0].split()[0]+'.html' # 從li標簽中提取新聞題目并改為完整路徑
detail_url='http://www.huangpi.gov.cn/ywdt/hpyw/'+href[1:] # href中的網址并不完整,這里變完整
response2 = requests.get(url=detail_url, headers=headers, proxies={"https": "115.207.226.40:9999"})
response2.encoding = 'utf-8'
html = response2.text
with open(title, 'w',encoding='utf-8') as fp: # 持久化存盤
fp.write(html)
print(title, '讀寫完畢!')
print('全部讀寫完畢!')
運行效果:
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/251773.html
標籤:python
上一篇:win10下python環境配置測驗代碼gpu:false的問題
下一篇:Python實作京東搶秒殺