Scrapy框架
?Scrapy是一個為了爬取網站資料,提取結構性資料而撰寫的應用框架, 可以應用在包括資料挖掘,資訊處理或存盤歷史資料等一系列的程式中,其最初是為了 頁面抓取 (更確切來說, 網路抓取 )所設計的, 也可以應用在獲取API所回傳的資料(例如 Amazon Associates Web Services ) 或者通用的網路爬蟲,Scrapy用途廣泛,可以用于資料挖掘、監測和自動化測驗,
?Scrapy 使用了 Twisted 異步網路庫來處理網路通訊,整體架構大致如下:
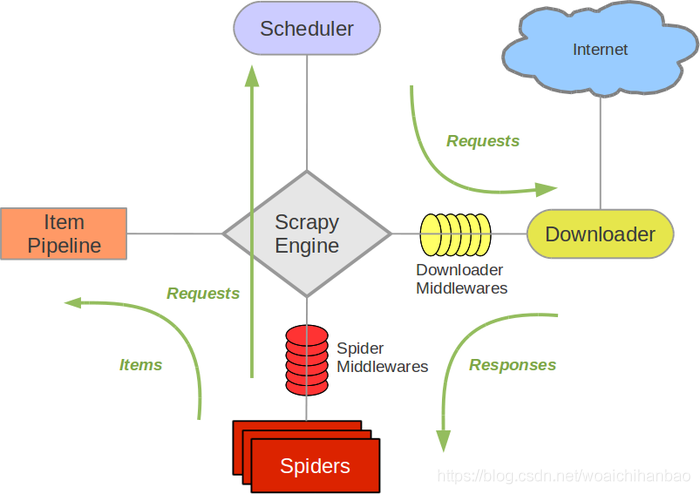
組件
Scrapy Engine
引擎負責控制資料流在系統中所有組件中流動,并在相應動作發生時觸發事件, 詳細內容查看下面的資料流(Data Flow)部分,
Scheduler(調度器)
調度器從引擎接受request并將他們入隊,以便之后引擎請求他們時提供給引擎,
Spiders
Spider是Scrapy用戶撰寫用于分析response并提取item(即獲取到的item)或額外跟進的URL的類, 每個spider負責處理一個特定(或一些)網站,
Item Pipeline
Item Pipeline負責處理被spider提取出來的item,典型的處理有清理、 驗證及持久化(例如存取到資料庫中),
下載器中間件(Downloader middlewares)
下載器中間件是在引擎及下載器之間的特定鉤子(specific hook),處理Downloader傳遞給引擎的response, 其提供了一個簡便的機制,通過插入自定義代碼來擴展Scrapy功能,
Spider中間件(Spider middlewares)
Spider中間件是在引擎及Spider之間的特定鉤子(specific hook),處理spider的輸入(response)和輸出(items及requests), 其提供了一個簡便的機制,通過插入自定義代碼來擴展Scrapy功能,
資料流(Data flow)
Scrapy中的資料流由執行引擎控制,其程序如下:
- 引擎打開一個網站(open a domain),找到處理該網站的Spider并向該spider請求第一個要爬取的URL(s),
- 引擎從Spider中獲取到第一個要爬取的URL并在調度器(Scheduler)以Request調度,
引擎向調度器請求下一個要爬取的URL, - 調度器回傳下一個要爬取的URL給引擎,引擎將URL通過下載中間件(請求(request)方向)轉發給下載器(Downloader),
- 一旦頁面下載完畢,下載器生成一個該頁面的Response,并將其通過下載中間件(回傳(response)方向)發送給引擎,
- 引擎從下載器中接收到Response并通過Spider中間件(輸入方向)發送給Spider處理,
Spider處理Response并回傳爬取到的Item及(跟進的)新的Request給引擎, - 引擎將(Spider回傳的)爬取到的Item給Item Pipeline,將(Spider回傳的)Request給調度器,
(從第二步)重復直到調度器中沒有更多地request,引擎關閉該網站,
Scrapy安裝以及生成專案
下載方式
windows:
從 https://pip.pypa.io/en/latest/installing.html 安裝 pip
打開命令列視窗,確認 pip 被正確安裝:
pip --verison
安裝scrapy:
pip install scrapy
專案初始化
startproject
語法: scrapy startproject <project_name>
是否需要專案: no
在 project_name 檔案夾下創建一個名為 project_name 的Scrapy專案,
打開命令列視窗,切換到自己想要創建的專案的目錄下,初始化一個名叫myproject的專案
scrapy startporject myproject
創建好后進入到我們所創建的專案中去,里面的目錄結構如下所示:
scrapy.cfg
myproject/
__init__.py
items.py
pipelines.py
middlewares.py
settings.py
spiders/
__init__.py
...
接下來,就可以使用 scrapy 命令來管理和控制您的專案了,比如,創建一個新的spider,我們以MOOC網為例:
genspider
語法: scrapy genspider [-t template] <name> <domain>
是否需要專案: yes
在當前專案中創建spider,
這僅僅是創建spider的一種快捷方法,該方法可以使用提前定義好的模板來生成spider,您也可以自己創建spider的原始碼檔案,
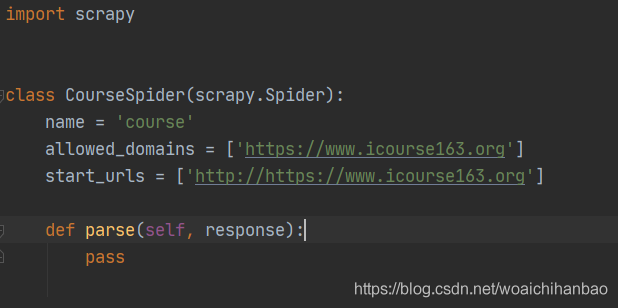
scrapy genspider course https://www.icourse163.org/
創建好后spider目錄下會生成一個course .py的檔案:
接下來我們看下專案的組態檔,專案的組態檔在目錄下的setting.py
BOT_NAME:專案名稱
USER_AGENT:用戶代理
ROBOTSTXT_OBEY:是否遵循機器人協議,默認是true
CONCURRENT_REQUESTS:最大并發數
DOWNLOAD_DELAY:下載延遲時間,單位是秒,控制爬蟲爬取的頻率,根據你的專案調整,不要太快也不要太慢,默認是3秒,即爬一個停3秒,設定為1秒性價比較高,如果要爬取的檔案較多,寫零點幾秒也行
COOKIES_ENABLED:是否保存COOKIES,默認關閉
DEFAULT_REQUEST_HEADERS:默認請求頭,上面寫了一個USER_AGENT,其實這個東西就是放在請求頭里面的,這個東西可以根據你爬取的內容做相應設定,
ITEM_PIPELINES:專案管道,300為優先級,越低越爬取的優先度越高,默認是注釋掉的
在使用Scrapy時,可以宣告所要使用的設定,這可以通過使用環境變數: SCRAPY_SETTINGS_MODULE 來完成,
SCRAPY_SETTINGS_MODULE 必須以Python路徑語法撰寫, 如 myproject.settings , 注意,設定模塊應該在 Python import search path 中,
接下來可以開始爬取任務,打開命令列輸入scrapy crawl 開始爬取任務
crawl
語法: scrapy crawl <spider>
是否需要專案: yes
使用spider進行爬取,
scrapy crawl course
日志模塊
?Scrapy提供了log功能,您可以通過 scrapy.log 模塊使用,當前底層實作使用了 Twisted logging ,不過可能在之后會有所變化,
?log服務必須通過顯示呼叫 scrapy.log.start() 來開啟,
Scrapy提供5層logging級別:
CRITICAL - 嚴重錯誤(critical)
ERROR - 一般錯誤(regular errors)
WARNING - 警告資訊(warning messages)
INFO - 一般資訊(informational messages)
DEBUG - 除錯資訊(debugging messages)
可以通過終端選項(command line option) –loglevel/-L 或 LOG_LEVEL 來設定log級別,設定log級別為WARNING,就只會WARNING等級之下的ERROR和CRITICAL
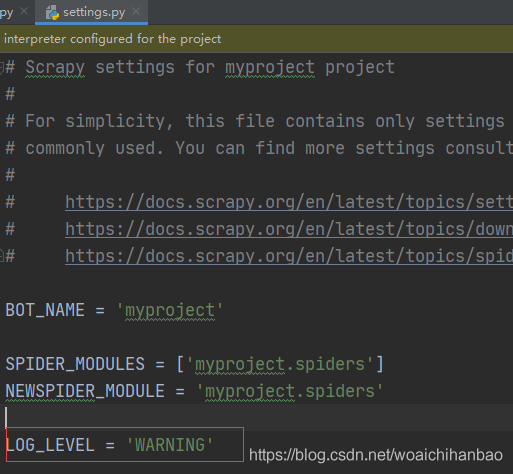
用WARNING記錄
from scrapy import log
log.msg("This is a warning", level=log.WARNING)
在spider中添加log的推薦方式是使用Spider的 log() 方法,該方法會自動在呼叫 scrapy.log.msg() 時賦值 spider 引數,其他的引數則直接傳遞給 msg() 方法,
也可自己封裝一個日志模塊
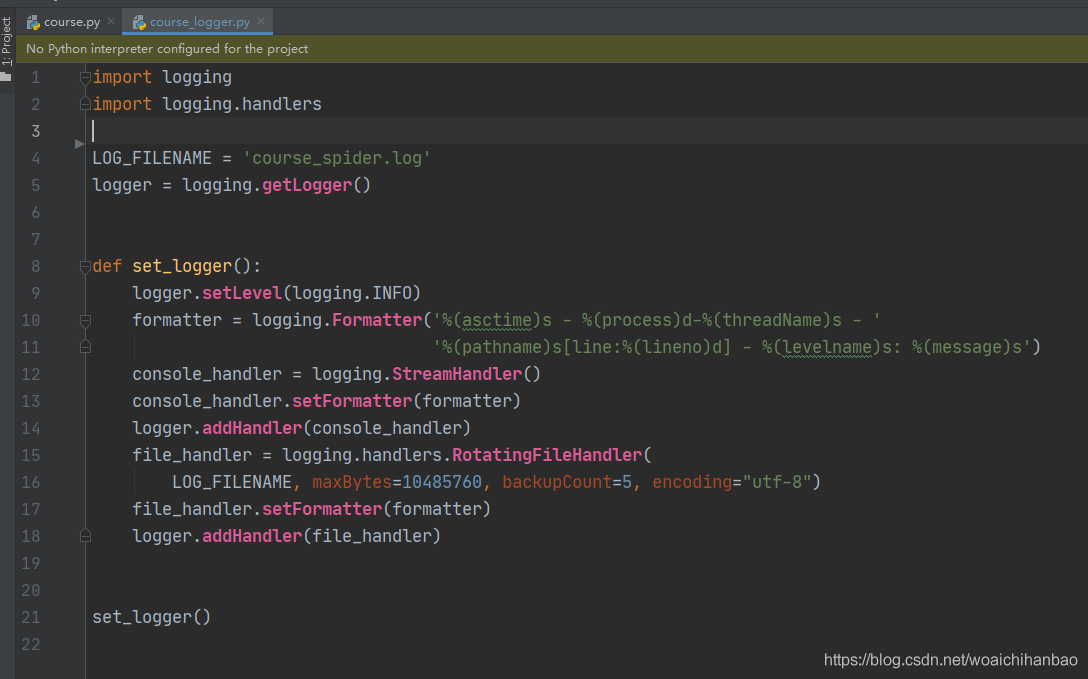
在使用的呼叫日志模塊
from .course_logger import logger
實際案例
接下來以中國大學MOOC為例,爬取免費公開課的一些資訊
以高等數學(三)為例,課程的地址必須類似以下兩種格式:
https://www.icourse163.org/course/NUDT-42002
https://www.icourse163.org/course/NUDT-42002?tid=1462924451
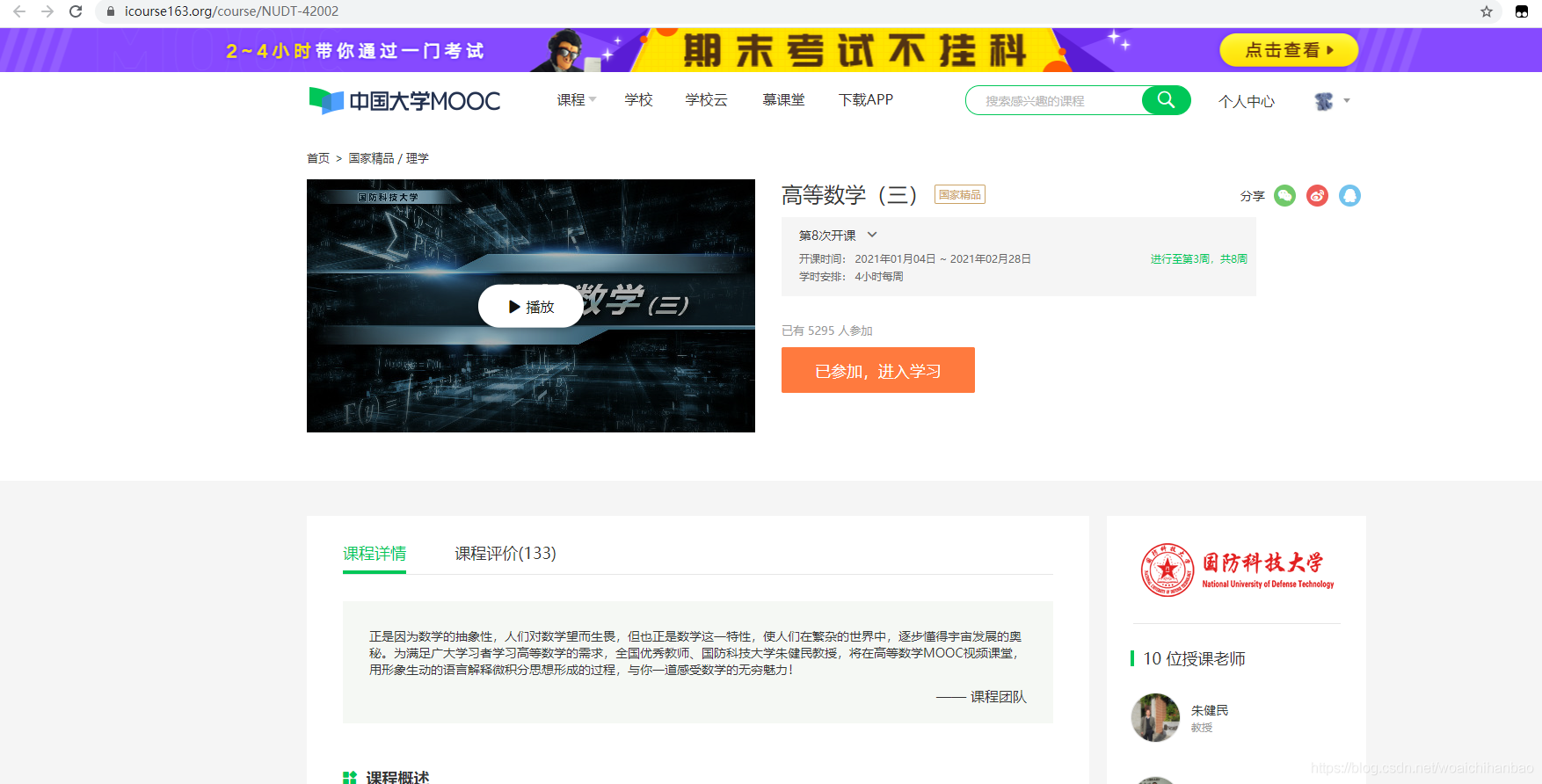
首先在item.py中,定義好你要提取的內容,比如我們提取的是課程的名稱、ID、講師、簡介、學校,相應創造這幾個變數,Field方法實際上的做法是創建一個字典,給字典添加一個建,暫時不賦值,等待提取資料后再賦值
import scrapy
class MoocItem(scrapy.Item):
term_id = scrapy.Field()
title = scrapy.Field()
description = scrapy.Field()
college = scrapy.Field()
lector = scrapy.Field()
思路
我們需要爬取的只是一個單頁面,主要就是分析HTML元素,利用xpath撰寫路徑運算式來獲取節點/節點集,和常規電腦檔案路徑類似,
re — 正則運算式操作
re模塊是python獨有的匹配字串的模塊,該模塊中提供的很多功能是基于正則運算式實作的,而正則運算式是對字串進行模糊匹配,提取自己需要的字串部分,他對所有的語言都通用
yield
scrapy框架會根據 yield 回傳的實體型別來執行不同的操作:
a. 如果是 scrapy.Request 物件,scrapy框架會去獲得該物件指向的鏈接并在請求完成后呼叫該物件的回呼函式
b. 如果是 scrapy.Item 物件,scrapy框架會將這個物件傳遞給 pipelines.py做進一步處理
def parse(self, response):
item = {'term_id': re.search(r'termId : "(\d+)"', response.text).group(1),
'title': response.xpath("//meta[@name= 'description']/@content").extract_first().split(',')[0],
'description': response.xpath("//meta[@name= 'description']/@content").extract_first().split(',')[1][
10:],
'college': response.xpath("//meta[@name= 'keywords']/@content").extract_first().split(',')[1],
}
lectors = []
script = response.css('script:contains("window.staffLectors")::text').get()
chiefLector_str = ''.join(re.findall('chiefLector = \\{([^}]*)\\}', script))
chiefLector_list = re.sub('\s+', '', ' '.join(chiefLector_str.split())).strip()
chiefLector = demjson.decode("{" + chiefLector_list + "}")
lectors.append(chiefLector)
staffLectors_str = ''.join(re.findall('staffLectors = \[([^\[\]]+)\]', script))
staffLectors_list = re.sub('\s+', '', ' '.join(staffLectors_str.split())).strip()
staffLector = demjson.decode("[" + staffLectors_list + "]")
if staffLector:
for staff in staffLector:
lectors.append(staff)
item['lector'] = lectors
yield item
在提取講師內容的時候有一點麻煩,講師內容是在script標簽中
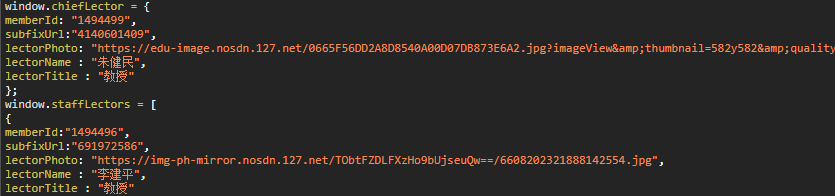
利用正則運算式去匹配變數名,然后再去匹配中括號或是大括號中的內容,還需要借助demjson處理JSON
demjson
python處理json是需要第三方json庫來支持,作業中遇到處理json資料,是沒有安裝第三方的json庫,demjson模塊提供用于編碼或解碼用語言中性JSON格式表示的資料的類和函式(這在ajax Web應用程式中通常被用作XML的簡單替代品),此實作盡量盡可能遵從JSON規范(RFC 4627),同時仍然提供許多可選擴展,以允許較少限制的JavaScript語法,它包括完整的Unicode支持,包括UTF-32,BOM,和代理對處理,
pipline.py管道可以處理提取的資料,如存Mongo資料庫,代碼敲好后不要忘記在settings里開啟pipelines,
from pymongo import MongoClient
class MyprojectPipeline:
MONGO_URL = "mongodb://localhost:27017"
MONGO_DB = "mooc"
MONGO_TABLE = "course"
client = MongoClient(MONGO_URL)
db = client[MONGO_DB]
def process_item(self, item, spider):
self.save_to_mongo(item)
return item
def save_to_mongo(self, data):
if self.db[self.MONGO_TABLE].insert(data):
print("SAVE SUCCESS", data)
return True
return False
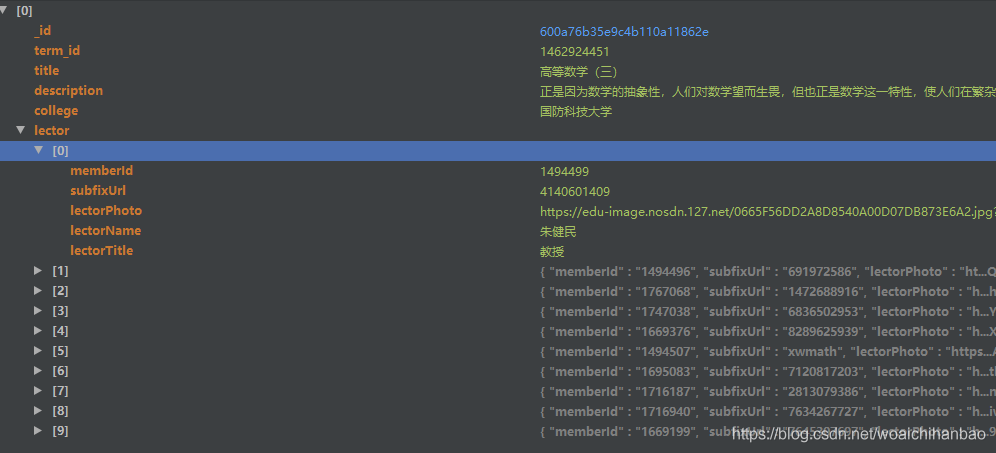
存盤成功
轉載請註明出處,本文鏈接:https://www.uj5u.com/houduan/251778.html
標籤:python
上一篇:藍橋杯每日一題(15):萊布尼茨計算圓周率(python)
下一篇:Python爬蟲自學系列(五)